文章目录
- 一、广义线性模型(Generalized liner model)的基本定义
- 二、对数几率模型与逻辑回归
-
- 1. 对数几率模型(logit model)
- 2. 逻辑回归与 Sigmoid 函数
- 3. Sigmoid 函数性质
- 三、逻辑回归模型输出结果与模型可解释性
- 四、多分类学习与多分类逻辑回归
-
- 1. OvO 策略
- 2. OvR 策略
- 3. MvM 策略
- 首先,我们来讨论关于逻辑回归的基本原理。
- 逻辑回归的基本原理,从整体上来划分可以分为两个部分,其一是关于模型方程的构建,也就是方程的基本形态,当然也包括模型的基本性质及其结果解读;其二则是模型参数求解,即在构建完模型之后如何利用数学工具求解最佳参数。基本划分情况如下:
- 模型构建部分:可以从广义线性回归(Generalized liner model)+ 对数几率函数(logit function)角度理解,也可以从随机变量的逻辑斯蒂分布(logistic distribution)角度出发进行理解。
- 参数求解部分:可以借助极大似然估计(Maximum Likelihood Estimate)方法求解,可以借助 KL 离散度基本理论构建二分类交叉熵损失函数求解。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from ML_basic_function import *
一、广义线性模型(Generalized liner model)的基本定义
- 在前文中我们了解到关于线性回归的局限性,这种局限性的根本由模型本身的简单线性结构(自变量加权求和预测因变量)导致的。
- 如果说线性回归是在一个相对严格的条件下建立的简单模型,那么在后续实践应用过程中,人们根据实际情况的不同,在线性回归的基础上又衍生出了种类繁多的线性类模型。
- 其中,有一类线性模型,是在线性回归基础上,在等号的左边或右边加上了一个函数,从而能够让模型更好的捕捉一般规律,此时该模型就被称为广义线性模型,该函数就被称为联系函数。
- 广义线性模型的提出初衷上还是为了解决非线性相关的预测问题,例如,现在有数据分布如下:
np.random.seed(24)
x = np.linspace(0, 4, 20).reshape(-1, 1)
x = np.concatenate((x, np.ones_like(x)), axis=1)
x
y = np.exp(x[:, 0] + 1).reshape(-1, 1)
y
- 此时 x 和 y 的真实关系为 y = e ( x + 1 ) y=e^{(x+1)} y=e(x+1)
- 但如果以线性方程来进行预测,即: y = w T ⋅ x + b y= w^T \cdot x + b y=wT⋅x+b
- 当然,我们可以令 w ^ = [ w 1 , w 2 , . . . w d , b ] T \hat w = [w_1,w_2,...w_d, b]^T w^=[w1,w2,...wd,b]T, x ^ = [ x 1 , x 2 , . . . x d , 1 ] T \hat x = [x_1,x_2,...x_d, 1]^T x^=[x1,x2,...xd,1]T,从而将上述方程改写为: y = w ^ T ⋅ x ^ y= \hat w^T \cdot \hat x y=w^T⋅x^
- 则模型输出结果为:
np.linalg.lstsq(x, y, rcond=-1)[0]
- 即 y = 30.44 x − 22.38 y=30.44x-22.38 y=30.44x−22.38
- 则模型预测结果为:
yhat = x[:, 0] * 30.44 - 22.38
yhat
plt.plot(x[:, 0], y, 'o')
plt.plot(x[:, 0], yhat, 'r-')

- 能够发现,线性模型预测结果和真实结果差距较大。
