贷款数据探索风险分析(EDA)
项目介绍
所谓探索性数据分析(Exploratory Data Analysis,以下简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们对这些数据中的信息没有足够的经验,不知道该用何种传统统计方法进行分析时,探索性数据分析就会非常有效。探索性数据分析在上世纪六十年代被提出,其方法由美国著名统计学家约翰·图基(John Tukey)命名。
本项目需解决的问题
本项目分析P2P平台Lending Club的贷款数据,探索数据分析过程中,并尝试回答以下2个问题:
1)利率与风险成正比,风险越高,利率越高,违约的可能线性越大,从P2P平台的数据来看,影响风险的因素有哪些?(为后续建模做准备)
2)了解P2P平台的业务特点、产品类型、资产质量、风险定价?
分析思路
我们可以将信贷信息分为信贷硬信息和信贷软信息。
任何可以量化客户的还款能力的信息均可以用作硬信息,可勾勒客户还款意愿的信息则为软信息。
信贷硬信息: 站在企业的角度,硬信息主要包括财务三大报表(资产负债表、利润表和现金流量表)以及信贷记录;站在个人角度硬信息主要包括:个人年收入 、资产状况(借款是否拥有房产、车或理财产品)。
信贷软信息: 过往的信贷记录比较直接了解客户的还款意愿,以往发生违约次数较多的客户再次发生违约的概率相比其他客户大。客户的学历、年龄、目前工作所在单位的级别和性别等信息也可作为软信息。
因此,我们主要围绕着“客户是否具有偿还能力,是否具有偿还意愿”展开探索分析。
项目背景
作为旧金山的一家个人对个人的借贷公司,Lending Club成立于2006年。他们是第一家注册为按照美国证券交易委员会SEC(Securities and Exchange Commission)的安全标准向个人提供个人贷款的借贷公司。与传统借贷机构最大的不同是,Lending Club利用网络技术打造的这个交易平台,直接连接了个人投资者和个人借贷者,通过此种方式,缩短了资金流通的环节,尤其是绕过了传统的大银行等金融机构,使得投资者和借贷者都能得到更多实惠、更快捷。对于投资者来说可以获得更好的回报,而对于借贷者来说,则可以获得相对较低的贷款利率。
数据集
数据集是Lending Club平台发生借贷的业务数据(2017年第二季),具体数据集可以从Lending Club官网下载
本项目报告分析,我将如何运用Python操作数据和探索分析数据的思考过程均记录下来。
前期准备
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
from pyecharts import Pie
#from missinggo import msno
import warnings #忽略弹出的warning
warnings.filterwarnings('ignore')%matplotlib inline。IPython提供了很多魔法命令,使得在IPython环境中的操作更加得心应手,使用%matplotlib inline在绘图时,将图片内嵌在交互窗口,而不是弹出一个图片窗口。具体请查看Stackoverflow的解释。
获取数据
第二步,使用Pandas解析数据
Pandas是基于NumPy的一个非常好用的库,无论是读取数据、处理数据,用它都非常简单。学习Pandas最好的方法就是查看官方文档 。
数据集的格式是CSV,因此我们用到pandas.read_csv方法,同时也将CSV内容转化成矩阵的格式。
data = pd.read_csv('C:/Users/Administrator/Desktop/EDA/LoanStats_2017Q2.csv' , encoding='latin-1',skiprows = 1探索分析数据(EDA)
一旦获得了数据,下一步就是检查和探索他们。在这个阶段,主要的目标是合理地检查数据。例如:如果数据有唯一的标记符,是否真的只有一个;数据是什么类型,检查最极端的情况。他们是否有意义,有什么需要删除的吗?数据应该怎么调整才能适用于接下来的分析和挖掘?此外,数据集还有可能存在异常值。同时,我将会通过对数据进行简单的统计测试,并将其可视化。 检查和探索数据的过程非常关键。因为下一步需要清洗和准备处理这些数据,只有进入模型的数据质量是好的,才能构建好的模型。(避免Garbage in, Garbage out)
首先预览基本内容,Pandas为我们提供很多可以方便查看和检查数数据的方法,有df.head(n)、df.tail(n)、df.shape()、http://df.info() 等 。
df.head(n)查看数据前n行;df.tail(n))查看数最后n行;df.shape查看数据有多少行和列;
处理缺失值
统计每列属性缺失值的数量。
def not_null_count(column):
column_null = pd.isnull(column)
null = column[column_null]
return len(null)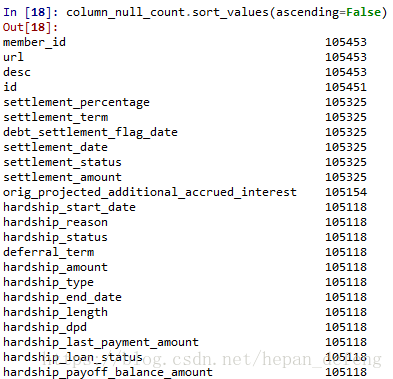
half_count = len(data)/2 # 设定阀值
loans = data.dropna(thresh = half_count, axis = 1 ) #若某一列数据缺失的数量超过阀值就会被删除
#(105453, 103)处理的数据
data.to_csv('loans_2017q2.csv', index = False) # 将预处理后的数据转化为csPandas的describe()不能统计数据类型为object的属性,部分数据int_rate和emp_length数据类型都是object,稍后分析数据时需将它们转化为类型为floate的数字类型。
数据集的属性较多,我们初步聚焦几个重要特征展开分析,特别是我们最关心的属性贷款状态。
