数据科学导论学习小结——其二
数据科学导论学习小结——其二
这是笔者大学二年级必修科目《数据科学基础》个人向笔记整理的第二部分,包含第四、五两个章节。本笔记内容基于清华大学出版社《数据科学导论-探索数据的奥秘》的相关知识。对于同样学习本门学科的读者可以此做参考方便您的学习;对于其他对本学科或相关领域感兴趣的读者,也可以在对本篇的阅读中激发兴趣。
文章目录
- 数据科学导论学习小结——其二
- 第四章 python基础
-
- 4.1 python常用的数据结构
-
- (1)numpy.ndarray
- (2)Pandas.DataFrame
- 4.2 python数据读入
-
- (1)numpy.loadtxt
- (2)pandas.read_csv 或 pandas.read_excel
- (3)读取在线数据
- 第五章 探索性数据分析EDA
-
- 5.1 数据检查
-
- (1)数据的意义及规模
- (2)特征的类型及意义
- (3)初步排除数据泄露
- 5.2 数据预处理
-
- (1)缺失值处理
- (2)异常处理
- (3)冗余处理
- 5.3 描述性统计
-
- (1)位置性测度
- (2)离散性测度
- (3)图形化描述统计
- 小结
第四章 python基础
作者默认读者已经掌握python语言的基本语法、流程控制等相关知识并已经熟练使用自己喜爱的编辑器,在此基础上作者将介绍python中与数据处理相关的知识。
4.1 python常用的数据结构
基本的列表、元组、字典、集合默认掌握,以下主要介绍numpy.ndarray与Pandas.DataFrame两种数据结构的基本知识。
(1)numpy.ndarray
numpy.ndarray 常用来存储数据类型一致的元素,使用时需要导包。
导包:
import numpy as np
构造方法:np.array( )
方法参数:列表,用来表示元素
x = [1, 2, 3, 4, 5, 6]
my_ndarray = np.array(x)
构造方法:np.random.randn(x, y)
方法参数:整数,代表维度
my_ndarray = np.random.randn(4, 5)
numpy.ndarray 对象的 + 操作是将其对应的元素相加:
my_ndarray1 = np.array([1, 2, 3, 4, 5, 6])
my_ndarray2 = np.array([1, 0, 1, 0, 1, 0])
my_sum = my_ndarray1 + my_ndarray2
print(my_sum)
'''
输出结果
[2 2 4 4 6 6](注意区别一维np.ndarray与列表的区别)
'''
numpy.ndarray 对象的 reshape( ) 方法:重塑数组的维度
方法参数:元组,用来表示数组维度
my_sum = my_sum.reshape((2, 3))
print(my_sum)
'''
输出结果
[[2 2 4]
[4 6 6]]
'''
numpy.ndarray 对象元素的访问:用切片的方式完成
格式:数组名[元素序号](多维时则注明各维度元素序号并用“,”隔开)
print(my_sum[0, 2]) #返回第一行第三列的元素
'''
输出结果
4
'''
numpy.ndarray 一旦初始化,数组的大小也就固定下来了!
(2)Pandas.DataFrame
Pandas.DataFrame 又叫数据框结构,不要求存储的数据类型一致,且可以完全等同于一个包含行索引和列标题的二维表格。使用时需要导包。
导包:
import pandas as pd
import numpy as np
构造方法:pd.DataFrame(data, index = , columns = , dtype =)
方法参数:
data:字典、np.ndarray ,代表数据
index:列表,指定行索引值
columns:列表,指定列标题
dtype:代表读入的数据类型
my_dataframe = pd.DataFrame(np.random.randn(4, 5),
index = ['a', 'b', 'c', 'd'],
columns = ['A', 'B', 'C', 'D', 'E'])
print(my_dataframe)
'''
输出结果
A B C D E
a 0.923095 -0.938284 -1.341674 0.036582 1.645969
b 1.647582 1.189909 -1.285119 -2.367142 -0.466558
c -0.167237 2.026707 1.690953 1.250200 -0.296057
d 0.320652 0.447191 1.068786 -0.514044 -0.610406
'''
pandas.DataFrame 对象元素的访问方法1:通过列标题访问,获取指定列构成的子表,返回的仍是 pandas.DataFrame 对象
格式:数据框名[[‘列标题1’, ‘列标题2’, …]]
print(my_dataframe[['B', 'C']])
print(my_dataframe[['B']])
'''
输出结果
B C
a -0.938284 -1.341674
b 1.189909 -1.285119
c 2.026707 1.690953
d 0.447191 1.068786
B
a -0.938284
b 1.189909
c 2.026707
d 0.447191
'''
