ORB特征提取、匹配及位置估计
1、什么是ORB特征点?
图像特征点可以理解为图像中比较显著的点,如轮廓点,较暗区域中的亮点,较亮区域中的暗点等。ORB采用FAST(features from accelerated segment test)算法来检测特征点。这个定义基于特征点周围的图像灰度值,检测候选特征点周围一圈的像素值,如果候选点周围领域内有足够多的像素点与该候选点的灰度值差别够大,则认为该候选点为一个特征点。FAST核心思想就是找出那些卓尔不群的点,即拿一个点跟它周围的点比较,如果它和其中大部分的点都不一样就可以认为它是一个特征点。
为了获得更快的结果,还采用了额外的加速办法。如果测试了候选点周围每隔90度角的4个点,应该至少有3个和候选点的灰度值差足够大,否则则不用再计算其他点,直接认为该候选点不是特征点。候选点周围的圆的选取半径是一个很重要的参数,这里为了简单高效,采用半径为3,共有16个周边像素需要比较。为了提高比较的效率,通常只使用N个周边像素来比较,也就是大家经常说的FAST-N。很多文献推荐FAST-9,作者的主页上有FAST-9、FAST-10、FAST-11、FAST-12,大家使用比较多的是FAST-9和FAST-12。
检测出的ORB特征点然后利用Harris角点的度量方法,从FAST特征点中挑选出Harris角点响应值最大的N个特征点。

