r语言逻辑回归_R语言机器学习 | 3 逻辑回归
1 基础知识
逻辑回归(logistic regression)是线性回归的推广,属于广义线性模型(generalized linear model)的一种。
所谓广义线性回归,本质上仍然是线性回归,只是把线性回归中的y变成了关于y的函数。举个例子,最简单的单个自变量的线性回归方程为:y=ax+b,现在把y在对数尺度上进行变换,即变为lny=ax+b,也就是y = exp(ax+b)。该回归方程显然是非线性的,但实质上可以通过对y取自然对数,使其变回线性回归(显然当y已知的时候,lny也是已知的)。所以,大家把这种对y进行一定变换后可以变回线性回归的方程叫做广义线性回归。
相比于一般的线性回归,逻辑回归的用途是进行分类。说白了,就是其因变量Y不再是连续变量,而是类别变量(尤其是二分类变量)。比如,要根据某些特征,来判断一个人是吃货or不是吃货,就可以用到逻辑回归。
如果要用回归做二分类问题,那因变量Y的取值只能是{0,1}。以分类是不是吃货为例,我们希望是吃货(阳性)的样本被分类到1,不是吃货(阴性)的样本被分类到0。按照这个逻辑,分类函数理应是这么一个单位阶跃函数(纵坐标y,横坐标ax+b):
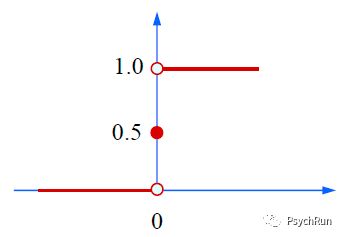
单位阶跃函数,ax+b<0时y=0;ax+b>0时y=1;ax+b=0时y=0
但是阶跃函数不是一个连续函数,这在进行计算的时候会存在问题。因此,通常会用一种近似单位阶跃函数的sigmoid函数来进行分类问题的解决,这也就是逻辑回归的函数表达,其数学表达式见下图。当然,要注意这个表达式只描述了一个自变量的情况,所以指数是-(a+bx),多个自变量的话e的指数就是-(a+b1x1+b2x2+...)。

逻辑回归的函数图像

逻辑回归的表达式
这个表达式显然是非线性的,但是可以通过对y进行一些数学变换使其变回线性回归。具体而言,将y变换为 ln(y/1-y),即可得到 ln(y/1-y) = ax+b,这下右边就和线性回归一样了,因此,逻辑回归是一种广义线性回归!
通常,将y视为阳性的可能性,那1-y就是阴性的可能性,因此可以将y/(1-y)称为几率(odds)。几率可用来度量样本x作为阳性(或者说"发生")的可能性大小,试想一件事儿发生的可能是0.8,不发生的可能是0.2,那么几率odds=0.8/0.2=4,也就是发生是不发生的4倍。
将几率取自然对数之后则得到对数几率 ln(y/1-y),也记作logit (y),这就是逻辑回归方程ln(y/1-y) = ax+b的左边儿部分,因此逻辑回归也叫作对数几率回归。
既然逻辑回归的方程可看做是 ln(y/1-y) = ax+b,那与线性回归类似,如果求得自变量的回归系数a=3,则代表当自变量增加1个单位,对数几率ln(y/1-y)就增加3个单位(也就是更有可能判断为阳性),几率y/(1-y)就增加exp(3)≈20个单位。研究者会把这个当自变量变化一个单位导致因变量几率变化的单位值叫作odds ratio: OR值。也就是说,当自变量回归系数为3,就可以说该自变量的OR值为exp(3)。
OR值的中文名叫做比值比/优势比等。OR =odds1/odds0=exp(a),其中odds1是实验组的几率,odds0是控制组的几率,a是自变量的回归系数。为啥之间有这些关系?似乎这样看还不是很清楚,下面举个例子来看一下这些变量的关系:
要研究性别X(分类变量:男1/女0)对支持某法案的态度y(分类变量:支持1/不支持0)的影响。 若求得逻辑回归方程: ln(y/1-y) = 1.2-0.3X。 由于y代表了“发生”or"阳性"的概率,因此这里的截距项1.2的含义是女性(X=0时)支持法案的 对数几率 ,对其进行指数计算后,可得到女性支持法案的几率是exp(1.2)=3.32,即女性支持法案的概率是不支持法案概率的3.32倍。相反,男性(当X=1)支持法案的对数几率是1.2-0.3=0.9,支持的几率是exp(0.9)=2.4596,也就是说男性支持法案的概率是不支持法案概率的2.4596倍。 因此 男 性支持几率(Odds1) 比上 女 性支持几率(Odds 0 ) = 2. 