- 但此时如果我们在等号右边加上以 e e e 为底的指数运算,也就是将线性方程输出结果进行以 e e e 为底的指数运算转换之后去预测 y,即将方程改写为 y = e ( w ^ T ⋅ x ^ ) y=e^{(\hat w^T \cdot \hat x)} y=e(w^T⋅x^)
- 等价于 l n y = w ^ T ⋅ x ^ lny = \hat w^T \cdot \hat x lny=w^T⋅x^
- 即相当于是线性方程输出结果去预测 y y y 取以 e e e 为底的对数运算之后的结果。此时我们可以带入 l n y lny lny 进行建模。
np.linalg.lstsq(x, np.log(y), rcond=-1)[0]
- 可得到方程 l n y = x + 1 lny=x+1 lny=x+1
- 等价于 y = e ( x + 1 ) y=e^{(x+1)} y=e(x+1)
- 即解出原方程。
- 通过上面的过程,我们不难发现,通过在模型左右两端加上某些函数,能够让线性模型也具备捕捉非线性规律的能力。而在上例中,这种捕捉非线性规律的本质,是在方程加入 ln 对数函数之后,能够使得模型的输入空间(特征所在空间)到输出空间(标签所在空间)进行了非线性的函数映射。
- 而这种连接线性方程左右两端、并且实际上能够拓展模型性能的函数,就被称为联系函数,而加入了联系函数的模型也被称为广义线性模型。广义线性模型的一般形式可表示如下: g ( y ) = w ^ T ⋅ x ^ g(y)=\hat w^T \cdot \hat x g(y)=w^T⋅x^
- 等价于 y = g − 1 ( w ^ T ⋅ x ^ ) y = g^{-1}(\hat w^T \cdot \hat x) y=g−1(w^T⋅x^)
- 其中 g ( ⋅ ) g(·) g(⋅) 为联系函数(link function), g − 1 ( ⋅ ) g^{-1}(·) g−1(⋅) 为联系函数的反函数。而如上例中的情况,也就是当联系函数为自然底数的对数函数时,该模型也被称为对数线性模型(logit linear model)。
- 这里需要注意,一般来说广义线性模型要求联系函数必须是单调可微函数。
- 从广义线性模型的角度出发,当联系函数为 g ( x ) = x g(x)=x g(x)=x 时, g ( y ) = y = w ^ T ⋅ x ^ g(y)=y=\hat w^T \cdot \hat x g(y)=y=w^T⋅x^,此时就退化成了线性模型。而能够通过联系函数拓展模型捕捉规律的范围,这也就是广义的由来。
二、对数几率模型与逻辑回归
- 逻辑回归也被称为对数几率回归。接下来,我们从广义线性模型角度理解逻辑回归。
1. 对数几率模型(logit model)
- 几率(odd)与对数几率
- 几率不是概率,而是一个事件发生与不发生的概率的比值。
- 假设某事件发生的概率为 p,则该事件不发生的概率为 1-p,该事件的几率为: o d d ( p ) = p 1 − p odd(p)=\frac{p}{1-p} odd(p)=1−pp
- 在几率的基础上取(自然底数的)对数,则构成该事件的对数几率(logit): l o g i t ( p ) = l n p 1 − p logit(p) = ln\frac{p}{1-p} logit(p)=ln1−pp
- 这里需要注意的是,logit 的是 log unit 对数单元的简写,和中文中的逻辑一词并没有关系。对数几率模型也被称为对数单位模型(log unit model)。
- 对数几率模型
- 如果我们将对数几率看成是一个函数,并将其作为联系函数,即 g ( y ) = l n y 1 − y g(y)=ln\frac{y}{1-y} g(y)=ln1−yy,则该广义线性模型为: g ( y ) = l n y 1 − y = w ^ T ⋅ x ^ g(y)=ln\frac{y}{1-y}=\hat w^T \cdot \hat x g(y)=ln1−yy=w^T⋅x^