pandas.DataFrame 对象元素的访问方法2:通过列标题访问,获取指定单列构成的 series 序列,返回的是 pandas.series 对象
格式:数据框名[列标题]
print(my_dataframe['B'])
'''
输出结果
a -0.938284
b 1.189909
c 2.026707
d 0.447191
Name: B, dtype: float64
'''
pandas.DataFrame 对象元素的访问方法3:通过 iloc 方法访问指定行序号,获取指定单行构成的 series 序列,返回的是 pandas.series 对象
格式:数据框名.iloc[行号]
print(my_dataframe.iloc[1])
'''
输出结果
A 1.647582
B 1.189909
C -1.285119
D -2.367142
E -0.466558
Name: b, dtype: float64
'''
pandas.DataFrame 对象元素的访问方法4:通过 loc 方法访问指定行标题,获取指定单行构成的 series 序列,返回的是 pandas.series 对象
格式:数据框名.loc[‘行标题’]
print(my_dataframe.loc['b'])
'''
输出结果
A 1.647582
B 1.189909
C -1.285119
D -2.367142
E -0.466558
Name: b, dtype: float64
'''
4.2 python数据读入
(1)numpy.loadtxt
numpy.loadtxt 可以将指定文件的数据加载到数组,支持纯文本文件(.txt, .csv等),返回 numpy.ndarray 的数据结构。
具体方法:numpy.loadtxt(data, delimiter = , dtype = )
方法参数:
data 数据文件,必要时添加完整路径
delimiter 字符串 指定数据之间的分隔符
dtype 代表读入的数据类型
import numpy as np
x = np.loadtxt('global-earthquakes.csv', delimiter = ',', dtype = int)
(2)pandas.read_csv 或 pandas.read_excel
pandas.read_csv 或 pandas.read_excel 可以将指定表格文件中的数据导入到数据框结构中并尽可能保留原始的数据类型,返回 pandas.DataFrame 的数据结构。
具体方法:pandas.read_csv(data, header = , names = , sep = , usecols = )
方法参数:
data 数据文件,必要时添加完整路径
sep 字符串 指定数据之间的分隔符
header 整数 默认为0 用来指定某一行作为列标题
names 列表 当header = None时启用,命名列标题
usecols 列表 提取文件指定列返回一个数据子集,该列表中的值必须是已经存在的列名
import pandas as pd
data = pd.read_csv('iris.csv', header = None, names = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid'])
(3)读取在线数据
pandas.read_csv 支持直接从网络上读取文件,只需要提供文件的url地址。
url = 'http://raw.githubuercontent.com/justmarkham/DAT8/master/data/bikeshare.csv'
bikes = pd.read_csv(url)
print(bikes.head())
第五章 探索性数据分析EDA
探索性数据分析(EDA)是得到数据后第一步工作
EDA的工作包含:
①数据检查:数据意义及规模,特征类型及意义,初步排除数据泄露
②数据预处理:缺失处理,异常处理,冗余处理
③数据初步分析:描述性统计(数据类型不同,分析方法不同)
5.1 数据检查
(1)数据的意义及规模
包括是否结构化、包含多少样本、特征列个数、样本类别划分等基本信息
(2)特征的类型及意义
包括每一列特征存储的数据类型是什么,对应了何种现实意义
通常将数据类型进行如下的分类:
①数值型(整数、浮点数):可以比较大小,支持数学运算
②排序型(整数、字符串):可以比较大小,不支持数学运算
③逻辑型(Boolean、整数0或1):不可以比较大小,二选一
④类别型(整数、字符串):不可以比较大小,多选一
数值型数据常用于计算,其他数据则用于分组、筛选
还可以将数据类型作更加具体的由低级到高级的分类:
①定类数据(类别型数据)
②定序数据(排序型数据)
③定距数据:描述事物类别或次序之间的间距,不仅能区分事物不同类型并排序,且可以精确指出差距的大小(是一种真正数量化的数值,可以进行加减乘除,“0”强行规定但存在含义,不代表完全没有)
④定比数据:在定距数据基础上扩展可作为比率的基数(一般需要统一的单位,如米、厘米、秒等,“0”代表完全没有的含义)
区分定距数据与定比数据的方法是判断“0”是否有实际的物理意义
| 数据类型 | 基本特征 | 关系与运算 | 举例 |
|---|---|---|---|
| 定类数据 | 无次序分类 | =,<> | 性别,政党等 |
| 定序数据 | 有次序分类 | =,<>,>,< | Bug严重级别,年级等 |
| 定距数据 | 有距离度量,无绝对零点 | +,-,*,/ | 温度,成绩等 |
