【Python】快速入门
目录
基础储备
Python输出:
Python换行:
Python命名规则:
Python变量:
Python运算:
Python注释:
小点:
Python的两种模式:
Python的用户问答互动程序:
Python条件语句
Python的逻辑运算:
Python列表
Python字典
循环
Python for循环
Python While循环
Python格式化字符串
Python 函数的定义
Python引入模块
面向对象
Python的面向对象编程
Python类的继承
文件
Python文件路径
Python的文件操作
基础储备
Python输出:
可以用单引号把内容引起来,也可以用双引号;
不同字符串之间可以直接用加号连接;
单引号和双引号会自动配对;有歧义时记得用转义字符
print('你好'+"是我呀!")Python换行:
(1)需要换行的内容后面加上“\n”;
(2) 内容前后各用三个单引号(双引号也没问题)引起来,内容里的换行写的内容,也会在输出时自动换行,不需要写“\n”;
eg:
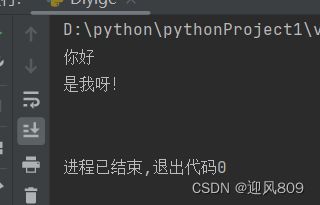
print("""你好
是我呀!
""")运行结果为:
Python命名规则:
(1)下划线命名法:字母全部小写,不同单词之间用下划线连接;eg:use_name;
(2)驼峰命名法:首字母大写,不同单词之间首字母大写;eg:UserName;
Python变量:
不需要定义类型,可以作为已知变量在初始化后,直接使用。
Python运算:
(1)允许除法两边为整数,eg:1/2=0.5;
(2)乘方表示为两个星号;eg:2**3=8;
(3)运用math库里的函数时,需要导入math库,即在第一行添加:import math
另外,在使用数学库里的函数之前需要加上math.
eg: math.log2(8)=3; math.sin(1)
Python注释:
单行注释:每行之前加 “#”,快捷键是:选中需要注释的段落,按ctrl+/;取消的方式是重复上述操作;
多行注释:在需要注释的内容前后,分别加上三个双引号;
