python 相关系数_寻找历史上的今天——皮尔逊相关系数实现相似K线匹配及其性能优化...

概念介绍
寻找相似K线是投资者用来研究“历史是否总会重演”的常用方法,目前许多交易工具都已经提供搜索相似K线功能。如下图是一些产品的相似K线效果图:
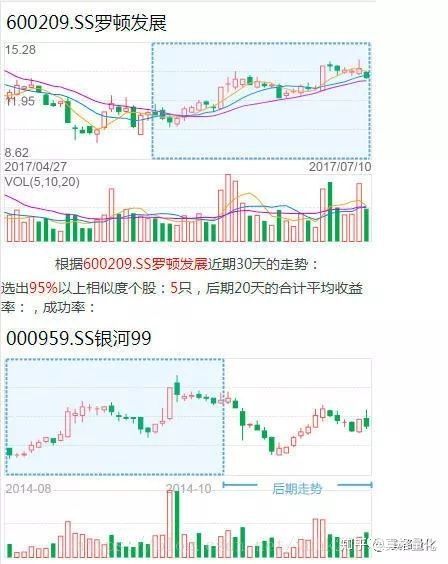

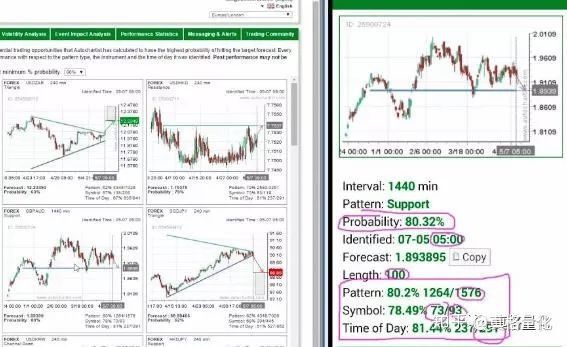
本文就将简要介绍如何实现相似K线的计算,并讨论实现过程中的一些难点细节。
计算及实现
相似K线的实现主要分为两大部分,第一部分是相似度匹配计算;第二部分是排名筛选。
相似度匹配
进行相似度匹配时我们使用“皮尔逊相关系数”(Pearson product-moment correlation coefficient)来进行相关度验证。详细的“皮尔逊相关系数”的推导及演算可从网上找到相关资料。本文我们直接使用结论公式:

公式主要通过平均数和协方差的概念来计算相似度,实现较为容易。对于K线数据,输入X,Y就是一组连续的价格数据,通过计算皮尔逊公式,我们会得到一个-1~1的相关系数,结果越接近1的数据,相似度越高。以下代码是对上述公式的完整实现,编程使用JavaScript(读者可以根据需要自行将其改写为Python或C++):

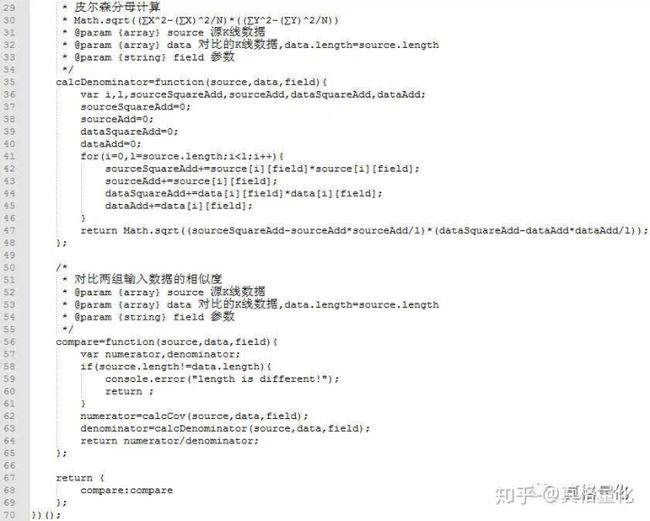
我们可以试着用以下数据来计算相关系数:

输出的结果为-1,目标数据呈完全负相关。
由此,我们就得到了对比相似度的方法。下一步我们将要从全市场历史数据中找出相关度最高的相似K线数据。
遍历计算
最简单的实现方法就是全市场计算,蛮力遍历,将得到的所有结果进行排序,最终得到相似K线:

这种算法实现简单,并且得到的结果一定是相似度最高的数据。但是这种算法需要将所有数据完整遍历计算,并且过程中需要保存下每个数据的计算结果,最终排序后得到最相似的数据,从时间和空间角度来看性能较差。
遍历计算优化
于是我们想到可以对排序进行优化:因为不会出现漏算的情况,我们在计算过程中只保存当前最高相似度数据的值,这样就节省了排序数组的空间和最后排序的时间:

可以看到,运行时间几乎得到了15%的性能提升。并且新的算法在空间上也更优。
虽然经过了优化,但是我们仍然无法避免大规模的数据运算,这种缺陷在进行全市场数据运算时将会暴露的更加凸显。介于此,我们提出一种可行的优化算法:引入分治思想。对于本文中的特定案例,我们计算600570最新30天的数据,也就是说每次循环,皮尔逊公式将计算两组长度为30的数组数据的相似度。为了降低计算量,我们从数组中选取几个特征数据,例如选取数组头、数组中、数组尾三个数据来计算相关度,替代每次都完整计算整个数据的相似度,在粗略计算后选取相似度排名前几位,然后对这前几位数据索引再进行完整计算:


对于这种算法,有一个性能公式可以参考(以下变量名和程序中相同):
cut∗compareCount+totalLength∗divide=totalLength∗compareCount
公式中,cut表示粗略计算后截取前多少名进行精确计算(本例中取值为100),compareCount表示整个对比数据的长度(本例中就是30),totalLength表示历史数据的长度(本例中600571历史数据长度为1404),divide表示特征数据个数(本例中用3个特征数代替30的完整数据)。对于这个公式,divide和cut是由开发人员主观定义的。divide越大,粗略计算的成本也就越高,当cut=compareCount时,这个算法也就退化成第一种蛮力遍历算法;cut越大,最后的精确计算成本也越高,但是注意cut不能太小,因为粗略计算过程中实际上是个贪婪计算过程,可能会遗失全局最优解而得到局部最优解。另一点要说明的是,该算法计算过程中也必须保存一个数据长度的相似度数组来进行最后的排序,因此空间消耗和第一种蛮力遍历算法一样大(可以通过维护一个长度为cut的降序数组保存相似度前几位的数据,来进行小幅度的优化,大约提升15%的性能)。
相似K线对于投资的作用
其实对于大部分历史数据段,在任何一支上市5年以上的标的历史数据上都可以找到相似度大于0.9的数据段。我们在许多产品上看到的排名前几位的相似K线也仅仅只是沧海一粟,对应的后期走势也不可能代表所有数据情况,所以投资者使用相似K线进行行情研判时也应当保持谨慎。因为对于一段数据,我们可能查找出的一个相似历史K线其后的价格为上升,而另一个相似K线其后的价格为下降,那投资者如何判断呢?并且这种分化走势是一定存在的。就算我们在某个标的上看到的相似K线显示未来100%上涨,那可能只是这个标的没有把数据算全,或者我们还没有遇到另一种可能性。相似K线只能提供形态上的模拟近似,并不能完整的将当前标的和历史数据的宏观环境(供需基本面、经济状况)完全匹配。投资者在使用相似K线做投资决策时仍需要注意“历史表现并不代表未来表现”的风险。

— — — — — — E N D — — — — — —
往期文章:
Numpy处理tick级别数据技巧
真正赚钱的期权策略曲线是这样的
多品种历史波动率计算
如何实现全市场自动盯盘
AI是怎样看懂研报的
真格量化策略debug秘籍
真格量化对接实盘交易
常见高频交易策略简介
如何用撤单函数改进套利成交
Deque提高处理队列效率
策略编程选Python还是C++
如何用Python继承机制节约代码量
十大机器学习算法
如何调用策略附件数据
如何使用智能单
如何扫描全市场跨月价差
如何筛选策略最适合的品种
活用订单类型规避频繁撤单风险
真格量化回测撮合机制简介
如何调用外部数据
如何处理回测与实盘差别
如何利用趋势必然终结获利
常见量化策略介绍
期权交易“七宗罪”
波动率交易介绍
推高波动率的因素
波动率的预测之道
趋势交易面临挑战
如何构建知识图谱
机器学习就是现代统计学
AI技术在金融行业的应用
如何避免模型过拟合
低延迟交易介绍
架构设计中的编程范式
交易所视角下的套利指令撮合
距离概念与特征识别
气象风险与天气衍生品
设计量化策略的七个“大坑”
云计算在金融行业的应用
机器学习模型评估方法
真格量化制作期权HV-IV价差
另类数据介绍
TensorFlow中的Tensor是什么?
机器学习的经验之谈
用yfinance调用雅虎财经数据
容器技术如何改进交易系统
Python调用C++
如何选择数据库代理
统计套利揭秘
一个Call搅动市场?让我们温习一下波动率策略
如何用真格量化设计持仓排名跟踪策略
还不理解真格量化API设计?我们不妨参考一下CTP平台
理解同步、异步、阻塞与非阻塞
隐波相关系数和偏度——高维风险的守望者
Delta中性还不够?——看看如何设计Gamma中性期权策略
Python的多线程和多进程——从一个爬虫任务谈起
线程与进程的区别
真格量化可访问:
https://quant.pobo.net.cn

真格量化微信公众号,长按关注:

遇到了技术问题?欢迎加入真格量化Python技术交流QQ群 726895887
