linux cuda 编程指南,CUDA编程指南阅读笔记
3.3 内存层次(Memory Hierarchy)
在GPU上CUDA线程可以访问到的存储资源有很多,每个CUDA线程拥有独立的本地内存(local Memory);每一个线程块(block)都有其独立的共享内存(shared memory),共享内存对于线程块中的每个线程都是可见的,它与线程块具有相同的生存时间;同时,还有一片称为全局内存(global memory)的区域对所有的CUDA线程都是可访问的。
除了上述三种存储资源以外,CUDA还提供了两种只读内存空间:常量内存(constant memory)和纹理内存(texture memory),同全局内存类似,所有的CUDA线程都可以访问它们。对于一些特殊格式的数据,纹理内存提供多种寻址模式以及数据过滤方法来操作内存。这两类存储资源主要用于一些特殊的内存使用场合。
一个程序启动内核函数以后,全局内存、常量内存以及纹理内存将会一直存在直到该程序结束。下面是CUDA的内存层次图:
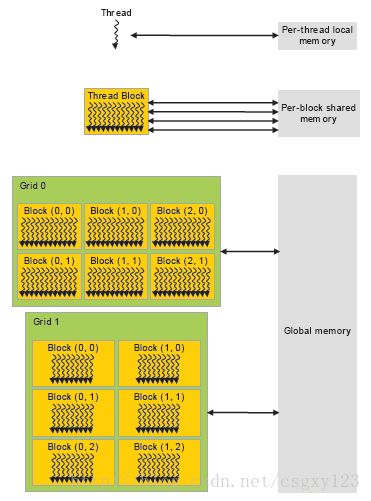
3.4 异构编程(Heterogeneous Programming)
CUDA的异构编程模型假定CUDA线程都运行在一个可被看做CPU协处理器的芯片上,这就使得CUDA内核函数可以和CPU端C程序的运行并行运行,从而加快程序的运行效率。为了达到这个效果,CUDA程序需要管理两大块由DRAM构成的内存区域:CPU端可以访问到的主机内存(host memory)以及GPU端供CUDA内核访问到的设备内存(device memory),设备内存主要由全局内存、常量内存以及纹理内存构成。现在,CUDA程序的运行机制便很明了了:CPU端代码生成原始数据,通过CUDA运行时函数库将这些原始数据传输到GPU上,在CPU端启动CUDA内核函数进行运算,然后将运算结果从设备端传输到主机端,计算任务便完成了。
4.CUDA C语言编程接口
异构程序设计跟传统的串行程序设计差别是很大的,学习起来也是非常不容易的。NVIDIA非常够意思,为了简化CUDA的学习曲线,它采用了绝大多数程序员都熟悉的C语言作为其根基,CUDA C是NVIDIA为程序员提供的一类编程接口,它实际上是一个C语言的扩展,在C的基础上增加了一些新的语法和变量,并且提供了功能丰富的库函数,方便程序员使用GPU进行异构计算。
除了前面章节提到的CUDA最基本、最核心的概念以外,CUDA C呈现给程序员的接口主要由两大类API构成,它们分别是CUDA Runtime API和CUDA Driver API,Runtime API实际上是对于Driver API的封装,其目的自然是方便程序员的代码编写工作。Driver API为用户提供了更细一层的控制手段,通过它可以控制诸如CUDA Contexts(一种类似主机进程的概念)以及CUDA Modules(类似主机动态加载库的概念)等更加底层的CUDA模块。
4.1 NVCC编译器
任何一种程序设计语言都需要相应的编译器将其编译为二进制代码,进而在目标机器上得到执行。对于异构计算而言,这一过程与传统程序设计语言是有一些区别的。为什么?因为CUDA它本质上不是一种语言,而是一种异构计算的编程模型,使用CUDA C写出的代码需要在两种体系结构完全不同的设备上执行:1、CPU;2、GPU。因此,CUDA C的编译器所做的工作就有点略多了。一方面,它需要将源代码中运行在GPU端的代码编译得到能在CUDA设备上运行的二进制程序。另一方面,它也需要将源代码中运行在CPU端的程序编译得到能在主机CPU上运行的二进制程序。最后,它需要把这两部分有机地结合起来,使得两部分代码能够协调运行。
CUDA C为我们提供了这样的编译器,它便是NVCC。严格意义上来讲,NVCC并不能称作编译器,NVIDIA称其为编译器驱动(Compiler Driver),本节我们暂且使用编译器来描述NVCC。使用nvcc命令行工具我们可以简化CUDA程序的编译过程,NVCC编译器的工作过程主要可以划分为两个阶段:离线编译(Offline Compilation)和即时编译(Just-in-Time Compilation)。
离线编译(Offline Compilation)
下面这幅图简单说明了离线编译的过程:

在CUDA源代码中,既包含在GPU设备上执行的代码,也包括在主机CPU上执行的代码。因此,NVCC的第一步工作便是将二者分离开来,这一过程结束之后:
1. 运行于设备端的代码将被NVCC工具编译为PTX代码(GPU的汇编代码)或者cubin对象(二进制GPU代码);
2. 运行于主机端的代码将被NVCC工具改写,将其中的内核启动语法(如<<>>)改写为一系列的CUDA Runtime函数,并利用外部编译工具(gcc for linux,或者vc compiler for windows)来编译这部分代码,以得到运行于CPU上的可执行程序。
完事之后,NVCC将自动把输出的两个二进制文件链接起来,得到异构程序的二进制代码。
即时编译(Just-in-time Compile)
任何在运行时被CUDA程序加载的PTX代码都会被显卡的驱动程序进一步编译成设备相关的二进制可执行代码。这一过程被称作即时编译(just-in-time compilation)。即时编译增加了程序的装载时间,但是也使得编译好的程序可以从新的显卡驱动中获得性能提升。同时到目前为止,这一方法是保证编译好的程序在还未问世的GPU上运行的唯一解决方案。
