联邦学习相关论文阅读
A Taxonomy of Attacks on Federated Learning
联邦学习是一个隐私设计的框架,它可以从分散的数据源中训练深度神经网络,但它充满了无数的攻击面。我们提供了最近对联邦学习系统的攻击的分类,并详细说明了在联邦学习环境中对更健壮的威胁建模的需求。
我们的工作的不同之处在于,我们寻求解决与联邦学习相关的高度特定的安全和隐私问题,并提出了几种解决方案来应对这些威胁。展望未来,解决这些关于联邦学习系统的安全、隐私和有效性的开放性问题将会产生重大的社会影响。本文的目的是全面概述对联邦学习系统的攻击,包括模型性能和数据隐私。我们提出了一个联邦学习的概述(参见“鲁棒联邦学习威胁模型所需的参数术语表”),并建立了一个鲁棒威胁建模的框架。然后,我们调查了模型的性能和数据隐私攻击的类型,并评估了一些现有的防御方法。最后,我们提出了一个对抗性联邦学习的分类,并强调了在协作机器学习的这个重要和新兴领域的开放挑战和机遇。
联邦学习系统在训练时暴露了几个新的攻击向量,从而围绕以下核心问题产生了复杂的、开放的挑战:
- 如何保证经过协作训练的DL模型的鲁棒性?
- 如何保护客户端数据贡献的隐私?
- 如何保护DL模型所体现的知识产权?
- 从中央服务器的角度来看,如何信任网络中参与者的报告结果?
- 从单个参与者的角度来看,人们如何信任中央服务器?
- 如何确保分布式神经网络架构对后门攻击具有鲁棒性?
新的攻击表面在传统的机器学习项目中,开发过程(学习阶段)受到保护,并集中在单个组织中。因此,安全机器学习的文献主要集中在在对生产中已开发的模型进行推理时抵御对抗性的客户。联邦学习是一种新型的分布式学习系统,在学习阶段很容易受到许多对数据隐私和模型安全的潜在攻击。联邦学习系统上最大的威胁面是通过提供数据而参与学习阶段的客户端网络。这种客户端攻击可能比推理阶段效应更强大,因为对抗的联合学习客户端在开发过程中能够简单地利用模型服务的边界。我们在表1中提供了对联邦学习系统的现有攻击的列表。

安全聚合
迄今为止,联邦学习社区的一个中心焦点一直是设计安全聚合的方法,旨在解决不可信的中央服务器的威胁。安全聚合协议的目的是防止中央服务器在执行联邦平均算法时获得对客户机的本地模型的可见性和控制。安全聚合的主干是安全的多方计算,这是密码学的一个分支,使不受信任的各方能够协同评估隐藏输入上的函数。这是一个非常活跃的研究领域,并且已经提出了许多关于联邦学习的技术。一个相关的方法利用可信的执行环境,这是基于硬件的解决方案,作为“反向黑盒”;也就是说,没有人能观察到一个安全的飞地内的输入和计算。
Survey of Model Performance Attacks
模型破坏是一种“训练时间”威胁,可以分为两种类型的对抗目标:非目标中毒攻击和目标中毒攻击。非目标中毒攻击的目的是通过降低给定模型的整体性能来诱导拒绝服务。有针对性的攻击,也被称为后门和木马攻击,目的是操纵模型来学习恶意错误分类对特定分布的样本,同时保持全球目标的高精度。图1突出显示了单个设备上的对手如何通过操纵操作更新破坏全球联邦学习系统。图2说明了如何根据实验设置对攻击和防御进行潜在的分类。数据中毒和模型中毒可以通过两种中毒方法实现靶向和非目标攻击。数据中毒攻击旨在恶意操纵训练和/或推理样本,间接导致模型损坏。模型中毒试图通过操纵学习过程本身来直接诱导模型腐败。

数据中毒
对联邦学习系统的数据中毒攻击通常会损害训练数据的完整性,从而损害模型的性能,例如在推理过程中为某些触发器插入后门,从而降低整个模型的准确性。在最近的文献中出现了几种不同的数据中毒方法,总结如下:
- 标签翻转:能够获得训练数据的对手在排列标签的同时保持功能的完整。之前对修改后的国家标准与技术研究所数据集的攻击涉及将7个人的标签翻转为1个人,反之亦然,同时保留图像内容本身,从而故意欺骗联邦学习模型
- 后门插入:对手可以通过添加邮票或水印来操作训练数据,从而使模型能够通过这些操作学习输入上的触发器,同时仍然保持干净数据的准确性,从而使攻击更难检测。
模型中毒