459 6/3.32 = 0.7408 。 这个 0.7408 就是OR值,即“优势比”,男 性支持法案的概率是 女 性的 0.7408 倍。而这个0.7408也就是exp(0.3)。 回头再看数学公式,当逻辑回归方程为:ln(y/1-y) = ax+b时, OR = odds1/odds0 = exp(a+b) / exp(b) = exp (a)。与线性回归的最小二乘法不同,逻辑回归估计系数的方法是极大似然法(Maximum likelihood estimation, MLE),因此在评价模型的时候使用的方法也有一点差异。在逻辑回归中一般使用对数似然(log-likelihood)作为模型评价指标。似然(likelihood)是古色古香的文言翻译,实际上就是概率或可能性的意思,因此取值是[0,1],对数似然则是其自然对数形式,所以取值是(-∞,0]。相比于对数自然,更常见的模型评价指标是-2 * log-likelihood(-2LL),-2LL也叫作偏差(deviance),衡量了逻辑回归的表现,既然都叫偏差了,显然-2LL越小,模型越好。由于-2LL近似服从卡方分布,所以可以更方便的检验逻辑回归的显著性。以-2LL为基础,可以继续推导出χ^2、各类R^2、AIC、BIC等模型评价指标。具体的计算细节在这里不展开了。
一般而言,逻辑回归只适用于二分类问题,即使是多分类逻辑回归 (Multinomiallogistic regression),本质上也只是进行一系列的二元逻辑回归并进行比较。相比之下,逻辑回归的推广形式Softmax回归可以解决多分类问题。
2 逻辑回归的R实现
接下来使用一个简单的数据集来演示逻辑回归。因变量Cure为是否治愈;自变量Intervention为是否接受治疗(分类变量),Duration为接受治疗的天数(连续变量)。
用glm()函数进行逻辑回归,其用法和lm类似,当进行逻辑回归时,规定family=binomial()即可。首先只纳入自变量Duration进行尝试:
#建立数据Cured = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1)Intervention = c("NO", "NO", "YES", "NO", "NO", "NO", "YES","NO", "NO", "NO", "NO", "NO", "YES","YES","YES","YES", "NO","YES", "YES", "YES", "YES", "NO" )Duration = c(7, 7,6, 5, 7, 4, 7, 6, 3, 7, 6, 3, 8, 8, 7, 9, 9, 7, 8, 5, 10, 9)A = data.frame(Cured,Intervention,Duration)#纳入一个自变量的逻辑回归M1 = glm(data = A, Cured~Duration,family = binomial()) summary(M1)
可以看到,summary的输出包括了和之前线性回归类似,有残差、回归系数及其显著性等。只是这里的假设检验不再是t检验,而是Z检验。此外,有时在研究报告中可以看到逻辑回归报告的参数是Wald值,这个Wald实际上就等于这里Z的平方,Wald检验的p值和这边Z检验的是一样的。
除此之外,这里还报告了很多有意义的指标。NULL deviance 指零模型的偏差,也就是当仅包括截距时的-2LL;Residual deviance指既包含截距也包含自变量时的 -2LL。如果NULL devianceAIC也是模型拟合指标,当有多个模型时可以利用AIC进行比较,同样越小越好。
下面可以对逻辑回归模型进行进一步的检验,包括利用-2LL进行卡方检验、R方计算、OR值及其置信区间计算等。
