OpenCV3学习(11.6) ORB特征检测器及BRIEF描述符
ORB是ORiented Brief的简称,在ORB的方案中,先采用了FAST作为特征点检测算子,再使用改进BRIEF进行描述符的计算的。ORB的一个重要贡献就是引入了定位关键点的方向。
BRIEF描述符:
传统的特征点描述子如SIFT,SURF描述子,每个特征点采用128维(SIFT)或者64维(SURF)向量去描述,每个维度上占用4字节,SIFT需要128×4=512字节内存,SURF则需要256字节。如果对于内存资源有限的情况下,这种描述子方法显然不适应。同时,在形成描述子的过程中,也比较耗时。后来有人提出采用PCA降维的方法,但没有解决计算描述子耗时的问题。
Binary Robust Independent Elementary Features。BRIEF描述子采用二进制码串(每一位非1即0)作为描述子向量,论文中考虑长度有128,256,512几种(OpenCV里默认使用256,但是使用字节表示它们的,所以这些值分别对应于16,32,63),同时形成描述子算法的过程简单,由于采用二进制码串,匹配上采用汉明距离,(一个串变成另一个串所需要的最小替换次数)。但由于BRIEF描述子不具有方向性,大角度旋转会对匹配上有很大的影响。
BRIRF只提出了描述特征点的方法,所以特征点的检测部分必须结合其他的方法,如SIFT,SURF等,但论文中建议与Fast结合,因为会更能体现出Brirf速度快等优点。
BRIEF描述子原理简要为三个步骤,长度为N的二进制码串作为描述子(占用内存N/8):
1.以特征点P为中心,取一个S×S(48*48)大小的Patch邻域;
2.在这个邻域内随机取N对点,然后对这2×N个点分别做高斯平滑,比较N对像素点的灰度值的大小;
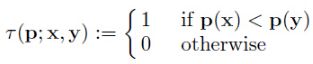
其中,p(x),p(y)分别是随机点x=(u1,v1),y=(u2,v2)的像素值。
3.最后把步骤2得到的N个二进制码串组成一个N维向量即可;
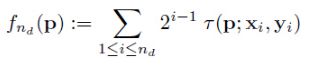
原理解析:
1.测试前,需要对随机点做高斯平滑,由于采用单个的像素灰度值做比较,会对噪声很敏感;采用高斯平滑图像,会降低噪声的影响,使得描述子更加稳定。论文中建议采用9×9的kernal。
2.论文中对随机取N对点采用了5种不同的方法做测试,论文中建议采用G II的方法:


3.特征配对是利用的汉明距离进行判决,直接比较两二进制码串的距离,距离定义为:其中一个串变成另一个串所需要的最少操作。因而比欧氏距离运算速度快。如果取N=128,即每个特征点需要128/8=16个字节内存大小作为其描述子:
- 两个特征编码对应bit位上相同元素的个数小于64的,一定不是配对的。
- 一幅图上特征点与另一幅图上特征编码对应bit位上相同元素的个数最多的特征点配成一对。
实例(opencv2):
#include
#include
#include "cv.h"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/core/core.hpp"
#include "opencv2/features2d/features2d.hpp"
#include "opencv2/nonfree/nonfree.hpp"
using namespace std;
using namespace cv;
int main( int argc, char** argv )
{
Mat img_1 = imread( "F:\\Picture\\book.jpg", CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( "F:\\Picture\\book_2.jpg", CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{
return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian); //采用Surf特征点检测
std::vector keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
BriefDescriptorExtractor extractor(64); //参数表示字节数,采用长度为64×8=512的向量表示,见下方分析
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors with a brute force matcher
BFMatcher matcher(NORM_HAMMING); //汉明距离匹配特征点
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
//-- Draw matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2, matches, img_matches );
-- Show detected matches
imshow("Matches", img_matches );
waitKey(0);
return 0;
}
from:https://blog.csdn.net/luoshixian099/article/details/48338273
BRIEF的优点在于速度,缺点也相当明显:
1:不具备旋转不变性。
2:对噪声敏感
3:不具备尺度不变性。
ORB就是试图解决上述缺点中的1和2.