模型中毒涉及到一种广泛的方法来操纵联邦学习的训练程序。虽然数据中毒攻击可以被认为是模型中毒的一个子集,但其他攻击,如直接操纵梯度和改变学习规则,都属于模型中毒的保护伞下,如下所述:
- 梯度操作:对手可以操纵局部模型的梯度来降低整体模型的性能,例如,通过降低整体精度。21通过直接梯度操作插入隐藏的全局模型后门。
- 训练规则操作:其他几项工作涉及到操作模型训练规则1,并证明了通过这种方法的模型中毒远比数据中毒更有效;在某些情况下,即使操纵单一的局部模型也会危及全局模型。Bhagoji等人报道了一个高级训练规则操纵的例子。22作者通过在目标函数中添加一个惩罚项来最小化恶意和良性权重更新分布之间的距离,成功地实现了隐形目标模型中毒攻击
对数据隐私攻击的调查
联邦学习已经引起了一些寻求对敏感数据集进行大规模分析的社区的关注。虽然联邦学习可以在不将数据集转移到外部服务的情况下实现协作式机器学习,但它并不能防止来自DL模型参数的信息泄漏。机器学习模型通常很容易受到攻击,其目的是通过交互和分析训练模型的参数来提取关于训练数据的信息。1因此,各种隐私攻击已经被证明可以从存储在模型参数本身中的训练数据中提取有意义的见解。这些类型的攻击可以分为模型反演、4个隶属度推理、5个和生成式对抗网络(GAN)重建。此外,对这些攻击的各种研究表明,在差异方面存在显著的漏洞
隐私,这是一种被广泛采用的技术,将在后面关于防御方法的章节中讨论。回想一下,在联邦学习中,由于所有客户端在每一轮中都会收到全局模型的副本,因此在学习阶段,任何对数据隐私的推理阶段攻击也是可行的。然而,防止学习阶段的数据提取明显更具挑战性。一个有效的学习阶段防御机制需要考虑到在模型开发过程中与模型之间的连续的、分布式的交互作用
模型反演攻击
模型反演攻击已经成功地描述了模型所表示的类和/或单个样本的敏感特性。1给定白盒对模型的访问,Fredrikson等人23报告说,对决策树的模型反演攻击可以识别敏感变量(调查响应)的实例,而没有假阳性。另一个例子是,在一项药物遗传学研究中,攻击者可以预测患者的遗传标记,只给出模型和一些关于目标个体的基本人口统计学信息
成员推理攻击
成员推理攻击试图确定一个给定的样本是否包含在训练数据集中和/或一个给定的样本是否属于该模型所代表的特定类。此外,即使目标与类的主要特征不相关,这种类型的攻击也可以成功
GAN重建攻击
GAN重建攻击类似于模型反演攻击;然而,它们被证明更强大,并已被证明可以生成在统计上具有训练数据代表性的合成样本。6Hitaj等人表明,当攻击更复杂的DL架构,如卷积神经网络时,传统的模型反演方法完全失败,而GAN重建攻击可以成功地生成真实的样本,即使在训练过程中应用中等差异隐私。此外,模型反演只需要在训练后访问鉴别器模型,而GANs则联合训练生成器和鉴别器。因此,在协作学习过程中,对手有可能影响良性客户,在不知情的情况下提交梯度更新,泄露比预期更多的私人信息
Survey of Defense Methods
最近对联邦学习安全的研究旨在强调测试现有的防止模型腐败和私人信息提取的方法。从根本上说,这些防御目标有一些共同之处潜在的属性,可以与关于泛化的基本机器学习理论有关。本质上,当一个模型概括得很好时,它已经学会了表示生成其训练示例的潜在统计分布。当一个模型没有被推广时,一个常见的结果被称为过拟合。过拟合可以被认为是“记忆”训练数据,这通常表明,训练数据的准确性明显高于看不见的(测试)数据
在防止模型损坏时,一种防御方法试图防止模型对恶意更新的过拟合,最大限度地减少潜在恶意更新的总体影响,并防止恶意更新被纳入全局模型中。一些防止私有信息泄漏的方法,如对抗性正则化技术,9试图防止模型过拟合或“记忆”关于任何给定数据点的区别信息。事实上,在泛化和隐私保护之间存在着一种有趣但又未被充分探索的关系。1我们将简要强调防御方法的主要类型:差异隐私是隐私保护的标准,而聚合机制和离群值检测主要旨在减轻模型腐败攻击的影响
差异隐私
差异隐私是一种正式的数学保证,它量化了数据库中单个条目所显示的信息量。例如,隐私受限的统计学家将使用差异隐私来约束两个相邻数据集之间的可测量差异(恰好缺少一个条目)。因此,差异隐私的目的是提供一个保证,即在一个数据集中,没有一个单一的记录能够与其他记录有意义地区别开来。