- 此时模型就被称为对数几率回归(logistic regression),也被称为逻辑回归。
2. 逻辑回归与 Sigmoid 函数
- 对数几率函数与 Sigmoid 函数
- 如果我们希望将上述对数几率函数反解出来,也就是改写为 y = f ( x ) y=f(x) y=f(x) 形式,则可参照下述形式:
- 方程左右两端取自然底数: y 1 − y = e w ^ T ⋅ x ^ \frac{y}{1-y}=e^{\hat w^T \cdot \hat x} 1−yy=ew^T⋅x^
- 方程左右两端 +1 可得: y + ( 1 − y ) 1 − y = 1 1 − y = e w ^ T ⋅ x ^ + 1 \frac{y+(1-y)}{1-y}=\frac{1}{1-y}=e^{\hat w^T \cdot \hat x}+1 1−yy+(1−y)=1−y1=ew^T⋅x^+1
- 方程左右两端取倒数可得: 1 − y = 1 e w ^ T ⋅ x ^ + 1 1-y=\frac{1}{e^{\hat w^T \cdot \hat x}+1} 1−y=ew^T⋅x^+11
- 1- 方程左右两端可得: y = 1 − 1 e w ^ T ⋅ x ^ + 1 = e w ^ T ⋅ x ^ e w ^ T ⋅ x ^ + 1 = 1 1 + e − ( w ^ T ⋅ x ^ ) = g − 1 ( w ^ T ⋅ x ^ ) \begin{aligned} y &= 1-\frac{1}{e^{\hat w^T \cdot \hat x}+1}\\ &=\frac{e^{\hat w^T \cdot \hat x}}{e^{\hat w^T \cdot \hat x}+1} \\ &=\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} = g^{-1}(\hat w^T \cdot \hat x) \end{aligned} y=1−ew^T⋅x^+11=ew^T⋅x^+1ew^T⋅x^=1+e−(w^T⋅x^)1=g−1(w^T⋅x^)
- 因此,逻辑回归基本模型方程为: y = 1 1 + e − ( w ^ T ⋅ x ^ ) y = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} y=1+e−(w^T⋅x^)1
- 同时我们也能发现,对数几率函数的反函数为: f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1
- 我们可以简单观察该函数的函数图像:
np.random.seed(24)
x = np.linspace(-10, 10, 100)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y)
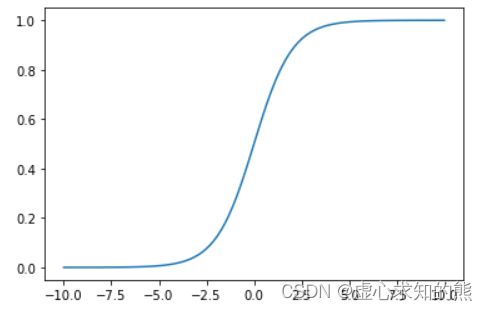
- 能够看出该函数的图像近似 S 形,这种类似 S 形的函数,也被称为 Sigmoid 函数。
- 注:Sigmoid 严格定义是指形如 S 型的函数,并不是特指某个函数。
- 也就是说,从严格意义来讨论,函数 f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1 只能被称为是 Sigmoid 函数的一种。但实际上,由于该函数是最著名且通用的 Sigmoid 函数,因此大多数时候,我们在说Sigmoid函数的时候,其实就是在指 f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1 函数。
3. Sigmoid 函数性质
- Sigmoid 函数性质与一阶导函数