在即时编译的过程中,显卡驱动将会自动缓存PTX代码的编译结果,以避免多次调用同一程序带来的重复编译开销。NVIDIA把这部分缓存称作计算缓存(compute cache),当显卡驱动升级时,这部分缓存将会自动清空,以使得程序能够自动获得新驱动为即时编译过程带来的性能提升。
有一些环境变量可以用来控制即时编译过程:
1. 设置CUDA_CACHE_DISABLE为1将会关闭缓存功能
2. CUDA_CACHE_MAXSIZE变量用于指定计算缓存的字节大小,默认情况下它的值是32MB,它最大可以被设置为4GB。任何大于缓存最大值得二进制代码将不会被缓存。在需要的情况下,一些旧的二进制代码可能被丢弃以腾出空间缓存新的二进制代码。
3. CUDA_CACHE_PATH变量用于指定计算缓存的存储目录地址,它的缺省值如下:

4. 设置CUDA_FORCE_PTX_JIT为1会强制显卡驱动忽略应用程序中的二进制代码并且即时编译程序中的嵌入PTX代码。如果一个内核函数没有嵌入的PTX代码,那么它将会装载失败。该变量可以用来确认程序中存在嵌入的PTX代码。同时,使用即时编译(just-in-time Compilation)技术也可确保程序的向前兼容性。
4.2 兼容性
1、二进制兼容性
二进制代码是设备相关的,使用NVCC编译器编译时,若指定-code选项,则会编译产生目标设备的二进制cubin对象。例如,编译时使用-code=sm_13会产生适用于计算能力1.3的二进制代码。二进制代码在CUDA计算设备上具有小版本的向前兼容性,但是在大版本上不具备兼容性。也就是说,对于计算能力X.y的硬件,使用-code=sm_Xy编译后,程序能够运行于计算能力X.z(其中z>=y)的硬件上,但不能运行在计算能力M.n(M!=X)的硬件上。
2、PTX代码兼容性
不同计算能力的设备所支持的PTX指令条数是不同的,一些PTX指令只在拥有较高计算能力的设备上被支持。例如,全局内存(global Memory)的原子操作指令只能用于计算能力不小于1.1的设备;双精度浮点运算指令只能用于计算能力不小于1.3的设备。在将C语言编译为PTX代码时,NVCC使用-arch编译选项指定PTX代码目标设备的计算能力。因此,要想使用双精度运算,编译时必须使用选项-arch=sm_13(或使用更高的计算能力),否则NVCC会自动将双精度操作降级为单精度操作。
为某一特定设备产生的PTX代码,在运行时总是能够被具有更高计算能力的设备JIT编译为可执行的二进制代码。
3、应用程序兼容性
执行CUDA程序有两种方式,一种是直接加载编译好的CUDA二进制代码运行,另一种是首先加载程序中的PTX代码,再执行JIT编译得到二进制的设备可执行文件,然后运行。特别需要注意的是,为了让程序运行具有更高计算能力的未来设备上,必须让程序加载PTX代码。
事实上,在一个CUDA C程序中可以嵌入不止一个版本的PTX/二进制代码。那么,具体执行时哪一个版本的PTX或者二进制代码会得到执行呢?答案是:最兼容的那个版本。例如编译一个名为x.cu的CUDA源代码:
![]()
将会产生兼容计算能力1.1硬件的二进制代码(第一排的-gencode选项)以及兼容计算能力1.1设备的PTX和二进制代码,这些代码都将会嵌入到编译后的目标文件中。
主机端将会产生一些额外的代码,在程序运行时,这些代码会自动决定装载哪一个版本的代码来执行。对于上面的例子:
计算能力1.0的设备运行该程序将会装载1.0版本的二进制代码
计算能力1.1、1.2或者1.3的设备运行该程序将会装载1.1版本的二进制代码
计算能力2.0或者更高的设备运行该程序将会装载1.1版本的PTX代码进而对其进行JIT编译得到相应设备的二进制代码
同时,x.cu还可以在程序中使用一些特殊的宏来改变不同设备的代码执行路径。例如,对于计算能力1.1的设备而言,宏__CUDA_ARCH__等于110,在程序中可以对该宏的值进行判断,然后分支执行程序。
NVCC用户手册列出了很多-arch,-code和-gencode等编译选项的简化书写形式。例如,-arch=sm_13就是-arch=compute_13 -code=compute13, sm_13的简化形式。更多详尽的内容请参阅该手册。
4、C/C++兼容性
NVCC编译器前端使用C++语法啊规则来处理CUDA源文件。在主机端,CUDA支持完整的C++语法;而在设备端,只有部分C++语法是被支持的。这方面更为详尽的讨论请参见《CUDA C程序设计指南》的C/C++语言支持章节。
5、64位兼容性
64位版本的nvcc编译器将设备代码编译为64位模式,即指针是64位的。运行64位设备代码的先决条件是主机端代码必须也使用64位模式进行编译。同样,32位版本的nvcc将设备代码编译为32位模式,这些代码也必须与相应的32位主机端代码相配合方能运行。
32位nvcc编译器可以使用-m64编译选项将设备代码编译为64位模式。同时64位nvcc编译器也可使用-m32编译选项将设备代码编译为32位模式。
4.3 CUDA C Runtime
CUDA C Runtime使用cudart动态链接库实现(cudart.dll或者cudart.so),运行时中所有的入口函数都以cuda为前缀。
4.3.1 初始化