| 定比数据 | 有绝对零点 | 比例除法运算 | 长度,重量,年龄等 |
高级数据可以通过处理降维成为低级数据
以下为代码举例:
import pandas as pd
my_data = pd.read_csv("titanic.csv") # 读取csv数据
#print(my_data.head(5)) # 用于显示前五行数据
print(my_data.info()) # 得到一些对数据的基本分析
print("Table1.Mean Fare of Group")
x = my_data.groupby(['Pclass']).mean() # 按类计算相关数值,注意此时全部特征列数据都参与了计算
print(x['Fare']) # 只取Fare特征值查看情况
'''
输出结果
[5 rows x 12 columns]
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
Table1.Mean Fare of Group
Pclass
1 84.154687
2 20.662183
3 13.675550
Name: Fare, dtype: float64
'''
以上代码用到的方法:
pandas.DataFrame 对象的 head(x) 方法:用于单独显示数据的前X行,不写参数则默认为5行
pandas.DataFrame 对象的 info( ) 方法:用于返回一些对数据的基本分析
pandas.DataFrame 对象的 value 属性:返回一个存放着表格数据的二维数组,返回 numpy.ndarray 类型
pandas.DataFrame 对象的 groupby( ) 方法:指定一列并将全部数据按此列的不同值分组,返回 pandas.DataFrameGroupBy 类型
pandas.DataFrame 对象或 pandas.DataFrameGroupBy 对象的 mean( ) 方法:求数据的平均值
数据类型例题:
1.邮轮仓位等级分为3档:1(一等舱)、2(二等舱)和3(三等舱),舱位等级属于:定序数据
2.某电商网站评价客户满意度分为5档:5(很满意)、4(满意)、3(一般)、2(不满意)和1(很不满意),满意度属于:定距数据
(3)初步排除数据泄露
数据泄露指用来作为模型输入的特征中包含了泄露输出目标的信息,而这种特征在真实应用中又是无法获得的
举例:鸢尾花数据中人为添加的id号码会泄露输出目标信息
如何甄别数据泄露:
①特征真的是数据本身数量或性质的体现,还是某种人为的定义
②新的数据是自动具备的这个特征,还是需要人工定义
③对数据进行预处理时,训练集是否影响了测试集
5.2 数据预处理
(1)缺失值处理
对于缺失值的处理方式,有丢弃和填充两种
①当样本容量足够大,缺失值占少数时,选择直接丢弃缺失的数据
以下为代码举例:
import pandas as pd
my_data = pd.read_csv("titanic.csv") # 读取数据
print(my_data.head(15)) # 显示前15条
my_fil_data1 = my_data.dropna(axis = 0) # 按行将缺失值进行删除
print(my_fil_data1.head(7))
my_fil_data2 = my_data.dropna(axis = 1) # 按列将缺失值进行删除
print(my_fil_data2.head(7))
'''
输出结果
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q
6 7 0 1 McCarthy, Mr. Timothy J male 54.0 0 0 17463 51.8625 E46 S
7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S
8 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27.0 0 2 347742 11.1333 NaN S
9 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14.0 1 0 237736 30.0708 NaN C
10 11 1 3 Sandstrom, Miss. Marguerite Rut female 4.0 1 1 PP 9549 16.7000 G6 S
11 12 1 1 Bonnell, Miss. Elizabeth female 58.0 0 0 113783 26.5500 C103 S
12 13 0 3 Saundercock, Mr. William Henry male 20.0 0 0 A/5. 2151 8.0500 NaN S
13 14 0 3 Andersson, Mr. Anders Johan male 39.0 1 5 347082 31.2750 NaN S
14 15 0 3 Vestrom, Miss. Hulda Amanda Adolfina female 14.0 0 0 350406 7.8542 NaN S
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
6 7 0 1 McCarthy, Mr. Timothy J male 54.0 0 0 17463 51.8625 E46 S
