【论文翻译】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
【论文】https://arxiv.org/abs/2204.12484v3
【github】GitHub - ViTAE-Transformer/ViTPose: The official repo for [NeurIPS'22] "ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation" and [Arxiv'22] "ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation"
摘要
虽然在设计中没有考虑到特定的领域知识,但plain vision
transformers在视觉识别任务中表现出了出色的性能。然而,很少有人努力揭示这种简单结构在姿态估计任务中的潜力。在本文中,我们通过一个简单的基线模型ViTPose,从模型结构的简单性、模型大小的可扩展性、训练范式的灵活性和模型之间知识的可移动性等方面展示了plain vision
transformers在姿态估计方面令人惊讶的良好能力。具体来说,ViTPose使用普通和非层次的视觉转换器作为骨干,为给定的人实例提取特征,并使用轻量级解码器进行姿态估计。利用可扩展的模型容量和变压器的高并行度的优势,它可以从100M参数扩展到1B参数,在吞吐量和性能之间设置一个新的帕累托前沿(Pareto front)。此外,ViTPose在注意力类型、输入分辨率、预训练和微调策略以及处理多个姿态任务方面非常灵活。我们还通过经验证明,大型ViTPose模型的知识可以通过一个简单的知识令牌轻松地转移到小型模型。实验结果表明,我们的基本ViTPose模型在具有挑战性的MS COCO关键点检测基准测试中优于代表性方法,而最大的模型在MS COCO测试开发集上设置了新的最先进的AP,即80.9 AP。代码和模型可以在https://github.com/ViTAE-Transformer/ViTPose上找到。
1. 介绍
人体姿态估计是计算机视觉的基本任务之一,具有广泛的实际应用[51,29]。它旨在定位人体解剖学的关键点,由于姿态重叠(occlusion)、截断(truncation)、尺度和人体外观的变化,它具有挑战性。为了解决这些问题,基于深度学习的方法已经取得了快速进展[37,42,36,50],这些方法通常使用卷积神经网络来解决具有挑战性的任务。
近年来,vision transformers[13,31,10,34,32]在许多视觉任务中显示出巨大的潜力。受其成功的启发,不同的vision transformers结构已经部署到姿态估计任务中。它们大多采用CNN作为主干,然后使用复杂结构的转换器对提取的特征进行细化,并对主体关键点之间的关系进行建模。例如,PRTR[23]结合了变压器编码器和解码器,以级联方式逐步细化估计关键点的位置。TokenPose[27]和TransPose[44]则采用编码器-only transformer结构来处理cnn提取的特征。另一方面,HRFormer[48]利用变压器直接提取特征,通过多分辨率并联变压器模块引入高分辨率表示。这些方法在姿态估计任务中取得了优异的性能。然而,它们要么需要额外的cnn来进行特征提取,要么需要精细地设计transformer结构以适应任务。这促使我们从相反的方向思考,普通vision transformers在姿态估计方面能做得多好?
为了找到这个问题的答案,我们提出了一个简单的baseline模型,称为ViTPose,并在MS COCO Keypoint数据集[28]上演示了它的潜力。具体来说,ViTPose使用普通和非分层的vision transformers[13]作为骨干,为给定的人实例提取特征映射,其中骨干预先训练了利用掩码图像建模任务,例如MAE[15],以提供良好的初始化。然后,一个轻量级解码器通过特征图的上采样和热点图的回归来处理提取的特征,该解码器由两个反褶积层和一个预测层组成。尽管在模型中没有精心设计,ViTPose在具有挑战性的MS COCO关键点测试开发集上获得了最先进的(SOTA)性能80.9 AP。值得注意的是,本文并没有声称算法的优越性,而是提出了一个简单可靠的 transformers 基线,具有更好的姿态估计性能。
