初学者Tensorflow2.0第一个程序(含源码)
小白初入门的时候还是踩了很多坑,所以以一个初学者的角度记录一下自己复现的第一个基于TensorFlow程序。
由于并不是专业,可能多有不足,不过水平相近的话应该可以更好的分享经验,平时还有很多其他的工程软甲需要使用,所以使用的是Windows操作系统(小白友好)
1、IDE的选择
这里我是使用的vscode,安装的插件如下图所示:

其中的,C++相关的插件应该没有用。
总体而言,虽然定位是编辑器,但是装了插件之后功能不比其他IDE差,语法高亮和自动补全非常舒服,主要是打开文件速度也快。
配置好python环境之后,打开一个以.py为后缀的文件,随便写点python代码,按F5跳出来的弹窗选python即可。
2、准备工作
2.1 python安装
准备工作首先是安装python,版本不要太高

由于我是使用的新版本,所以安装的是python3.7.8。安装过程是自带pip安装的,中间勾选即可,可以省很多事。大家自行搜索python安装教程即可,注意在官网上要选择合适的版本。
python3.7.8版本下载:
https://www.python.org/ftp/python/3.7.8/python-3.7.8rc1-amd64.exe
python全部Windows版本下载(注意下载可执行程序):
Python Releases for Windows | Python.org
下载太慢可以试试百度网盘:
链接:https://pan.baidu.com/s/1TRtQuv1LusPdLimYPb7MMA
提取码:94db
安装没什么困难,我选了自定义安装,安装到E盘了,其他都是无脑下一步即可。最后添加系统变量即可。
有人会喜欢用anaconda对包进行管理,比如前段时间的我,但是作为新手发现自己用不了这么多包,而且anaconda的bug实在是有些一言难尽,本来是图方便,结果反而花了更多更多的时间。而且非常臃肿,不论是内存占用还是硬盘占用都比较大,对于我这样的初学者而言,还是直接用python要划算的多。
如果python安装配置不明白,可以自行搜索,或者参考这篇文章:
python环境的安装 环境变量和系统变量 - 小人物哎 - 博客园
2.2 包安装
2.2.1 准备工作:
首先要确保pip可以在cmd中可以使用。第一步要确保python成功安装。
如果提示“pip不是内部或外部命令,也不是可运行的程序,或批处理文件”应该是环境变量没有配置好,参考Python--“pip不是内部或外部命令,也不是可运行的程序或批处理文件”解决方法 - 路上code - 博客园
为了防止包下载速度极慢或者找不到链接
这个一般就是因为使用了默认的服务器,而默认服务器在国外,所以无法连接,解决的办法是更换到国内的镜像源。控制台(win+r,输入cmd回车进入)键入:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple这个网址就是镜像源站提供的网址,可以更换为:
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
2.2.2 包的安装
在本文章中使用的包有
from sklearn import datasets
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt所以要安装的包有
sklearn(数据集)、numpy(常用库)、TensorFlow、matplotlib(用于绘图)
由于咱们安装的python中已经带了pip,所以直接用pip命令安装即可。
首先先升级pip:
win+r运行,输入cmd进入控制台,输入:
python -m pip install -U pip效果如图:

按回车输入即可。
之后正式进入包的安装,首先是scikit-learn的安装,也就是import中的sklearn。控制台输入
pip install scikit-learn效果如图:回车即可自动安装
注意这里是scikit-learn就是是头文件中的sklearn,sklearn是简写,包的名字是全称。
其他包的安装也是一样,把scikit-learn改成,numpy、tensorflow-gpu、matplotlib即可。tensorflow-gpu是安装GPU版本,可以提高运算速度。
2.2.3 CUDA的安装
CUDA是TensorFlow利用GPU运行的环境基础,具体安装可以参考这篇文章即可
cuda安装教程+cudnn安装教程_sinat_23619409的博客-CSDN博客_cuda安装
不过自定义安装cuda的时候只装第一项就行,后面都是显卡驱动和physx什么的,没必要装。
3 代码讲解
本文都是参考了《北京大学人工智能实践-TensorFlow2.0》进行复现的,所以代码讲解部分也可以去听课。
from sklearn import datasets
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt本次训练的数据集存储在sklearn的datasets中,本次训练和测试是使用datasets中的iris数据集。
numpy和TensorFlow主要用于数组的处理和框架的搭建
