作者: ShawnYan 原文来源: https://tidb.net/blog/5e697bac
背景
Spark 是一款专为大规模数据处理而设计的计算引擎,而 TiSpark 是基于 Spark 非侵入式的强化插件,可以很好的兼容 TiDB,并对 TiDB 中的数据进行处理分析。TiSpark 集成了 mysql-connector-java,可以从 TiKV 和 TiFlash 读取数据。并且,TiSpark 实现了 TiKV 的 Java 客户端,可以写入数据到 TiKV,而不用经过 TiDB Server。
本文将介绍如何安装配置 TiSpark v2.5,并演示如何用 Spark 客户端对 TiDB 中的数据进行读、写、删操作,以及调用窗口函数。
TiSpark v3.0.0 已于 6月15日正式发布,本文也将解读部分新功能。
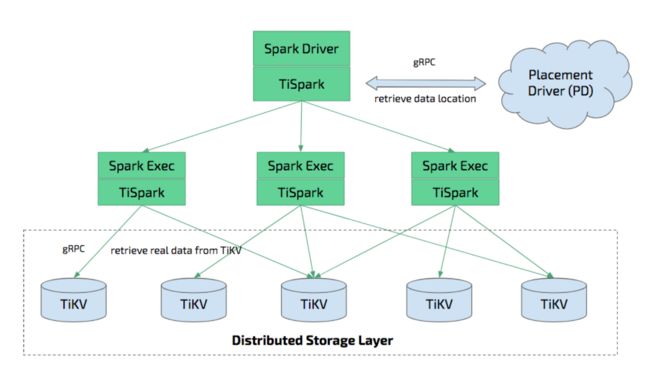
TiSpark 安装
版本信息
TiSpark 需要配合 Spark 使用,而 Spark 是基于 Scala 开发的,Scala 依赖 JDK,故需要安装如下组件。
本文所涉及的各个组件及版本信息如下:
TiDB 6.0.0
OpenJDK 1.8.0
Scala 2.13.8
Spark 3.0.3
TiSpark 2.5.0
组件安装
TiDB
本文使用的是 TiDB 6.0,安装步骤略,查看数据库版本如下。
TiDB-v6 [test] 00:37:25> select tidb_version()\G
*************************** 1. row ***************************
tidb_version(): Release Version: v6.0.0
Edition: Community
Git Commit Hash: 36a9810441ca0e496cbd22064af274b3be771081
Git Branch: heads/refs/tags/v6.0.0
UTC Build Time: 2022-03-31 10:33:28
GoVersion: go1.18
Race Enabled: false
TiKV Min Version: v3.0.0-60965b006877ca7234adaced7890d7b029ed1306
Check Table Before Drop: false
1 row in set (0.001 sec)
JDK
安装过程省略,直接查看 JDK 版本信息。
shawnyan@centos7:~$ java -version
openjdk version "1.8.0_302"
OpenJDK Runtime Environment (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (build 25.302-b08, mixed mode)
Scala
直接从 Scala 官网下载 2.12 版本的 RPM 包,并进行安装。
wget https://downloads.lightbend.com/scala/2.12.15/scala-2.12.15.rpm
sudo yum install ./scala-2.12.15.rpm
安装完成后,查看 Scala 版本。
scala -version
Scala code runner version 2.12.15 -- Copyright 2002-2021, LAMP/EPFL and Lightbend, Inc.
Spark
从官网下载 Spark 3.0,解压后导入环境变量后,即可使用。
wget https://archive.apache.org/dist/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz
tar zxvf spark-3.0.3-bin-hadoop2.7.tgz
vi ~/.bashrc
export PATH=$PATH:~/spark-3.0.3-bin-hadoop2.7/bin
source ~/.bashrc
TiSpark
通过对接 Spark 的 Extension 接口,TiSpark 得以在不直接修改 Spark 源代码的前提下,深度订制 Spark SQL 的根本行为,包括加入算子,扩充语法,修改执行计划等等,让它看起来更像是一款 Spark 原生产品而非第三方扩展。
TiSpark 的主要部件是 tispark-assembly-x.x.x.jar 这个 jar 包,获取方式有两种,一是直接使用 tiup install tispark ,二是直接下载 jar 包。由于 TiSpark 2.5 尚未推送到 tiup mirror,故本文采用第二种方式。
通过 tiup list 可查看 tiup mirror 远端的 spark/tispark 版本。
shawnyan@centos7:~$ tiup list spark
Available versions for spark:
Version Installed Release Platforms
------- --------- ------- ---------
v2.4.3 2020-07-08T16:59:15+08:00 any/any
shawnyan@centos7:~$ tiup list tispark
Available versions for tispark:
Version Installed Release Platforms
------- --------- ------- ---------
v2.3.1 2020-07-09T15:59:03+08:00 any/any
...
