
近期举办的 2022 第四届实时计算 Flink 挑战赛中,在各位大佬的指导下,完成了本课题的设计和实践,现在把本方案的设计思路分享给大家,希望通过本次经验分享可以为其它企业带来一点实时数据使用的新思路。
众所周知,实时数仓落地是一个难点,尤其是金融行业,还没有出现真正所谓的实时报表。金融行业个别案例的实时数仓是在较窄场景、较多限制下的尝试,还不能够称之为实时数仓,如银行普遍的实时报表业务都无法满足。当前亟需设计实现一套能够落地的金融行业的实时报表方案,来满足业务场景对数据时效性越来越高的需求。
本文内容首先介绍了银行业常见的实时场景和解决方案,然后针对银行业报表依赖维度表计算的特点,提出了基于 Flink Table Store 作为数据存储,进而构建流式数仓的解决方案。
在正式开始之前呢,简单介绍一下中原银行的基本情况。中原银行是河南全省唯一的省属法人银行,总资产突破 1.2 万亿,在国内城市商业银行排名第 8 位。本团队是负责中原银行的实时计算业务,包括实时的采集、加工和分析全链路。
一、金融行业实时数仓现状分析
1.1 动账场景介绍

数仓建模有范式建模和维度建模,银行业采用的是维度建模,其中分为事实表和维度表。
事实表:刻画行为的,一般用来统计交易笔数,交易金额,业务量等。
维度表:描述结果和状态的,常见的用户手机号、身份证号、所属的机构等不经常更新的数据,但其中银行业比较重要的有“账户余额”,客户余额会随着动账交易而频繁更新。

本文以银行典型的动账场景为例,一次动账操作其实是一个事务,至少操作两张表,第一张比较好理解,就是交易流水表,记录转账的一次行为;第二张则是用户的属性表,其中有一个字段是用户的余额,需要随着动账的交易流水表同步更新,上面的两个表是两次转账的示例。

在这个转账场景下进行分析
- 流水表的特点:主要是 Insert 操作,记录行为信息,适合增量计算,如统开户、取款、贷款、购买理财等事件行为。
应用的场景有实时营销,如大额动账提醒,工资代发,理财产品购买等;实时反欺诈的申请反欺诈、交易反欺诈;在贷后管理也有应用,如监控用户入账行为,提供给零贷贷后临期催收、扣款等。
- 客户属性表的特点:主要是 Update 操作,记属性信息,客户的存款、贷款、理财、基金、保险等产品的余额是在维度表中,所以常使用维度表全量计算资产信息,如资产余额类的计算,计算某分支行的总存款余额等。
应用的场景主要是实时报表、实时大屏:如对公 CRM、零售 CRM;经营管理;资产负债管理等。
针对于银行业这两种典型的动账场景,有三种解决方案。下面逐个介绍不同方案适用的场景和有哪些局限。
1.2 基于 Kafka 的 ETL

该架构能够解决的问题,大多是基于事实表的增量计算,已经在行内有大量的落地案例,但无法解决银行业的基于维度表的全量计算。另外该方案很难形成规模化的数据分层复用,Kafka 存在数据无法查询和长期持久化等问题。这种烟囱式的 case by case 开发阶段,本行已经经历过了,生产上也有大量的落地场景,实时任务达到了 300+个。
1.3 基于微批的 ELT

为了解决银行业大量基于维度表的统计分析场景,来看一下进行了哪些方式的探索。总结来说,是一种先载入后分析,也就是 ELT 的方式。过程是这样的,先实时采集-> 然后直接实时载入->最后在实时 OLAP 查询阶段进行逻辑的加工。
在ELT探索的的初期,我们采用过微批全量计算的方式,在数据实时地写入到数据库后,定时执行全量加工逻辑,类似于离线数仓有跑批的概念,只不过每天跑批缩短到了小时级别或分钟级别跑一次批,来达到准实时加工的效果。显而易见,这种方式是不可取的,存在时效性差、跑批不稳定等问题。
1.4 基于视图的 ELT