CUDA C Runtime函数库没有明确的初始化函数,在程序第一次调用Runtime库函数时它会自动初始化。因此,在记录Runtime函数调用时间和理解程序中第一个Runtime调用返回的错误代码时,需要将初始化考虑在内。
在初始化期间,Runtime将会为系统中每一个设备创建一个CUDA上下文(类似CPU中进程的数据结构),这个上下文是设备的基本上下文,它被程序中所有的主机线程所共享。创建过程在后台运行,并且,Runtime将隐藏基本上下文使之对Runtime API这一层次的程序员不可见。
当一个主机线程调用cudaDeviceReset()函数时,它将会销毁线程当前控制设备的基本上下文。也就是说,当线程下一次调用runtime函数时将会重启初始化,一个新的CUDA基本上下文将被创建出来。
4.3.2 设备内存
正如前面异构计算章节所讲,CUDA编程模型假定系统是由主机和设备构成的,它们分别具有自己独立的内存空间。Runtime负责设备内存的分配,回收,拷贝以及在主机和设备间传输数据的工作。
设备内存可以有两种分配方式:线性内存或者CUDA数组
CUDA数组是一块不透明的内存空间,它主要被优化用于纹理存取。
线性内存空间与平时我们访问的内存类似,对于计算能力1.x的设备来说,它存在于一个32位的地址空间。对于更高计算能力的设备而言,它存在于一个40位的地址空间中。因此,单独分配的实体可以使用指针来相互应用。
我们通常使用cudaMalloc()函数分配线性内存空间,使用cudaFree()函数释放线性内存空间,使用cudaMemcpy()函数在主机和设备之间传输数据。下面是CUDA Vector Add代码示例的一些片段:
// Device code
__global__ voidVecAdd(float*A,float*B,float*C,intN) {
inti = blockDim.x * blockIdx.x + threadIdx.x;
if(i
C[i] = A[i] + B[i];
}
// Host code
intmain() {
intN = ...;
size_tsize = N *sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float*h_A = (float*)malloc(size);
float*h_B = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float*d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
intthreadsPerBlock = 256;
intblocksPerGrid = (N +threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<>>(d_A, d_B, d_C, N);
// Copy result from device memory to host Memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}
片段展示了设备内存的分配,传输以及回收过程。
除了上面展示的方法,我们还可以使用cudaMallocPitch()和cudaMalloc3D()函数来分配线性内存。这些函数能够确保分配的内存满足设备内存访问的对齐要求,对于行地址的访问以及多维数组间的数据传输提供高性能保证,因此非常适合对于二维和三维数组内存空间的分配。下面的代码片段展示了分配和使用尺寸为width x height的二维数组的技术:
// Host code
intwidth = 64, height = 64;
float*devPtr;
size_tpitch;
cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
// Device code
__global__ voidMyKernel(float* devPtr,size_tpitch,intwidth,intheight) {
for(intr = 0; r
float* row = (float*)((char*)devPtr + r * pitch);
for(intc = 0; c
floatelement = row[c];
}
}
}
下面的代码片段展示了一个尺寸为width x height x depth的三维数组的分配和使用方法:
// Host code
intwidth = 64, height = 64, depth = 64;
cudaExtent extent = make_cudaExtent(width * sizeof(float), height, depth);
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
MyKernel<<<100, 512>>>(devPitchedPtr, width, height, depth);
// Device code
__global__ voidMyKernel(cudaPitchedPtr devPitchedPtr,intwidth,intheight,intdepth) {
char* devPtr = devPitchedPtr.ptr;
size_tpitch = devPitchedPtr.pitch;
size_tslicePitch = pitch * height;
