【语义分割】4、DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
文章目录
-
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 深层特征聚合网络
-
- 3.1 Observations
- 3.2 深层特征聚合
- 3.3 网络结构
- 4. 实验
-
- 4.1 DFA 结构的分析
-
- 4.1.1 轻量级 backbone 网络
- 4.1.2 特征聚合
- 4.1.3 DFANet 的整体结构
- 4.2 速度和正确度的比较
- 4.3 在其他数据集上的实验
- 5. 结论
摘要
本文提出了一种及其高效的 CNN 结构——DFANet,来解决计算资源受限情况下的语义分割。
本文提出的网络,始于一个简单的backbone,并将这些子网络、子层级的有区分力的特征分别进行聚合。
基于多尺度特征传递的 DFANet 不仅仅减少了大量的参数,也获得了足够的感受野并加强了模型的学习能力,保持了分割速度和分割性能的平衡。
在 Cityscapes 和 CamVid 数据集上的实验证明了 DFANet 在取得与现有SOTA 实时语义分割算法相当的性能情况下,比其 FLOPs 少8倍,速度快2倍。
DFANet速度和效果:
平台: NVIDIA Titan X
mean IoU:Cityscapes 上达到了 70.3%
速度:170 FPS
内存量:1.7 GFLOPs
高分辨率图像: Mean IoU 达到了 71.3%,3.4 GFPLOs
1. 引言
语义分割的目的是给每个像素都分配一个类别标签,是计算机视觉的基础任务,应用于自动驾驶、视频监控、机器人感知等等领域。
对很多任务来说,如何对高分辨率的图像同时保持高速推理和高精度的性能一直难以解决。
已有的实时语义分割方法[1][25][27][29][33][22]在特定的基准上取得了较好的效果[10][9][18][36][2],但在高分辨率特征图的 U型 结构耗费了大量的时间。
现有方法解决高分辨率图像分割的不足:
很多方法利用减小输入图像尺寸[27]或降低网络通道数来提高推理速度[1,22],这样会丢失时域边缘信息和小图像信息,并且变简单的网络结构难以提取有区分力的特征。
为了克服这些不足,其他方法[33][29] 提出了一个 多分支框架 将时域细节和上下文信息结合起来。然鹅,额外的分支会限制其速度,且分支之间是独立的,这会限制模型的学习能力。
一般情况,语义分割任务通常使用从图像分类任务训练所得的 “funnel” backbone,如 ResNet[11], Xception[8], DenseNet[13] 等等。
实时分割的推理阶段,本文使用了一个轻量级的backbone,并研究了如何在计算能力受限的情况下提升分割性能。
目前主流的分割方法中,金字塔特征组合(类似于空域金字塔池化[34,5] )的方法被用来使用高层上下文信息来丰富化特征,但会增加很多计算复杂度。
此外,传统的方法通常使用单一通道结构的最终输出来丰富化特征,这种设计中,高层上下文缺乏与原有的层特征的结合,同时保留了网络路径中的空间细节和语义信息,为了强化模型学习能力并提升感受野,特征的重复利用实最直观的方法。这启发了本文寻找轻量级方式来多层上下文信息来编码特征。
本文的方法有两个阶段来实现尺度间的特征聚合:
- 首先,将从 backbone 中抽取得到的高层特征重复利用,来解决语义信息和结构细节的gap
- 其次,将网络的处理过程的不同阶段所获得的特征进行组合,来提高特征的表达能力,如图2所示。

详细来说:
本文将轻量级 backbone 重复使用来证实特征聚合的方法。
DFANet 包含三个步骤:
- lightweight backbones
- sub-network aggregation
- sub-stage aggregation。
由于深层可分离卷积被证明是实时分割推理阶段最高效的结构,故本文使用 Xception 网络作为 backbone。
1. lightweight backbones:
为了获得更好的准确性,本文在 backbone 的尾部使用一个全连接的注意力模型来存储最大的感受野。