在联邦学习系统中,差异隐私可以用来最小化DL模型参数中信息泄漏的风险。最常见的情况是,统计噪声可以添加到用于查询或分析客户端数据集的算法的输出中。此外,客户机提供的信息可以被正则化技术所限制,这些正则化技术试图排除异常值,以便聚合的更新可以限制全局分布中的方差。在实践中,差异隐私可以通过多种方式来实现。例如,在本地差异隐私中,每个客户端在在网络中广播其更新之前添加自己的隐私。1相比之下,中心差异隐私依赖于一个受信任的服务器来代表所有客户端实现隐私转换。当考虑模型性能攻击时,巴格达沙扬等人21证明了局部差异隐私可以成功地抵御后门攻击,但所需的噪声水平显著阻碍模型的学习能力。需要进一步的研究来探索差异隐私作为一种除了隐私保护之外的防御方法的效用的程度。
鲁棒聚合
聚合算法是联邦学习的核心。对于拜占庭鲁棒算法有广泛的研究,这些算法寻求在面对网络不稳定时维持高性能的模型开发,如客户端退出、错误更新和恶意行为者。许多基本的拜占庭稳健聚合,如克鲁姆、Bulyan、修剪后的平均值和坐标中值1,都依赖于不适合联邦学习的理论假设,它们的弱点已经在之前的工作中进行了实证评估。例如,巴格达沙扬等人21证明,控制1-10%客户端的攻击者可以分别通过Krum聚合算法选择80-97%的时间
因此,人们提出了许多自适应聚合机制,如自适应模型平均,以拒绝系统损坏的客户端更新1和基于残差的重加权,以减少数据中毒攻击的影响。例如,Munoz等人报告说,他们的自适应联合平均算法可以90-100%成功检测拜占庭对抗客户端,但无法找到有噪声的对抗客户端,成功率仅为2.7-20%。
离群值检测
这是一种更积极主动的防御形式,旨在明确地识别和否认对系统的恶意影响。一种流行的方法,即对负面影响的拒绝,可以通过测量一个给定更新的测试误差,并拒绝它并没有改善全球模式。虽然这可能针对非目标的中毒攻击有效,但它未能解决有针对性的秘密和/或后门攻击,这些攻击不会降低全球目标的性能。另一种基于检测的防御被称为TRIM,它试图通过去除具有残差高的异常值,使全局目标的损失最小化。1Jagielski等人报告说,在抵御对医疗保健、贷款和住房数据的多种中毒攻击时,TRIM方法将均方误差保持在未中毒线性回归模型的1%以内
一种有趣的检测机制可以计算客户端更新之间的距离测量,它自然适合于联邦学习系统,在联邦学习系统中,理解客户端分布的异质性是至关重要的。其中一种方法被称为FoolsGold,它基于贡献的相似性来适应客户的学习率。14一个关键的发现是,在非独立同分布环境中(这是联邦学习的典型情况),一组串通恶意中毒攻击的系统与不同的良性客户相比具有明显的统计相似性。在一种补充方法中,Bhagoji等人22表明,当大多数良性客户在一个全局目标上合作时,通过测量与参数更新的全局分布的距离,可以将恶意更新区分为离群值。
Federated Machine Learning: Concept and Applications
Definition of Federated Learning
联合训练的模型的准确率和传统集中训练的模型的准确率相差小于 ϵ \epsilon ϵ
Indirect information leakage
直接梯度传肯定不安全
后门攻击
研究人员发现了协作机器学习系统中的潜在漏洞,其中不同各方在协作学习中使用的训练数据很容易受到推理攻击。他们表明,一个对抗性的参与者可以推断出成员身份以及与训练数据子集相关的属性
In [62], authors expose a potential security issue associated with gradient exchanges between different parties, and propose a secured variant of the gradient descent method and show that it tolerates up to a constant fraction of Byzantine拜占庭 workers.