for(intz = 0; z
char* slice = devPtr + z * slicePitch;
for(inty = 0; y
float* row = (float*)(slice + y * pitch);
for(intx = 0; x
floatelement = row[x];
}
}
}
更多详细的内容请查阅参考手册。
下面的代码示例展示了多种使用Runtime API访问全局变量的技术:
__constant__floatconstData[256];
floatdata[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
cudaMemcpyFromSymbol(data, constData, sizeof(data));
__device__ floatdevData;
floatvalue = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
__device__ float* devPointer;
float* ptr;
cudaMalloc(&ptr, 256 * sizeof(float));
cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr));
使用cudaGetSymbolAddress()函数可以获得被声明存储在全局内存中的变量地址。为了获得分配内存的大小,可以使用cudaGetSymbolSize()函数。
4.3 CUDA C Runtime
4.3.3 共享内存(Shared Memory)
共享内存是CUDA设备中非常重要的一个存储区域,有效地使用共享内存可以充分利用CUDA设备的潜能,极大提升程序性能。那么,共享内存有哪些特点呢?
1、共享内存(shared Memory)是集成在GPU处理器芯片上的(on-chip),因此相比于存在于显存颗粒中的全局内存(global Memory)和本地内存(local Memory),它具有更高的传输带宽,一般情况下,共享内存的带宽大约是全局内存带宽的7-10倍。
2、共享内存的容量很小。根据NVIDIA官方文档的说法,在计算能力1.x的设备中,每一个流多处理器(Streaming Multiprocessor)上的共享内存容量为16KB。对于计算能力2.x、3.0及3.5的设备该参数为48KB。因此共享内存是稀有资源。
3、共享内存在物理上被划分为很多块,每一块被称为一个存储体(bank)。在同一时刻,CUDA设备可以同时访问多个存储体。因此,如果一次针对共享内存的访存操作需要读取n个地址,而这n个地址恰好分布在n个不同的存储体(bank)中,那么只需要一个存取周期就可以完成n个地址的访存任务了。对于计算能力1.x的设备,共享内存被平均划分为16个存储体。而对于计算能力2.x、3.0及3.5的设备此参数为32。在共享内存中,相邻两块32bit的数据分别属于相邻的两个存储体。存储体每两个时钟周期可以传输32位数据。
4、共享内存既可以静态分配,也可以动态分配。
从共享内存的这些特点中我们可以看出,它实际上相当于一个程序员可以操控的缓存(cache),下面,我们使用矩阵乘法的例子来说明如何有效使用共享内存。
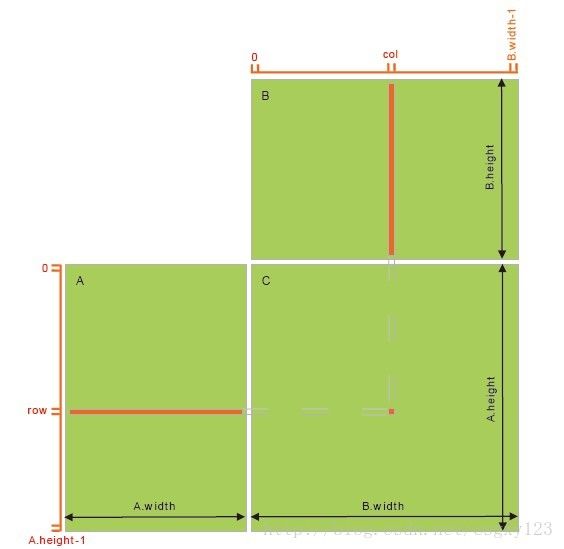
首先,我们使用最直观的方法来完成矩阵乘法C = A x B:读取A的每一行和B的每一列,顺次完成计算任务。矩阵乘法的示意图如下所示:
下面是矩阵乘法的CUDA C主要实现代码:
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.width + col)
typedefstruct{
intwidth;
intheight;
float*elements;
} Matrix;
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ voidMatMulKernel(constMatrix,constMatrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
voidMatMul(constMatrix A,constMatrix B, Matrix C) {
// Load A and B to device memory
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_tsize = A.width * A.height *sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_c.elements, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ voidMatMulKernel(Matrix A, Matrix B, Matrix C) {
// Each thread computes one element of C
// by accumulating results into Cvalue
floatCvalue = 0;
introw = blockIdx.y * blockDim.y + threadIdx.y;