2. sub-network aggregation:
将前一个 backbone 的高层特征映射进行上采样,保证输入下一个 backbone 的特征图大小,来精细化预测结果。也就是可以看做一个从粗尺度到细尺度的像素分类
3. sub-stage aggregation:
将粗尺度和精细尺度的特征表达进行聚合,通过将大小相同的层级结合起来,可以保持感受野和高维结构细节信息。
这三个步骤之后,由“卷积+双线性上采样”操作组成的简单解码器被应用于每个stage来产生从粗糙到精细尺度的分割结果。DFANet 结构如图3所示。

在 NVIDIA Titan X card上,用标准的基线数据集 Cityscapes 和 CamVid 做实验,输入 1024*1024,DFANet达到了 71.3% 的mIoU,3.4G FLOPs,速度为 100 FPS 。
当使用较小尺寸的输入和较轻量级的 backbone 时,Mean IoU 仍能分别达到 70.3% 和61.7%,1.7 G FLOPS 和 2.1G FLOPS,比许多实时分割算法性能都好。
本文主要贡献如下:
- 为低运算力场合的实时分割提供了新的可能,对比已有的结果,本文的 FLOPS小8倍,速度快2倍,效果也很好。
- 本文提出了一个全新的分割网络结构,拥有多级连通的编码流程,以将高层的上下文信息编码到特征中去。
- 本文方法能够最大程度的利用多尺度感受野,并在计算量略有增加的情况下多次细化高级特性。
- 给 Xception backbone 添加了一个 注意力层来增强感受野,且基本不需要增加额外的计算量。
2. 相关工作
实时分割:
实时语义分割的目标是在计算力有限的情况下产生高质量的预测,SegNet[1] 使用一个小的结构和pooling indices 策略来减少网络参数。
ENet [22] 考虑减小下采样次数,以获得一个紧致的框架结构,由于其使用模型的最后一级特征,导致感受野非常小,难以对大目标进行检测和分割。
ESPNet [26] 使用心得金字塔模型来提高计算速度。
ICNet[33] 使用多尺度图像作为输入并串联网络来提升效率。
BiSeNet[29] 引入空间路径和语义路径来减少计算量。
ICNet 和 BiSeNet中,只有一条分支是用于特征提取的深层 CNN,其余分支被用于捕捉细节信息。
本文结构与其不同,我们在特征空间中增强了单个模型的容量,以保留更多的细节信息。
Depthwise Separable Convolution:
深度可分离卷积(跟随于逐点卷积之后),是近年来应用很广的一种网络设计方法,该方法可以减小计算开销和网络参数量,并保持基本相当的性能。
High-level Features:
分割任务的重点在于感受野和分类能力,一般的编码-解码结构中,编码器输出的高层特征刻画了输入图像的语义信息。基于此,PSPNet[34], DeepLab series[7][5][4], PAN[16] 使用额外的操作来将更多的上下文信息和多尺度特征表达结合起来。空域金字塔池化已经广泛用于提供总体区域场景,尤其是多尺度情况下多个目标的情况。这些模型展示了高质量的分割结果,但计算量仍然很大。
Context Encoding:
SE-Net [12] 通过对通道信息的学习得到一个“ channel-wise 注意力模型”,并获得了最好的图像分类性能,注意力机制称为的深度神经网络的一个有力工具。可以看成一个通过逐通道选择来提升模型的特征表示能力的过程。
EncNet 引入了 Context Encoding 机制来提升每个像素的预测能力,这取决于编码语义。本文中,提出了一种全连接的模型来增强backbone性能,且对计算复杂度的影响很小。
Feature Aggregation:
传统的方法仅仅使用单一路径的编码-解码网络来解决逐个像素的预测。
随着网络深度的增加,更需要研究的是如何将不同模块之间的特征聚合起来。
RefineNet [17] 给编码器和解码器中间的每个上采样stage中引入复杂的 refine 模块,来抽取多尺度特征,另外一种聚合方法是使用稠密连接。DLA [31] 将该方法扩展,获得了一个更深的聚合结果来提升特征表达能力。
3. 深层特征聚合网络
3.1 Observations