小点:
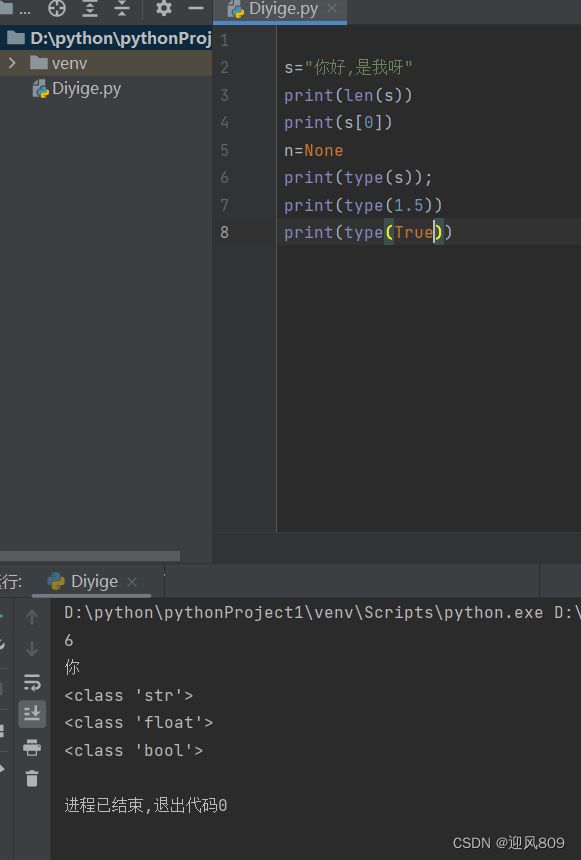
(1)len(),可以获得字符串的长度,但是用在数字上就会报错;
(2)"hello"[3]=l ; 下标为01234;
(3)空值类型 NoneType ,表示完全没有值,不是空格,不是0,也不是空"";
定义某个变量为None eg:n=None
(4)type()返回数据的类型,eg:type("Hello")
(5)int()用于强制类型转换,把字符串中的数字变成整型数字,所以原字符串里不是数字时,不能进行转换,会报错
(6)连在一起的两个除号是除完再取整的意思,即 3 / 2 = 1.5 , 3 / / 2 = 1 ;
Python的两种模式:
命令行模式和交互模式
(1)命令行模式:写好命令后,保存并运行整个文件。运行时,解释器一行一行对文件进行解析和执行。
(2)交互模式:输入一行,显示一行结果
优点1:不需要创建任何Python文件就可以运行
优点2:不需要用print()就可以看见返回结果
原因:交互模式里的命令不会被保存。一旦退出,所有键入的内容都不会保存。
Python的用户问答互动程序:
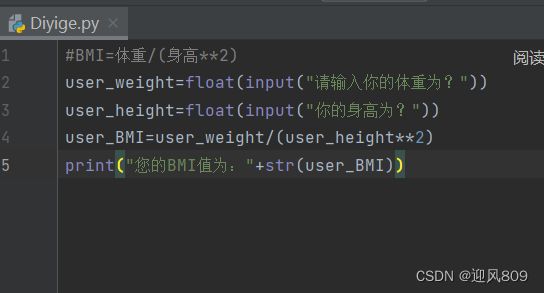
字符串和数字不能相连,当数字需要和字符串相连时,要把数字转换为字符串,用str();
当字符串转换为数字时,前提是字符串本身能转换为数字,比如“8”这个字符串,用int();
eg:int("9")
Python条件语句
(1)单个判断
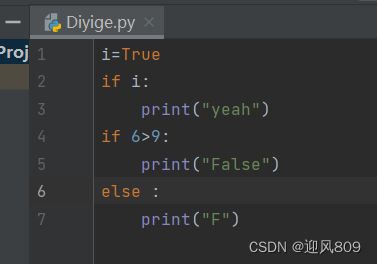
冒号和缩进!
如果条件成立需要执行的代码不止一句,可以在下一行同样缩进,会被认为是同一个判断需要执行的内容;
默认缩进四个空格;
当字符串和数字进行比较时,不要忘了转换。(同上)
(2)嵌套判断
根据缩进判断语句属于哪个分支;
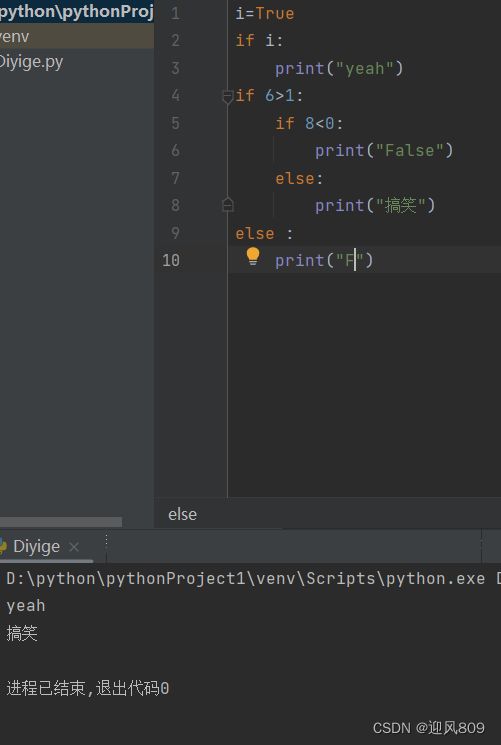
(3)多个条件判断
中间多个条件用 elif [条件]: 连接;
且数学里的左右两边同时有不等式的形式Python仍可以用.