intcol = blockIdx.x * blockDim.x + threadIdx.xl
for(inte = 0; e
Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
}
可以看出,为了计算矩阵C的任何一个元素,程序都需要从全局内存(global memory)中获得矩阵A的一行和矩阵B的一列。因此,完成这一计算矩阵A被读取了B.width次,矩阵B被读取了A.height次。
现在我们来使用共享内存(shared memory)实现矩阵乘法。假设矩阵C可以被划分为若干个较小的子方阵Csub,我们使用一个线程块(thread block)来负责某一子方阵的计算,线程块中的每一个线程(thread)正好负责子方阵Csub中一个元素的计算。这样划分后,任何一个结果子方阵Csub'(尺寸为block_size * block_size)都是与该方阵具有相同行索引的尺寸为A.width * block_size的A的子矩阵Asub和与该方阵具有相同列索引的尺寸为block_size * B.height的B的子矩阵Bsub相乘所得到。
为了匹配设备的计算资源,两个子矩阵Asub和Bsub被划分为尽可能多的分离的维度为block_size的子方阵,Csub的值便是这些子矩阵相乘后相加所得到的结果。子矩阵乘法的执行顺序都是首先将它们从全局内存(global memory)拷贝到共享内存(shared memory)(线程块中的每一个线程正好负责方阵一个元素的拷贝),然后由线程自己完成相应元素的计算任务,利用寄存器存储局部结果,最后将寄存器的内容与新得到的计算结果依此累加起来得到最终运算结果并将其传输到全局内存(global memory)中。
通过使用这种分治的计算策略,共享内存得到了很好的利用,采用这种方案计算完成时全局内存中矩阵A被访问的次数为B.width / block_size,矩阵B被访问的次数为A.height / block_size,很明显,这为我们节省了非常多的全局内存带宽。优化后的矩阵计算示意图如下所示:

为了提升计算效率,我们为类型Matrix增加了一个成员变量stride。__device__函数用来获得和设置子矩阵的元素。下面是优化后的代码:
// Matrices are stored in row-major order;
// M(row, col) = *(M.elements + row * M.stride + col)
typedefstruct{
intwidth;
intheight;
intstride;
float* elements;
} Matrix;
// Get a matrix element
__device__ floatGetElement(constMatrix A,introw,intcol) {
returnA.elements[row * A.stride + col];
}
// Set a matrix element
__device__ voidSetElement(Matrix A,introw,intcol,floatvalue) {
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, introw,intcol) {
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col];
returnAsub;
}
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ voidMatMulKernel(constMatrix,constMatrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
voidMatMul(constMatrix A,constMatrix B, Matrix C) {
// Load A and B to device memory
Matrix d_A;
d_A.width = d_A.stride = A.width;
d_A.height = A.height;
size_tsize = A.width * A.height *sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width;
d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = d_C.stride = C.width;
d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ voidMatMulKernel(Matrix A, Matrix B, Matrix C) {
// Block row and column
intblockRow = blockIdx.y;
intblockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub
// by accumulating results into Cvalue
floatCvalue = 0;
// Thread row and column within Csub
introw = threadIdx.y;
intcol = threadIdx.x;