分类
- 联邦迁移学习(FTL)。联邦迁移学习适用于两个数据集不仅在样本上而且在特征空间上都有不同的情况。
- 安全定义-水平联邦学习系统:通常假定诚实的参与者和安全对抗诚实但好奇的服务器[9,51]。也就是说,只有服务器才能妥协数据参与者的隐私,因此不允许将信息从任何参与者泄漏到服务器。在这些工程中已提供了安全证明。最近,另一个考虑恶意用户[29]的安全模型也被提出,这带来了额外的隐私挑战。在训练结束时,向所有参与者公开通用模型和整个模型参数。
如果使用SMC[9]或同态加密[51]进行梯度聚合,则证明了上述体系结构可以防止半诚实服务器的数据泄漏。但在另一个安全模型中,它可能会受到恶意参与者在协作学习过程中训练生成对抗网络(GAN)的攻击
- 安全定义-纵向联邦学习系统:通常假定为诚实但好奇的参与者。例如,在两党案件中,两党不串通,最多有一方被对手妥协。安全定义是,对手只能从它损坏的客户端学习数据,而不能从其他客户端学习的数据,超出输入和输出显示的数据。为了便于双方之间的安全计算,有时会引入一个半诚实的第三方(STP),在这种情况下,假定STP不与任何一方勾结。SMC为这些协议[25]提供了正式的隐私证明。在学习结束时,每一方只保存与其自身特征相关联的模型参数,因此在推理时,双方还需要协作生成输出。
第1部分。已加密的实体对齐。由于两家公司的用户组不相同,系统使用[38,56]等基于加密的用户ID对齐技术来确认双方的共同用户,而不需要A和B公开他们各自的数据。在实体对齐期间,系统不会公开彼此之间不重叠的用户。
第2部分。已加密的模型培训。在确定了公共实体之后,我们可以使用这些公共实体的数据来训练机器学习模型。培训过程可分为以下四个步骤:
Step 1: collaborator C creates encryption pairs, send public key to A and B;
Step 2: A and B encrypt and exchange the intermediate results for gradient and loss calculations;
Step 3: A and B computes encrypted gradients and adds additional mask, respectively,and B
also computes encrypted loss; A and B send encrypted values to C;
Step 4: C decrypts and send the decrypted gradients and loss back to A and B; A and B
unmask the gradients, update the model parameters accordingly
因为在训练过程中,双方接收到的损失和梯度与联合构建一个地方收集数据的模型时收到的损失和梯度完全相同,也就是说,这个模型是无损的。该模型的效率取决于加密数据的通信成本和计算成本。在每次迭代中,A和B之间发送的信息与重叠样本的数量变化。因此,采用分布式并行计算技术可以进一步提高该算法的效率
Vulnerabilities in Federated Learning
安全多方计算(SMC)或零知识证明(ZKP)
恶意的对手将试图学习其他客户的私人状态,并通过破坏、重播或删除消息来偏离FL协议。即使是良性的客户机在联合设置中也不能被信任,因为它们可能会好奇并试图推断敏感信息,在不破坏模型更新的情况下推断敏感信息。在传统的深度学习中,恶意数据提供者通常仅限于静态攻击,即在训练开始之前提供有毒数据。相比之下,恶意客户端持续参与FL,并可能在整个模型训练过程中发起攻击。实际上,攻击者可以随着训练的进行而自适应地改变训练数据或模型更新。
FL协议也可能会受到服务器漏洞的影响。服务器可以观察客户端更新,篡改聚合过程,并控制全局模型和压缩参数的参与者的视图。
FL的各种漏洞来源是什么?•FL生态系统中的安全攻击是什么?•是什么使这些攻击成为FL生态系统的独特性呢?•如何保护FL免受对抗性攻击?•FL拓扑结构如何影响攻击面?