- 对于 Sigmoid 函数来说,函数是单调递增函数,并且自变量在实数域上取值时,因变量取值范围在 (0,1) 之间。并且当自变量取值小于 0 时,因变量取值小于 0.5,当自变量取值大于 0时,因变量取值大于 0.5。
- 并且,我们简单查看 Sigmoid 导函数性质。
- 令: S i g m o i d ( x ) = 1 1 + e − x Sigmoid(x) = \frac{1}{1+e^{-x}} Sigmoid(x)=1+e−x1
- 对其求导可得: S i g m o i d ′ ( x ) = ( 1 1 + e − x ) ′ = ( ( 1 + e − x ) − 1 ) ′ = ( − 1 ) ( 1 + e − x ) − 2 ⋅ ( e − x ) ′ = ( 1 + e − x ) − 2 ( e − x ) = e − x ( 1 + e − x ) 2 = e − x + 1 − 1 ( 1 + e − x ) 2 = 1 1 + e − x − 1 ( 1 + e − x ) 2 = 1 1 + e − x ( 1 − 1 1 + e − x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) \begin{aligned} Sigmoid'(x) &= (\frac{1}{1+e^{-x}})' \\ &=((1+e^{-x})^{-1})' \\ &=(-1)(1+e^{-x})^{-2} \cdot (e^{-x})' \\ &=(1+e^{-x})^{-2}(e^{-x}) \\ &=\frac{e^{-x}}{(1+e^{-x})^{2}} \\ &=\frac{e^{-x}+1-1}{(1+e^{-x})^{2}} \\ &=\frac{1}{1+e^{-x}} - \frac{1}{(1+e^{-x})^2} \\ &=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}}) \\ &=Sigmoid(x)(1-Sigmoid(x)) \end{aligned} Sigmoid′(x)=(1+e−x1)′=((1+e−x)−1)′=(−1)(1+e−x)−2⋅(e−x)′=(1+e−x)−2(e−x)=(1+e−x)2e−x=(1+e−x)2e−x+1−1=1+e−x1−(1+e−x)21=1+e−x1(1−1+e−x1)=Sigmoid(x)(1−Sigmoid(x))
- 我们发现,Sigmoid 函数的导函数可以简单的用 Sigmoid 函数本身来表示。接下来我们验证 Sigmoid 导函数特性,首先简单定义 Sigmoid 函数:
def sigmoid(x):
return (1 / (1 + np.exp(-x)))
sigmoid(10)
def sigmoid_deri(x):
return (sigmoid(x)*(1-sigmoid(x)))
sigmoid_deri(10)
- 进一步,我们可以绘制 Sigmoid 导函数图像:
plt.plot(x, sigmoid_deri(x))
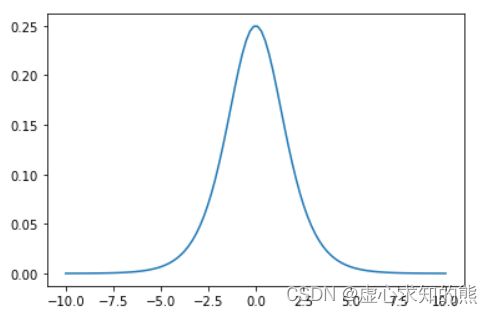
- 我们发现,Sigmoid 导函数在实数域上取值大于 0,并且函数图像先递增后递减,并在 0 点取得最大值。据此我们也可以进一步讨论 Sigmoid 函数性质:
plt.plot(x, sigmoid(x))
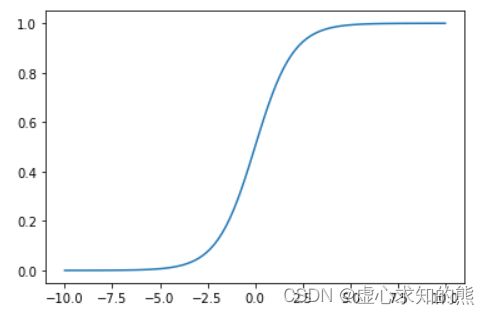
- 由于导函数始终大于 0,因此 Sigmoid 函数始终递增,并且导函数在 0 点取得最大值,因此 Sigmoid 在 0 点变化率最快,而在远离零点的点,Sigmoid 导函数取值较小,因此该区间 Sigmoid 函数变化缓慢。该区间也被称为 Sigmoid 的饱和区间。
- 总结 Sigmoid 函数性质如下:
| 性质 |
说明 |
| 单调性 |
