spark安装
1. spark安装与使用(在Hadoop已经安装的基础上)
参考厦门大学大数据实验室的博客安装
1.1. 安装环境
Ubuntu 20.04
Hadoop 3.1.3
Java JDK 1.8
Spark 3.0.0 preview2
1.2. 安装Hadoop(伪分布式)
在我之前的博客中有
1.3. 安装Spark
1.3.1. 下载Spark压缩包
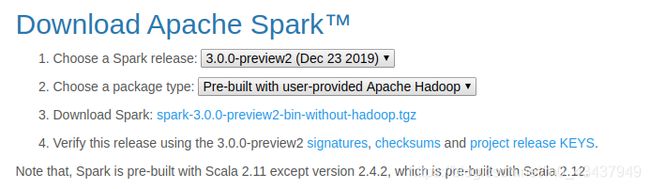
1.3.2. 解压压缩包并为Spark配置文件
解压压缩包
sudo tar -zxf ~/下载/spark-3.0.0-preview2-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-3.0.0-preview2-bin-without-hadoop/ ./spark
为Spark配置文件
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
gedit ./conf/spark-env.sh
在打开的文件末尾添加
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
关于spark-env.sh的配置选项
spark-env.sh配置
1.3.3. 运行Spark自带的例子
cd /usr/local/spark
bin/run-example SparkPi
运行结果会与日志信息混在一起,可以将日志信息(标准错误输出)重定向丢弃或者将结果(标准输出)重定向到文件再查看
# 日志信息(标准错误输出)重定向丢弃
bin/run-example SparkPi 2>/tmp/null
# 输出重定向到文件再查看
bin/run-example SparkPi > /tmp/sparkExample_res
cat /tmp/sparkExample_res
1.4. 使用Spark Shell
Spark shell是交互式解释器
1.4.1. 打开Spark Shell
在spark目录下
使用./bin/spark-shell打开scala版的解释器
使用./bin/pyspark打开python版的解释器
本片使用的是scala版的解释器,关于python可见spark官方指南
1.4.2. 加载text文件
val textFile = sc.textFile("file:///usr/local/spark/README.md")
![]()
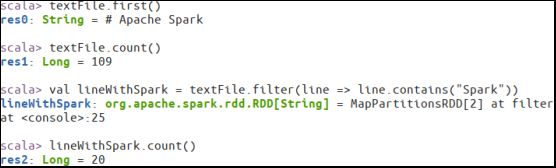
1.4.3. 简单的RDD操作
//获取RDD文件textFile的第一行内容
textFile.first()
//获取RDD文件textFile所有项的计数
textFile.count()
//抽取含有“Spark”的行,返回一个新的RDD
val lineWithSpark = textFile.filter(line => line.contains("Spark"))
//统计新的RDD的行数
lineWithSpark.count()
1.4.4. 实现简单的MapReduce
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
![]()
1.4.5. 退出Spark Shell
:quit
![]()
1.4.6. Scala应用程序编程
用Scala在idea上编写一个简单的程序,没有进行打包
1.4.6.1. 建立sbt项目
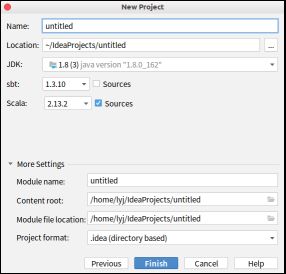
将Scala版本改为2.12.10
第一次建立sbt项目时间可能会有点长,建议再开一个窗口进行java应用程序编程(见下)
1.4.6.2. 编写.sbt文件
值得注意的是Spark对于Scala版本有一定要求
spark依赖查看地址https://mvnrepository.com/

如上图,此时Spark构建于2.12版本的Scala,我一开始用2.13版本报错

选择版本找到依赖以后写入.sbt文件
name := "sbtTestForSpark"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2"
1.4.6.3. 编写.scala文件并运行
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
1.4.7. 7.java应用程序编程
1.4.7.1. 创建Maven项目
1.4.7.2. 编写pom.xml文件
查找依赖还是使用https://mvnrepository.com/
<project>
<groupId>com.lyjgroupId>
<artifactId>simple-projectartifactId>
<modelVersion>4.0.0modelVersion>
<name>Simple Projectname>
<packaging>jarpackaging>
<version>1.0version>
<repositories>
<repository>
<id>jbossid>
<name>JBoss Repositoryname>
<url>http://repository.jboss.com/maven2/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>3.0.0-preview2version>
dependency>
dependencies>
project>
1.4.7.3. 编写java程序并运行
/*** SimpleApp.java ***/
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///usr/local/spark/README.md"; // Should be some file on your system
SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
1.4.7.4. 打包为jar文件
点击package就可以生成jar包
1.4.7.5. 使用spark-submit运行simpleApp
/usr/local/spark/bin/spark-submit --class "SimpleApp" ./target/simp
le-project-1.0.jar 2>&1 | grep Line