李宏毅机器学习2022-HW3
系列文章目录
李宏毅机器学习2022-hw1
李宏毅机器学习2022-hw2
文章目录
- 系列文章目录
- 问题概述
- 实验部分
-
- Simple baseline:0.50099
- Medium baseline: 0.73207
- Strong baseline: 0.81872
- Boss baseline: 0.88446
- Report Questions
-
- Q1
- Q2
- 总结
问题概述
图像分类
给一张图片,预测属于哪种食物,一共有11种
实验部分
Simple baseline:0.50099
运行初始代码,提交结果:

分析:由于初始的例程并没有做数据增强,训练3个epoch就停止了,模型复杂数据不够,严重过拟合。
Medium baseline: 0.73207
ppt:Training Augmentation + Train Longer
数据增强:根据助教ppt提示加了5种常用的图像增强手段。
加了dropout:Dropout 层一般加在全连接层,防止过拟合,提升模型泛化能力。而很少见到卷积层后接Dropout(原因主要是卷积参数少,不易过拟合)
训练批次增加到100,early_stop=8
这里有一个心路历程就是调整dropout的参数,一开始是设置了一个dropout(0.4),只有public过线,可能是泛化能力不够?

增加成两个dropout(0.4),更拉跨了。感觉是不是数值大了,就调小了一点,最后得到两个dropout(0.25)。(加完dropout训练好慢啊害
训练结果:acc=0.74695

提交结果(双medium baseline):

参数总结:
(1)网络结构:

(2)数据增强设置
train_tfm = transforms.Compose([
# Resize the image into a fixed(固定的) shape (height = width = 128)
# TODO:You may add some transforms here.
transforms.RandomResizedCrop((128, 128), scale=(0.7, 1.0)), # 随机截取并resize
# 几何变换
transforms.RandomHorizontalFlip(0.5), # 随机横向翻转
transforms.RandomVerticalFlip(0.5), # 随机竖向翻转
transforms.RandomRotation(180), # 随机旋转
transforms.RandomAffine(30), # 随机仿射
# 像素变换
transforms.RandomGrayscale(p=0.2), # 随机灰度化,p为灰度化的概率
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
(3)其他参数设置:
# The number of training epochs and patience.
n_epochs = 100
patience = 8 # If no improvement in 'patience' epochs, early stop
Strong baseline: 0.81872
ppt:Training Augmentation + Model Design + Train Looonger (+ Cross Validation + Ensemble)
数据增强方法相比于middle baseline不变
Model Design:使用残差网络
Cross Validation + Ensemble:n折交叉验证+合并网络
这里四折要训练好几次,因为kaggle一次只能持续运行12h(第一次运行完只跑完了前两折和第三折的大部分白白浪费12h我裂开,第二次竟然只跑了第三折和第四折的大部分??这不是刁难我!于是再跑一遍呜呜呜)。最后跑了3遍终于完事了…再把保存的模型都合并
第一折:

第二折:

第三折:

第四折:

其实每一折的准确率已经比medium的时候高很多了,用这四个一起预测效果更牛逼
合并后的最终预测结果:过了好多!!!
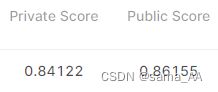
Boss baseline: 0.88446
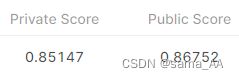
ppt:Training Augmentation + Model Design +Test Time Augmentation + Train Looonger (+ Cross Validation + Ensemble)
新加了TTA
TTA概念:对测试数据集进行数据扩展
它在测试集中创建每个图像的多个增强副本(如果只做一个增强有可能丢失特征),让模型为每个图像做出预测,然后采用这些预测的加权值,一般测试集不进行变换的权重要大一些。
不知道是不是我增强的方式不对,参数和ppt上的差不多(0.6,0.08,0.08,0.08,0.08,0.08,一共5个增强+一个本来的test),效果没有好很多,之后有时间再改进
Report Questions
Q1

数据增强,见上面medium baseline
Q2

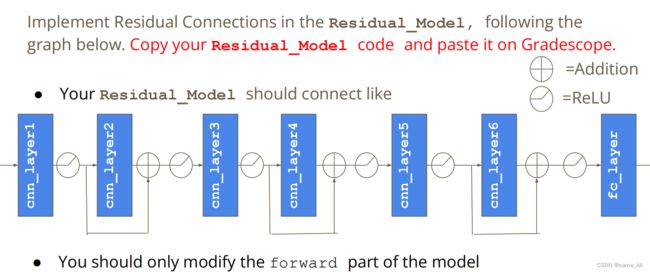
修改网络为残差网络,确实很好用,准确率提高了不少。具体结构见上面strong baseline
总结
到CNN感觉和前面两个FC的操作模式又不太一样了。
学到了处理数据增强,残差网络的应用,TTA