单调递增 |
| 变化率 |
0点变化率最大,越远离0点变化率越小 |
| 取值范围 |
(0,1) |
| 凹凸性 |
0点为函数拐点,0点之前函数为凸函数,此后函数为凹函数 |
三、逻辑回归模型输出结果与模型可解释性
- 从整体情况来看,逻辑回归在经过 Sigmoid 函数处理之后,是将线性方程输出结果压缩在了 0-1 之间,用该结果再来进行回归类的连续数值预测肯定是不合适的了。在实际模型应用过程中,逻辑回归主要应用于二分类问题的预测。
- 一般来说,我们会将二分类的类别用一个两个分类水平取值的离散变量来代表,两个分类水平分别为 0 和 1。该离散变量也被称为 0-1 离散变量。
- 连续型输出结果转化为分类预测结果
- 对于逻辑回归输出的 (0,1) 之间的连续型数值,我们只需要确定一个阈值,就可以将其转化为二分类的类别判别结果。通常来说,这个阈值是 0.5,即以 0.5 为界,调整模型输出结果: y c l a = { 0 , y < 0.5 1 , y ≥ 0.5 \begin{equation} y_{cla}=\left\{ \begin{aligned} 0, y<0.5 \\ 1, y≥0.5 \end{aligned} \right. \end{equation} ycla={0,y<0.51,y≥0.5
- 其中, y c l a y_{cla} ycla 为类别判别结果,而 y y y 为逻辑回归方程输出结果 s i g m o i d ( w ^ T ⋅ x ^ ) sigmoid(\hat w^T \cdot \hat x) sigmoid(w^T⋅x^)。例如,有简单数据集如下:
| sepal_width |
species |
| 2 |
0 |
| 0.5 |
1 |
- 由于只有一个自变量,因此可假设逻辑回归模型如下: y = 1 1 + e x − 1 y = \frac{1}{1+e^{x-1}} y=1+ex−11
- 带入数据可进一步计算模型输出结果:
x = np.array([2, 0.5]).reshape(-1, 1)
sigmoid(1-x)
- 据此,在阈值为 0.5 的情况下,模型会将第一条判别为 0,第二条结果判别为 1,上述过程代码实现如下:
yhat = sigmoid(1-x)
yhat
ycla = np.zeros_like(yhat)
ycla
thr = 0.5
yhat >= thr
ycla[yhat >= thr] = 1
ycla
| sepal_width |
species |
方程输出结果 |
类别判别结果 |
| 2 |
0 |
0.27 |
0 |
| 0.5 |
1 |
0.62 |
1 |
def logit_cla(yhat, thr=0.5):
"""
逻辑回归类别输出函数:
:param yhat: 模型输出结果
:param thr:阈值
:return ycla:类别判别结果
"""
ycla = np.zeros_like(yhat)
ycla[yhat >= thr] = 1
return ycla
logit_cla(yhat)
- 关于阈值的选取与 0\1 分类的类别标记:阈值为人工设置的参数,在没有特殊其他要求下,一般取值为 0.5。
- 关于类别的数值转化,即将哪一类设置为 0 哪一类设置为 1,也完全可以由人工确定,一般来说,我们会将希望被判别或被识别的类设置为 1,例如违约客户、确诊病例等。
- 逻辑回归输出结果 (y) 是否是概率
- 决定 y 是否是概率的核心因素,不是模型本身,而是建模流程。
- 逻辑斯蒂本身也有对应的概率分布,因此输入的自变量其实是可以视作随机变量的,但前提是需要满足一定的分布要求。
- 如果逻辑回归的建模流程遵照数理统计方法的一般建模流程,即自变量的分布(或者转化之后的分布)满足一定要求(通过检验),则最终模型输出结果就是严格意义上的概率取值。
