SSD训练自己数据集
SSD训练自己数据集
原理
目标检测|SSD原理与实现
损失函数:(1)类别损失(置信度误差)为softmax loss
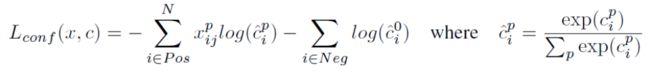 (2)位置损失为Smooth L1 Loss
(2)位置损失为Smooth L1 Loss
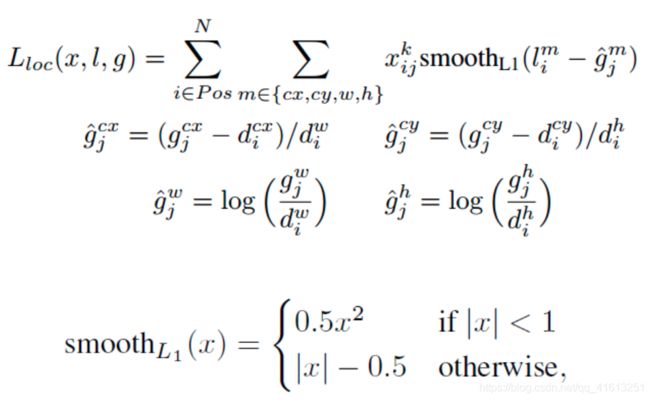
训练
1.数据制作
(1)首先准备img与txt文件夹(图像及标注的txt文件),txt文件夹下的文件均为txt文件,里边的内容为1 2 26 18 70样式,其中1为类别,(2,26)为左上点坐标,(18,70)为右下角坐标。目标检测标注工具初始生成的文件包括xml,xml2txt文件如下。
import os
import re
import json
import shutil
import numpy as np
from PIL import Image
from lxml import etree
import xml.etree.ElementTree as et
from lxml.etree import Element, SubElement, tostring
#class_filters=['person','bicycle','car','motorcycle','bus','train','truck','backpack','umbrella','handbag','cell phone','suitcase','tie']
#class_filters=['person','bicycle','car','motorcycle','bus','truck']
class_filters=['plate']
anno_folder = '/data_2/LYD/plate_detection/train/data/split/test/xml'
trainval_folder = '/data_2/data/yolo3-train-data/weifa_jiance_20190612/yolov3'
if __name__ == '__main__':
for root, dirs, files in os.walk(anno_folder):
for filename in files:
split_name = re.split('\.', filename)
bbox_file = split_name[0] + '.txt'
trainval_file = os.path.join(trainval_folder, bbox_file)
trainval_txt_file_fd = open(trainval_file, 'w')
anno_path = os.path.join(anno_folder, filename)
print 'anno_path = ', anno_path
tree = et.parse(anno_path)
root = tree.getroot()
for obj_size in root.findall('size'):
width = int(obj_size.find('width').text)
height = int(obj_size.find('height').text)
dw = 1.0 / width
dh = 1.0 / height
for obj in root.findall('object'):
obj_name = obj.find('name').text
if obj_name in class_filters:
if obj.find('name').text == 'smallCar':
trainval_txt_file_fd.write(str(0) + ' ')
elif obj.find('name').text == 'car':
trainval_txt_file_fd.write(str(0) + ' ')
elif obj.find('name').text == 'Car':
trainval_txt_file_fd.write(str(0) + ' ')
elif obj.find('name').text == 'xiaoche':
trainval_txt_file_fd.write(str(0) + ' ')
elif obj.find('name').text == 'bigCar':
trainval_txt_file_fd.write(str(1) + ' ')
bndbox = obj.find('bndbox')
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
x = (int(xmin) + int(xmax)) / 2.0
y = (int(ymin) + int(ymax)) / 2.0
w = int(xmax) - int(xmin)
h = int(ymax) - int(ymin)
x = x * dw
y = y * dh
w = w * dw
h = h * dh
trainval_txt_file_fd.write(str(x) + ' ')
trainval_txt_file_fd.write(str(y) + ' ')
trainval_txt_file_fd.write(str(w) + ' ')
trainval_txt_file_fd.write(str(h) + '\n')
trainval_txt_file_fd.close()
(2)生成train.txt文件(为了第三步生成lmdb文件),生成的是相对路径。
import os
import re
import random
if __name__ == '__main__':
base_dir = '/data_2/LYD/红绿灯检测/原始数据/ssd数据制作脚本/data/'
image_dir = [base_dir + 'img', ]
label_dir = [base_dir + 'txt', ]
train_txt = base_dir + 'train.txt'
outlines = []
for i, dir_path in enumerate(image_dir):
imgs = os.listdir(dir_path)
for img in imgs:
split_name = re.split('.jpg', img)
# outlines.append(
# os.path.join(image_dir[i], img) + ' ' + os.path.join(label_dir[i],
# split_name[0] + '.txt') + '\n') # -4 or -9
outlines.append('img/'+img + ' ' + 'txt/' + split_name[0] + '.txt' + '\n')
random.shuffle(outlines)
random.shuffle(outlines)
random.shuffle(outlines)
random.shuffle(outlines)
random.shuffle(outlines)
random.shuffle(outlines)
with open(train_txt, 'w+') as train_file:
train_file.writelines(''.join(outlines))
train_file.close()