OPENCV中可通过ORB来创建一个ORB检测器:
ORB::ORB(int nfeatures=500, float scaleFactor=1.2f, int nlevels=8, int edgeThreshold=31, int firstLevel=0, int WTA_K=2, int scoreType=ORB::HARRIS_SCORE, int patchSize=31)
nfeatures - 最多提取的特征点的数量;
scaleFactor - 金字塔图像之间的尺度参数,类似于SIFT中的k;
nlevels – 高斯金字塔的层数;
edgeThreshold – 边缘阈值,这个值主要是根据后面的patchSize来定的,靠近边缘edgeThreshold以内的像素是不检测特征点的。
firstLevel - 看过SIFT都知道,我们可以指定第一层的索引值,这里默认为0。
WET_K - 用于产生BIREF描述子的 点对的个数,一般为2个,也可以设置为3个或4个,那么这时候描述子之间的距离计算就不能用汉明距离了,而是应该用一个变种。OpenCV中,如果设置WET_K = 2,则选用点对就只有2个点,匹配的时候距离参数选择NORM_HAMMING,如果WET_K设置为3或4,则BIREF描述子会选择3个或4个点,那么后面匹配的时候应该选择的距离参数为NORM_HAMMING2。
scoreType - 用于对特征点进行排序的算法,你可以选择HARRIS_SCORE,也可以选择FAST_SCORE,但是它也只是比前者快一点点而已。
patchSize – 用于计算BIREF描述子的特征点邻域大小。
2、特征描述子
得到特征点后我们需要以某种方式描述这些特征点的属性。这些属性的输出我们称之为该特征点的描述子(Feature DescritorS).ORB采用BRIEF算法来计算一个特征点的描述子。
BRIEF算法的核心思想是在关键点P的周围以一定模式选取N个点对,把这N个点对的比较结果组合起来作为描述子。
理想的特征点描述子应该具备的属性:
在现实生活中,我们从不同的距离,不同的方向、角度,不同的光照条件下观察一个物体时,物体的大小,形状,明暗都会有所不同。但我们的大脑依然可以判断它是同一件物体。理想的特征描述子应该具备这些性质。即,在大小、方向、明暗不同的图像中,同一特征点应具有足够相似的描述子,称之为描述子的可复现性。
当以某种理想的方式分别计算描述子时,应该得出同样的结果。即描述子应该对光照(亮度)不敏感,具备尺度一致性(大小 ),旋转一致性(角度)等。
ORB并没有解决尺度一致性问题,在OpenCV的ORB实现中采用了图像金字塔来改善这方面的性能。ORB主要解决BRIEF描述子不具备旋转不变性的问题。
3、汉明距离与Brute-Force匹配
两个不同二进制之间的汉明距离指的是两个二进制串不同位的个数。两个二进制不同位的个数是越少越好,故匹配的距离distance越小越好。
汉明距离是以理查德•卫斯里•汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
"toned" 与 "roses" 之间的汉明距离是 3。
给予两个任何的字码,10001001和10110001,即可决定有多少个相对位是不一样的。在此例中,有三个位不同。要决定有多少个位不同,只需将xor运算加诸于两个字码就可以,并在结果中计算有多个为1的位。两个字码中不同位值的数目称为汉明距离(Hamming distance) 。
Brute-Force匹配器很简单,它取第一个集合里的一个特征的描述子与第二个集合里所有其他特征和它通过一些距离计算进行匹配,返回匹配最近的值。
对于BF匹配器,OPENCV中首先得用BFMatcher类创建BF匹配器对象,它可取两个参数:第一个参数是normType,它指定要使用的距离量度。默认是NORM_L2。对于SIFT,SURF很好。(还有NORM_L1)。对于二进制字符串的描述子,比如ORB,BRIEF,BRISK等,应该用NORM_HAMMING。使用Hamming距离度量,如果ORB使用VTA_K == 3或者4,应该用NORM_HAMMING2。第二个参数是布尔变量,crossCheck默认值是false。如果设置为True,匹配条件就会更加严格,只有到A中的第i个特征点与B中的第j个特征点距离最近,并且B中的第j个特征点到A中的第i个特征点也是最近时才会返回最佳匹配(i,j), 即这两个特征点要互相匹配才行。
BFMatcher对象有两个方法BFMatcher.match()和BFMatcher.knnMatch()。第一个方法会返回最佳匹配。第二个方法为每个关键点返回k个最佳匹配,其中k是由用户设定的。
4、匹配优化
在比对描述值相似度的方法中,最简单直观的方法就是使用暴力匹配方法(Brute-Froce Matcher),即计算某一个特征点描述子与其他所有特征点描述子之间的距离,然后将得到的距离进行排序,取距离最近的一个作为匹配点。这种方法简单粗暴,其结果也是显而易见的,但也可能有大量的错误匹配,这就需要使用一些机制来过滤掉错误的匹配。
1)汉明距离小于最小距离的两倍
经典的方法有汉明距离小于最小距离的两倍,选择已经匹配的点对的汉明距离不大于最小距离的两倍作为判断依据,如果不大于该值则认为是一个正确的匹配;大于该值则认为是一个错误的匹配。
// 匹配对筛选
double min_dist = 1000, max_dist = 0;
// 找出所有匹配之间的最大值和最小值
for (int i = 0; i < descriptors1.rows; i++)
{
double dist = matches[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
// 当描述子之间的匹配大于2倍的最小距离时,即认为该匹配是一个错误的匹配。
// 但有时描述子之间的最小距离非常小,可以设置一个经验值作为下限
vector good_matches;
for (int i = 0; i < descriptors1.rows; i++)
{
if (matches[i].distance <= max(2 * min_dist, 30.0))
good_matches.push_back(matches[i]);
} 2)交叉匹配
针对暴力匹配,可以使用交叉匹配的方法来过滤错误的匹配。交叉过滤的思想是再进行一次匹配,反过来使用被匹配到的点进行匹配,如果匹配到的仍然是第一次匹配的点的话,就认为这是一个正确的匹配。举例来说就是,假如第一次特征点A使用暴力匹配的方法,匹配到的特征点是特征点B;反过来,使用特征点B进行匹配,如果匹配到的仍然是特征点A,则就认为这是一个正确的匹配,否则就是一个错误的匹配。OpenCV中BFMatcher已经封装了该方法,创建BFMatcher的实例时,第二个参数传入true即可,BFMatcher bfMatcher(NORM_HAMMING,true)。
3)KNN匹配
在匹配过程中,为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,SIFT的作者Lowe提出了比较最近邻距离与次近邻距离的SIFT匹配方式:取一幅图像中的一个SIFT关键点,并找出其与另一幅图像中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离得到的比率ratio少于某个阈值T,则接受这一对匹配点。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。显然降低这个比例阈值T,SIFT匹配点数目会减少,但更加稳定,反之亦然。
const float minRatio = 1.f / 1.5f;
const int k = 2;
vector> knnMatches;
matcher->knnMatch(leftPattern->descriptors, rightPattern->descriptors, knnMatches, k);
for (size_t i = 0; i < knnMatches.size(); i++) {
const DMatch& bestMatch = knnMatches[i][0];
const DMatch& betterMatch = knnMatches[i][1];
float distanceRatio = bestMatch.distance / betterMatch.distance;
if (distanceRatio < minRatio)
matches.push_back(bestMatch);
}const float minRatio = 1.f / 1.5f;
const int k = 2;
vector> knnMatches;
matcher->knnMatch(leftPattern->descriptors, rightPattern->descriptors, knnMatches, 2);
for (size_t i = 0; i < knnMatches.size(); i++) {
const DMatch& bestMatch = knnMatches[i][0];
const DMatch& betterMatch = knnMatches[i][1];
float distanceRatio = bestMatch.distance / betterMatch.distance;
if (distanceRatio < minRatio)
matches.push_back(bestMatch);
} 4)通过RANSAC寻找单应性矩阵的方法
5、映射矩阵Homography
Homography:在图中有两张书的平面图,两张图分别有四个相对位置相同的点,Homography就是一个变换(3*3矩阵),将一张图中的点映射到另一张图中对应的点 。