- 如果是遵照机器学习建模流程进行建模,在为对自变量进行假设检验下进行模型构建,则由于自变量分布不一定满足条件,因此输出结果不一定为严格意义上的概率。
- 例如在上例中:
| sepal_width |
species |
方程输出结果 |
类别判别结果 |
| 0.5 |
0 |
0.27 |
0 |
| 2 |
1 |
0.62 |
1 |
- 我们可以说,第一条样本预测为 1 的概率为 0.38,相比属于类别 1,第一条样本更大概率属于类别 0;而第二条样本属于类别 1 的概率高达 73%,因此第二条样本我们判别其属于类别 1。
- 并且,根据逻辑回归方程: y = 1 1 + e − ( 1 − x ) y = \frac{1}{1+e^{-(1-x)}} y=1+e−(1−x)1
- 可以进一步推导出: l n y 1 − y = 1 − x ln\frac{y}{1-y} = 1-x ln1−yy=1−x
- 可解读为 x 每增加 1,样本属于 1 的概率的对数几率就减少 1。
- 当然,类似的可解释性,也就是自变量变化对因变量变化的贡献程度的解读,对于线性回归同样适用。例如 y = x + 1 y=x+1 y=x+1,我们可以解读为, x x x 每增加 1, y y y 就增加 1。
- 而这种基于自变量系数的可解释性不仅可以用于自变量和因变量之间的解释,还可用于自变量重要性的判别当中,例如,假设逻辑回归方程如下: l n y 1 − y = x 1 + 2 x 2 − 1 ln\frac{y}{1-y} = x_1+2x_2-1 ln1−yy=x1+2x2−1
- 则可解读为 x 2 x_2 x2 的重要性是 x 1 x_1 x1 的两倍, x 2 x_2 x2 每增加 1 的效果(令样本为 1 的概率的增加)是 x 1 x_1 x1 增加 1 效果的两倍。
- 本节结束后,我们需要将此前定义的两个函数,也就是 Sigmoid 函数、Sigmoid 导函数即逻辑回归类别判别函数写入 ML_basic_function.py 中。
- 逻辑回归的概率表示形式
- 如果我们将逻辑回归模型输出结果视作样本属于1类的概率,则可将逻辑回归模型改写成如下形式: p ( y = 1 ∣ x ^ ; w ^ ) = 1 1 + e − ( w ^ T ⋅ x ^ ) p(y=1|\hat x;\hat w) =\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} p(y=1∣x^;w^)=1+e−(w^T⋅x^)1 p ( y = 0 ∣ x ^ ; w ^ ) = e − ( w ^ T ⋅ x ^ ) 1 + e − ( w ^ T ⋅ x ^ ) p(y=0|\hat x;\hat w) =\frac{e^{-(\hat w^T \cdot \hat x)}}{1+e^{-(\hat w^T \cdot \hat x)}} p(y=0∣x^;w^)=1+e−(w^T⋅x^)e−(w^T⋅x^)
四、多分类学习与多分类逻辑回归
- 此前的讨论都是基于二分类问题(0-1分类问题)展开的讨论,而如果要使用逻辑回归解决多分类,则需要额外掌握一些技术手段。
- 总的来说,如果要使用逻辑回归解决多分类问题,一般来说有两种方法,其一是将逻辑回归模型改为多分类模型形式,其二则是采用通用的多分类学习方法对建模流程进行改造。
- 其中将逻辑回归模型改写成多分类模型形式并不常用并且求解过程非常复杂,包括 Scikit-Learn 在内,主流的实现多分类逻辑回归的方法都是采用多分类学习方法。
- 所谓多分类学习方法,则指的是将一些二分类学习器(binary classifier)推广到多分类的场景中,该方法属于包括逻辑回归在内所有二分类器都能使用的通用方法。
- 多分类问题描述
- 当离散型标签拥有两个以上分类水平时,即对多个(两个以上)分类进行类别预测的问题,被称为多分类问题。例如有如下四分类问题简单数据集:

- 其中 index 是每条数据编号,labels 是每条数据的标签。
- 多分类问题解决思路
- 一般来说,用二分类学习器解决多分类问题,基本思想是先拆分后集成,也就是先将数据集进行拆分,然后多个数据集可训练多个模型,然后再对多个模型进行集成。这里所谓集成,指的是使用这多个模型对后续新进来数据的预测方法。
- 具体来看,依据该思路一般有三种实现策略,分别是一对一(One vs Ons,简称 OvO)、一对剩余(One vs Rest,简称 OvR)和多对多(Many vs Many,加成 MvM)。
1. OvO 策略
- 拆分策略
- OvO 的拆分策略比较简单,基本过程是将每个类别对应数据集单独拆分成一个子数据集,然后令其两两组合,再来进行模型训练。
- 例如,对于上述四分类数据集,根据标签类别可将其拆分成四个数据集,然后再进行两两组合,总共有 6 种组合,也就是 C 4 2 C^2_4 C42 种组合。
- 拆分过程如下所示:

- 集成策略
- 当模型训练完成之后,接下来面对新数据集的预测,可以使用投票法从 6 个分类器的判别结果中挑选最终判别结果。

- 根据少数服从多数的投票法能够得出,某条新数据最终应该属于类别 1。
2. OvR 策略
- 拆分策略
- 和 OvO 的两两组合不同,OvR 策略则是每次将一类的样例作为正例、其他所有数据作为反例来进行数据集拆分。
- 对于上述四分类数据集,OvR 策略最终会将其拆分为 4 个数据集,基本拆分过程如下:
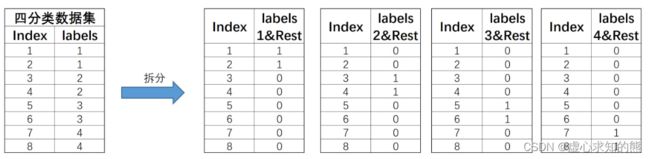
- 此 4 个数据集就将训练 4 个分类器。
- 注意,在 OvR 的划分策略中,是将 rest 无差别全都划分为负类。当然,如果数据集总共有 N 个类别,则在进行数据集划分时总共将拆分成 N 个数据集。
- 集成策略
- 当成,集成策略和划分策略息息相关,对于 OvR 方法来说,对于新数据的预测,如果仅有一个分类器将其预测为正例,则新数据集属于该类。
- 若有多个分类器将其预测为正例,则根据分类器本身准确率来进行判断,选取准确率更高的那个分类器的判别结果作为新数据的预测结果。

- OvO 和 OvR的比较
- 对于这两种策略来说,尽管 OvO 需要训练更多的基础分类器,但由于 OvO 中的每个切分出来的数据集都更小,因此基础分类器训练时间也将更短。
- 因此,综合来看在训练时间开销上,OvO 往往要小于 OvR。而在性能方面,大多数情况下二者性能类似。
3. MvM 策略
- 相比于 OvO 和 OvR,MvM 是一种更加复杂的策略。
- MvM 要求同时将若干类化为正类、其他类化为负类,并且要求多次划分,再进行集成。一般来说,通常会采用一种名为纠错输出码(Error Correcting Output Codes,简称 ECOC)的技术来实现 MvM 过程。
- 拆分策略
- 此时对于上述 4 分类数据集,拆分过程就会变得更加复杂,我们可以任选其中一类作为正类、其余作为负类,也可以任选其中两类作为正类、其余作为负数,以此类推。由此则诞生出了非常多种子数据集,对应也将训练非常多个基础分类器。
- 当然,将某一类视作正类和将其余三类视作正类的预测结果相同,对调下预测结果即可,此处不用重复划分。
- 例如,对于上述 4 分类数据集,则可有如下划分方式:
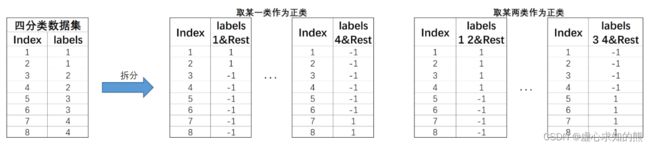
- 根据上述划分方式,总共将划分 C 4 1 + C 4 2 = 10 C_4^1+C_4^2=10 C41+C42=10 个数据集,对应构建,对应的我们可以构建 10 个分类器。不过一般来说对于 ECOC 来说我们不会如此详尽的对数据集进行划分,而是再上述划分结果中挑选部分数据集进行建模、
- 例如就挑选上面显式表示的 4 个数据集来进行建模,即可构建 4 个分类器。
- 由此我们也不难看出 OvR 实际上是 MvM 的一种特例。
- 集成策略