used_col = ['loan_amnt', 'term', 'int_rate', 'grade', 'issue_d', 'addr_state', 'loan_status','purpose', 'annual_inc', 'emp_length'] # 贷款金额、贷款期限、贷款利率、信用评级、业务发生时间、业务发生所在州、贷款状态、贷款用途
used_data = loans[used_col]def not_null_count(column):
column_null = pd.isnull(column) #判断某列属性是否存在缺失值
null = column[column_null]
return len(null)
column_null_count = used_data.apply(not_null_count)
print (column_null_count)
查看数据缺失值情况,每个列数据均有两个缺失值,占总数据比例极小,可直接删除

所有缺失值都在同一行,因此可直接删除缺失值所在行。
单变量分析
1)贷款状态分布
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
#把贷款状态LoanStatus编码为违约=1, 正常=0:
pd.value_counts(used_data["loan_status"])
used_data["Loan_Status_Coded"] = coding(used_data["loan_status"], {'Default':0,'Current':0,'Fully Paid':0,'In Grace Period':1,'Late (31-120 days)':1,'Late (16-30 days)':1,'Charged Off':1})
pieData = pd.value_counts(used_data["Loan_Status_Coded"])
attr = ["normal", "break"]
plt.axes(aspect=1)
plt.pie(x=pieData, labels=attr,autopct='%3.1f %%',labeldistance=1.1, startangle = 90,pctdistance = 0.6)
从图中可以看出,平台贷款发生违约的数量占少数。贷款状态为正常的有99286个,贷款正常状态占比为94.2%。贷款状态将作为我们建模的标签,贷款状态正常和贷款状态违约两者数量不平衡,绝大多数常见的机器学习算法对于不平衡数据集都不能很好地工作。
2)带款金额分布
plt.figure(figsize=(18, 9))
sns.set()
sns.set_context("notebook", font_scale=1, rc={"lines.linewidth":2 } )
sdisplot_loan = sns.distplot(used_data['loan_amnt'] )
plt.xticks(rotation=90)
plt.xlabel('Loan amount')
plt.title('Loan amount\'s distribution')
sdisplot_loan.figure.savefig("Loan_amount") 
平台贷款呈现右偏正态分布,贷款金额最小值为1,000美元,最大值为40,000美元,贷款金额主要集中在10,000美元左右,中位数为12,000美元,可以看出平台业务主要以小额贷款为主。贷款金额越大风险越大。
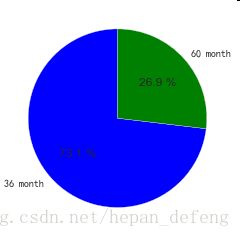
3)贷款期限分布
pieData2 = [int(i) for i in used_data['term'].value_counts()]
labels1 = ['36 month', '60 month']
plt.axes(aspect=1)
plt.pie(x=pieData2, labels=labels1,autopct='%3.1f %%',labeldistance=1.1, startangle = 90,pctdistance = 0.6)
平台贷款产品期限分为36个月和60个月两种,其中贷款期限为60个月的贷款占比为26.9%,贷款期限为36个月的贷款占比为73.1%。一般来说贷款期限越长,不确定性越大,违约的可能性更大,期限较长的贷款产品风险越高 。从期限角度看,平台风险偏小的资产占大部分。
4)贷款产品用途种类比较
histData = used_data['purpose'].value_counts() plt.figure(figsize=(18, 9)) sns.set() sns.set_context("notebook", font_scale=1.5, rc={"lines.linewidth": 2.5}) total = float(len(used_data.index)) ax = sns.countplot(x="purpose", data=used_data, palette="Set2") ax.set(yscale = "log") plt.xticks(rotation=90) plt.title('Purpose') plt.show()P2P平台贷款用途最多的为债务重组(借新债还旧债),其次是信用卡还款,第三是住房改善。一般来说,贷款用途为债务重组和信用卡还款的客户现金流较为紧张,此类客户也是在传统银行渠道无法贷款才转来P2P平台贷款,这部分客户的偿还贷款能力较弱,发生违约的可能性较高。还有部分贷款用途为Other的贷款,需要通过其他维度来分析其风险。
5)客户信用等级占比