图2中简单描述了分割网络结构,对于实时推理, [33,29] 中使用多分支来实现多尺度特征抽取并保留图像空域细节信息。例如,BiSeNet[29] 针对高分辨率图像提出了一种 shallow network (浅层网络),并且使用具有快速下采样能力的深层网络来保存分类效果和感受野的平衡。如图2(a) 所示。
这些方法的缺点在于没有很好的使用并行分支中的高层特征,仅仅使用了卷积层来融合特征,此外,并行分支之间也没有过多的交流,且高分辨率图像的额外分支导致其计算量增大。
语义分割任务中,空域金字塔池化(SPP)模块经常被用于解决干层特征 [5],如图2(b) 所示,SPP 模型被用于抽取高层语义上下文信息并提升感受野,如 [4,34,16] ,然鹅,SPP 模块很耗费时间。
受上述模型的启发,本文先用网络输出的上采样结果来代替高层操作,并使用另外的sub-network 来精细化特征图,如图2© 所示,不同于 SPP模型,特征图在交大分辨率下进行了细化,同时学习了 sub-pixel 的细节。
然而随着整体网络结构的深化,高维特征和感受野通常会面临精度下降的问题,因为其只有一条路径。
本文提出了一种 stage-level 的方法(图2(d)所示),来传递 low-level 和空域信息来进行语义理解,由于所有的 sub-network 拥有相同的结构,可以将相同分辨率的层级进行连接,来产生 multi-stage 的上下文,从而进行 stage-level 的精细化。
本文方法要同时结构 network-level 和 stage-level 的特征。
3.2 深层特征聚合
本文聚焦于将不同深度的特征进行聚合的任务,聚合策略由 sub-network 聚合和sub-stage 聚合组成,DFANet 的结构如图3所示。
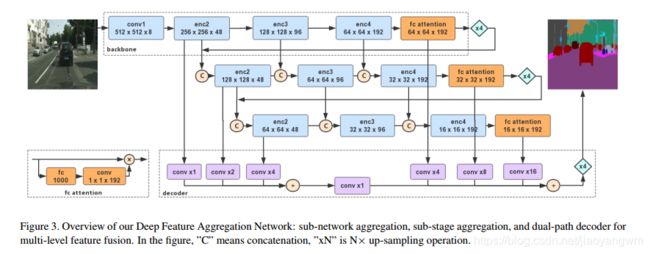
sub-network 聚合:
sub-network聚合是将高层特征进行结合,我们将DFANet作为一个backbones的集合,也就是将上一个backbone的输出作为下一个backbone的输入。换句话说,sub-network 聚合可以被看成一个精细化的过程,backbone处理过程可以定义为 y = Φ ( x ) y=\Phi(x) y=Φ(x),编码器 Φ n \Phi_n Φn 的输出是编码器 Φ n + 1 \Phi_{n+1} Φn+1 的输入,所有sub-network聚合可以表示成: Y = Φ n ( Φ n − 1 ( . . . Φ 1 ( X ) ) ) Y=\Phi_n(\Phi_{n-1}(... \Phi_1(X))) Y=Φn(Φn−1(...Φ1(X)))
类似的想法在[21]中有提出,其结构是由编码器-解码器的 “沙漏” 结构堆叠而成,sub-network 聚合过程允许可以再次处理这些高层特征来进一步评估和再次评估高阶空域关系。
sub-stage 聚合:
sub-stage 聚合局建议融合多个网络间的stage-level的语义和空域信息。随着网络深度的增加,空域细节会丢失。常见的方法,如U型 结构,用来实现skip connection 从解码器中恢复图像细节。
然而,更深的编码器模块缺乏低层特征和空域信息,无法对大尺度的各种目标和精细的结构边缘做出判断。
并行分支结构的设计采样原始分辨率和低分辨率作为输入,其输出是大规模分支和小规模分支结果的融合,而这种设计缺乏并行分支之间的信息通信。
sub-stage 聚合对编码过程的特征进行组合,对同一深度下不同stage之间的特征进行融合。
前一个 sub-network 的特定 stage 的输出,作为下一个 sub-network 的相同 stage 的输入。
对单个的backbone Φ n ( x ) \Phi_n(x) Φn(x),一个 stage 的过程可以定义为 ϕ n i \phi_n^i ϕni,前一个 stage 定义为 ϕ n − 1 i \phi_{n-1}^i ϕn−1i。 i i i 表示 stage 的索引。
sub-stage 聚合方法可以表示如下:
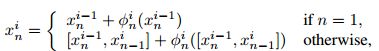
