CVPR 2021 | 基于模型的图像风格迁移
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:侯云钟 | 已授权转载(源:知乎)
https://zhuanlan.zhihu.com/p/371101640
本文从另外一个角度解读,澳洲国立大学郑良老师实验室CVPR 2021新工作《Visualizing Adapted Knowledge in Domain Transfer》。一般而言,我们需要同时利用 两张图片 完成图像的风格迁移(style transfer):一张图片指导内容(content);一张图片指导风格(style)。在本文中, 我们探寻如何在仅利用一张图片作为内容指导的情况下,通过训练好的模型作为指导,将该图片迁移至一种未曾见过的风格。我们首先展示一些示例结果,如下图,在只利用目标(target)图片的情况下,我们可以将其有效迁移至未曾见过的源(source)图片风格。
 基于模型的图像风格迁移。在没有利用源图片(c)作为图像风格指导的情况下,我们仅利用目标图片(a),即可将其迁移至源域风格(b)。
基于模型的图像风格迁移。在没有利用源图片(c)作为图像风格指导的情况下,我们仅利用目标图片(a),即可将其迁移至源域风格(b)。
题目:Visualizing Adapted Knowledge in Domain Transfer
论文地址:https://arxiv.org/abs/2104.10602
作者:Yunzhong Hou, Liang Zheng
代码:https://github.com/hou-yz/DA_visualization
基于图片的图像风格迁移
不论是风格迁移(style transfer)还是图像变换(image translation)工作,想要在保持图片内容的条件下变换图像的风格,都需要同时利用两张图片:一张图片 指示内容;一张图片 指示风格。此外,它们还需要一个特定的评价网络 ,来推动图像风格的变换。在风格迁移中(如neural style transfer [1]), 可能是ImageNet预训练VGG的特征分布;在图像变化中(如cyclegan [2]), 可能是两个域分别对应的判别器网络(discriminator)。
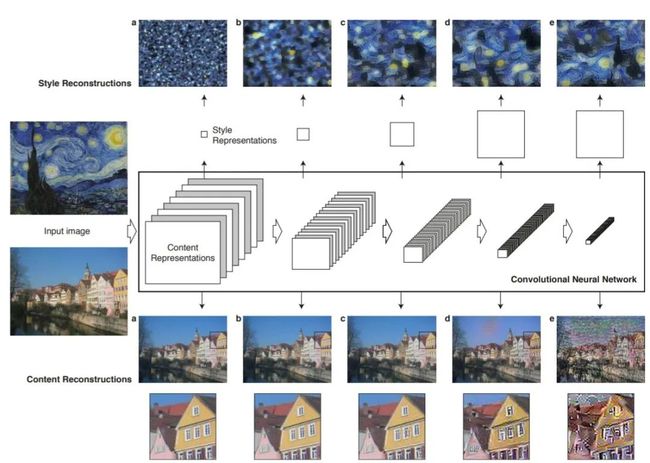 neural style transfer [1] 利用内容图像、风格图像、和基于ImageNet预训练的VGG的评价网络
neural style transfer [1] 利用内容图像、风格图像、和基于ImageNet预训练的VGG的评价网络 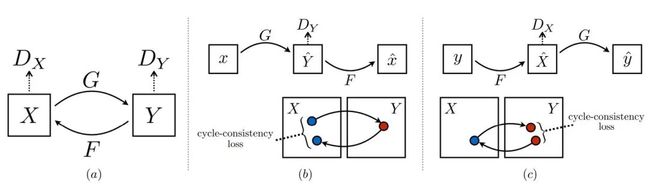 cyclegan [2] 利用内容图像数据集、风格图像数据集(两者互易)、和判别器形式的评价网络
cyclegan [2] 利用内容图像数据集、风格图像数据集(两者互易)、和判别器形式的评价网络
对于传统的风格迁移,可以形式化的记为 ,其中 为生成图片, 分别代表风格图像和内容图像, 代表某一特定评价网络。
基于模型的图像风格迁移
在本文中,不同于两张图片,我们利用训练好的两个模型,来指导图像的风格迁移。特别的,我们考虑域迁移(domain adaptation)的任务情景:给定源域(source domain)和目标域(target domain),以及训练好的适用于源域的网络 和适用于目标域的网络 ,且默认这两个网络共享分类层 (域迁移中常见设置)。
 域迁移:可以得到分别适用于源域和目标域的两个神经网络模型,以此推动图像风格迁移
域迁移:可以得到分别适用于源域和目标域的两个神经网络模型,以此推动图像风格迁移
基于这两个网络,我们探寻能否将目标域图像直接迁移至源域风格。我们可以进一步给出任务目标的形式化定义 ,其中图片 指导生成图片 的内容。对比传统的图像风格迁移 ,基于模型的风格迁移存在以下区别:
不能基于 内容-风格 图像对 训练,而是凭借源域模型 和目标域模型 指导图像风格差异;
风格迁移的标准不依赖于特定的评价网络 ,而仍是依赖源域模型 和目标域模型 。
Source-Free Image Translation 方法
面对基于模型的风格迁移目标 ,我们设计了一套方法,完成基于模型的图像风格迁移任务。特别的,我们只利用目标域图片 作为内容指导(即作为 ),而完全避免在图像迁移的过程中利用源域图片 。由此,我们的方法也得名source-free image translation(SFIT),即不依赖源域数据的图像风格迁移。
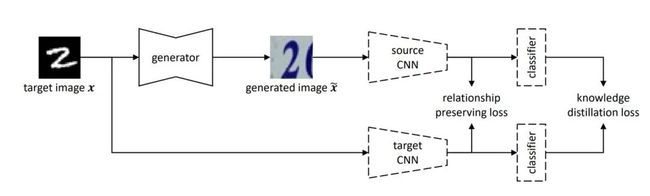 基于模型的风格迁移:不依赖风格图像和评价网络;而是依赖源域模型、目标域模型
基于模型的风格迁移:不依赖风格图像和评价网络;而是依赖源域模型、目标域模型
SFIT方法的流程设计如下。给定(目标域)内容图片 ,我们训练一个生成器 来将其迁移至(源域)风格,生成图片 。面对原始的内容图片 和生成的风格化图片 ,传统的基于图像的风格迁移和本文中提出的基于模型的风格迁移存在以下区别:
基于图片的风格迁移(neural style transfer)约束生成图片 内容上接近 (content loss: 评价网络 特征图之差),风格上接近 (style loss: 评价网络 特征图分布的区别)
基于模型的风格迁移(SFIT)约束这内容图片 和生成的风格化图片 在经过(预训练且固定的)目标域模型 和源域模型 后,能获得相似的输出。我们通过约束最终输出的相似和特征图的分布相似,完成对生成图片内容和风格上的约束。
损失函数设计
知识蒸馏(knowledge distillation):直接约束风格化前后图片在源域和目标域模型上输出相似,
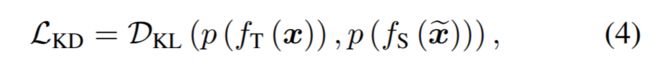
由于这两个模型描述相同的语义,相似输出保证内容(按照网络准确率的概率)不变。
关系保持(relationship preserving):归一化版本的style loss,约束两路特征图输出在特征分布(Gram矩阵,即特征图关于通道的自相关矩阵:抵消HW维度,剩余通道数D维度)上接近
传统的style loss约束两张图片在同一个评价网络 上特征图分布相似;
relationship preserving loss约束两张图片分别经过源域模型 和目标域模型 后,得到的特征图归一化分布相似。
由于两个模型适用场景不同,相似输出分布保证两张图片分别适应两种风格(原始图像及两个域对应模型固定不变,则生成图像需适应源域风格)