matplotlib用于最后总结时的图像绘制,如果不需要绘制可以不添加。
# 读取数据
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target读取datasets中iris数据集的data部分(鸢尾花分类),每组数据包括【"花萼长度","花萼宽度","花瓣长度","花瓣宽度"】4个数据,一共一百多组,将数据存放到x_data中。
target部分,每组为类似[0,1,0]这样的数据,1在哪一位,就代表是哪一种花(一共三种花)。也同样是一百多组,与data部分一样多并且一一对应。读取target部分存放到y_data中。
# 将数据集打乱顺序
# 注意,需要设置相同的随机种子,才能使x、y相对应
np.random.seed(116)
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)这里需要打乱集合的顺序,不然可能会因为一些奇奇怪怪的规律导致训练出现误差
np.random.seed()设置随机种子,np.random.shuffle()将集合打乱顺序
# 将数据集后30个作为测试集,其余作为训练集
x_train = x_data[:-30]
x_test = x_data[-30:]
y_train = y_data[:-30]
y_test = y_data[-30:]
# 更改变量类型,不然矩阵相乘tf.matmul()时会报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)分割数据集是用的python列表的相关操作
tf.cast(x,tf.float32)将x中的数据转为tf.float32类型
# 把每组数据集配对成[输入,结果]的形式,然后一次batch多组数据
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(4)
# 定义可训练的参数
# 该神经网络中只有一层,所以输入4,输出3,所以权重w为[4,3],偏置b只加到输出上即可,所以是[3]
w = tf.Variable(tf.random.truncated_normal([4, 3], mean=0, stddev=1))
b = tf.Variable(tf.random.truncated_normal([3], mean=0, stddev=1))tf.data.Dataset.from_tensor_slices((x, y)).batch(32)将x、y两个表中的每一对数据进行配对,并把32组合成一批,每次训练的时候就以32组为单位喂入神经网络中。batch中的参数可以更改。
这里要采用的是一个矩阵乘法的神经网络:y=x*w+b
其中y和b都是1行3列的矩阵,x是一个1行4列的矩阵,w是一个4行3列的矩阵。其中w叫做权重(weight),b叫做偏置(bias)。
tf.random.truncated_normal([4, 3], mean=0, stddev=1)是生成一个形状为[4,3]的表,其中的数据用随机数填充,填充的随机数服从均值(mean)=0,方差(stffev)=1的正态分布(normal)分布
这个是生成数据的函数,还可以使用其他的生成方式:
比如:
tf.fill([1,2],9) 生成一个形状为[1,2]的表,并用9填充其中的每一个数。
tf.zeros([3,4]) 生成一个形状为[3,4]的表,并用0填充其中的每一个数。
还有服从其他分布的随机数,这里就不多赘述。
之后在外面套一层tf.Variable(),表示它是一个待优化的参数表。
所以:
w = tf.Variable(tf.random.truncated_normal([4, 3], mean=0, stddev=1))的意思是:
定义w为一个形状为[4,3]的矩阵,其中的数据暂时用服从正态分布的数据填充,可对其进行优化更改。
b同理
# 迭代循环,使用with结构更新参数,显示当前的loss
epoch = 500
lr = 0.1
train_loss_result = []
test_acc = []
loss_all = 0这里定义训练时的参数。
epoch为循环优化的次数
lr为学习率(learning rate)说白了就是每次优化时,参数更改多少(如果结果大了,就减小一个lr;反之则增加一个lr)
train_loss_result是一个单纯的列表,记录训练模型时每一轮中和结果差了多少(误差),方便最后我们画图的时候用
test_acc同理,不过是记录测试模型时的准确度,方便后面画图。
loss_all就是每一轮中的误差。
下面开始定义训练过程
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y = tf.matmul(x_train, w)+b # 定义神经网络的结构
y = tf.nn.softmax(y) # 输出y的概率分布,并将其转换到独热码同量级
y_ = tf.one_hot(y_train, depth=3) # 将标签转换为独热码
loss = tf.reduce_mean(tf.square(y_-y)) # 定义损失函数(优化目标)
loss_all += loss.numpy() # 将损失函数添加到loss_all中,方便后面画图