10 11 1 3 Sandstrom, Miss. Marguerite Rut female 4.0 1 1 PP 9549 16.7000 G6 S
11 12 1 1 Bonnell, Miss. Elizabeth female 58.0 0 0 113783 26.5500 C103 S
21 22 1 2 Beesley, Mr. Lawrence male 34.0 0 0 248698 13.0000 D56 S
23 24 1 1 Sloper, Mr. William Thompson male 28.0 0 0 113788 35.5000 A6 S
PassengerId Survived Pclass Name Sex SibSp Parch Ticket Fare
0 1 0 3 Braund, Mr. Owen Harris male 1 0 A/5 21171 7.2500
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 1 0 PC 17599 71.2833
2 3 1 3 Heikkinen, Miss. Laina female 0 0 STON/O2. 3101282 7.9250
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 1 0 113803 53.1000
4 5 0 3 Allen, Mr. William Henry male 0 0 373450 8.0500
5 6 0 3 Moran, Mr. James male 0 0 330877 8.4583
6 7 0 1 McCarthy, Mr. Timothy J male 0 0 17463 51.8625
'''
以上代码用到的方法:
pandas.DataFrame 对象的 dropna( axis = ) 方法:用于删除含有缺失值的数据
方法参数:
axis 整数 当 axis = 0 时表示按行删除;当 axis = 1 时表示按列删除
②当样本容量不够大,选择填补缺失的数据(填补是止损手段而非加分手段)
以下为代码举例:
import pandas as pd
my_data = pd.read_csv("titanic.csv") # 读取数据
mean_Age = int(my_data[['Age']].mean()[0]) # 计算年龄的平均值,这里需要切片得到具体数值,否则是一个pandas.DataFrame对象
my_dict = {'Age': mean_Age, 'Cabin': 'haha'} # 决定填充值
my_fil_data3 = my_data.fillna(my_dict) # 进行字典填充
print(my_fil_data3.head(7))
my_fil_data4 = my_data.fillna(method = 'ffill') # 进行临近值填充
print(my_fil_data4.head(7))
'''
输出结果
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 haha S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 haha S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
5 6 0 3 Moran, Mr. James male 29.0 0 0 330877 8.4583 haha Q
6 7 0 1 McCarthy, Mr. Timothy J male 54.0 0 0 17463 51.8625 E46 S
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 C85 S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 C123 S
5 6 0 3 Moran, Mr. James male 35.0 0 0 330877 8.4583 C123 Q
6 7 0 1 McCarthy, Mr. Timothy J male 54.0 0 0 17463 51.8625 E46 S
'''
以上代码用到的方法:
pandas.DataFrame 对象的 fillna( method = ) 方法:用于填充数据的缺失值
当 fillna( ) 方法以一个字典作参数,则会相应的对应不同特征取不同值
当 fillna( ) 方法不以字典作参数而启用 method 参数时:
method 字符串 ffill表示用缺失值之前最邻近的有效值填充,bfill表示用缺失值之后最邻近的有效值填充
(2)异常处理
利用最基本的统计学方法,存在一些处理异常的常用手段:结合实际意义的有效范围判断、基于正态分布z-score的判断、无正态分布约束的四分位距(IQR)判断,按这些方法判断为异常值,如果确定出错,则丢弃或替换;如果不能确定出错,则增大样本容量
①结合实际意义的有效范围判断:利用常识或专业知识判断
②基于正态分布z-score的判断:z-score定义
z = x − x ˉ s z =\frac{x-\bar{x}}{s} z=sx−xˉ
其中, x ˉ \bar{x} xˉ为统计均值, s s s为样本集标准差,z-score实质是以标准差为单位衡量的个体偏离统计均值的程度,是一个无量纲的数
当z-score绝对值大于3时,数据就可能存在异常
③无正态分布约束的四分位距(IQR)的判断:IQR定义