(3)生成lmdb,使用的脚本及脚本调用的文件如下
create_data2_320.sh
# cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
# root_dir=$cur_dir/../..
# cd $root_dir
export PYTHONPATH=$PYTHONPATH:/data_2/ssd/caffe/python
redo=1
data_root_dir="/data_2/LYD/红绿灯检测/原始数据/ssd数据制作脚本/data"
dataset_name="traffictrain"
mapfile="labelmap_voc2.prototxt"
anno_type="detection"
db="lmdb320"
min_dim=0
max_dim=0
width=320
height=320
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in train
do
python2 /data_2/ssd/caffe/scripts/create_annoset.py --shuffle --anno-type=$anno_type --label-type="txt" --label-map-file=$mapfile\
--min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height\
--check-label $extra_cmd $data_root_dir ./$subset.txt $data_root_dir/$db/$dataset_name"_"$subset"_"$db\
/media/f/src_data/Face/ssd-face/examples/$dataset_name
done
# examples/$dataset_name
labelmap_voc2.prototxt
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "trafficlight"
label: 1
display_name: "trafficlight"
}
create_annoset.py
import argparse
import os
import shutil
import subprocess
import sys
caffe_root = '/data_2/ssd/caffe'
sys.path.insert(0, caffe_root + '/python')
from caffe.proto import caffe_pb2
from google.protobuf import text_format
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Create AnnotatedDatum database")
parser.add_argument("root",
help="The root directory which contains the images and annotations.")
parser.add_argument("listfile",
help="The file which contains image paths and annotation info.")
parser.add_argument("outdir",
help="The output directory which stores the database file.")
parser.add_argument("exampledir",
help="The directory to store the link of the database files.")
parser.add_argument("--redo", default = False, action = "store_true",
help="Recreate the database.")
parser.add_argument("--anno-type", default = "classification",
help="The type of annotation {classification, detection}.")
parser.add_argument("--label-type", default = "xml",
help="The type of label file format for detection {xml, json, txt}.")
parser.add_argument("--backend", default = "lmdb",
help="The backend {lmdb, leveldb} for storing the result")
parser.add_argument("--check-size", default = False, action = "store_true",
help="Check that all the datum have the same size.")
parser.add_argument("--encode-type", default = "",
help="What type should we encode the image as ('png','jpg',...).")
parser.add_argument("--encoded", default = False, action = "store_true",
help="The encoded image will be save in datum.")
parser.add_argument("--gray", default = False, action = "store_true",
help="Treat images as grayscale ones.")
parser.add_argument("--label-map-file", default = "",
help="A file with LabelMap protobuf message.")
parser.add_argument("--min-dim", default = 0, type = int,
help="Minimum dimension images are resized to.")
parser.add_argument("--max-dim", default = 0, type = int,
help="Maximum dimension images are resized to.")
parser.add_argument("--resize-height", default = 0, type = int,
help="Height images are resized to.")
parser.add_argument("--resize-width", default = 0, type = int,
help="Width images are resized to.")
parser.add_argument("--shuffle", default = False, action = "store_true",
help="Randomly shuffle the order of images and their labels.")
parser.add_argument("--check-label", default = False, action = "store_true",
help="Check that there is no duplicated name/label.")