除了卓越的性能外,我们还从简单性、可伸缩性、灵活性和可移植性等各个方面展示了ViTPose令人惊讶的好能力。1)为了简单,由于vision transformers具有强大的特征表示能力,ViTPose框架可以非常简单。例如,骨干编码器的设计不需要任何特定的领域知识,并且通过简单地堆叠几个transformers层来获得一个简单的非分层encoder结构。decoder可以进一步简化为单个上采样层,然后接上一个卷积预测层,性能下降可以忽略不计。这种结构上的简单使得ViTPose具有更好的并行性,从而在推理速度和性能上达到了新的帕累托前沿,如图1所示。2)此外,结构简单带来了ViTPose出色的可扩展性。因此,它受益于可扩展的预训练vision transformers的快速发展。具体地说,可以通过堆叠不同数量的transformers层和增加或减少特征维来轻松控制模型大小,例如,使用ViT-B、ViT-L或ViT-H来平衡各种部署需求的推断速度和性能。3)此外,我们证明了ViTPose在训练范式中非常灵活。ViTPose可以很好地适应不同的输入分辨率和特征分辨率,**并可以为更高分辨率的输入提供更准确的姿态估计结果**。除了通常在单个姿态数据集上训练ViTPose外,我们还可以通过非常灵活地添加额外的解码器对其进行修改,以适应多个姿态数据集,从而形成联合训练管道,并带来显著的性能改进。由于ViTPose中的解码器是相当轻量级的,因此这种训练模式只带来边际的(额外的)计算成本。此外,ViTPose在使用更小的未标记数据集进行预训练或使用冻结的注意力模块进行微调时,仍然可以获得SOTA性能,比完全预训练的微调范式需要更少的训练成本。4)最后,通过一个额外的可学习的知识 token,将大型ViTPose模型的知识转移到小型ViTPose模型,从而可以很容易地提高小型ViTPose模型的性能,证明了ViTPose良好的可转移性。
总之,本文的贡献有三方面。1)我们提出了一个简单而有效的人体姿态估计基线模型ViTPose。它在MS COCO Keypoint数据集上获得SOTA性能,甚至没有使用复杂的结构设计或复杂的框架。2)简单的ViTPose模型被证明具有令人惊讶的良好功能,包括结构的简单性、模型大小的可伸缩性、训练范式的灵活性和知识的可转移性。这些功能为基于vision transformers的姿态估计任务建立了强大的基线,并可能为该领域的进一步发展提供线索。3)在流行基准上进行综合实验,研究和分析ViTPose的能力。以一个非常大的视觉转换器模型ViTAE-G[52]为骨干,单个ViTPose模型在MS COCO Keypoint test-dev集中获得了最佳的80.9 AP
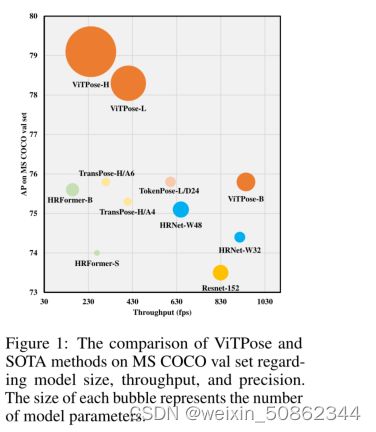
图1:MS COCO val集上ViTPose和SOTA方法在模型大小、吞吐量和精度方面的比较。每个气泡的大小代表模型参数的数量
2. 相关工作
2.1 用于姿态估计的vision transformers
姿态估计经历了从cnn[42]到视觉变压器网络的快速发展。 早期的工作倾向于将transformer视为更好的解码器[23,27,44],例如TransPose[44]直接处理cnn提取的特征来建模全局关系。TokenPose[27]通过引入额外的标记来估计被遮挡的关键点的位置,并对不同关键点之间的关系建模,从而提出了基于标记的表示。为了摆脱cnn对特征提取的影响,提出了HRFormer[48]使用变压器直接提取高分辨率特征。为了逐步融合HRFormer中的多分辨率特征,提出了一种精巧的并联变压器模块。这些基于变压器的姿态估计方法在流行的关键点估计基准上获得了优异的性能。然而,它们要么需要cnn进行特征提取,要么需要仔细设计变压器结构。目前在探索普通vision transformers在姿态估计任务中的潜力方面的努力很少。在本文中,我们通过提出一个简单而有效的基线模型ViTPose来填补这一空白,该模型基于普通的vision transformers。
2.2 vision transformers预训练
受ViT[13]成功的启发,提出了许多不同的vision transformers主干[31,43,40,55,39,52,38,53],它们通常在完全监督的设置下在ImageNet-1K[12]数据集上进行训练。最近,自监督学习方法[15,4]被提出用于训练普通视觉变压器。这些方法以掩码图像建模(MIM)为借口,为普通视觉转换器提供了良好的初始化。本文主要针对姿态估计任务,采用基于MIM预训练的普通视觉变形器作为骨干。此外,我们还探讨了使用ImageNet-1K进行预训练对于姿态估计任务是否必要。令人惊讶的是,我们发现使用较小的未标记姿态数据集进行预训练也可以为姿态估计任务提供良好的初始化