假设样本容量N,将所有样本按考察特征取值从小到大排列,排在0.25N,0.5N,0.75N的特征值为第1、2、3个四分位数,IQR即是第3个和第1个四分位数的差值
x < q 1 − 1.5 × I Q R x < q_1 -1.5\times IQR x<q1−1.5×IQR 或 x > q 3 + 1.5 × I Q R x > q_3 +1.5\times IQR x>q3+1.5×IQR 代表异常值
x < q 1 − 3 × I Q R x < q_1 - 3\times IQR x<q1−3×IQR 或 x > q 3 + 3 × I Q R x > q_3 + 3\times IQR x>q3+3×IQR 代表极端异常值
(3)冗余处理
删除数据中的重复信息
①对重复行的处理:
pandas.DataFrame 对象的 duplicated( ) 方法:用来判断是否存在重复行
pandas.DataFrame 对象的 drop_duplicates( ) 方法:用来直接删除复行
②对重复列的处理:列冗余分为简单重复、一元线性依赖、多元线性依赖
Ⅰ.简单重复:按列提取即可避免重复
Ⅱ.一元线性依赖:如果一个特征 C 2 C_2 C2 可以通过另一个特征 C 1 C_1 C1 线性变换得到,即满足
C 2 = k C 1 + b C_2 = kC_1 + b C2=kC1+b
其中,k和b都是常数,则可以说 C 2 C_2 C2 线性依赖于 C 1 C_1 C1
以下为代码举例:
import pandas as pd
my_data = pd.read_csv("iris.csv", header = None, names = ['sepel_length', 'sepel_width', 'petal_length', 'petal_width', 'target']) # 读取、提取数据
print(my_data.corr(method = 'pearson')) # 计算线性相关系数(参数默认可以不加)
'''
输出结果
sepel_length sepel_width petal_length petal_width
sepel_length 1.000000 -0.109369 0.871754 0.817954
sepel_width -0.109369 1.000000 -0.420516 -0.356544
petal_length 0.871754 -0.420516 1.000000 0.962757
petal_width 0.817954 -0.356544 0.962757 1.000000
'''
以上代码用到的方法:
pandas.DataFrame 对象的 corr( ) 方法:用于求两两特征的线性相关系数
当两个特征系数线性相关系数接近1或-1,两个特征存在强线性相关,有较大冗余
当两个特征系数线性相关系数等于0,两个特征没有线性相关性
该方法也可以在后面的机器学习中,用于测试每个特征与结果是否存在线性相关,以此进行特征提取
Ⅲ.多元线性依赖:某个特征不能由另一个特征完全描述,但却可以被另外几个特征的线性组合表达,此时采用主成分分析法PCA
PCA具体可参阅站内资料或博主本人额外整理的资料,以下粗略介绍
数据集在某方向的投影方差最大:则最大程度保存原始数据信息(主方向)
数据集在某方向的投影方差最小:则是随机扰动,不重要(次方向)
PCA方法可以设定阈值,保留主成分
以下为代码举例:
import numpy as np
from sklearn import datasets
from sklearn.decomposition import PCA # 核心库
from matplotlib import pyplot as plt
my_iris = datasets.load_iris() # 自带鸢尾花数据集导入
# print(type(my_iris.data)) # 答案是numpy.ndarray
my_pca = PCA(n_components = 0.95) # PCA实例对象,其参数代表保留投影方差累计超过总体95%的前k个分量
post_proc = my_pca.fit_transform(my_iris.data) # fit_transform()方法对应主成分分解
print("原始数据的尺寸是:", my_iris.data.shape, "\n即包含:", my_iris.data.shape[1], "维度特征\n")
print("PCA后留下的主要成分数据尺寸是:", post_proc.shape, "\n即满足要求的主要成分维度是:", post_proc.shape[1], "\n")
print("PC1所占总方差的比例为:", my_pca.explained_variance_ratio_[0]) # PCA对象的属性,分别表示主分量方差占比
print("PC2所占总方差的比例为:", my_pca.explained_variance_ratio_[1])
print("两个主成分所占总方差的比例为:", my_pca.explained_variance_ratio_.sum()) # 发现超过阈值
print("两个主方向矢量为:")
print(my_pca.components_) # PCA对象的属性,保存了两个主方向
plt.scatter(post_proc[:, 0], post_proc[:, 1], c = my_iris.target) # 以两个主方向作为新的坐标画散点图