args = parser.parse_args()
root_dir = args.root
list_file = args.listfile
out_dir = args.outdir
example_dir = args.exampledir
redo = args.redo
anno_type = args.anno_type
label_type = args.label_type
backend = args.backend
check_size = args.check_size
encode_type = args.encode_type
encoded = args.encoded
gray = args.gray
label_map_file = args.label_map_file
min_dim = args.min_dim
max_dim = args.max_dim
resize_height = args.resize_height
resize_width = args.resize_width
shuffle = args.shuffle
check_label = args.check_label
# check if root directory exists
if not os.path.exists(root_dir):
print("root directory: {} does not exist".format(root_dir))
sys.exit()
# add "/" to root directory if needed
if root_dir[-1] != "/":
root_dir += "/"
# check if list file exists
if not os.path.exists(list_file):
print("list file: {} does not exist".format(list_file))
sys.exit()
# check list file format is correct
with open(list_file, "r") as lf:
for line in lf.readlines():
img_file, anno = line.strip("\n").split(" ")
if not os.path.exists(root_dir + img_file):
print("image file: {} does not exist".format(root_dir + img_file))
if anno_type == "classification":
if not anno.isdigit():
print("annotation: {} is not an integer".format(anno))
elif anno_type == "detection":
if not os.path.exists(root_dir + anno):
print("annofation file: {} does not exist".format(root_dir + anno))
sys.exit()
break
# check if label map file exist
if anno_type == "detection":
if not os.path.exists(label_map_file):
print("label map file: {} does not exist".format(label_map_file))
sys.exit()
label_map = caffe_pb2.LabelMap()
lmf = open(label_map_file, "r")
try:
text_format.Merge(str(lmf.read()), label_map)
except:
print("Cannot parse label map file: {}".format(label_map_file))
sys.exit()
out_parent_dir = os.path.dirname(out_dir)
if not os.path.exists(out_parent_dir):
os.makedirs(out_parent_dir)
if os.path.exists(out_dir) and not redo:
print("{} already exists and I do not hear redo".format(out_dir))
sys.exit()
if os.path.exists(out_dir):
shutil.rmtree(out_dir)
# get caffe root directory
caffe_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
if anno_type == "detection":
cmd = "{}/build/tools/convert_annoset" \
" --anno_type={}" \
" --label_type={}" \
" --label_map_file={}" \
" --check_label={}" \
" --min_dim={}" \
" --max_dim={}" \
" --resize_height={}" \
" --resize_width={}" \
" --backend={}" \
" --shuffle={}" \
" --check_size={}" \
" --encode_type={}" \
" --encoded={}" \
" --gray={}" \
" {} {} {}" \
.format(caffe_root, anno_type, label_type, label_map_file, check_label,
min_dim, max_dim, resize_height, resize_width, backend, shuffle,
check_size, encode_type, encoded, gray, root_dir, list_file, out_dir)
elif anno_type == "classification":
cmd = "{}/build/tools/convert_annoset" \
" --anno_type={}" \
" --min_dim={}" \
" --max_dim={}" \
" --resize_height={}" \
" --resize_width={}" \
" --backend={}" \
" --shuffle={}" \
" --check_size={}" \
" --encode_type={}" \
" --encoded={}" \
" --gray={}" \
" {} {} {}" \
.format(caffe_root, anno_type, min_dim, max_dim, resize_height,
resize_width, backend, shuffle, check_size, encode_type, encoded,
gray, root_dir, list_file, out_dir)
print(cmd)
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
output = process.communicate()[0]
if not os.path.exists(example_dir):
os.makedirs(example_dir)
link_dir = os.path.join(example_dir, os.path.basename(out_dir))
if os.path.exists(link_dir):
os.unlink(link_dir)
os.symlink(out_dir, link_dir)
运行create_data2_320.sh脚本即可生成lmdb文件。
2. 训练
训练文件包括网络结构ResNet_34_train_valv8_2.prototxt、标签文件
labelmap_voc2.prototxt、求解器solver.prototxt、及训练脚本
(1)ResNet_34_train_valv8_2.prototxt
(2)solver.prototxt
train_net: "ResNet_34_train_valv8_2.prototxt"
base_lr: 0.0001
display: 100
max_iter: 300000
#lr_policy: "fixed"
weight_decay: 0.00005
snapshot: 1000
snapshot_prefix: "models/"
solver_mode: GPU
lr_policy: "step"
#lr_policy: "multistep"
gamma: 0.5
stepsize: 100000
#stepvalue: 100000
#stepvalue: 400000
#stepvalue: 950000
#stepvalue: 1450000
type: "Adam"
momentum: 0.9
momentum2: 0.999
delta: 1e-3
#iter_size: 4
#type: "RMSProp"
#rms_decay: 0.98
(3)labelmap_voc2.prototxt
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "trafficlight"
label: 1
display_name: "trafficlight"
}
(4)train.sh
#!/usr/bin/env sh
LOG=log/log-`date +%Y-%m-%d-%H-%M-%S`.log
set -e
/data_2/ssd/caffe/build/tools/caffe train -solver solver.prototxt -weights ssd.caffemodel -gpu 0 2>&1 | tee $LOG $@
#/data_2/red-light/detect/caffe-ssd/caffe/build/tools/caffe train -solver solver.prototxt -snapshot ./model/modelres34v8_iter_16000.solverstate -gpu 0 2>&1 | tee $LOG $@