v2.4.0 2021-04-16T15:07:02+08:00 any/any
v2.4.1 YES 2021-05-17T15:17:01+08:00 any/any
下载 tispark-assembly-2.5.0.jar 后,将其移动到 spark 的 jars 路径下,如此启动 spark 客户端时就无需显式引用。
wget https://github.com/pingcap/tispark/releases/download/v2.5.0/tispark-assembly-2.5.0.jar
mv tispark-assembly-2.5.0.jar spark-3.0.3-bin-hadoop2.7/jars/
- 未放到 jars 路径下,需要显式引用
spark-shell --jars tispark-assembly-2.5.0.jar
- 已放到 jars 路径下,则可直接运行
spark-shell
启动 spark-shell 后,可以从 SparkContext WebUI 看到已经导入 TiSpark 的 jar 包。

TiSpark v3.0.0 启用 Jar 包新命名规则
TiSpark 的 Jar 包有了新的命名规则: tispark-assembly-{spark_version}_{scala_version}-{$tispark_verison} #2370
这是一项兼容性修改,新命名规则为: tispark-assembly-{$spark_version}_{$scala_version}-{$tispark_verison} 。Jar 包命名更加规范、清晰,用户可按需下载对应的 Jar 包。本次发版提供了三个 Jar 包,分别名为:
- tispark-assembly-3.0_2.12-3.0.0.jar
- tispark-assembly-3.1_2.12-3.0.0.jar
- tispark-assembly-3.2_2.12-3.0.0.jar
TiSpark v3.0.0 支持 Scala 2.12,以及 Spark 3.0/3.1/3.2。本文使用 Spark 3.0,故这里需下载对应的 Jar 包,然后将其移动到 spark 的 jars 路径下。
wget https://github.com/pingcap/tispark/releases/download/v3.0.0/tispark-assembly-3.0_2.12-3.0.0.jar
mv tispark-assembly-3.0_2.12-3.0.0.jar spark-3.0.3-bin-hadoop2.7/jars/
TiSpark 版本说明
下表为 TiSpark、Spark、Scala 的版本对应表,并标注了是否需要 pytispark。本文中的示例使用 TiSpark 2.5.0 和 TiSpark 3.0.0,故直接使用 pyspark 即可,推荐各位读者使用最新版本。
| TiSpark 版本 | Spark 版本 | Scala 版本 | 是否需要 pytispark | 备注 |
|---|---|---|---|---|
| < 2.3 | 2.11 | ✅ | 支持 TiDB 4.0, 不再维护 | |
| 2.4.x | 2.3, 2.4 | 2.11, 2.12 | pyspark ❎ spark-sumbit ✅ | 支持 TiDB 4.0, TiDB 5.0 |
| 2.5.x | 3.0, 3.1 | 2.12 | ❎ | 支持 TiDB 4.0, TiDB 5.0 |
| 3.0.0 | 3.0, 3.1, 3.2 | 2.12 | ❎ | 支持 TiDB 4.0, TiDB 5.0 |
注:
- 从 TiSpark 2.4.0 开始支持 TiDB 5.0。
- 对于 TiDB 6.0,TiSpark 尚未完全支持,本文只是使用 TiDB 6.0 作为案例演示,而非生产环境中的实例。
TiSpark 还未进行全面的 TiDB 6 兼容性测试,其中一个已知问题就是未支持 new_collations,着急用可以先关闭此选项,大部分功能应该可以正常使用。new_collations 的支持在排期中,在支持后我们相应也会进行 TiDB 6 的兼容性测试,最后宣布支持 tidb 6。时间大概在7-8 月
- 关于 pytispark 的 官方阐释 如下:
- 在不支持 extension 的 Spark 2.3 之前,TiSpark 通过替换 Spark 类的方式来改变 Spark 执行计划。这带来了一个问题:当我们结合 TiSpark 和 Spark 周边工具使用时,还需要进行额外的适配工作。其中 pytispark 就是为 TiSpark 和 pyspark 结合使用而生。