plt.gca().set_xlabel('PC1')
plt.gca().set_xlabel('PC2')
plt.show()
'''
输出结果
原始数据的尺寸是: (150, 4)
即包含: 4 维度特征
PCA后留下的主要成分数据尺寸是: (150, 2)
即满足要求的主要成分维度是: 2
PC1所占总方差的比例为: 0.9246187232017271
PC2所占总方差的比例为: 0.053066483117067825
两个主成分所占总方差的比例为: 0.977685206318795
两个主方向矢量为:
[[ 0.36138659 -0.08452251 0.85667061 0.3582892 ]
[ 0.65658877 0.73016143 -0.17337266 -0.07548102]]
'''
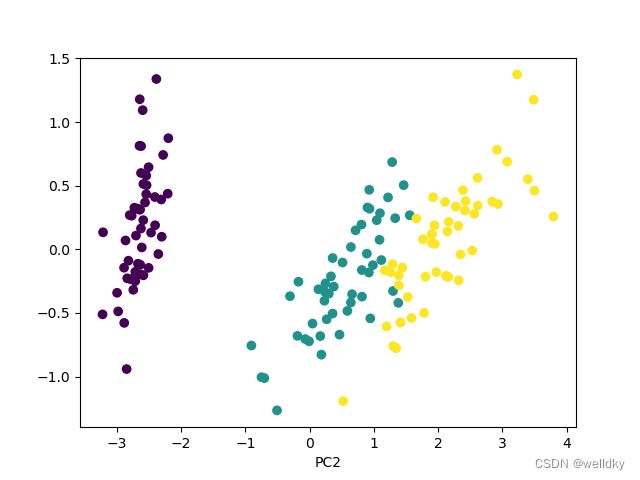
经过PCA后,可以把返回的主分量数据作为新的特征送交后续模型处理
5.3 描述性统计
在EDA中,进行完数据的预处理后要对数据进行描述性统计,包括位置性测度计算、离散性测度计算、图形化描述,其中,前两项只能用于数值型数据
(1)位置性测度
包括算术平均、中位数、p百分位数、众数等,用来反映样本集合中心成员或特定成员在所考察数域或空间的位置
①算术平均:对所有考察的样本求统计平均,最常用,但易受极端值影响
x ˉ = 1 n ∑ i = 1 n x i \bar{x} = \frac{1}{n}\sum_{i=1}^nx_i xˉ=n1i=1∑nxi
②中位数:排序后中间位置的一个数(样本容量奇数),或两个数的平均(样本容量偶数),对极端值不敏感
对称分布:算术平均接近中位数
正倾斜:算术平均大于中位数
负倾斜:算术平均小于中位数
③第p百分位数:从小到大排序后排序在第p%的样本取值,当样本容量足够大,第p百分位数相对稳定,不会受到样本容量影响
第p百分位数的计算方法:假设有n个数据,求其第p百分位数
计算n*p%的结果:Ⅰ.如果不是整数,向上取整就是第p百分位数;Ⅱ.如果是整数,则取该整数和其下一个整数的平均值作为第p百分位数
④众数:出现次数最多的值,有多个众数则为双峰/多峰分布
以下为代码举例:
import pandas as pd
import numpy as np
my_data = pd.read_csv("titanic.csv")
print("对Fare的位置性测度统计结果:")
print("均值:", my_data[['Fare']].mean()[0])
print("中位数:", my_data[['Fare']].median()[0])
print("第25百分位数:", my_data[['Fare']].quantile(q = 0.25)[0])
print("众数:", my_data[['Fare']].mode().values[0, 0])
'''
输出结果
对Fare的位置性测度统计结果:
均值: 32.2042079685746
中位数: 14.4542
第25百分位数: 7.9104
众数: 8.05
'''
以上代码用到的方法:
pandas.DataFrame 对象的 mean( )、median( )、quantile( q = )、mode( ) 分别代表均值,中位数,第q百分位数,众数
前三种方法返回的均是 pandas.series 对象,对其值可以直接切片访问
第四种方法返回的仍是 pandas.DataFrame 对象,要获取值可以利用 value 属性(其 value 属性是一个 numpy.ndarray 对象)
(2)离散性测度
包括极差、方差/标准差、变异系数等
①极差:集合中最大值和最小值的差异,对极值敏感
②方差/标准差:方差为所有样本值相对于均值的偏差的平方求近似平均,标准差为方差的平方根,反映的都是样本的离散性
V a r = ∑ i = 1 n ( x i − x ˉ ) 2 n − 1 Var = \frac{\sum_{i=1}^n(x_i-\bar{x})^2}{n-1} Var=n−1∑i=1n(xi−xˉ)2
s = V a r s = \sqrt{Var} s=Var
③变异系数:标准差除以均值乘以100%,消除量纲的影响
C V = s x ˉ × 100 % CV = \frac{s}{\bar{x}}\times100\% CV=xˉs×100%
以下为代码举例
import pandas as pd
import numpy as np
my_data = pd.read_csv("titanic.csv")
print("对Fare的离散性测度统计结果:")
print("变化范围:[", my_data[['Fare']].min()[0], "\t", my_data[['Fare']].max()[0], "]")
print("极差:", my_data[['Fare']].max()[0] - my_data[['Fare']].min()[0])
print("方差:", my_data[['Fare']].var()[0])
print("标准差:", my_data[['Fare']].std()[0])
print("变异系数:", my_data[['Fare']].std()[0] / my_data[['Fare']].mean()[0])
print(my_data[['Fare']].describe())
'''
输出结果