pieData3 = loans['grade'].value_counts() pieData3 = [int(i) for i in pieData3] labels2 = ['C','B','A','D','E','F','G'] pie = Pie("Grade") pie.add("", labels2, pieData3,is_label_show=True,is_legend_show=False) pie.render()#将图片一Lending Club平台对客户的信用等级分7类,A~G,信用等级为A的客户信用评分最高,信用等级为G的客户最低,信用等级的客户发生违约的可能性更低。目前,平台客户信用等级占比较多的客户为C类,其次是B类和A类,三者合计占比为81.62%。此外信用等级为E、F、G类的客户占比为6.99%。可以看出Lending Club授信部门对申请人的资信情况把关较严。
6)贷款利率种类分布
used_data['int_rate_num']= used_data['int_rate'].str.rstrip("%").astype("float") plt.figure(figsize=(18, 9)) sns.set() sns.set_context("notebook", font_scale=1, rc={"lines.linewidth":2 } ) sdisplot_loan = sns.distplot(used_data['int_rate_num'] ) plt.xticks(rotation=90) plt.xlabel('Interest Rate') plt.title('Interest Rate\'s distribution')
Lending Club平台贷款利率呈现右偏正态分布,利率中位数12.62%,利率最高值为31.00%,利率最小值为5.32%,总体利率水平相对传统银行较高。。利率是资金的价格,利率越高,借款人借贷成本越高,借款人违约的可能性越高。Lending Club平台贷款利率呈现右偏正态分布,利率中位数12.62%,利率最高值为31.00%,利率最小值为5.32%。利率是资金的价格,利率越高,借款人借贷成本越高,借款人违约的可能性越高。
多维变量分析
1)探索贷款与时间的关系
used_data['issue_d2'] = pd.to_datetime(used_data['issue_d'])#时间转换 used_data['issue_month'] = used_data['issue_d2'].apply(lambda x: x.to_period('M'))#统一转换为月份 amount_month = used_data.groupby('issue_month')['loan_amnt'].sum() amount_month = pd.DataFrame(amount_month).reset_index() plt.figure(figsize=(15, 9)) sns.set() sns.set_context("notebook", font_scale=1, rc={"lines.linewidth": 2}) plot1 = sns.barplot(x='issue_month', y= 'loan_amnt', data = amount_month) plt.xlabel('Month') plt.ylabel('Loan_amount') plt.title('Mounth VS Loan_amount') plot1.figure.savefig("Mounth VS Loan_amount.png")
二季度4月份贷款最低,而5月和6月的贷款金额基本持平。由于本数据集只包含2017Q2的数据,如果数据集能包括横跨几年业务数据,可以将数据按年按月做横向和纵向对比,更能反映公司业务的发展情况。初步看来,L eding Club 平台在2017Q2业务持续增长 。
2)探索信用评级、贷款期限和利率的关系
group1 = used_data.groupby(['grade', 'term'])['int_rate_num'].mean() group1= pd.DataFrame(group1).reset_index() #group_pivot = group1.pivot(index='grade',columns='term',values='int_rate_num') plt.figure(figsize=(15, 9)) sns.set_context("notebook", font_scale=1.2, rc={"lines.linewidth": 2.5}) sboxplot2 = sns.barplot(x="grade", y="int_rate_num",hue='term', data=group1) sns.despine(top=True) plt.xticks(rotation=90) plt.title('Int_rate_num VS Term')
贷款期限长意味着不确定性增加,风险也随之增加,期限较长的贷款在同信用等级下的借款利率也相对高,但是并不明显,其中原因有待探索。
3)探索贷款用途与利率的关系
plt.figure(figsize=(15, 9)) sns.set_context("notebook", font_scale=1.5, rc={"lines.linewidth": 2.5}) sboxplot = sns.boxplot(y="purpose", x="int_rate_num", data=used_data) sns.despine(top=True) plt.xlabel('Interest_Rate') plt.ylabel('Purpose') plt.xticks(rotation=90) plt.show() sboxplot.figure.savefig("Purpose VS Rate")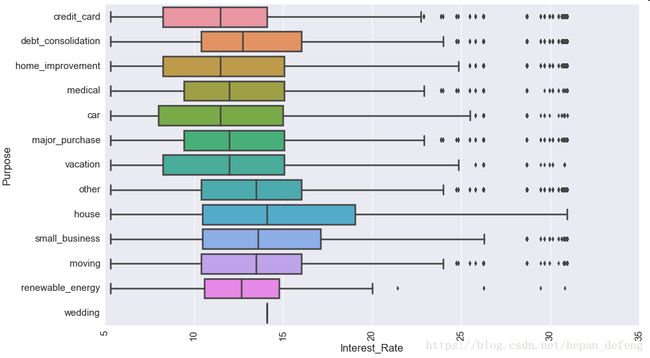
贷款用途分别为house、small_business以及Other的贷款利率较高。其中贷款用途为house的贷款利率为最高,经探索,house带款中期限为60month达到30%。