梯度泄漏
FL为分布式数据的训练提供了一种保护隐私的解决方案。然而,尽管数据在训练过程中没有明确共享数据,但对手仍然可以揭示微妙的信息,甚至重建大约[31],[32]的原始数据。此外,正如[33]所示,即使是一小部分中间结果,如梯度更新,也可以揭示有关本地数据的敏感信息。因此,梯度的传输实际上可能会泄漏私人信息,这种现象被称为梯度泄漏
对手可以利用泄露的梯度来推断关于良性参与者的有价值的信息。这些信息对于克服防御[34]很有价值。拜占庭式的恶意客户端可以使用关于良性参与者的信息来调整他们的更新,使其具有与合法的模型更新相似的分布,从而使它们很难检测到[35]。拜占庭式的攻击通常比其他类型的攻击更强,因为它们严格地增强了对手的能力。
聚合算法
聚合算法协调全局模型参数的学习。由于隐私保证,不能检查客户端数据和训练管道的异常,聚合器代表了抵御攻击最关键的防线。它应该包含适当的机制来检测异常的客户端更新并丢弃它们。聚合算法中包含的异常检测机制保证了全局模型[39]的收敛性和与异构客户端[40]、[41]的公平性。不能正确配置和维护健壮的聚合算法将使全局模型脆弱和不可信任
联邦学习的分布式性质
分布式训练为串通和分布式攻击打开了大门,在分布式攻击中,多方串通发起协调攻击。过去的客户可以与当前或未来的参与者协调,参与对全局模型当前或未来更新的攻击。例如,[44]的作者最近提出了分布式后门攻击(DBA),这是一种通过充分利用FL的分布式特性而开发出来的新型串通攻击。DBA将全局触发模式分解为单独的局部模式,并将它们嵌入到不同敌对方的训练集中。他们证明了DBA在金融和图像数据等不同的数据集上更加持久和隐秘。此外,非均匀的数据分布在FL中引入了一个潜在的偏差来源。它也对在避免误报方面的防御策略提出了挑战。
攻击分类
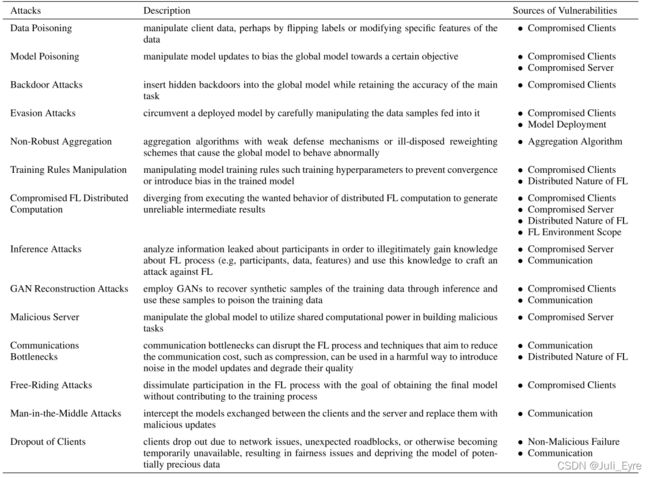
一个攻击是利用恶意攻击者的漏洞来操纵全局模型的。对抗性攻击通常可以根据其目标分为两类:目标攻击和非目标攻击。目标攻击通常被称为后门攻击,因为对手的目标是改变模型在特定目标子任务上的行为,同时在主要任务上保持良好的总体准确性。例如,对于一个图像分类应用程序,攻击者可能会破坏模型,将“带条纹的汽车”错误地分类为“鸟”,同时确保其他汽车实例被正确地分类。在非目标攻击下,对手的目标是降低模型的全局精度或“完全打破”全局模型。表2提供了对FL的攻击的全面概述:
拜占庭攻击
拜占庭攻击主要考虑的是多用户的情况。攻击方控制了多个用户,这些用户被称为拜占庭用户。拜占庭用户可以给中心服务器发送任意参数,而不是发送本地更新后的模型参数。这种攻击会导致全局模型在局部最优处收敛,甚至导致模型发散。假设拜占庭客户端拥有了访问联邦学习模型的权限,或者拥有非拜占庭式客户端更新的白盒访问权限,通过正常的模型更新调整输出,难以被系统检测。对于拜占庭类型的攻击,参考文献提出通过冗余和数据洗牌的更新防御机制来防御拜占庭攻击,但是存在的问题是,这些机制通常具有严格的理论保证,并且建立在一些难以实现的假设上。例如,需要假定服务器可以直接访问数据,这些假设与联邦学习的实现存在矛盾,并且会增加通信成本。如何在联邦学习中协调和实现这种基于冗余的防御拜占庭攻击机制是一个很有挑战的问题