对Fare的离散性测度统计结果:
变化范围:[ 0.0 512.3292 ]
极差: 512.3292
方差: 2469.436845743117
标准差: 49.693428597180905
变异系数: 1.5430725278408517
Fare
count 891.000000
mean 32.204208
std 49.693429
min 0.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 512.329200
'''
以上代码用到的方法:
pandas.DataFrame 对象的 min( )、max( )、var( )、std( ) 分别代表最大值,最小值,方差,标准差
返回的均是 pandas.series 对象,对其值可以直接切片访问
极差,变异系数需要通过公式额外计算获得
pandas.DataFrame 对象的 describe( ) 方法:一次性计算多个描述性统计变量
(3)图形化描述统计
包括直方图、箱型图、分组统计的柱状图、散点图等
①直方图:反映数据分布
以下为代码举例:
import pandas as pd
import matplotlib.pyplot as plt
my_data = pd.read_csv("titanic.csv")
my_data[['Fare']].hist(bins = 40, figsize = (18, 5), xlabelsize = 16, ylabelsize = 16)
plt.show()
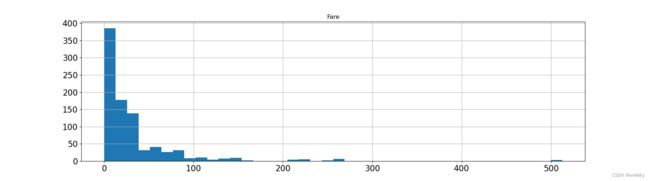
以上代码用到的方法
pandas.DataFrame 对象的 hist( bins = , figsize = , xlabelsize = , ylabelsize = ) 方法:绘制直方图
具体参数如下:
bins 整数 指定区间(直方条)个数,默认为10
figsize 数值 指定图片大小
xlabelsize/ylabelsize 整数 指定坐标轴字体大小
②箱型图:刻画分布,通过重要的百分位数界定数据的主要分布
以下为代码举例:
import pandas as pd
import matplotlib.pyplot as plt
my_data = pd.read_csv("titanic.csv")
my_data[['Fare']].boxplot()
plt.show()
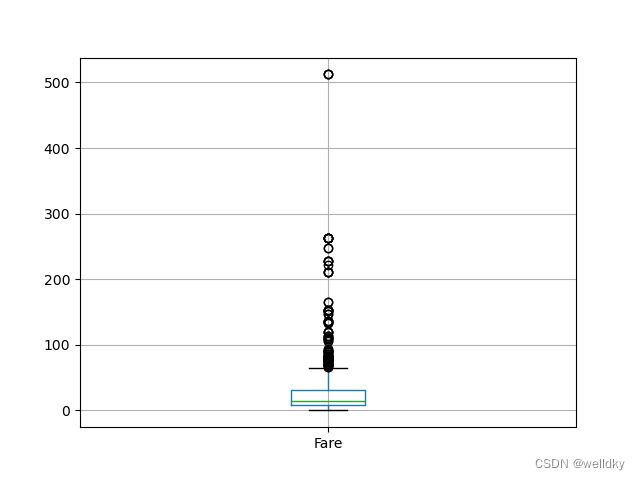
以上代码用到的方法
pandas.DataFrame 对象的 boxplot( ) 方法:绘制箱型图
箱型内的是位于第1、3百分位数之间的数据
上下两条黑色横线表示上、下边界值(异常值边界),其他点表示异常值
③分组统计的柱状图:非数值型特征分组后对各分组频次统计绘制的柱状图
以下为代码举例1:
import pandas as pd
import matplotlib.pyplot as plt
my_data = pd.read_csv("titanic.csv")
my_plot_data = my_data[['Pclass']].groupby(['Pclass']).size()
print(my_plot_data)
my_plot_data.plot(kind = 'bar')
plt.show()
#分组统计
print("表1. 按舱位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的均值")
print(my_data[['Fare', 'Age', 'SibSp', 'Parch', 'Pclass']].groupby(['Pclass']).mean())
print("\n\n表2. 按舱位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的标准差")
print(my_data[['Fare', 'Age', 'SibSp', 'Parch', 'Pclass']].groupby(['Pclass']).std())
'''
输出结果
Pclass
1 216
2 184
3 491
dtype: int64
表1. 按舱位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的均值
Fare Age SibSp Parch
Pclass
1 84.154687 38.233441 0.416667 0.356481
2 20.662183 29.877630 0.402174 0.380435
3 13.675550 25.140620 0.615071 0.393075
表2. 按舱位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的标准差
Fare Age SibSp Parch
Pclass
1 78.380373 14.802856 0.611898 0.693997
2 13.417399 14.001077 0.601633 0.690963
3 11.778142 12.495398 1.374883 0.888861
'''
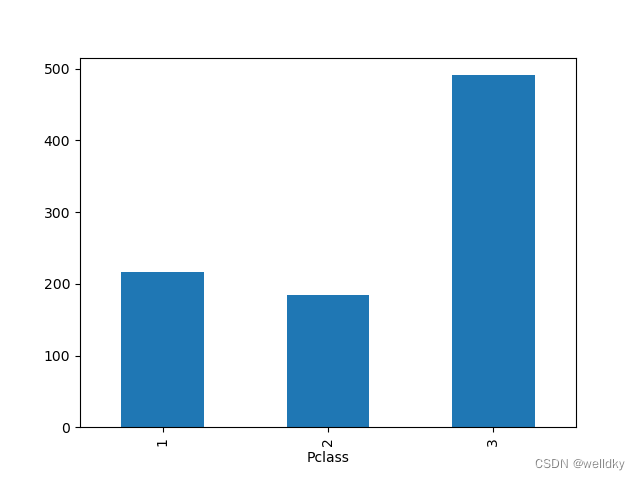
以上代码用到的方法:
pandas.DataFrameGroupBy 对象的 size( ) 方法:统计各类样本个数