其中, x n − 1 i x_{n-1}^i xn−1i 来自于:
x n − 1 i = x n − 1 i − 1 + ϕ n − 1 i ( x n − 1 i − 1 ) x_{n-1}^i=x_{n-1}^{i-1}+\phi_{n-1}^i(x_{n-1}^{i-1}) xn−1i=xn−1i−1+ϕn−1i(xn−1i−1)
传统的方法是对于 x n i − 1 x_n^{i-1} xni−1 学习一个mapping F ( x ) + x F(x)+x F(x)+x,本文方法中,sub-stage 聚合方法是在每个 stage 的开始学习一个残差项 [ x n i − 1 , x n − 1 i ] [x_n^{i-1},x_{n-1}^i] [xni−1,xn−1i]。
对于 n > 1 n>1 n>1 的情况,第 n n n 个 network 的第 i i i 个stage的输入是第 n − 1 n-1 n−1 个 network 的第 i i i 个 stage 的输出,之后,第 i i i 个stage 学习到一个残差表示 [ x n i − 1 , x n − 1 i ] [x_n^{i-1},x_{n-1}^i] [xni−1,xn−1i]。 x n i − 1 x_n^{i-1} xni−1 和 x n − 1 i x_{n-1}^i xn−1i 具有相同的分辨率,之后将其融合。
本文始终将特征是从高分辨率到低分辨率,上面表达式的表达不仅仅学习第 n n n 个特征图的新的 mapping,同时也保存第 ( n − 1 ) (n-1) (n−1) 个特征图和感受野,信息可以通过多级网络进行流动。
3.3 网络结构
网络的整体结构如图3所示,通常情况下,语义分割网络可以被看成一个编码-解码结构,编码器将三个 Xception backbones 进行聚合,由sub-stage 聚合和sub-network聚合组成。
对于实时推理,我们没有在解码器上做过多的研究,解码器是作为一个高效的特征下采样模型来融合低层特征和高层特征,为了方便实施聚合策略,sub-network 采样单个的双线性上采样 backbone 作为解码器,所有的backbone有相同的结构且用相同的权重来初始化。
backbone:
基准 backbone 是略有微调的适用于分割任务的轻量级 Xception 模型。
对于语义分割问题,不仅仅提供稠密特征表达方式是一个问题,如何有效的获得上下文语义信息也是一个问题。所以,我们保存 ImageNet 预训练的全连接层来提高语义抽取。
分类任务中,全连接层是在全局池化层之后,来获取最终概率向量,由于分类任务的数据集比分割任务的数据集提供了更多的类别,从分类任务中得到的预训练网络比从分割任务中训练的预训练网络能力更强。
我们在全连接层之后使用一个 1x1 的卷积层,用于减少通道数,使得其能和 Xception backbone 的特征图进行匹配。之后, 一个大小为 N × C × 1 × 1 N \times C \times 1 \times 1 N×C×1×1 的编码向量和初始抽取的特征以逐 channel 的方式相乘。
Decoder:
本文提出的解码模型如图3所示,对于实时推断,我们没有太多的研究设计解码器的模型。
根据 DeepLabV3+ [7] ,一个stage中,并不是所有的特征都是对解码器有用的,我们直接将高层和低层的特征结合起来,因为编码器是由三个backbone组成的,我们首先将三个backbone中的最下面的backbone的高层特征进行融合,之后对这些高层特征进行因子为4的双线性上采样。每个backbone的分辨率相同的底层信息也分别进行了融合。
之后,高层特征和底层细节相加,并以4为因子进行上采样,来获得最终的预测。
编码模块中,我们仅仅使用很少的卷积计算来减小通道的数量。
4. 实验
虽然本文的网络对高分辨率图像的处理效率较高,我们在两个具有挑战性的数据集上进行了实验:Cityscapes 和 CamVid。
两数据集的图像大小分别为 2048x1024 和 960x720,这对实时分割来说是一个较大的挑战。
下面,我们首先介绍本文结构的效果,之后和已有方法进行对比。