Homography是一个3乘3的矩阵:
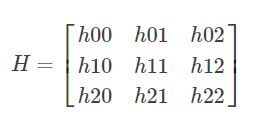
两张图间的H映射关系就可以表示成

opencv中findHomography只需要输入点对,以及基于点对的位置投影矩阵计算方法,就能求出H。
CV_EXPORTS_W Mat findHomography( InputArray srcPoints, InputArray dstPoints,
int method = 0, double ransacReprojThreshold = 3,
OutputArray mask=noArray(), const int maxIters = 2000,
const double confidence = 0.995);
- 0 - 使用最小化投影误差
- RANSAC - 基于RANSAC的鲁棒性方法
- LMEDS - Least-Median robust method
- RHO - PROSAC-based robust method
如果参数method设置为默认值0,该函数使用一个简单的最小二乘方案来计算初始的单应性估计。
然而,如果不是所有的点对(srcPoints,dstPoints)都适应这个严格的透视变换。(也就是说,有一些异常值),这个初始估计值将很差。在这种情况下,我们可以使用两个鲁棒性算法中的一个。RANSCA和LMEDS这两个方法都尝试不同的随机的相对应点对的子集,每四对点集一组,使用这个子集和一个简单的最小二乘算法来估计单应性矩阵,然后计算得到单应性矩阵的质量quality/goodness。(对于RANSAC方法是内层围点的数量,对于LMeDs是中间的重投影误差)。然后最好的子集用来产生单应性矩阵的初始化估计和inliers/outliers的掩码。
RANSAC方法,几乎可以处理任含有何异常值比率的情况,但是它需要一个阈值用来区分inliers和outliers。LMeDS方法不需要任何阈值,但是它仅在inliers大于50%的情况下才能正确的工作。最后,如果你确信在你计算得到的特征点仅含一些小的噪声,但是没有异常值,默认的方法可能是最好的选择。(因此,在计算相机参数时,我们或许仅使用默认的方法)
6、示例
用ORB特征点方法做目标识别的前提是待识别目标需要有丰富的特征点。ORB入门级特征点检测匹配方法代码如下,img_1表示目标物体obj需要提取特征点的图像,img_2表示场景照片scene需要提取特征点的图像;步骤往往是特征点KeyPoint与描述值descriptors的提取,特征点匹配,判断是否有匹配,显示匹配,计算变换矩阵并且绘制匹配位置。
// load obj and scene
Mat img_1 = imread("../PicProcess/query.bmp", IMREAD_COLOR); // guery image
Mat img_2 = imread("../PicProcess/train.bmp", IMREAD_COLOR); // train image
// initialize
vector keypoints_1, keypoints_2;
Mat descriptors_1, descriptors_2;
Ptr orb = ORB::create(500, 1.2f, 8, 31, 0, 2, ORB::HARRIS_SCORE, 31, 20);
// step1: detect Oriented FAST
orb->detect(img_1, keypoints_1);
orb->detect(img_2, keypoints_2);
// step2: computer descriptors
orb->compute(img_1, keypoints_1, descriptors_1);
orb->compute(img_2, keypoints_2, descriptors_2);
// step3: descriptor match using Hamming Distance
vector matches;
BFMatcher matcher(NORM_HAMMING);
matcher.match(descriptors_1, descriptors_2, matches);
// step4: select max and min distance, and define the good match
double min_dist = 10000, max_dist = 0;
for (int i = 0; i < descriptors_1.rows; i++)
{
double dist = matches[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
vector good_matches;
for (int i = 0; i < descriptors_1.rows; i++)
{
if (matches[i].distance <= max(2 * min_dist, 30.0))
{
good_matches.push_back(matches[i]);
}
}
//step5: draw match and good_match
Mat img_match;
Mat img_goodmatch;
drawMatches(img_1, keypoints_1, img_2, keypoints_2, matches, img_match);
drawMatches(img_1, keypoints_1, img_2, keypoints_2, good_matches, img_goodmatch);
// step6: compute Homography
vector obj, scene;
for (unsigned int i = 0; i < good_matches.size(); ++i)
{
obj.push_back(keypoints_1[good_matches[i].queryIdx].pt);
scene.push_back(keypoints_2[good_matches[i].trainIdx].pt);
}
估计Two Views变换矩阵
Mat H = findHomography(obj, scene, CV_RANSAC);
vector obj_corners(4), scene_corners(4);
obj_corners[0] = cvPoint(0, 0);
obj_corners[1] = cvPoint(img_1.cols, 0);
obj_corners[2] = cvPoint(img_1.cols, img_1.rows);
obj_corners[3] = cvPoint(0, img_1.rows);
perspectiveTransform(obj_corners, scene_corners, H);
Mat show_match;
line(img_goodmatch, scene_corners[0] + Point2f(img_1.cols, 0), scene_corners[1] + Point2f(img_1.cols, 0), Scalar(0, 255, 0), 4);
line(img_goodmatch, scene_corners[1] + Point2f(img_1.cols, 0), scene_corners[2] + Point2f(img_1.cols, 0), Scalar(0, 255, 0), 4);
line(img_goodmatch, scene_corners[2] + Point2f(img_1.cols, 0), scene_corners[3] + Point2f(img_1.cols, 0), Scalar(0, 255, 0), 4);
line(img_goodmatch, scene_corners[3] + Point2f(img_1.cols, 0), scene_corners[0] + Point2f(img_1.cols, 0), Scalar(0, 255, 0), 4);
效果图:

网上的效果图:

参考文章:
1、https://blog.csdn.net/yuan1125/article/details/73381287
2、https://www.douban.com/note/605819823/
3、https://www.cnblogs.com/wangguchangqing/p/8076061.html