- Spark 2.3 之后推出了 extension ,TiSpark 抛弃了上述 hack 的方式转而使用 extension。理论上我们无需适配即可使用所有原生的 Spark 工具。但实际上,我们仍可能需 pytispark 来解决 SPARK-25003 带来的问题。需要明确的是,虽然同样是用了 pytispark ,但使用的目的是不一样的。
- Spark 3.0 之后, SPARK-25003 已被解决,我们可以放心大胆的直接使用 pyspark 了。但由于 This session stuff logic is a bit convoluted and many session changes were made. I wouldn’t backport it from 3.0 to 2.x unless it’s quite serious one. 该 fix 并没有 back port 到 2.3 以及 2.4 版本。如果你想使用 pyspark 与 tispark, 建议使用 spark 3.0 及以上版本。
TiSpark 开发实践
TiSpark v2.5 相关配置
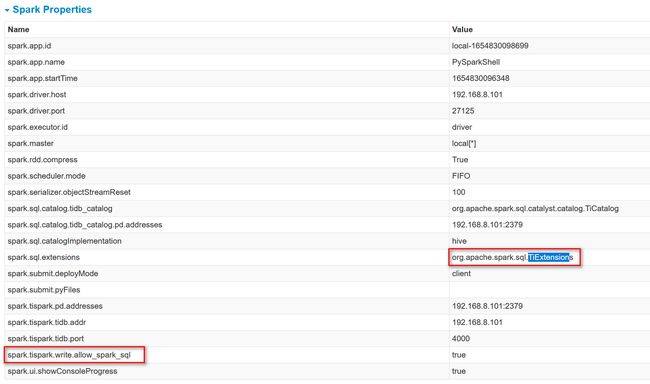
TiSpark 依赖于 PD 组件,所以在 Spark 的配置文件中,需要配置 PD 地址。本例中,将配置信息写入到 spark/conf 路径下的 spark-defaults.conf 文件。
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses 192.168.8.101:2379
spark.tispark.tidb.addr 192.168.8.101
spark.tispark.tidb.port 4000
# enable write through SparkSQL
spark.tispark.write.allow_spark_sql true
# enable `Catalog` provided by `spark-3.0`.
spark.sql.catalog.tidb_catalog org.apache.spark.sql.catalyst.catalog.TiCatalog
spark.sql.catalog.tidb_catalog.pd.addresses 192.168.8.101:2379
注:
- 实际使用时,建议将三个 pd 的地址都填写到
pd.addresses配置项,本文为便于演示,只写了其中一个地址。 - 这里要确保开启
spark.tispark.write.allow_spark_sql,才能将数据写入 TiKV。
启动 spark-shell 后,可通过 WebUI 看到生效的 Spark 配置项。
TiSpark v3.0.0 相关配置
不再支持不使用 catalog 的方式。现在你必须配置 catalog 并使用 tidb_catalog #2252
解读:从 TiSpark v3.0.0 开始,配置项中必须启动下面两项,上文的案例中已启用这一配置,继续按上文示例使用即可。
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses ${your_pd_adress}
环境准备好之后,接下来将演示如何进行数据读取和写入。
使用 PySpark 进行数据读取
首先演示如何使用 PySpark 读取 TiDB 中的数据。PySpark 是 Python 编写的 Spark 接口,可以调用 Python API 对 Spark 程序进行读写操作,并且可以进行数据分析。
安装 PySpark
这里主要介绍两种 pyspark 的安装方式:
- Spark 自带,所以无需另行安装。
shawnyan@centos7:~$ which pyspark
~/spark-3.0.3-bin-hadoop2.7/bin/pyspark
shawnyan@centos7:~$ pyspark --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.3
/_/
Using Scala version 2.12.10, OpenJDK 64-Bit Server VM, 1.8.0_332
Branch HEAD
Compiled by user ubuntu on 2021-06-17T04:52:32Z
Revision 65ac1e75dc468f53fc778cd2ce1ba3f21067aab8
Url https://github.com/apache/spark
Type --help for more information.