- 接下来我们进行模型集成。值得注意的是,如果是以上述方式划分四个数据集,我们可以将每次划分过程中正例或负例的标签所组成的数组视为每一条数据自己的编码。如下所示:
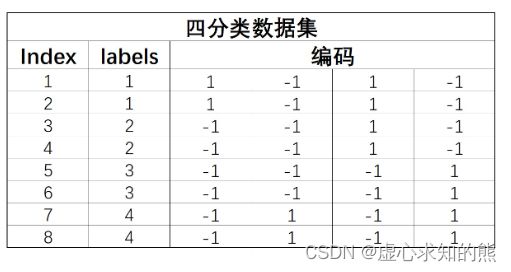
- 同时,我们使用训练好的四个基础分类器对新数据进行预测,也将产生四个结果,而这四个结果也可构成一个四位的新数据的编码。
- 接下来,我们可以计算新数据的编码和上述不同类别编码之间的距离,从而判断新生成数据应该属于哪一类。

- 不拿发现,如果预测足够准确,编码其实是和类别一一对应的。但如果基础分类器预测类别不够准确,编码和类别并不一定会一一对应,有一种三元编码方式,会将这种情况的某个具体编码改为 0 (纠错输出码),意为停用类。
- 当然,距离计算有很多种方法,此处简单进行介绍,假设 x 和 y 是两组 n 维数据如下所示: x = ( x 1 , x 2 , . . . , x n ) x=(x_1, x_2, ..., x_n) x=(x1,x2,...,xn) y = ( y 1 , y 2 , . . . , y n ) y=(y_1,y_2,...,y_n) y=(y1,y2,...,yn)
- 欧式距离计算公式如下: d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(x, y) = \sqrt{\sum_{i = 1}^{n}(x_i-y_i)^2} d(x,y)=i=1∑n(xi−yi)2
- 即对应位置元素依次相减后取其平方和再开平方。
- 街道距离计算公式如下: d ( x , y ) = ∑ i = 1 n ( ∣ x i − y i ∣ ) d(x, y) =\sum_{i = 1}^{n}(|x_i-y_i|) d(x,y)=i=1∑n(∣xi−yi∣)
- 即对应位置元素依次相减后取其绝对值的和。
- 闵可夫斯基距离计算公式如下: d ( x , y ) = ∑ i = 1 n ( ∣ x i − y i ∣ ) n n d(x, y) = \sqrt[n]{\sum_{i = 1}^{n}(|x_i-y_i|)^n} d(x,y)=ni=1∑n(∣xi−yi∣)n
- 不难发现,其实街道距离和欧式距离都是闵可夫斯基距离的特例。
- 此处以欧式距离为例计算新数据编码和各类编码之间距离。为了方便运算,此处可定义闵可夫斯基距离计算函数如下:
def dist(x, y, cat = 2):
"""
闵可夫斯基距离计算函数
"""
d1 = np.abs(x - y)
if x.ndim > 1 or y.ndim > 1:
res1 = np.power(d1, cat).sum(1)
else:
res1 = np.power(d1, cat).sum()
res = np.power(res1, 1/cat)
return res
x = np.array([1, 2])
y = np.array([2, 3])
dist(x, y)
np.sqrt(2)
code_mat = np.array([[1, -1, 1, -1],
[-1, -1, 1, -1],
[-1, -1, -1, 1],
[-1, 1, -1, 1]])
data_code = np.array([1, -1, 1, 1])
dist(code_mat, data_code)
np.abs(code_mat - data_code)
np.sqrt(np.power(np.abs(code_mat - data_code), 2).)sum(1)
- 不难发现,新样本应该属于第一类。至此,我们就完成了 MvM 的一次多分类预测的全流程。
- ECOC 方法评估
- 对于 ECOC 方法来说,编码越长预测结果越准确,不过编码越长也代表着需要耗费更多的计算资源,并且由于模型本身类别有限。
- 因此数据集划分数量有限,编码长度也会有限。不过一般来说,相比 OvR,MvM 方法效果会更好。