3. ViTPose
3.1 ViTPose的简单性
结构简单。本文的目标是为姿态估计任务提供一个简单而有效的vision transformers 基线,并探索普通和无层次vision transformers[13]的潜力。因此,我们尽量保持结构简单,并尽量避免花哨但复杂的模块,即使它们可能提高性能。为此,我们简单地在变压器主干之后附加了几个解码器层来估计关键点的热图,如图2 (a)所示。为了简单起见,我们在解码器层中不采用跳过连接或交叉注意力(kip-connections or cross-attentions),而是采用简单的反卷积层和预测层,如[42]。具体来说,给定一个人实例图像X∈![]() 作为输入,ViTPose首先通过 patch embedding 层将图像嵌入到tokens中,即F∈
作为输入,ViTPose首先通过 patch embedding 层将图像嵌入到tokens中,即F∈![]() ,其中d(默认为16)为 patch embedding 的下采样比,C为通道维数。在此之后,嵌入的tokens被多个vision transformers处理,每个变压器层由一个多头自注意(MHSA)层和一个前馈网络(FFN)组成,即:
,其中d(默认为16)为 patch embedding 的下采样比,C为通道维数。在此之后,嵌入的tokens被多个vision transformers处理,每个变压器层由一个多头自注意(MHSA)层和一个前馈网络(FFN)组成,即:
![]()
其中i表示第i个transformers层的输出,初始特征F0 = PatchEmbed(X)表示 patch embedding层之后的特征。需要指出的是每个transformers层的空间和通道尺寸都是恒定的。我们将骨干网的输出特征表示为Fout ∈ ![]()
我们采用两种轻量级解码器对骨干网提取的特征进行处理,并对关键点进行定位。第一个是经典的解码器。它由两个反卷积组成,每个反卷积块包含一个反卷积层,后面是批归一化[19]和ReLU[1]。按照以往方法的共同设置[42,50],每个块对特征图进行2次上采样。然后利用核尺寸为1 × 1的卷积层得到关键点的定位热图,即:
![]()
其中K∈![]() 表示估计的热图(每个关键点一个),Nk是要估计的关键点数量,对于MS COCO数据集设置为17。
表示估计的热图(每个关键点一个),Nk是要估计的关键点数量,对于MS COCO数据集设置为17。
虽然经典的解码器是简单和轻量级的,但我们也尝试了ViTPose中另一个更简单的解码器,由于vision transformers主干的强大表示能力,它被证明是有效的。具体来说,我们直接用双线性插值对特征图进行4次上采样,然后用ReLU和核大小为3 × 3的卷积层得到热图,即

尽管该解码器的非线性能力较小,但与经典解码器和以往代表性方法中精心设计的基于transformers的解码器相比,其性能具有竞争力,体现了ViTPose结构的简单性。
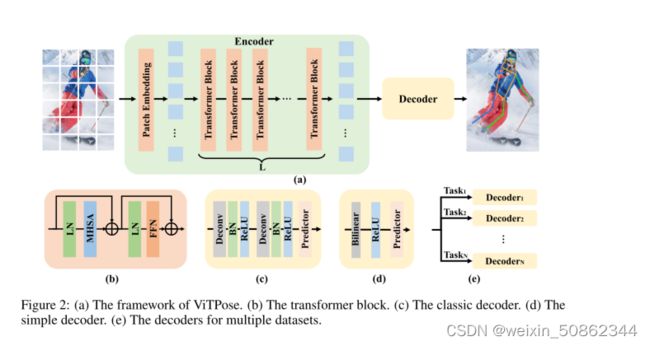
图2:(a) ViTPose的框架。(b)transformer块。(c)经典解码器。(d)简单解码器。(e)用于多个数据集的解码器
3.2 ViTPose的可扩展性
由于ViTPose结构简单,可以根据部署需求在图1的新帕累托前沿中选择一个点,通过堆叠不同数量transformers层,增加或减少特征维数,轻松控制模型大小。从这个意义上说,ViTPose可以受益于可扩展的预训练vision transformers的快速开发,而无需对其他部件进行太多修改。为了研究ViTPose的可伸缩性,我们使用预先训练的不同模型容量的骨干,并在MS COCO数据集上对其进行微调。例如,我们使用ViT-B, ViT-L, ViT-H [13], 和ViTAE-G[52]与经典解码器进行姿态估计,并观察到随着模型尺寸增加的一致性能增益。对于在预训练时使用大小为14 × 14的 patch embedding的ViT-H和ViTAE-G,我们使用零填充(zero padding)来制定与ViT-B和ViT-L相同设置的大小为16 × 16的 patch embedding
3.3 ViTPose的灵活性