- 使用 pip 进行安装。
shawnyan@centos7:~$ pip3 install pyspark --user
Collecting pyspark
Using cached https://files.pythonhosted.org/packages/f4/65/41eb22b7b4623d9f4560526cc456cb6425770c098a9dff6763111c4455cc/pyspark-3.2.1.tar.gz
Collecting py4j==0.10.9.3 (from pyspark)
Using cached https://files.pythonhosted.org/packages/5e/e6/68db58a1d94d41ae042400f7965ed6a2c30e4108f77b54672d6451f86ebd/py4j-0.10.9.3-py2.py3-none-any.whl
Installing collected packages: py4j, pyspark
Running setup.py install for pyspark ... done
Successfully installed py4j-0.10.9.3 pyspark-3.2.1
由此也可看出,PySpark 是借助 Py4j 实现 Python 调用 Java 来驱动 Spark 应用程序,其本质主要还是 JVM runtime,Java 到 Python 的结果返回是通过本地 Socket 完成。
启动 PySpark
启动 PySpark 时,可通过 spark.driver.host 配置项指定 IP,启动后,可通过该 IP 访问 WebUI 页面,在页面上可以直观的看到 Spark 配置项及计算结果。
pyspark --conf spark.driver.host='192.168.8.101'
查看 PySpark 版本信息
在交互式客户端查看 PySpark 的版本信息:
>>> print("pyspark "+str(sc.version))
pyspark 3.0.3
>>> import pyspark
>>> print("pyspark",pyspark.__version__)
('pyspark', '3.0.3')
使用 PySpark 通过 JDBC 读取数据
本例将演示如何通过 JDBC 读取 TiDB 中的数据。
- 在 TiDB 中创建基础数据,创建表 t1, t2。
- 基础数据如下:
create table t1 (id int, col char(1));
insert t1 select 1,'a';
create table t2(id int, col char(2));
insert t2 select 2,'b';
- 创建一个 Spark 连接
from pyspark.sql import SparkSession
spark = SparkSession \
.Builder() \
.appName('sql') \
.master('local') \
.getOrCreate()
- 设置 JDBC 连接信息,
dbtable是指预读取的表名。
url = "jdbc:mysql://192.168.8.101:4000/test?user=root&password=&useSSL=false&rewriteBatchedStatements=true"
df=spark.read.format("jdbc").options(url=url,
driver="com.mysql.jdbc.Driver",
dbtable="t1"
).load()
- 按条件
id=1过滤,并显示结果。
>>> df.filter(df.id == 1).show()
+---+---+
| id|col|
+---+---+
| 1| a|
+---+---+
- 按 id 列进行分组统计,并显示结果。
>>> countById = df.groupBy("id").count()
>>> countById.show()
+---+-----+
| id|count|
+---+-----+
| 1| 1|
+---+-----+
使用 spark-shell 进行数据写入
接下来,演示如何使用 spark-shell 写入数据到 TiDB。
启动 spark-shell
spark-shell --conf spark.driver.host='192.168.8.101'
查看 spark-shell 信息
查看 spark 和 tispark 版本信息。
scala> org.apache.spark.SPARK_VERSION
res0: String = 3.0.3
scala> spark.sql("select ti_version()").collect
res0: Array[org.apache.spark.sql.Row] =
Array([Release Version: 2.5.0
Git Commit Hash: e48b484f7f8e5a3b70cdd8294fecfdb92fcdd411
Git Branch: release-2.5
UTC Build Time: 2022-01-27 09:13:04
Supported Spark Version: 3.0 3.1
Current Spark Version: 3.0.3
Current Spark Major Version: 3.0
TimeZone: Asia/Shanghai])
从以上信息可知,当前 TiSpark 的代码取自分支 release-2.5 ,由此可快速定位到对应版本的源码: https://github.com/pingcap/tispark/commit/e48b484f7f8e5a3b70cdd8294fecfdb92fcdd411
使用 spark-shell 写入数据
- 定义 SparkConf,配置 pd/tidb 地址和端口。
import org.apache.spark.SparkConf
val sparkConf = new SparkConf().
setIfMissing("spark.master", "local[*]").
setIfMissing("spark.app.name", getClass.getName).
setIfMissing("spark.sql.extensions", "org.apache.spark.sql.TiExtensions").
setIfMissing("spark.tispark.pd.addresses", "192.168.8.101:2379").
setIfMissing("spark.tispark.tidb.addr", "tidb").