- 基于训练数据的攻击:这种攻击也被称为数据中毒攻击,其目的是通过操纵局部训练数据来误导全局模型。一般来说,这种攻击主要有三种方法:1标签翻转:攻击者“翻转”其训练数据的标签到任意的标签(例如,通过一个排列函数)。2.添加噪声:攻击者通过添加噪声来污染数据集,从而降低模型的质量。3后门触发器:攻击者向原始数据集的一个小区域注入一个触发器,导致分类器错误地分类为目标类别。
- 基于参数的攻击:这种攻击方法涉及到改变局部参数(即梯度或模型),从而使中央服务器聚合一个损坏的全局模型。有两种方法可以修改参数:1修改从局部数据集学习到的参数的方向和大小,例如,翻转局部迭代和梯度的符号,或放大大小。2直接修改参数,如从高斯分布中随机抽取一个数字,并将其作为局部模型的参数之一进行处理。
根据服务器检测或逃避异常更新的原理,现有的防御方案可分为四类:基于距离的防御方案、基于性能的防御方案、基于统计的防御方案和基于目标优化的防御方案。
- The Distance based Defense Schemes
距离其他远的被丢弃 - The Performance based Defense Schemes
在这个类别中,每个更新都将通过服务器提供的干净数据集进行评估,这样任何表现不佳的更新都将被分配低权重或直接删除。 - The Statistics based Defense Schemes
这类方案利用上传更新的统计特征,如中位数或平均值,以规避异常更新,以获得一个稳健的更新。 - The Target Optimization based Defense Schemes
基于目标优化的防御方案是指对不同的目标函数进行优化,以提高全局模型的鲁棒性。Li等人[5]提出了RSA(拜占庭-鲁棒随机聚合),它在目标损失函数中增加了一个正则化项,使每个正则局部模型被迫接近全局模型。据我们所知,这是迄今为止这一类中唯一的工作
我们知道基于距离的防御方案通常依赖于恶意攻击者的参数分布分散且偏离良性参数分布的假设,因此只适合抵抗产生明显异常参数的攻击。例如,标签翻转攻击很容易导致参数的重大变化。然而,很明显,当攻击引起微弱的变化时,这种防御方案表现不佳。
基于性能的防御方案通过直接验证其性能来检测异常更新,这比其他解决方案更可靠。Zeno[4]在基于数据的攻击(例如,符号翻转)和基于参数的攻击(例如,随机梯度)。然而,它依赖于一个干净的辅助数据集来进行检查,这妨碍了其实用性。此外,Zeno[4]具有较高的时间复杂度,因为在使用自动编码器时需要进行耗时的预训练。
基于统计的防御方案依赖于计算中位数或均值来规避异常参数,只适用于恶意用户数量小于总用户数量一半的情况,否则当恶意更新占主导地位时,合法的更新将被忽略。相比之下,基于目标优化的防御方案具有较高的效率。例如,根据[5]在MNIST数据集上进行的实验结果,RSA的时间成本约为45s,而中位数、Krum和GeoMed的时间成本分别约为50s、62s和127s
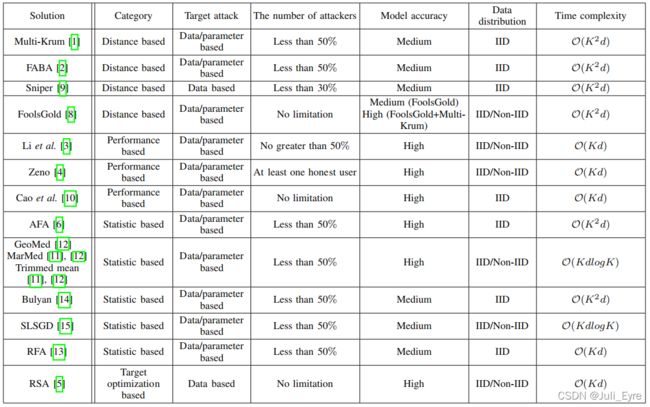