为何约束不同网络的特征图分布可以迁移风格?
Demystifying neural style transfer [3] 一文证明,传统style loss可以以类似域迁移中Maximum Mean Discrepancy (MMD) loss的方式,通过不同图片在同一网络的Gram矩阵以及二阶统计量,迁移图像的风格。
由于我们假设,源域的网络 和一个适用于目标域的网络 共享分类层 (域迁移中常见设置),我们可以认为这两个网络在通道维度上语义是相对对齐的(共享分类层,需要global average pooling之后的特征向量在通道上对齐,才能在两个不同的域上都获得较好的结果)。鉴于此,我们可以认为, 和 这两个网络以一种松散的方式,保持着类似于同一网络的特性,即通道维度语义对齐。
但毕竟,两个网络肯定还是存在差别,通道之间的关系也不可能严格维持不变。由此,我们在relationship preserving loss中,使用归一化的Gram矩阵而非原始的Gram矩阵(如传统style loss)。如下图,归一化的Gram矩阵能提供更加均匀的约束,而且能免于对某些维度的过度自信(传统style loss存在过大loss值,在网络不严格一致的情况下,可能过于自信)。
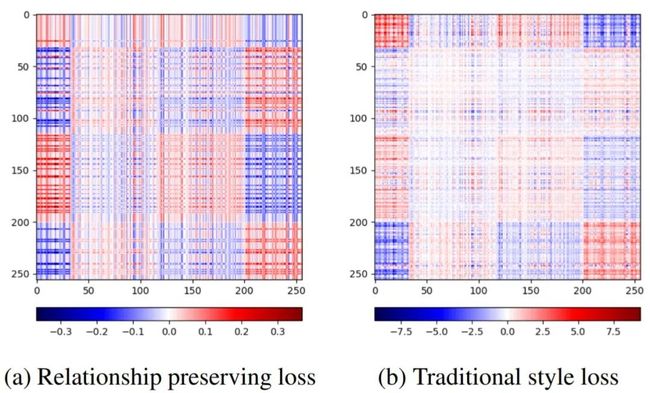 relationship preserving loss和传统style loss对应的归一化/原始Gram矩阵差别:归一化的更加均匀,且避免过强(过度自信)的约束
relationship preserving loss和传统style loss对应的归一化/原始Gram矩阵差别:归一化的更加均匀,且避免过强(过度自信)的约束
实验结果

实验结果表明,仅依赖模型,也可以将目标域图像有效迁移至源域风格。
 VisDA数据集上风格迁移更多结果。左为原始图片,右为风格化图片。
VisDA数据集上风格迁移更多结果。左为原始图片,右为风格化图片。
我们也同时对比了利用不同方式迁移图像风格的效果。如下图,直接对齐Batch Norm层中的统计量可以轻微迁移图像风格 (b);传统的style loss有效迁移风格,但存在边缘和前景的过度白化 (c);文章中提出从relationship preserving loss则是在保持前景的同时(更加锐利的边缘、和背景的区别更明显),有效迁移的图像风格。

此外,我们还利用定量实验验证了风格迁移的结果是对源域和目标域模型知识差异的有效刻画,且生成的风格图片可进一步帮助微调域迁移模型。关于这方面的分析,请见论文原文,或从域迁移任务可解释新角度的分析文章。
CVPR 2021 | 帮你理解域迁移!可视化网络知识的变化
Reference
[1]. Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 2414-2423).
[2]. Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision(pp. 2223-2232).
[3]. Li, Y., Wang, N., Liu, J., & Hou, X. (2017, August). Demystifying neural style transfer. InProceedings of the 26th International Joint Conference on Artificial Intelligence(pp. 2230-2236).
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看