setIfMissing("spark.tispark.tidb.port", "4000")
- 配置好必要的依赖以后,初始化一个 SparkSession 对象。
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.config(sparkConf).getOrCreate()
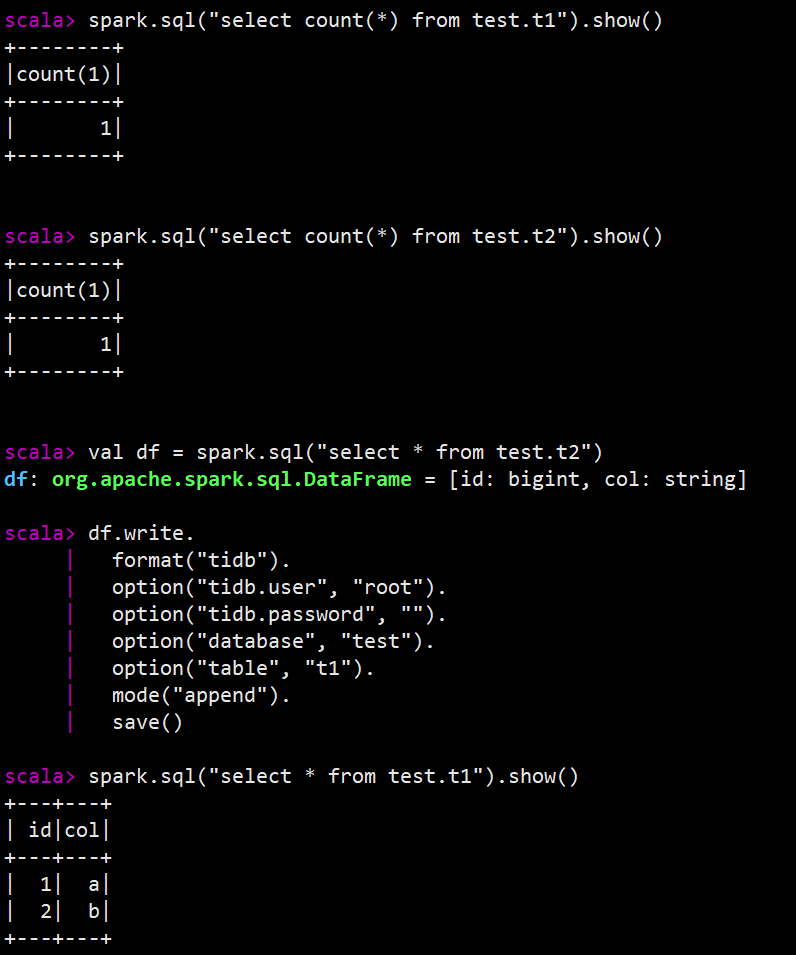
- 查看当前 t1 表中的数据量。
spark.sql("use tidb_catalog")
spark.sql("select count(*) from test.t1").show()
- 查询 t2 表中的数据,并将数据追加到 t1 表。
val df = spark.sql("select * from test.t2")
df.write.
format("tidb").
option("tidb.user", "root").
option("tidb.password", "").
option("database", "test").
option("table", "t1").
mode("append").
save()
append 意为将此数据插入到具有与 DataFrame 相同的模式的现有表中。
- 再次查看 t1 表数据,确认数据已成功写入。
spark.sql("select * from test.t1").show()
数据写入的关键日志如下图:
- 也可从 TiDB 查询 t1 表数据,确认数据已写入。
TiDB-v6 [test] 17:27:21> select * from t1;
+------+------+
| id | col |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
2 rows in set (0.002 sec)
使用 spark-shell 进行数据删除
这是 TiSpark v3.0.0 的新特性。接下来,演示如何使用 spark-shell 删除数据。
启动 spark-shell 后,查看 TiSpark 版本信息。
scala> spark.sql("select ti_version()").collect
res1: Array[org.apache.spark.sql.Row] =
Array([Release Version: 3.0.0
Git Commit Hash: 4e48f9e5e87ee24fbdceb6aa5a9a3c5a7661e22e
Git Branch: 3.0_release
UTC Build Time: 2022-06-15 06:22:06
Supported Spark Version: 3.0 3.1 3.2
Current Spark Version: 3.0.3
Current Spark Major Version: 3.0
TimeZone: Asia/Shanghai])
前3个步骤与上一小节的写入步骤一样,从第4步开始,调用删除方法。
scala> spark.sql("select count(*) from test.t1").show()
+--------+
|count(1)|
+--------+
| 1|
+--------+
scala> spark.sql("delete from test.t1 where id=1")
res5: org.apache.spark.sql.DataFrame = []
scala> spark.sql("select count(*) from test.t1").show()
+--------+
|count(1)|
+--------+
| 0|
+--------+
对于新支持的 delete 操作,有如下 限制 ,使用时需注意。
-
Delete语句必须含有where条件,但不能接where 1=1。
scala> spark.sql("delete from test.t1 where 1=1")
java.lang.IllegalArgumentException: requirement failed: Delete with alwaysTrue WHERE clause is not supported
- 不支持子查询。
scala> spark.sql("delete from test.t2 where id in (select id from test.t1)")
org.apache.spark.sql.AnalysisException: Delete by condition with subquery is not supported: Some(id#275L IN (list#274 []));