# 退出with结构
grads = tape.gradient(loss, [w, b]) # grads接受梯度下降算法对参数的优化
w.assign_sub(lr*grads[0]) # 参数更新
b.assign_sub(lr*grads[1])
print("Epoch: {}, loss: {}".format(epoch, loss_all/4))
# 将4个step中的loss取平均存入此变量,并将loss_all为下个循环归零
train_loss_result.append(loss_all/4)
loss_all = 0第一个for循环定义训练多少轮
第二个for循环遍历我们之前打包好的训练集train_db
使用with结构进行参数的优化,调用tf.GradientTape()优化器,就是一个可以求近似导数的类,名字太长了,所以我们简称它为一个加tape的对象。
下面就是with里面的内容讲解:
我们说了这个神经网络的模型是y=x*w+b,所以我们调用tf.matmul()函数,这一看就是矩阵(matrix)乘法(multiplication)的意思。后面因为计算的结果也是一个形状相同的矩阵,所以直接和b相加就可以了。
这就定义了我们的神经网络,每一轮的时候计算一下这个y值,如果结果和答案接近了就继续优化,如果远离了,就把刚才优化的过程反向进行。
之后,y = tf.nn.softmax(y)将y里面的数据变为概率,比如计算结果是[11,30,9],那么我们要算一下可能性,最后得到0.22的可能性是第一种;0.6的可能性是第二种;0.18的可能性是第三种,那我们就把[11,30,9]变成了概率分布[0.22, 0.6, 0.18](相加为1,不过有自己的算法,可以去了解一下,这里作为小白向不多赘述)
之后,y_ = tf.one_hot(y_train, depth=3),将答案以独热码的形式存到y_中,因为有一个y里有3个参数,所以depth=3。注意,这里的y_是数据集中给的答案,而上一步中的y是模型计算的结果。
再之后,loss = tf.reduce_mean(tf.square(y_-y))定义了我们要优化的内容。tf.square(y_-y)估计大家都能猜到,就是定义计算结果和答案的差的平方(答案-结果)^2。我们想让它越小越好,所以就在外面套了一层 tf.reduce_mean(),以它为标准,计算结果越小越好,并且返回里面的结果保存到变量loss中。并把loss加到loss_all上,后面计算平均误差的时候要用。
tape.gradient(loss, [w, b]) 返回一个与[w,b]维度相同的列表,就是对w与b的梯度[∂y/∂w, ∂y/∂b]然后我们吧这个梯度保存到列表grads[]中
那我们知道了梯度方向了,想让它下降怎么办?很简单的,每个变量都朝向梯度方向的反方向前进不就好了?
这里就直接用简单的减法就好了assign_sub(),sub一看就是减法(subtraction)的意思,不难理解。然后这里,前面定义的lr就派上用场了,较小的lr可以避免优化的步子太大,让这个结果在最优点的左右两边反复摇摆。
w.assign_sub(lr*grads[0])
b.assign_sub(lr*grads[1])
后面的print(输出每轮优化结果)和train_loss_result.append()就不说了,就是单纯的python的语法。后面要绘图,所以需要用train_loss_result[]保存好每一轮优化的数据。
最后别忘了把多轮优化过程中的loss_all归零,不归零不影响程序,但后面绘图和输出结果的时候就会出问题了。
然后就等着把w,b训练好就行了呗
# 测试集开始:
total_correct, total_number = 0, 0
for x_test, y_test in test_db:
y = tf.matmul(x_test, w)+b
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1)
pred = tf.cast(pred, dtype=y_test.dtype)
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
correct = tf.reduce_sum(correct)#将每个batch中的正确的加到一起
total_correct += int(correct)
total_number += x_test.shape[0]
acc = total_correct/total_number
print("test_acc:", acc)最后就是实践测试了
for循环遍历train_db测试集
y和训练时的算法一样,还是y=x*w+b
再对y进行一次softmax()
预测值pred为y结果中最大(可能性最大)的那个,然后将pred的的type设置成与y_test的一致,这样就可以比较了。
我们用tf.equal()函数比较一下pred, y_test是否相等,如果相等correct=1,反之为0,并用tf.cast将其转变为tf.float32类型。之后利用correct = tf.reduce_sum(correct)把batch中的correct加到一起就可以计算一个batch(32个)中预测正确的个数,一个循环结束之后再加到total_correct(预测正确的总数)上,顺便记录一下数据总数。
