mysql多行合并成一行_Python_一行多行合并拆分
是这样的,这个需求应该还是会常有的,特别是当你收集到的数据不规范的时候。有些人自认为自己很聪明,给的数据很漂亮,看上去一目了然,它不知道这些数据还要用来分析出来的,当要用的时候,很难受,正如下面这样的数据,一个人对应几个省,个数还不一样。看上去是不是既优雅又美观,但是你要怎么操作呢,我要每个省的数据,每个省然后对应哪些人。这个时候你不会操作怎么办?是不是很难受,下面有几个思路可以借鉴一下,用Python完成的,其实Excel也能,但用Excel来处理就偏题了。
再仔细看一下,这个字体是不是很有趣呢,不那么严肃,透露着活泼的气氛,这是上周在毕老师苹果电脑上发现的,于是问了一下字体的名字,没想到windows也是有的,只是要网上折腾一下,下面那个链接是我自己的存储空间,很安全,复制到浏览器或者下载器就可以下载了。

https://linss.oss-cn-beijing.aliyuncs.com/%E7%B4%A0%E6%9D%90/fonts/%E9%9B%85%E7%97%9E-%E7%AE%80.ttf【进入正题】
先读取数据
import pandas as pdimport osos.chdir(r"E:\Python\小工具")data = pd.read_excel("一行拆分合并.xlsx")【方案一】
这个就有点绕了,但是学习嘛,不影响,这个过程可以学到新的东西,其他地方是用的上的。也可以顺便复习一下pandas的一些操作,学而时习之嘛。我就拆分一下哦。
# 将一列分成多列。这里有点偷懒了,一个人最多4各省嘛,我就写了abcd,这是不严谨的,不过危急时刻时间最重要,先解决问题再说。
data[["a","b","c","d"]] = data["province"].str.split("、",expand=True)
#选取想要的列
data_final = data[["id",'name',"a","b","c","d"]]
#将行转列
前面两步还是很轻松愉悦的,这一步是重点,涉及一个新的,也不算,之前pandas系列里面说过,(这是传送门)。不过刚回头看了一下,说的略微简单,怕你理解不到,所以这一篇后面又专门深入的介绍了一下,在后面,往后面看,如果这都还看不懂,那就很遗憾了。
data_final = data_final.melt(id_vars=["id","name"],value_name="类型")
是不是快到想要的效果了,后面在把不要的列,空值处理一下就行了,很简单了,看看就能懂的。
#排序data_final = data_final[['id','name','类型']]data_final.sort_values(by="id",inplace=True)# 删除“类型==None”的行data_final = data_final[-data_final['类型'].isnull()]
结果很完美,是我想要的。
【方案二】
感觉更全面一点,也更简单一点,是这样↓
先分个列,形成一个新的列表
data["pro"] = data["province"].str.split("、")
然后呢,这一步很神奇,explode,就会把列表里面每个元素给分开,前面的其他字段还会跟着填充,很神奇。
data1 = data.explode("pro")
最后筛选一下列就行了,这个很简单,就不操作了。
【回到起点】
那么怎么回到过去呢,想回到最初的起点,这个其实也是很常用的,有的人就喜欢这样,你能怎么办,不给操作就找领导来跟你说,最后还是得操作,还折腾。
其实就是groupby一下,自定义一个规则就行了。
def func(df): return '、'.join(df.values)data_2 = data1.groupby(by=['id','name']).agg(func).reset_index()
这就回来了↑
---正文end---
上面几个字应该能看明白什么意思,说明还有附录部分,如果你仔细看了上面的内容,应该就知道附录部分是什么了。
【 参数↓】
pandas.melt(frame, 要处理的数据集。 id_vars=None, 不需要被转换的列名。 value_vars=None, 需要转换的列名,如果剩下的列全部都要转换,就不用写了 var_name=None, 自定义设置对应的列名 value_name='value', 自定义设置对应的列名 col_level=None) 如果列是MultiIndex,则使用此级别先准备一组简单明了的案例数据↓
d = {'ID': ['A001','A002','A003','A004'], '四川': [1,2,3,4], '德阳':['d1','d2','d2','d4'], '成都':['cd1','cd2','cd2','cd4']}df = pd.DataFrame(data=d)
这个的意思就是按照ID列,把其他所有列都放下来,文字不好描述。我给画了个图,看得明白。

pd.melt(df, id_vars=['ID'], var_name='区域', value_name='参数值')
能看明白吧?这个图画的还是很好地。
再看下面这个图,固定ID和四川两列,把剩下两列放下来。

pd.melt(df, id_vars=['ID','四川'], var_name='区域', value_name='参数值')最后就是通过value_vars,设置只需要放下来的列,其他就自动删除了。就不想画图了,应该可以领悟到了。
pd.melt(df, id_vars=['ID'], value_vars=['德阳'], var_name='区域', value_name='参数值')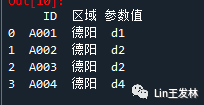

End