步骤一:粗提取。FAST算法能够提取大量的特征点,但是有很大一部分的特征点的质量不高。下面介绍提取方法。从图像中选取一点P,如上图1。我们判断该点是不是特征点的方法是,以P为圆心画一个半径为3pixel的圆。圆周上如果有连续n个像素点的灰度值比P点的灰度值大或者小,则认为P为特征点。一般n设置为12。为了加快特征点的提取,快速排出非特征点,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的的像素值都大于或者小于P点的灰度值。如果不满足,则直接排出此点。
步骤二:机器学习的方法筛选最优特征点。简单来说就是使用ID3算法训练一个决策树,将特征点圆周上的16个像素输入决策树中,以此来筛选出最优的FAST特征点。
步骤三:非极大值抑制去除局部较密集特征点。使用非极大值抑制算法去除临近位置多个特征点的问题。为每一个特征点计算出其响应大小。计算方式是特征点P和其周围16个特征点偏差的绝对值和。在比较临近的特征点中,保留响应值较大的特征点,删除其余的特征点。
步骤四:特征点的尺度不变形。建立金字塔,来实现特征点的多尺度不变性。设置一个比例因子scaleFactor(opencv默认为1.2)和金字塔的层数nlevels(opencv默认为8)。将原图像按比例因子缩小成nlevels幅图像。缩放后的图像为:I’= I/scaleFactor*k(k=1,2,…, nlevels)。nlevels幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点。
步骤五:特征点的旋转不变性,解决旋转不变性:
在Sift的方案中,特征点的主方向是由梯度直方图的最大值和次大值所在的bin对应的方向决定的。略嫌耗时。在ORB的方案中,特征点的主方向是通过矩(moment)计算而来,也就是说通过矩来计算特征点以r为半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:

有了主方向之后,就可以依据该主方向提取BRIEF描述子。但是由此带来的问题是,由于主方向会发生变化,随机点对的相关性会比较大,从而降低描述子的判别性。解决方案也很直接,采取贪婪的,穷举的方法,暴力找到相关性较低的随机点对。
如何解决对噪声敏感的问题:
在前面提到过,在最早的eccv2010的文章中,BRIEF使用的是pixel跟pixel的大小来构造描述子的每一个bit。这样的后果就是对噪声敏感。因此,在ORB的方案中,做了这样的改进,不再使用pixel-pair,而是使用9×9的patch-pair,也就是说,对比patch的像素值之和。(可以通过积分图快速计算)。
关于尺度不变性:
ORB没有试图解决尺度不变性,(因为FAST本身就不具有尺度不变性。)但是这样只求速度的特征描述子,一般都是应用在实时的视频处理中的,这样的话就可以通过跟踪还有一些启发式的策略来解决尺度不变性的问题。
关于计算速度:
ORB是sift的100倍,是surf的10倍
ORB属于features2d模块中,opencv3中提供了一个静态成员函数来供我们使用,而且还是用了一个C++的新特性:智能指针Ptr,使用智能指针最方便的就是在我们使用new申请动态内存的时候,不需要用delete释放,系统会自动释放。
static Ptr cv::ORB::create (
int nfeatures = 500,
float scaleFactor = 1.2f,
int nlevels = 8,
int edgeThreshold = 31,
int firstLevel = 0,
int WTA_K = 2,
int scoreType = ORB::HARRIS_SCORE,
int patchSize = 31,
int fastThreshold = 20
) 参数含义:
nfeatures - 最多提取的特征点的数量;
scaleFactor - 金字塔图像之间的尺度参数;
nlevels – 高斯金字塔的层数;
edgeThreshold – 边缘阈值,这个值主要是根据后面的patchSize来定的,靠近边缘edgeThreshold以内的像素是不检测特征点的。
firstLevel - 看过SIFT都知道,我们可以指定第一层的索引值,这里默认为0。
WET_K - 用于产生BIREF描述子的 点对的个数,一般为2个,也可以设置为3个或4个,那么这时候描述子之间的距离计算就不能用汉明距离了,而是应该用一个变种。OpenCV中,如果设置WET_K = 2,则选用点对就只有2个点,匹配的时候距离参数选择NORM_HAMMING,如果WET_K设置为3或4,则BIREF描述子会选择3个或4个点,那么后面匹配的时候应该选择的距离参数为NORM_HAMMING2。
scoreType - 用于对特征点进行排序的算法,你可以选择HARRIS_SCORE,也可以选择FAST_SCORE,但是它也只是比前者快一点点而已。
patchSize – 用于计算BIREF描述子的特征点邻域大小。
官网描述:https://docs.opencv.org/3.2.0/db/d95/classcv_1_1ORB.html#adc371099dc902a9674bd98936e79739c
实例:
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main()
{
//读取图片
Mat rgbd1 = imread("自己的图片Path");
Mat rgbd2 = imread("自己的图片Path");
//imshow("rgbd1", depth2);
//waitKey(0);
Ptr orb = ORB::create();
vector Keypoints1,Keypoints2;
Mat descriptors1,descriptors2;
orb->detectAndCompute(rgbd1, Mat(), Keypoints1, descriptors1);
orb->detectAndCompute(rgbd1, Mat(), Keypoints2, descriptors2);
//cout << "Key points of image" << Keypoints.size() << endl;
//可视化,显示关键点
Mat ShowKeypoints1, ShowKeypoints2;
drawKeypoints(rgbd1,Keypoints1,ShowKeypoints1);
drawKeypoints(rgbd2, Keypoints2, ShowKeypoints2);
imshow("Keypoints1", ShowKeypoints1);
imshow("Keypoints2", ShowKeypoints2);
waitKey(0);
//Matching
vector matches;
Ptr matcher =DescriptorMatcher::create("BruteForce");
matcher->match(descriptors1, descriptors2, matches);
cout << "find out total " << matches.size() << " matches" << endl;
//可视化
Mat ShowMatches;
drawMatches(rgbd1,Keypoints1,rgbd2,Keypoints2,matches,ShowMatches);
imshow("matches", ShowMatches);
waitKey(0);
return 0;
} 程序来自:https://blog.csdn.net/bingoplus/article/details/60133565