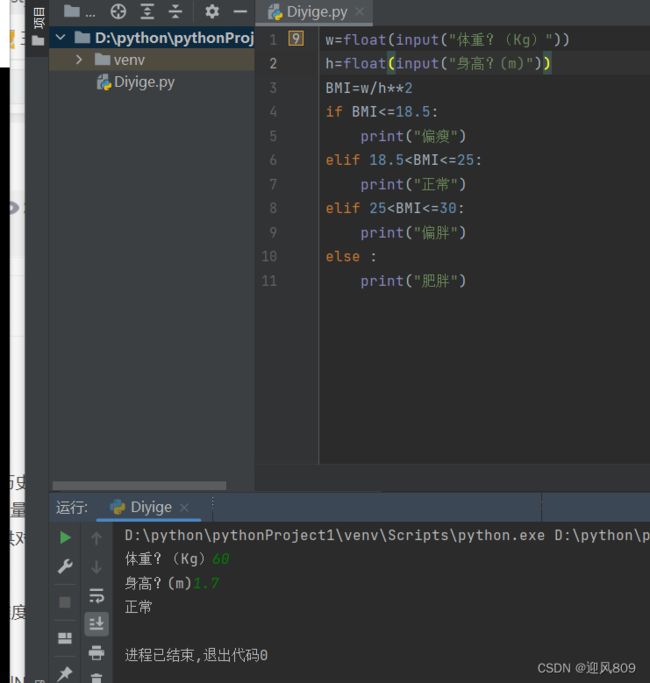
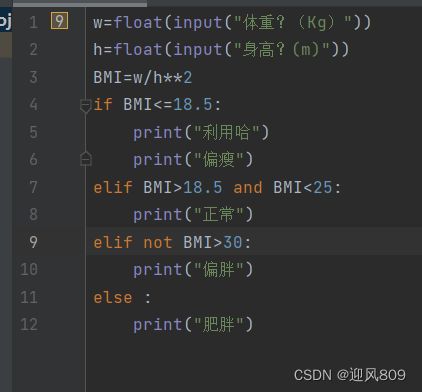
Python的逻辑运算:
(1)逻辑与:and,
(2)逻辑或: or
(3)逻辑非:not
优先级:not>and>or
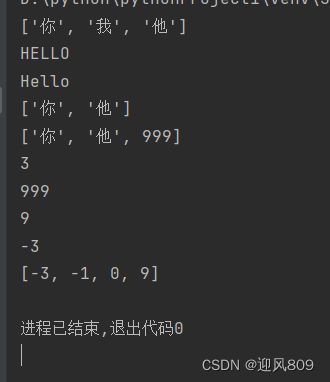
Python列表
#列表
list=["你","我"]
#添加。调用方法,对象.方法名();调用函数,函数名(对象)
list.append("他")
print(list)
#列表是可变的,但是基本数据类型不是
s="Hello"
print(s.upper())
print(s)
#删除,要求需要删除的元素确实在列表里存在
list.remove("我")
print(list)
#列表里可以放不同元素的数据
list.append(999)
print(list)
#len()求长度
print(len(list))
#可以直接利用索引查找元素
print(list[2])
num_list=[0,-1,9,-3]
#内置函数
print(max(num_list))
print(min(num_list))
print(sorted(num_list)) #升序排列
Python字典
#键-值对;空的字典:contacts={}
#键值之间用冒号分隔
#注意:键的类型必须是不可变的,所以不能是列表
contacts={"小明":"199999",
"小花":"188888"}
#获取某个键的值:
contacts["小明"]
#元组 tuple。不可变但是很像列表的数据结构,区别是,元组用圆括号,中间同样可放多个元素
#由于元组不可变,添加删除等操作都不可进行
tuple1=("你","我")
#添加键对,(当该键在字典中不存在时产生添加功能),如果键本身存在,发生覆盖
contacts["美女!"]="1987"
print(contacts)
#键 in 字典,会返回一个bool值
print("小明" in contacts)
print("我呀" in contacts)
#删除一个键值对用del,若想删除的键本身不存在就会报错
del contacts["小明"]
print(contacts)
#len()可用于求字典中的元素个数
print(len(contacts))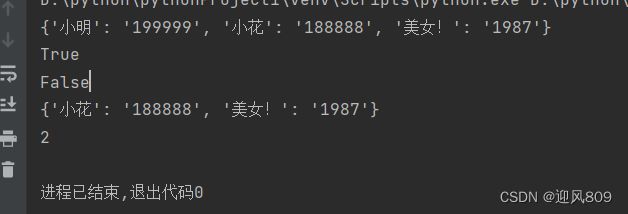
循环
Python for循环
格式:
for 变量名 in 可迭代对象
#对每个对象做的事情
(1)字典名.keys() #返回所有键
(2)字典名.values() #返回所有值
(3)字典名.items() #返回所有键值对
for结合items()时,变量会被赋值为键和值组成的元组
(4)for循环结合range()
range表示整数序列。
range(5,10) #第一个元素表示起始值,第二个元素表示结束值(!该值不在序列的范围内)
range(1,10,2) #第三个元素表示步长,就是每次跨几个数字,不指明的时候默认为1。
#(1)for与列表
list=[39.6,34,37,38]
for temperature in list:
if temperature >=37:
print(str(temperature)+"完蛋了")
#(2)for与元组
list2={"对象1":39.8,"对象2":37.9,"对象3":40}
#相当于把键赋值给it,值赋值给wd
for it,wd in list2.items():
if wd>=38 :
print(it+"发烧了")
"""
相当于:
for tuple in list2.items():
it=tuple[0]
wd=tuple[1]
if wd>=38:
print(it+"发烧了")
"""
#(3)for与range()
for i in range(5,10):
print(i)
for i in range(1,10,2):
print(i)
total=0
#计算1+2+3+...+101
for i in range(1,101):
total+=i
print(total)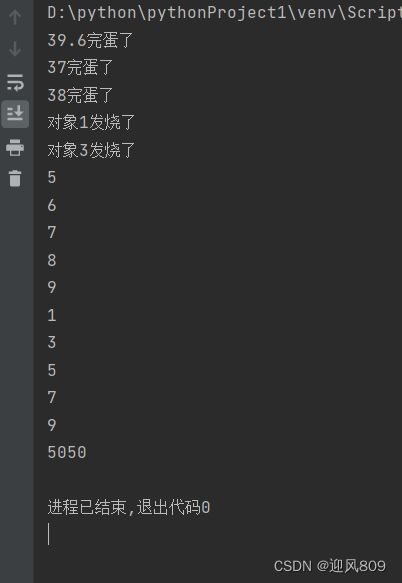
Python While循环
语句模式:
While 条件:
行动
list1=["你","好","吗","兄","弟"]
#for循环实现
for it in list1:
print(it)
#for+range()实现,it表示下标数字,在本循环内可自加,起始值默认为0
for it in range(len(list1)):
print(list1[it])
#while 循环实现
i=0
while i 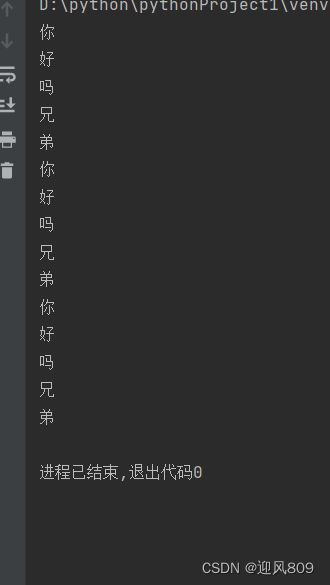
在有明确循环次数时,常用for;在循环次数未知时,常用while
Python格式化字符串
实现一:
(一)format 方法