// Look over all the sub-matrices of A and B that are required to compute Csub
// Multiply each pair of sub-matrices together and accumulate the results
for(intm = 0; m
// Get sub-matrix Asub of A
Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B
Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively
__shared__ floatAs[BLOCK_SIZE][BLOCK_SIZE];
__shared__ floatBs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory
// Each thread loads one element of each sub-matrix
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded
// before starting the computation
__syncthreads();
// Multiply Asub and Bsub together
for(inte = 0; e
Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding computation is done before
// loading two new sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write Csub to device memory
// Each thread writes one element
SetElement(Csub, row, col, Cvalue);
}
异步并行执行
主机和设备间并行执行
为了支持主机和设备的并行执行,CUDA提供了一些异步函数。异步是指设备在完成功能执行之前就将控制权交还给主机线程,以便主机线程继续执行。这些函数有:
1、内涵启动(Kernel Launches);
2、同一设备内存中两个地址块之间的数据传输;
3、从主机到设备的小于或等于64KB的一次数据块传输;
4、使用Async前缀函数进行的数据传输;
5、内存置位函数调用(Memory set functions calls)。
程序员可以通过设置环境变量CUDA_LAUNCH_BLOCKING来开启或者关闭内核启动(Kernel Launch)的异步功能。但是这一方法仅限于调试,在任何产品代码中不应当关闭异步内核启动。
内核启动在下面这些情况下则是同步的:
1、应用程序通过调试器或者内存检查器运行在计算能力为1.x的设备上。
2、硬件计数器信息正被性能分析器收集。
将内核启动与数据传输重叠起来
对于一些计算能力等于或高于1.1的设备,它们可以将内核启动任务和锁页内存到设备内存的数据传输任务并行执行。应用程序可以检查设备属性中的asyncEngineCount项来确定设备是否支持这一功能。当该项值大于0时代表设备支持这一层次的并行。对于计算能力1.x的设备,该功能不支持通过cudaMallocPitch()函数分配的CUDA数组或2D数组。
并行内核执行
一些计算能力2.x或更高的设备可以同时并行执行多个内核函数。应用程序可以检查设备属性中的concurrentKernels项来确定设备是否支持这一功能,值为1代表支持。运算能力3.5的设备在同一时刻能够并行执行的最大内核函数数量为32,运算能力小于3.5的硬件则最多支持同时启动16个内核函数的执行。同时需要注意的是,在一个CUDA上下文中的内核函数不能与另一个CUDA上下文中的内核函数同时执行。使用很多纹理内存或者大量本地内存的内核函数也很可能无法与其它内核函数并行执行。
并行数据传输
一些计算能力为2.x或更高的设备可以将锁页内存到设备内存的数据传输和设备内存到锁页内存的数据传输并行执行。应用程序可检查设备属性中的asyncEngineCount项来确定这一功能的支持程度,等于2时表示支持。
流(Streams)
应用程序通过流来管理并行。一个流是一个顺次执行的命令序列。不同的流之间并行执行,没有固定的执行顺序。
1、流的创建与销毁
定义一个流的过程通常包括:创建一个流对象,然后指定它为内核启动或者主机设备间数据传输的流参数。下面的一段代码创建了两个流并且在锁页内存中分配了一块float类型的数组hostPtr:
cudaStream_t stream[2];
for(inti = 0; i
cudaStreamCreate(&stream[i]);
float*hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
下面的代码定义了每一个流的行为:从主机端拷贝数据到设备端,内核启动,从设备端拷贝数据到主机端:
for(inti = 0; i
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
}
这部分代码中有一点需要注意:为了并行化数据拷贝和内核执行,主机端内存必须分配为锁页(page-locked)内存。