表一:拜占庭式稳健FL法的综合比较,“中”和“高”分别表示精度低于和接近非攻击者的情况。
在标准的联邦学习设置中,当在每次迭代中聚合更新时,分配给每次更新的权重完全取决于本地训练数据集的大小。由于隐私方面的原因,中央服务器没有权威或有效的手段来检查客户的培训数据的大小和质量。因此,本地数据集的大小是由客户端自己声明的,而不需要进行任何验证。
攻击方法:
基于这一观察结果,任何恶意客户端都可以任意地谎报其数据集的大小,以获得较高的权重。根据攻击者申报他们的方式训练数据集的大小,我们考虑以下两个简单的误报案例:
攻击者的训练数据集大小比常规客户端要小得多,但它们声明它们的大小与常规客户端相似。2)攻击者和常规客户端具有相似的训练数据集大小,但攻击者声明他们的训练集大小比常规客户端要大得多。
步骤1:中央服务器向每个选定的客户机广播全局模型。步骤2:每个客户端,包括攻击者,根据其本地训练数据集对全局模型进行重新训练。步骤3:客户端将更新发送到服务器。攻击者错误报他们的数据集大小,而常规客户端忠实地报告他们的训练集大小。步骤4:中央服务器聚合接收到的更新模型,以获得一个新的全局模型,并重复步骤1到步骤4,直到全局模型收敛
对策:
此外,正如我们的实验所示,基于性能的防御方案,如芝诺,比其他方案表现得好得多。我们认为这种防御方案在未来可以做得更好,因为要确定一个更新是良性的还是恶意的,最直接的方法是检查其性能。当干净的测试数据集为某些实验设计得很好时,由权重攻击产生的“坏的”更新肯定会有不同的作用。对于基于统计的和基于目标优化的防御方案,我们坚信,通过充分利用局部更新的统计特征或选择良好的损失来优化目标函数,也可以有效地减轻权重攻击。
BrainTorrent: A Peer-to-Peer Environment for Decentralized Federated Learning
我们首次提出了一种无服务器的、点对点的联合学习方法,即客户端在它们之间直接进行通信。我们把这种分散的环境称为BrainTorrent。本设计的动机是为了满足上述对一组医疗中心进行合作的要求。缺少中央服务器主体不仅使我们的环境能够抵抗故障,而且还排除了对每个人都信任的主体的需要。此外,任何客户端在任何时候都可以非常动态地启动一个更新过程。由于通信回合的数量并不是医疗中心的瓶颈,因此它们可以更频繁地进行互动。此外,任何客户端在任何时候都可以非常动态地启动一个更新过程。由于通信回合的数量并不是医疗中心的瓶颈,因此它们可以更频繁地进行互动。由于每个客户端的交互和更新过程的高频率高,脑流中的模型收敛速度更快,达到了与汇集所有客户端数据训练的模型相似的精度。
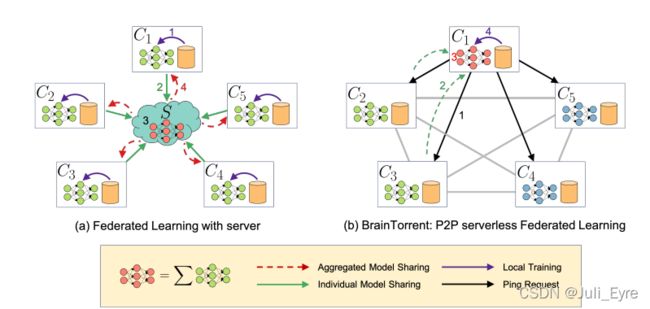
BrainTorrent:
- 一个客户端(C1)向所有其他客户端发送一个ping请求(黑线),以检查它们的版本。
- 客户端C2和C3有一个较新的版本(绿色),而C4和C5没有(蓝色)。只有C2和C3的权重被发送到C1(绿色虚线)
- 结合C1、c2和c3、4形成了一个聚合模型(红色部分)
- 聚合模型根据C1的局部数据进行了微调(紫色线)

SecureBoost纵向联邦