(1)根据字典序(即位置)。花括号表示被替换的位置,里面的数字表示会用format里的第几个参数进行替换。{0}表示format中的第一个参数,{1}表示第二个参数
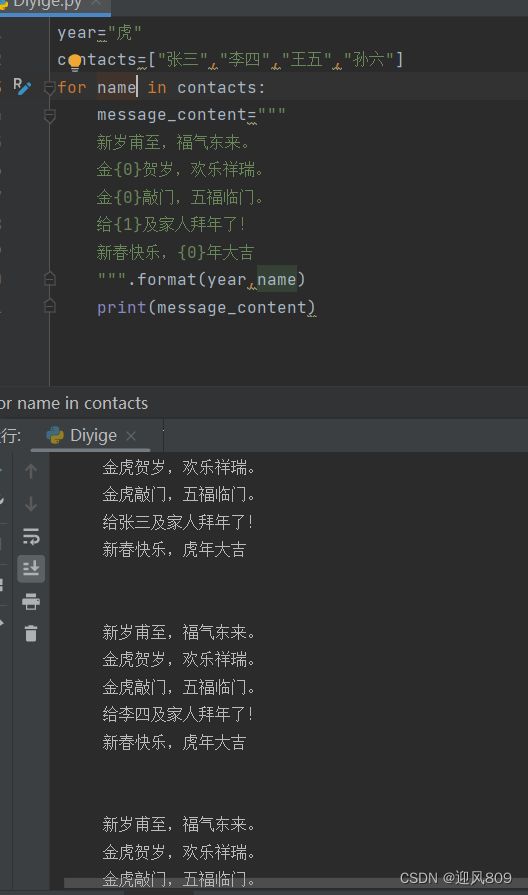
(2)根据关键字指定进行替换的对象,format里的参数位置就不用在意了。
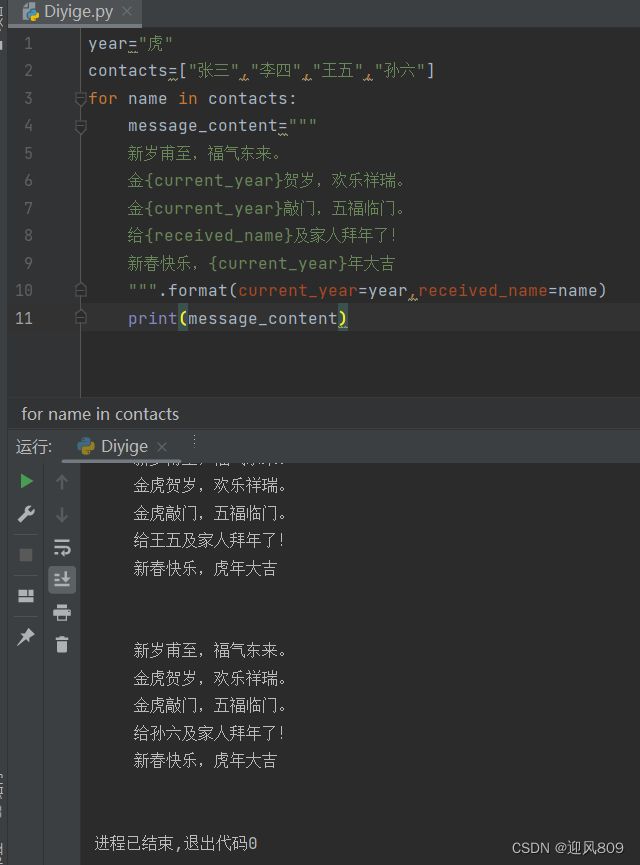
(3)参数名可以重复用到字符串里。分清:等号前面的是关键字,对应花括号里面的关键字;后面的是参数值
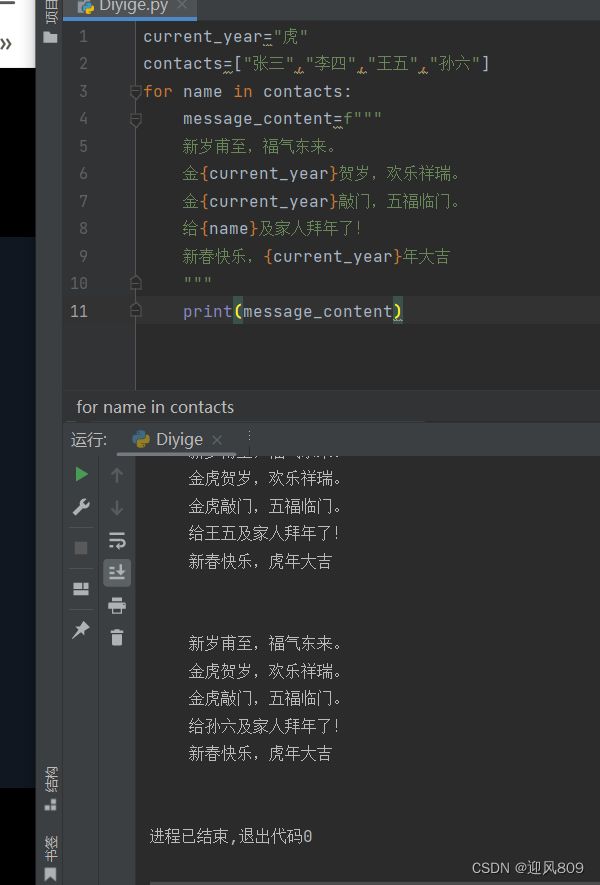
(二)f-字符串
在字符串前加前缀f,花括号会被直接求值,带入变量本身的值
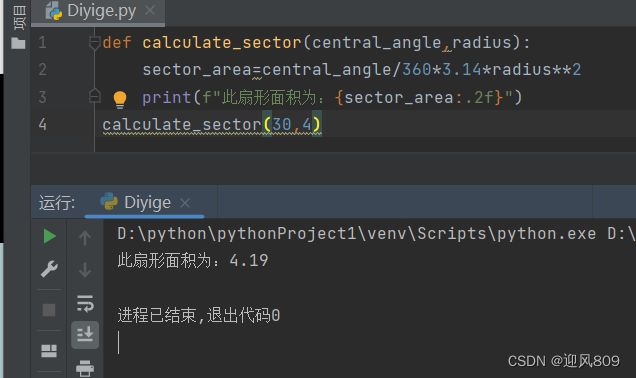
(三)用数字对字符串进行格式化
Python 函数的定义
def 函数名 (参数列表):
#定义函数的代码:
未写返回语句时,默认函数返回为return None
(print()、.append()的语句,默认返回值为None)
Python引入模块
(1)import 语句
import 模块名
模块名.函数名()
模块名.变量名()
(2) from...import... 语句
from 模块名 import 函数名(或者变量名),函数名
优点:调用时不用写模块名
(3) from...import.*.. 语句
把模块里面所有内容都进行引入,使用时,都不需要在前面加上模块名了
但是不推荐,因为可能会有命名冲突
#import 语句
import statistics
print(statistics.median([0,9,-5,7,2]))
print(statistics.mean([-9,8,9]))
#from...import..语句
from statistics import median,mean
print(median([2,6,7,8,9]))
#from 模块 import *
在Pycharm里按住ctrl,点击函数名,就可以看到别人写的函数源代码
(4)使用第三方模块的时候,需要先从互联网上安装,然后再用import引入
pypi.org这个网站可以对第三方库进行搜索
安装的话,到终端,输入pip install 再加上库的名字
面向对象
Python的面向对象编程
(一)定义类名,命名风格:
(1)下划线命名法,user_name
适用于变量名
(2)Pascal命名法
适用于类名,eg:UserAccount
(二)定义构造函数
self 可以把属性值绑定到对象自身上,调用构造函数时,不需要手动传入self的值