所有提到的方法都使用相同的训练方式,使用mini-batch SGD ,batch 大小为 48,动量为0.9,权重衰减为 1 0 − 5 10^{-5} 10−5。
初始学习率为0.2,使用“poly” 学习率方法,乘因子为 1 − i t e r m a x − i t e r i t e r 1-\frac{iter}{max-iter}^{iter} 1−max−iteriteriter。
所有类别的每个像素交叉熵误差作为loss function,数据增强方法包括去掉均值、水平翻转、缩放率在 [0.75,1.75] 内的尺度缩放、随机裁剪等。
4.1 DFA 结构的分析
本文使用 Cityscapes 来对网络进行定性和定量的分析,Cityscapes 是从来自于50个不同城市的街区的视频序列中截取的数据集,包含30个类别,其中19个类别用于训练和评估。
数据集包含5000个精细标注的图像,19998个粗略标注的图像,分辨率都为 2048x1024。
精细标注的数据集划分为训练、验证和测试集,分别包含2979,500和1525个图像。在训练中仅仅使用精细标注的图像,在迭代次数为40k时停止训练。
模型性能的评估使用验证集,为了公平起见,消融实验中将图像裁剪为 1024x1024大小,该过程中,为了获得更好的效果,不使用任何测试的数据增强,像多尺度或多裁剪的测试集。
定量分析,class-wise mean IoU 和 float-point operations(FLOPs)被用来分别作为准确率和计算复杂度的衡量标准。
4.1.1 轻量级 backbone 网络
如上所述,backbone 网络是模型加速的主要限制,然而,两个小的backbone网络会导致分割效果急剧下降。
Xception 是一个轻量级结构,能够实现速度和性能的平衡,本文使用两个修正的 Xception 网络(A 和 B),计算复杂度也较低,推断阶段速度较快,细节如表1所示。
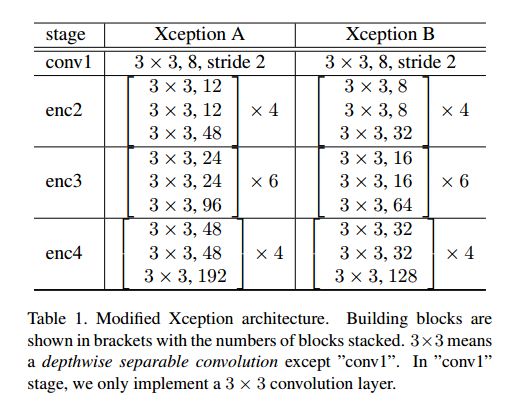
修正的 Xception 网络在 ImageNet-1k 数据集上进行预训练,初始学习率为0.3,使用 Nesterov momentum,且动量=0.9,权重衰减为 4 × 1 0 − 5 4\times 10^{-5} 4×10−5.
训练30个epoches之后,将后面30个迭代的学习率设置为0.03,batch size 为256,图像大小为224x224。
使用修正的 Xception 在Cityscapes 验证集上进行验证,为了保证预测的分辨率和初始分辨率相同,特征以16倍进行双线性上采样。
为了对比,我们复现ResNet-50,其采用扩张卷积进行1/16的下采样,可以看出,当使用 Xception A 时,分割准确率从68.3%下降到了59.2%。
当将其和 ASPP[5] 一起使用的时候性能下降的较少( ResNet-50 + ASPP 获得 72.1%, Xception A + ASPP 获得 67.1%),这也证明了ASPP 模块对轻量级网络的效果。
Xception A + ASPP 的模型能够获得67.1%的mIoU,基本上和 ResNet-50 的 68.3% 相当,但其计算复杂度远远低于ResNet-50。
这就表示我们可以将轻量级网络和和高层上下文模块进行结合,来解决算力受限的语义分割问题。
我们也考虑降低输入图像的分辨率来提升计算速度:
之前的方法中,研究人员尝试使用低分辨率的输入来实现实时推断,然而当缩放率为0.25时,对应的 mIoU 就很低了,且 FLOPS 仍然比使用 small backbone 要大很多。
在轻量级 backbone 后边加上 ASPP之后,Xception A 很容易的就能达到比传统 ResNet-50更好的效果,即使使用更小的 Xception B,准确率也较好且 FLOPs 是其一半。
忽略掉 ASPP 模块,计算复杂度仍然很大
我们在3.3节中验证了 FC 注意力模型的作用,如表2所示,可以提高约 4%-6%的准确率,计算量几乎没变,FC注意力模型证明了高维上下文信息的作用,实现了简单且有效的融合。

下面实验中,使用 Backbone A 和 B 作为基本单元,来验证 DFANet 的性能。
4.1.2 特征聚合