#利用-2LL进行卡方检验(模型拟合程度的指标) modelChi = M1$null.deviance - M1$deviance #两个-2LL的差值即衡量模型拟合性的指标 Chidf = M1$df.null - M1$df.residual # 卡方的自由度 Chisqprob = 1-pchisq(modelChi,Chidf) #卡方的显著性检验 Chisqprob # 得到卡方检验的p值,小于0.05显著说明该模型拟合良好! #下面计算R2,有几种算法 R2.hl = modelChi/M1$null.deviance #Hosmer and Lemeshow’s measure R2.cs = 1-exp((M1$deviance-M1$null.deviance)/nrow(A)) #Coxand Snell’s measure, 这里的22是样本量N R2.n = R2.cs/(1-(exp(-(M1$null.deviance/nrow(A))))) #Negelkerke’smeasure, 这里的22是样本量N #OR值 OR = exp(M1$coefficients) # OR(odd ratio)值 ORConfi = exp(confint(M1)) # OR值的置信区间下面进行加入两个自变量的逻辑回归,其实和上面几乎是一样的:
M2 = glm(data = A, Cured~Intervention+Duration,family = binomial())summary(M2)#之后进行卡方检验、R方计算、OR值计算和之前一样。#anovaanova(M1,M2) #卡方分析Chi2Compare=M1$deviance - M2$deviance ChiComparedf = M1$df.residual-M2$df.residual pchi = 1-pchisq(Chi2Compare,ChiComparedf) pchi # p值显著则说明模型2比起模型1能解释更多东西,需要保留第二个变对于逻辑回归同样可以进行模型诊断、回归假设检验(如多重共线性诊断、对数线性假设等),这个在这里不做重点介绍了。但是在这里很推荐使用基于R的统计软件JASP,几乎可以全面秒杀SPSS,而且做一般的统计也比R要更方便快捷,点点界面可以把上面几乎所有的关键统计量都完美输出,岂不美哉?下面是用JASP做(Crued~Duration)逻辑回归的输出:

机器学习的目的是分类、预测,那么这个逻辑回归模型的预测效果怎么样呢?由于还没讲到交叉验证的方法,这里仅用原始数据来演示一下预测。使用predict(模型,要预测的数据,输出类型)即可:
Yhat1 = predict(M1,A,type = 'response') #predict(model,newdata,type) Yhat2 = predict(M2,A,type = 'response') #预测概率值A$curedYhat1Yhat2
可以看到,方程M1和M2对于原始数据Y的预测概率。之后,我们可以设定一个概率的阈值(一般为0.5),如果超过阈值,就判定Y=1,不超过阈值,则判定Y=0。
若以0.5为阈值,就可以得到预测的分类结果,与实际分类结果对比就可以得到 混淆矩阵(confusion matrix),以此评判分类效果:Yhat1[Yhat1>0.5]=1;Yhat1[Yhat1<0.5]=0 #将概率大于0.5的分为1,小于0.5的分为0Yhat2[Yhat2>0.5]=1;Yhat2[Yhat2<0.5]=0table(A$Cured,Yhat1) #混淆矩阵:就是实际观测和预测是否匹配的表格table(A$Cured,Yhat2)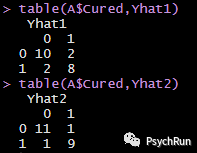
上面输出的就是混淆矩阵,因为是二分类,所以是2*2的表格。矩阵每一列代表预测值,每一行代表的是实际的类别,对角线上的就是正确预测的数量(本想细讲讲,但是觉得混淆矩阵太好理解了没啥好讲的)。根据混淆矩阵,可计算模型1的预测准确率为(10+8) /(10+8+2+2)=81.8%;模型2的预测准确率为20/22=90.9%。模型2在分类上要优于模型1。
只要是分类任务就会有混淆矩阵,因此混淆矩阵接下来的出镜率会极高。此外,模型预测效能的评估还可以用ROC曲线及其一系列指标(起码六七个,真·一系列)来评价,这部分打算之后专门来看。
注: 参考资料包括公众号荷兰心理统计联盟Play with R系列的逻辑回归部分、UCAS人工智能学院机器学习课程、B站R语言手把手系列视频以及其他网络综合资料,侵删。