4)探索贷款利率与违约次数之间的关系
plt.figure(figsize=(15, 9)) sns.set_context("notebook", font_scale=1.2, rc={"lines.linewidth": 2.5}) sboxplot2 = sns.boxplot(x="delinq_2yrs", y="int_rate_num", data=used_data) sns.despine(top=True) plt.xticks(rotation=90) plt.title('Interest Rate VS Delinq_2yrs') sboxplot2.figure.savefig("Interest Rate VS Delinq_2yrs")
违约次数越多的人意味着自身财务状况较差,偿付能力也较低,因此此类客户贷款风险越高,对该部分客户应严格审查,确定其贷款资质。

5)探索利率、收入、工作年限以及贷款状态之间的关系
mapping_dict = {'grade':{'A':7,'B':6,'C':5,'D':4,'E':3,'F':2,'G':1}}
used_data = used_data.replace(mapping_dict)
mapping_dict1 = {
"emp_length": {
"10+ years": 10,
"9 years": 9,
"8 years": 8,
"7 years": 7,
"6 years": 6,
"5 years": 5,
"4 years": 4,
"3 years": 3,
"2 years": 2,
"1 year": 1,
"< 1 year": 0,
"n/a": 0
}
}
used_data = used_data.replace(mapping_dict1)
group2 = used_data.groupby('emp_length')['grade'].mean()
group3 = pd.DataFrame(group2).reset_index()
sns.set()
plt.figure(figsize=(15, 9))
sns.set_context("notebook", font_scale=1, rc={"lines.linewidth": 5})
sbarplot = sns.barplot(y='grade' , x='emp_length' , data=group3)
plt.xlabel('Emp_length')
plt.ylabel('Grade')
plt.xticks(rotation=90)
plt.title('Grade VS Emp_length')
sbarplot.figure.savefig("State VS Loan_amount")
工作年限越长,客户的收入也越高,自身现金流比较充足,此类客户偿还债务的能力较强。但是从上图来看,工作年限的差别而导致的贷款评级并无明显差别。由此可推测,公司进行了严格的客户筛选,将工作年限短,还款能力差的客户剔除了,从而导致客户评分在各个工作年限上分布无明显差别。
总结
names = ['loan_amnt', 'annual_inc' ,'emp_length', 'Loan_Status_Coded','int_rate' ] #设置变量名
correlations = used_data.corr()
# plot correlation matrix
plt.figure(figsize=(19, 9))
fig = plt.figure() #调用figure创建一个绘图对象
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1) #绘制热力图,从-1到1
fig.colorbar(cax) #将matshow生成热力图设置为颜色渐变条
ticks = np.arange(0,5,1) #生成0-5,步长为1
ax.set_xticks(ticks) #生成刻度
ax.set_yticks(ticks)
ax.set_xticklabels(names) #生成x轴标签
ax.set_yticklabels(names)
plt.xticks(rotation=90)
fig.savefig("Corr")
plt.show()
1.影响风险的因素
分析企业偿债能力主要考察企业的资产状况和经营情况,只有负债结构与企业盈利能力合理匹配,企业才能持续稳定地发展。
个人的资产状况好比企业的资产负债表,个人收入犹如企业的利润表或现金流量表。高收入的客户意味着有良好的现金流,偿还债务能力较高,违约的可能性较低,一般来说此类客户的信用评级也相对较高,平台对应的贷款资产风险也相对较低;个人过往的信用记录能够反映客户的偿还意愿,因此应根据个人资产状况以及个人过往的信用记录对用户进行评分,对于评分过低的客户应不予贷款。
1)平台业务持续稳定发展:第二季度业务持续增长,平台业务主要集中于加州、德克萨斯州和纽约州。
2)平台贷款金额以 小额贷款为主,贷款金额主要集中在10,000美元左右,小而散的贷款金额能够很好的分散资金风险。
3)平台贷款利率较高,贷款利率集中在12.62%,贷款利率相对传统金融机构较高。
4)平台二季度违约风险得到良好的控制,平台贷款发生违约的数量较少,贷款正常状态占比为94.2%
3.个人建议
1)完善客户画像和产品设计:信贷业务开展前,首先要明确信贷机构的目标客户群、目标客户的特征和画像信息是什么。例如Lending Club平台的small business业务,中小企业目标群体的特征描述应包括能够反映企业的资产负债和现金流相关的财务报表信息或表外债务信息等。完整的客户信息有利于风控人员和系统分析把控违约风险。
2)优化贷款模型:完善客户信息的同时,借助机器学习的技术持续优化贷款模型。