本节中,我们研究了聚合策略在本框架中的作用
特征聚合是由 sub-network 聚合和 sub-stage 聚合组成的。
如表3所示,基于 Backbone A ,分割效果从 65.4%提高到了 66.3%,且仅仅使用了 sub-network 聚合。

当使用两次聚合时(x3),准确率从 66.3% 降到了 65.1%,我们认为,Backbone A x2 的感受野已经比整个图都大了,另外的一次聚合会带来其他噪声。
由于输出直接被上采样到了和原始大小一样,所以噪声也被放大了,尽管上采样可以带来很多细节,但噪声会带来很多负面影响。
当聚合次数为‘x4’ 时,准确率没有得到很大的提升,因为当输入为1024x1024时,最终输出的分辨率为 8x8,特征太小了,不足以进行分类。
如图4展示了三种不同 backbone 堆积方式的结果:

第一个backbone 的预测有些噪声,下一 stage 的输出会更小,空域细节会丢失,结果证明,sub-stage 学习之后,感受野变大了且引入了全局上下文。
之后,经过第三个聚合backbone的处理之后,最终的结果中包含了很多精细的细节信息,细节信息和上下文信息被结合起来。
sub-stage 聚合能够带来多尺度信息的结合,基于本文的级联模型,能够学习到更多的有区分力的特征,且亚像素学习是逐步进行了。
4.1.3 DFANet 的整体结构
3.3 小节中设计的解码模块是一个简单高效的能够将高层和底层特征结合起来的模块,解码模块汇总没有直接利用上采样,而是对结合的结果进行了深层的平滑,聚合解码器的性能见表4。

尽管使用 Backbone A x3 的性能比使用 Backbone A x2 的性能要差,但最终的聚合编码是由三个backbone组成的,如图3所示。基于解码操作,Backbone A x3 的效果要明显好于 Backbone A x2,该结果也证明了之前的结论,即sub-stage 3 中能够学习到更多的细节信息,不同尺度的输出的融合能够消除一定的噪声。
由于聚合方法可以提供大量的特征,我们不一定要构建一个复杂的解码器。
上面两个不同的 backbone中,所有的高层和底层解码器在提升性能的同时仅仅引入了很少的计算开销。
Cityscapes 数据集的验证集上,获得了 71.9%的 mIoU,3.4 GFLOPs
此外,基于 Backbone B 的整个网络的计算速度降低到了 2.1 GFLOPs,达到了 68.4%的 mIoU。
4.2 速度和正确度的比较
表5 中展示了所有速度的比较,此处用推断阶段的时间来表示效率。
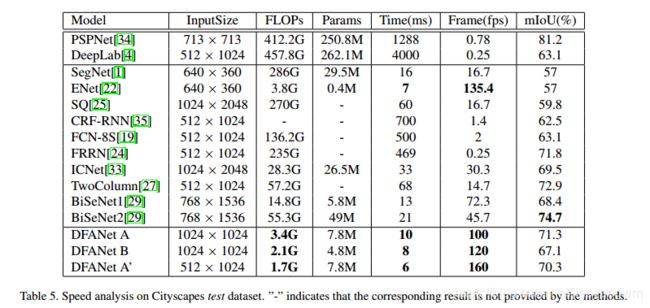
从表中可知,本文的方法的推断速度比现有的SOTA 方法都要快,且性能相当。
Cityscapes:
mIoU:71.3%
inference speed:100FPS
此处用两种改变方式来探究DFANet:输入图像大小 + 通道数
当 backbone 模型是简单的那种时,准确率为 67.1%,120 FPS inference speed,和现有的bisenet 性能(68.4%)相当。
输入图像大小削减一半时, FLOPs 降到了 1.7G,准确率仍然较好。
本文方法能达到最快的速度是 160 FPS,mIoU 为 70.3%,之前最快的是 135 FPS ,mIoU 为 57%。
DFANet A、B、A’ 分别比已有的最好算法快 1.38倍、1.65 倍和 2.21 倍,FLOPs 分别是其 1/4、1/7 和 1/8。且性能还略有上升。
图4中展示了一些结果,本文方法的效果较好。
4.3 在其他数据集上的实验
DFANet 同样在 CamVid 数据集上进行了实验,该数据集是从时频序列中截取的分辨率大小为 960x720 的图像。包括 701 幅图像,其中357个用于训练,101个用于验证,233个用于测试。
结果见表6,DFANet A/B 分别获得了120 FPS 和 160 FPS 的速度。

5. 结论
本文中,提出了一种基于深度特征聚合的方法来实现高分辨率图像的实时分割。
聚合策略级联了一系列卷积层来有效的精细化高层和底层特征,没有其他额外的操作。
定性和定量的分析表明本文方法在保持高效的情况下也能获得较为乐观的分割结果。