随着 MPP 数据库的发展,查询性能得到了极大的提升,本行使用 StarRocks 引擎,通过 View 视图嵌套加工逻辑的方式也进行了探索,也就是把业务数据库的数据以 CDC 方式,载入 MPP 数据库的明细层,查询分析逻辑使用 View 封装,在查询触发时直接计算,这种方式也可以解决基于维度表的全量计算,但每次查询资源消耗太大,支撑大数据高频率的查询操作比较困难,无法大范围应用推广。
1.5 动账场景总结
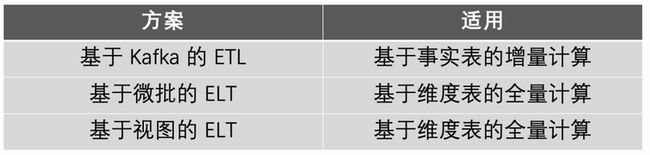
基于事实表的增量计算已经在生产进行了大量的落地和实践,本文主要是讨论银行业基于维度表的全量计算场景,上述两种解决方案虽然能够解决一部分实时场景,但局限很大,当前阶段来到了优化升级和未来方向选择的节点。
为了解决银行业基于维度表的实时 OLAP,必须把部分计算向前移动,在 Flink侧计算。湖存储 Flink Table Store 的出现,使基于维度表的全量计算成为了可能。也就是底层一部分转化工作在Flink中计算,另一部分聚合计算等工作在 OLAP 数据库中计算,两者分摊一下计算时间和资源消耗。在未来,还是希望把全部加工逻辑,全部在Flink端分层完成,向着存算分离、流批一体的流式数仓方向发展。
二、基于 Flink Table Store 的金融行业流式数仓
2.1 Flink Table Store 介绍

2022 年发布的 Flink Table Store,能够很好地解决之前遇到的大量数据更新、全量存储等问题,Table Store 是一个统一的存储,用于在 Flink 中构建流式处理和批处理的动态表,支持高速数据摄取和快速的数据查询。
- 是一种湖存储格式,存储和计算分离,导入数据时双写到数据文件和日志系统。
- 支持流批写入、流批读取,支持快速 Update 操作。
- 还支持丰富的 OLAP 引擎,Hive、Trino 等,当前 StarRocks 也在支持湖存储查询分析,相信在不久的将来,StarRocks 也是能够支持查询 Flink Table Store。
了解详情,请移步到官网:https://nightlies.apache.org/flink/flink-table-store-docs-release-0.2/
2.2 导入数据

在银行业,业务数据库仍然是以 Oracle 为主,全量数据初始化到 Flink Table Store 中,使用的 Oracle Connector 需要开发才能使用,同时需要支持 Filter、Project 等操作。采用 JDBC 连接以流式读取数据库的方式进行全量写入到 Flink Table Store 中,同时在建表配置项中配置 changelog-producer = input,保存完整的 changelog,为后续流写和流读作准备。

在完成了全量数据的初始化,后续增量的更新数据需要持续地写入到 Flink Table Store 中,首先从 Oracle 中把数据实时地抽取出来,以 JSON 格式写入到 Kafka,供后续多个场景复用 Topic。在银行业,数据库管理较为严格,能够实时获取业务数据比其它行业要解决更多方面的困难。下面模拟一下动账过程:
- 客户表初始状态为客户 1、2、3 的余额分别为 100、200、300。
- 客户 1 转入 100 元,则客户表执行 Update 操作,使客户 1 的余额从 100 -> 200。
- 客户 2 转出 100 元,则客户表执行 Update 操作,使客户 2 的余额从 200 -> 100。
- 数据库的 Update 操作,使用 CDC 工具把 changelog 信息以 json 格式写入到 Kafka 队列。后续启动 Flink SQL 任务消费 Kafka,将 changelog 流写入到 Flink Table Store 中。

在拿到增量的 CDC 数据后,需要把增量更新数据和历史全量数据进行融合,才能够得到完整最新的全量数据。这里有两个问题需要探讨:
第一:全量数据和增量数据为什么分开写入呢?
- 避免实时数据抽取多份,统一写入 Kafka,后续多个实时场景可以复用;
- 离线数据全量初始化可能是一个经常性的操作,比如每周进行一次全量的初始化。
第二:全量数据和增量数据如何保证衔接正确呢?
- 维度表常规情况下是有主键的表,这样就能够保证有幂等的特性,只需要保证增量数据早于全量数据就行了。比如增量数据5点开始启动写入到 Kafka,全量数据 6 点开始全量同步,增量写入任务在全量同步结束后开始指定早于 6 点的数据开始消费就可以保证数据的完整性了。
另外在写入 Flink Table Store 时需要配置 table.exec.sink.upsert-materialize= none,避免产生 Upsert 流,以保证 Flink Table Store 中能够保存完整的changelog,为后续的流读操作做准备。
2.3 查询数据

第一种方式,Batch模式。
历史存量和实时写入的数据,均能够在线 OLAP 分析。支持流写批读,Batch 模式读取数据是从 Snapshot 文件中读取,checkpoint interval 周期内可见。支持多种查询引擎 Hive、Trino、Flink SQL 等,全局有序 Sorted File 的 Data Skipping,Sort Aggregation and Sort Merge Join 特性等。
这里可以任意时间查看各个分支行的存款余额,或者分析客户的明细信息等。

第二种方式,Streaming 模式。
以 Streaming 模式启动查询时,任务会持续在线运行,当客户 1 进行转账操作时,如转入 100 元,变成了 200 元。此时在实时数仓发生的过程如下:

这个过程有如下特点:
- 流批统一。存储统一,Snapshot+Log,存量数据读取 Snapshot,增量数据读取 changelog,hybird 读取全量实时数据。查询统一,离线和实时使用相同的 SQL 语句。Streaming 模式开启 mini-batch 减少聚合语句的冗余changelog 输出。
- 减少物化。FTS 中有完整的 changelog,避免 Flink State 中生成物化节点。
- 时延较低。changelog 使用 File 存储,代价低,时延高;使用 Kafka 存储,代价高,时延低。
- 数据驱动,而不是时间调度驱动或者查询时才开始触发计算。
2.4 导出数据

最终的结果数据,如果查询频率不高,可以直接使用 Flink 1.16 提供的 SQL Gateway 功能;如果查询频率较高,可以再以流式写出到外部的数据库中,提供稳定的在线服务能力。
2.5 未来发展

实现真正端到端的流式数仓,既能够支持实时数据和完整的 changelog,也支持批量导入离线数据,当数据在源头发生变化时就能捕捉到这一变化,并支持对它做逐层分析,让所有数据实时流动起来,并且对所有流动中的数据都可以实时查询,是以纯流的方式而不是微批的方式流动。在这个过程中,数据是主动的,而查询是被动的,分析由数据的变化来驱动。
数仓的分层可以解决实时数据的复用,多指标随着数据的实时流动而实时变化,从另一种角度说也是在用空间换取时间。离线数据和实时数据共同存储在 Flink Table Store 中,使用廉价的存储和存算分离更加灵活的进行弹性计算。离线分析 sql 和实时分析 sql 式完全一样的,最终达到流批一体的效果。总结如下:
- 存算分离的湖存储,FTS 提供完善的湖存储 Table Format,提供准实时 OLAP 分析。
- 能够存储全量数据,每层数据能够可查,支持 Batch 和 Streaming 两种模式。
- 支持大量数据更新,有序的 LSM 结构,支持快速的 Update 操作。
- 支持流批写流批读,尤其是能够流式读取,流式数据从 Log System 中读取。
- 完整的 changelog,支持全部流程传递完整的+I、-U、+U、-D 操作,减少 Flink State 中的物化节点。
- 真正实现流批一体,流批统一 Flink SQL,流批统一存储。
那为什么不直接采用这种架构进行构建呢?当前阶段这个架构还无法完全落地,比如其中聚合计算有大量的撤销动作、多个层之间的实时数据流动需要大量的资源和调试技能等,不过随着技术的发展,相信流式数仓一定会到来。
2.6 流式数仓落地进展

当前阶段,既然多层的流式数仓落地还有一定的距离,那么在加入 Flink Table Store 后,在原有 ELT 架构的基础上,进行优化升级,看看带来了哪些变化。
在整个计算过程中,直接把原始数据写入 Flink Table Store,使之存储历史全量和实时更新的表数据,然后计算逻辑使用 Flink SQL 实现,最后把初步汇总的数据写入到 StarRocks 中。原始明细数据在 Flink 中计算,极大的减少了 StarRocks 的计算逻辑,Flink 和 OLAP 引擎两者协调配合,共同提供端到端的实时报表业务。这种架构在我们在生产上也已经行进了初步的尝试,效果非常显著。
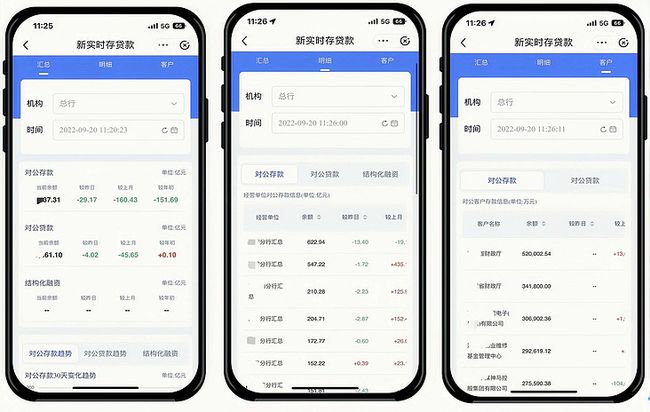
以对公 CRM 实时存贷款场景为例,该功能显示全行、分支行的实时存贷款情况。旨在为业务人员及客户经理提供一个可以随时查看行内总/分/支行及客户的存贷款等重要业务指标变化情况的功能,从而时刻掌握行内资产最新状况。
扫码进入赛事官网了解更多信息:

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算Flink版现开启活动:
99 元试用 实时计算Flink版(包年包月、10CU)即有机会获得 Flink 独家定制卫衣;另包 3 个月及以上还有 85 折优惠!
了解活动详情:https://www.aliyun.com/produc...