calss CuteCat:
#默认构造函数,第一个参数约定为self,表示参数自身。注意!init前后都是两个下划线组成的
def __init__( self )
self.name=None
def __init__(self , cat_name):
self.name=cat_name
(三)定义方法
第一个参数值为self,作用:可以获取或修改和对象绑定的属性
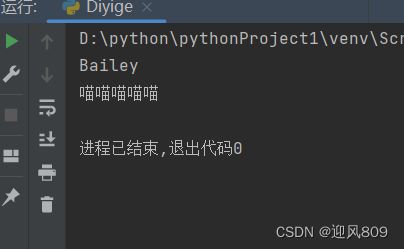
class CuteCat:
def __init__(self):
self.name='Bailey'
self.age=5
def speak(self):
print("喵"*self.age)
cat1 =CuteCat()
print(f"{cat1.name}")
cat1.speak()
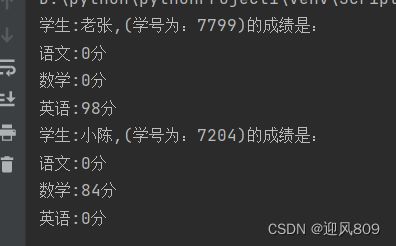
class Student:
def __init__(self,name,id):
self.name=name
self.id=id
self.grade={"语文":0,"数学":0,"英语":0}
def set_grade(self,course,grades):
if course in self.grade:
self.grade[course]=grades
def print(self):
print(f"学生:{self.name},(学号为:{self.id})的成绩是:")
for it in self.grade:
print(f"{it}:{self.grade[it]}分")
chenmou=Student("小陈","7204")
zhangnn=Student("老张","7799")
chenmou.set_grade("数学","84")
zhangnn.set_grade("英语","98")
zhangnn.print()
chenmou.print()
Python类的继承
在类名后加括号(),里面写上父类的名字
class Human(Mammal):
#类内的方法
class Mammal:
def __init__(self,name,sex):
self.name=name
self.sex=sex
self.num_eyes=2
def breathe(self):
print(f"{self.name},在呼吸")
def poop(self):