要销毁一个流需要调用函数cudaStreamDestroy()
for(inti = 0; i
cudaStreamDestroy(stream[i]);
cudaStreamDestroy()函数等待之前流中的指令序列运行完成,然后销毁指定流,将控制权返还给主机端。
2、默认流(Default stream)
在内核启动或者数据拷贝过程中如果不指定流,或者设置流参数为0,则相应的指令将会运行在默认流上,它们也因此而顺次执行。
3、明同步(Explicit Synchronization)
在CUDA中有很多种方式可以用来同步流的执行:
cudaDeviceSynchronize()函数使得主机端线程阻塞直到所有流中的指令执行完成。
cudaStreamSynchronize()函数将一个流对象作为输入参数,用以等待指定流中的所有指令执行完成。
cudaStreamWaitEvent()函数将一个流对象和一个事件作为输入参数,它将延迟该函数调用后在指定流中所有新加入的命令的执行直到指定的事件完成为止。流参数可以为0,在该情形下所有流中的任何新加入的指令都必须等待指定事件的发生,然后才可以执行。
cudaStreamQuery()函数为应用程序提供了一个检测指定流中之前指令是否执行完成的方法。
为了避免同步带来的性能下降,所有上述同步函数最好用于计时目的或者分离错误的内核执行或数据拷贝。
4、暗同步(Implicit Synchronization)
如果任何一个流中正在执行以下操作,那么其它流是不能与其并行运行的:
a. 分配锁页内存空间
b. 设备内存分配
c. 设备内存置位
d. 同一设备两个不同地址间正在进行数据拷贝
e. 默认流中有指令正在执行
f. L1/shared内存配置的转换
对于支持并行内核执行并且计算能力3.0或以下的设备来说,任何一个需要检查依赖性以确定流内核启动是否完成的操作:
a. 只有当前CUDA上下文中所有流中所有之前的内核启动之后才能够启动执行。
b. 将会阻塞所有当前CUDA上下文中的任意流中新加入的内核调用直到内核检查完成。
需要进行依赖性检查的操作包括执行检查的内核启动所在流中的其它指令以及任何在该流上对cudaStreamQuery()函数的调用。因此,应用程序可以遵照以下指导原则来提升潜在并行性:
(1)所有非依赖操作应当比依赖性操作提前进行
(2)任何类型的同步越迟越好
5、重叠行为(Overlapping Behavior)
两个流间重叠行为的数量取决于以下几个因素:
(1)每个流中命令发出的次序
(2)设备是否支持内核启动与数据传输并行
(3)设备是否支持多内核并行启动
(4)设备是否支持多数据传输并行
例如,在不支持并行数据传输的设备上,“流的创建与销毁”章节中代码样例中的操作就不能并行,因为在stream[0]中发出设备端到主机端的数据拷贝后,stream[1]又发出主机端到设备端的数据拷贝命令,这两个命令式不能重叠执行的。假设设备支持数据传输与内核启动并行,那么如下代码:
for(inti = 0; i
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for(inti = 0; i
MyKernel<<<100, 512, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
for(inti = 0; i
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
可将stream[0]的内核启动和stream[1]从主机端到设备端的数据拷贝重叠起来并行执行。
6、回调函数
CUDA运行时提供了cudaStreamAddCallback()函数以在流中的任意位置插入一个回调函数点。回调函数运行于主机端,如果在默认流中插入回调函数,那么它将等待所有其它流中的命令执行完成之后才会开始执行。
下面的代码展示了回调函数技术的应用:
voidCUDART_CB MyCallback(cudaStream_t stream, cudaError_t status,void**data) {
printf("Inside callback %d\n", (int)data);
}
...
for(inti = 0; i
cudaMemcpyAsync(devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(devPtrOut[i], devPtrIn[i], size);
cudaMemcpyAsync(hostPtr[i], devPtrOut[i], size, cudaMemcpyDeviceToHost, stream[i]);
cudaStreamAddCallback(stream[i], MyCallback, (void**)i, 0);
}
上面的代码定义了两个流的操作,每个流都完成一次主机端到设备端的数据拷贝,一次内核启动,一次设备端到主机端的数据拷贝,最后增加了一个加入回调函数的操作。当设备端代码运行到回调函数点的时候,设备将控制权交还给主机端,主机端运行完成以后再将控制权返还给设备端,然后设备端继续运行。
值得注意的是,在一个回调函数中,一定不能进行任何CUDA API的调用,直接的或者间接的都是不可以的。
http://blog.csdn.net/csgxy123/article/details/9704461