预训练数据灵活性。使用ImageNet[12]预训练的骨干网的实际上已经成为获得良好初始化的一个常规。但是,除了姿态估计之外,它还需要额外的数据,这使得姿态估计任务对数据的要求更高。这就涉及到我们是否可以在整个训练阶段只使用姿态数据来放松数据要求。为了探索数据的灵活性,除了ImageNet[12]预训练的默认设置外,我们使用MAE[15]分别用MS COCO[28]和MS COCO与AI Challenger[41]的组合对主干进行预训练,从图像中随机屏蔽75%的补丁并重建这些被屏蔽的补丁。然后,我们使用预训练的权重来初始化ViTPose的主干,并在MS COCO数据集上对模型进行微调。令人惊讶的是,虽然姿态数据的体积比ImageNet小很多,但仅用姿态数据训练的ViTPose可以获得具有竞争力的性能,这意味着ViTPose可以从不同尺度的数据中灵活地学习良好的初始化。
分辨率的灵活性。我们改变ViTPose的输入图像大小和下采样比d,以评估其在输入和特征分辨率方面的灵活性。具体来说,为了使ViTPose适应更高分辨率的输入图像,我们只需调整输入图像的大小,并相应地训练模型。此外,为了使模型适应更低的下采样比,即更高的特征分辨率,我们只需改变patch embedding层的步幅,从而对重叠的tokens进行分区,并保留每个patch.的大小。我们表明,无论是更高的输入分辨率还是更高的特征分辨率,ViTPose的性能都有所提高
注意类型灵活性。由于注意力计算的二次计算复杂度和内存消耗,在较高分辨率的特征图上使用全注意力会造成巨大的内存占用和计算成本。基于相对位置嵌入的基于窗口的注意[25,26]已被探索,以减轻处理高分辨率特征映射的沉重内存负担。然而,由于缺乏全局上下文建模能力,对所有transformers块简单地使用基于窗口的注意会降低性能。针对这一问题,我们采用了两种技术:1)移动窗口(Shift window):不使用固定窗口进行注意力计算,而是使用Shift窗口机制[31]来帮助在相邻窗口之间传播信息;2)池化窗口(Pooling window)。除了移动窗口(Shift window)机制,我们还尝试了另一种解决方案——池化。具体来说,我们将每个窗口的token集合在一起,以获得窗口内的全局上下文特性。然后将这些特性输入到每个窗口中,作为键和值token,以实现跨窗口的特性通信。此外,我们证明了这两种策略是互补的,可以共同提高性能和减少内存占用,不需要额外的参数或模块,只需要对注意力计算进行简单的修改。
整合的灵活性。如NLP领域[30,2]所示,预训练的transformers模型可以很好地推广到其他部分参数调优的任务。为了研究它是否仍然适用于vision transformers,我们在MS COCO上对ViTPose进行了微调,其中所有参数都未冻结,MHSA模块分别冻结,FFN模块冻结。我们通过经验证明,当MHSA模块冻结时,ViTPose获得了与完全微调设置相当的性能。
任务的灵活性。由于ViTPose中的解码器相当简单和轻量级,我们可以采用多个解码器,通过共享骨干编码器来处理多个姿态估计数据集,而无需太多额外的成本。我们为每次迭代从多个训练数据集中随机采样实例,并将它们输入骨干和解码器,以估计对应于每个数据集的热图。
3.4 ViTPose的可移植性
提高较小模型性能的一种常用方法是从较大模型中转移知识,即知识蒸馏[17,14]。具体来说,给定一个教师网络T和学生网络S,一种简单的蒸馏方法是增加一个输出蒸馏损失![]() ,使学生网络的输出模仿教师网络的输出,例如:
,使学生网络的输出模仿教师网络的输出,例如:
![]()
其中,k和Kt是在相同输入条件下,学生和教师网络的输出。
除了上述常用的方法外,我们还探索了一种基于token的蒸馏方法来连接大小模型,这是对上述方法的补充。具体来说,我们随机初始化一个额外的可学习知识token t,并将其附加到教师模型的patch embedding层之后的视觉token中。然后,我们冻结训练有素的教师模型,只调优几个epoch的知识令牌来获得知识,即:
![]()
其中![]() 是ground truth热图,X是输入图像,
是ground truth热图,X是输入图像,![]() 表示老师的预测,t *表示使损失最小化的最优令牌。在此之后,知识令牌t *被冻结,并在训练过程中与学生网络中的视觉token连接,以将知识从教师网络传输到学生网络。因此,学生网络的损失是
表示老师的预测,t *表示使损失最小化的最优令牌。在此之后,知识令牌t *被冻结,并在训练过程中与学生网络中的视觉token连接,以将知识从教师网络传输到学生网络。因此,学生网络的损失是
![]()
式中,![]() 和
和![]() 分别为token蒸馏损失和输出蒸馏损失与token蒸馏损失的组合
分别为token蒸馏损失和输出蒸馏损失与token蒸馏损失的组合
4.实验
实验部分就不写了,毕竟也没什么人能复现这种大实验