那么 正确的总数÷数据的总数=正确率,输出一下就好了。
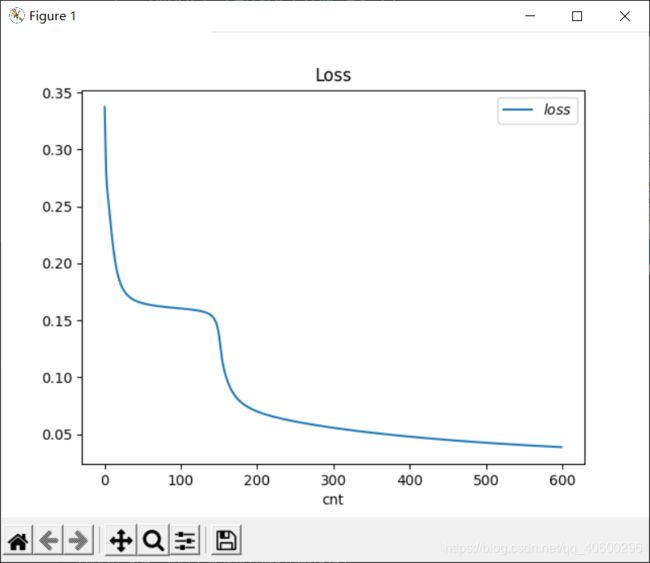
# 绘制loss图像:
plt.title("Loss")
plt.xlabel("cnt")
plt.plot(train_loss_result, label="$loss$")
plt.legend()
plt.show()最后绘制一下训练时loss的变化曲线,不多赘述,是matplotlib中的内容,如何操作可以参看相关的教程。
最后贴上完整源码
from sklearn import datasets
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
# 读取数据
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 将数据集打乱顺序
# 注意,需要设置相同的随机种子,才能使x、y相对应
np.random.seed(116)
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
# 将数据集后30个作为测试集,其余作为训练集
x_train = x_data[:-30]
x_test = x_data[-30:]
y_train = y_data[:-30]
y_test = y_data[-30:]
# 更改变量类型,防止矩阵相乘时报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# 把每组数据集配对成[输入,结果]的形式,然后一次batch多组数据
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(4)
# 定义可训练的参数
# 该神经网络中只有一层,所以输入4,输出3,所以权重w为[4,3],偏置b只加到输出上即可,所以是[3]
w = tf.Variable(tf.random.truncated_normal([4, 3], mean=0, stddev=1,dtype=tf.float32))
b = tf.Variable(tf.random.truncated_normal([3], mean=0, stddev=1,dtype=tf.float32))
# 迭代循环,使用with结构更新参数,显示当前的loss
epoch = 500
lr = 0.05
train_loss_result = []
test_acc = []
epoch = 600
loss_all = 0
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y = tf.matmul(x_train, w)+b # 定义神经网络的结构
y = tf.nn.softmax(y) # 输出y的概率分布,并将其转换到独热码同量级
y_ = tf.one_hot(y_train, depth=3) # 将标签转换为独热码
loss = tf.reduce_mean(tf.square(y_-y)) # 定义损失函数(优化目标)
loss_all += loss.numpy() # 将损失函数添加到loss_all中
# 退出with结构
grads = tape.gradient(loss, [w, b]) # grads接受梯度下降算法对参数的优化
w.assign_sub(lr*grads[0]) # 参数更新
b.assign_sub(lr*grads[1])
print("Epoch: {}, loss: {}".format(epoch, loss_all/4))
# 将4个step中的loss取平均存入此变量,并将loss_all为下个循环归零
train_loss_result.append(loss_all/4)
loss_all = 0
# 测试集开始:
total_correct, total_number = 0, 0
for x_test, y_test in test_db:
y = tf.matmul(x_test, w)+b
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1)
pred = tf.cast(pred, dtype=y_test.dtype)
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_correct += int(correct)
total_number += x_test.shape[0]
acc = total_correct/total_number
test_acc.append(acc*100)
print("test_acc:", acc)
# 绘制loss图像:
plt.title("Loss")
plt.xlabel("cnt")
plt.plot(train_loss_result, label="$loss$")
plt.legend()
plt.show()运行结果:

正在学习中,有错误之处还请大佬们多多指教