- 不支持分区表,不支持悲观事务。
使用 PySpark 演示窗口函数
本例已 rank() 函数为例,其他窗口函数类似。
- 准备测试数据。
DROP TABLE if EXISTS student;
CREATE TABLE if NOT EXISTS student (course VARCHAR(10), mark INT, name VARCHAR(10));
INSERT INTO student VALUES
('Maths', 60, 'Thulile'),
('Maths', 60, 'Pritha'),
('Maths', 70, 'Voitto'),
('Maths', 55, 'Chun'),
('Biology', 60, 'Bilal'),
('Biology', 70, 'Roger');
- 与 《使用 PySpark 进行数据读取》小节的前3步一致。
- 引用 pyspark 中的
Window/functions方法,并进行查询。
from pyspark.sql import Window, functions
w = Window.partitionBy("course").orderBy(functions.desc("mark"))
df.select("course", "mark", "name", functions.rank().over(w).alias("rank")).show()
- 查询结果输出如下。
+-------+----+-------+----+
| course|mark| name|rank|
+-------+----+-------+----+
| Maths| 70| Voitto| 1|
| Maths| 60|Thulile| 2|
| Maths| 60| Pritha| 2|
| Maths| 55| Chun| 4|
|Biology| 70| Roger| 1|
|Biology| 60| Bilal| 2|
+-------+----+-------+----+
实际上,在这个案例中,是通过 pyspark 连接到 TiDB Server,将表 student 的全部数据读取出来,再在 Spark 中进行运算,最终得到所示结果集。
到此,四个案例已全部演示完毕。
TiSpark v3.0.0 其他新功能
TiSpark v3.0.0 支持 Spark 3.2
新特性 – 支持 Spark 3.2 #2287
解读:Spark 3.2.1 于 1月26日发版,是近期发布的最新稳定版本。
TiSpark v3.0.0 支持遥测
新特性 – 支持遥测以收集相关信息 #2316
解读:
- 遥测功能默认开启,可通过参数
spark.tispark.telemetry.enable进行控制。 - 遥测功能会收集操作系统信息和部分 TiSpark 配置信息,并将信息分享给 PingCAP。具体收集方法,可参考源码。
core/src/main/scala/com/pingcap/tispark/utils/SystemInfoUtil.scala
core/src/main/scala/com/pingcap/tispark/telemetry/TelemetryRule.scala
- 如果想看完整的遥测收集内容,可将 TiSpark 日志级别调至
INFO及以下,然后在 Spark 的日志文件中查看。
# tispark v3.0.0, print telemetry content
log4j.logger.com.pingcap.tispark=WARN
总结
- TiSpark 已支持从 TiKV 和 TiFlash 读取数据,并通过自定义插件的形式增强了数据处理能力和计算下推能力。并且支持绕过 TiDB Server 直接写入数据到 TiKV,大大提升了数据批量写入的效率。
- TiSpark 对 TiDB 6.0 的支持尚未得到完全测试 ( #2238 ),建议使用 TiSpark 3.0.0 + TiDB 5.4 的版本搭配。
- 最新版本的 TiSpark 未推送到 tiup mirror,需从源码库下载,或直接通过 Maven 库引用。
- 由于 PySpark 底层调用的是 py4j,实际仍会转化为 Java,所以对于大量的流式计算,建议直接使用 Scala 或者 Java 编写程序。
- TiSpark v3.0.0 支持删除语句,TiSpark 读写能力得到进一步强化。
- TiSpark 是 TiDB 周边生态中的一个重点项目,但毕竟使用场景有一定的局限性,所以在期待 TiSpark 功能增强的同时,应多予以一些耐心和信心。
参考链接
- TiSpark 源码
- TiSpark 用户指南
- Spark 官网
- TiDB 6.1 MPP 实现窗口函数框架