pandas.DataFrame 对象的 plot( kind =, ) 方法:绘制图形
具体参数:
kind 字符串 绘制图片类型,默认折线图,这里"bar"代表柱状图
以下为代码举例2:
import pandas as pd
import matplotlib.pyplot as plt
my_data = pd.read_csv("titanic.csv")
#借助分组、筛选的图形化描述
gender_dst_org = my_data[['Sex']].groupby(['Sex']).size()
print("数据文件中全部非空数据的性别情况")
print(gender_dst_org, '\n')
my_filter = my_data[my_data.Survived == 1]
gender_dst_srv = my_filter[['Sex']].groupby(['Sex']).size()
print("数据文件中幸存者的性别情况")
print(gender_dst_srv, '\n')
my_tmp = pd.concat([gender_dst_org, gender_dst_srv], axis = 1)
my_plot_data = my_tmp.rename(columns = {0: 'Total', 1:'Survived'}) # 对列重命名
print(my_plot_data)
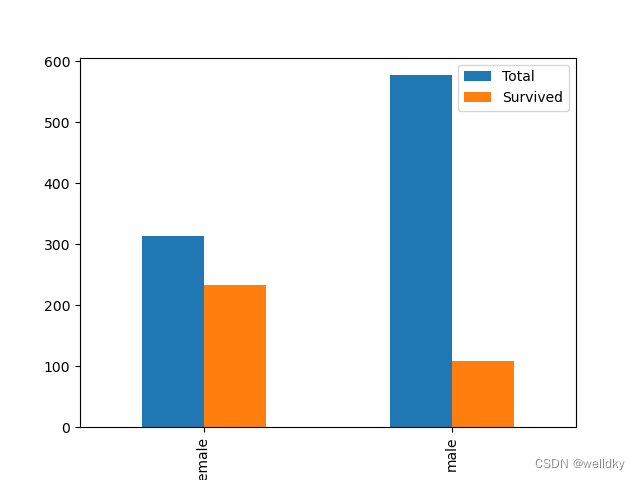
my_plot_data.plot(kind = 'bar')
plt.show()
'''
输出结果
数据文件中全部非空数据的性别情况
Sex
female 314
male 577
dtype: int64
数据文件中幸存者的性别情况
Sex
female 233
male 109
dtype: int64
Total Survived
Sex
female 314 233
male 577 109
'''
以上代码用到的方法:
pandas.DataFrame 对象的筛选,返回仍是 pandas.DataFrame 对象
格式:数据框名[数据框.列名 条件]
pandas.DataFrame 对象的 rename( columns =, ) 方法:列重命名
具体参数:
columns 字典 重命名字典
pandas.DataFrame 对象的 concat(data, axis = ) 方法:连接 pandas.DataFrame 对象,返回的仍是 pandas.DataFrame 对象
具体参数:
data 列表 将要连接的对象放在该列表中
axis 整数 0表示按行连接,1表示按列连接
④高维散点图:反映多个特征两两之间的相互依赖关系
以下为代码举例:
import matplotlib.pyplot as plt
import pandas as pd
my_data = pd.read_csv("iris.csv", header = None, names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'target'])
# 以下步骤用于给不同的鸢尾花类别标记不同的散点颜色
my_set = set(my_data['target']) # 创建集合,内只含有鸢尾花的三个类别
my_set_list = list(my_set) # 将集合转化为列表
colors = list() # 创建空列表用以保存颜色
palette = {my_set_list[0]: 'red', my_set_list[1]: 'green', my_set_list[2]: 'blue'} # 设置填充颜色的字典,每一种类鸢尾花使用不同颜色标记
for n, row in enumerate(my_data['target']): # 循环遍历pandas.series对象的每一个元素
colors.append(palette[my_data['target'][n]]) # 利用字典的键进行索引
# 以上循环全部结束后,colors是一个长度等同于my_data['target']的列表,且其值代表每一项元素对应的颜色
scatterplot = pd.plotting.scatter_matrix(my_data, alpha = 0.3, figsize = (10, 10), diagonal = 'hist', color = colors, marker = 'o', grid = True)
plt.show()
以上代码用到的方法:
enumerate( ) 方法:用于将一个可遍历的对象组合为一个索引序列
pandas.DataFrame 对象的 plotting.scatter_matrix( ) 方法:绘制散点矩阵图
具体参数:
第一个参数:需要作图的数据集
alpha 浮点数取(0,1] 图像透明度
figsize 元组 图像区域大小
marker 字符串 点的形状:'o’代表圆点
diagonal 字符串 选择对角线的图片的替换图(同一个特征拿来比较无意义) 一般选’hist’作直方图
grid 布尔型 是否显示网格:True代表显示
至此完成探索性数据分析EDA,接下来将进入建模阶段
小结
笔记的第二部分包含了数据科学项目处理流程中探索性数据分析EDA的相关理论内容与代码实例。本节内容理论结合实践,内容较为丰富,同样学习该门学科的读者不光需要结合教材熟练掌握理论知识,更应该亲自上手联系代码书写。最为重要的统计建模和机器学习部分将在下一部分的笔记中分享。