print(self.name+"在拉屎")
class Human(Mammal):
def __init__(self,name,sex):
super().__init__(name,sex)
def read(self):
print(self.name+"在阅读")
chenmou=Human("小陈","男")
chenmou.read()
chenmou.poop()
文件
Python文件路径
(1)绝对路径
以 / 开头,路径中的每个目录之间用 / 进行分隔,最后以目标文件或者目标目录结尾
Windows系统下,以区名加 / 开头,其余同上
eg:C:\Users\admin
(2)相对路径
从一个参考位置出发,从该位置看,其他文件属于什么路径
用 . 表示相对文件所在的目录,父目录用.. ,在往上用..\..(Windows下是\,Unix用/)
往下走,用./data ./data/a.py等描述;./可以省略,用文件名加/ eg:data/pp
Python的文件操作
#括号内的是(文件路径,文件操作,编码方式),用此编码方式来读取值
#open函数执行成功会返回一个文件对象,可以对他进行操作
#(1)read方法,一次性读取文件里的所有内容,并已字符串的形式进行返回
file=open(".\就是你.txt","r",encoding="utf-8")
print(file.read(6))
file.close()
#再次调用read时,返回为空,会读空字符串并打印,因为之前已经读到文件结尾了
#!在文件特别大的时候不要用read,会占很大的内存
#!可以给read()里传一个数字,表示读取多少字节,再次执行该语句,会接着上次的位置往下读
#!读的时候换行符也被读进去了,算一个字节
#(2)readline(),每次读取一行。根据换行符判断本行结尾。
#!读的时候换行符也被读进去了,算一个字节,当作内容的一部分
#当读到文件结尾时,会返回空字符串,可用做文件读取结束的判断。同上。
#
f=open(".\就是你.txt","r",encoding="utf-8")
line=f.readline()
while line!="":
print(line)
line=f.readline()
# (3)readlines()会读取全部文件内容,并返回由每行组成的字符串列表
#
kk=open(".\就是你.txt","r",encoding="utf-8")
K=kk.readlines()
for line in K:
print(line)
encoding默认是跟随系统的