XAPP1167(v2.0)2013.8.27-Accelerating OpenCV Applications with Zynq-7000 All Programmable SoC翻译
July 21, 2016
作者:dengshuai_super
出处:http://blog.csdn.net/dengshuai_super/article/details/51975607
声明:转载请注明作者及出处。
整理自:
http://xilinx.eetrend.com/files-eetrend-xilinx/download/201401/6326-10718-xapp1167.pdf
Accelerating OpenCV Applications with Zynq-7000 All Programmable SoC using Vivado HLS Video Libraries
Author: Stephen Neuendorffer, Thomas Li, and Devin Wang
Summary
本应用笔记介绍OpenCV库如何被用来制定Zynq® -7000所有Programmable SoC的计算机视觉应用。 OpenCV的可在设计过程中的许多不同的点被使用,从算法原型到在系统执行。 OpenCV的代码也可以使用与Vivado®高层次综合( HLS)交付视频库迁移到综合的C ++代码。当集成到一个ZYNQ SoC设计,合成的块使能高的分辨率和帧速率的计算机视觉算法来实现。
Introduction
计算机视觉是一个领域,广义上包括许多有趣的应用程序,从检测不当制造项目,可以驱动汽车的汽车系统工业监控系统。许多计算机视觉系统的实施或使用OpenCV的,其中包含了许多常见的计算机视觉功能针对台式机处理器和GPU的优化实现库原型。虽然在OpenCV库许多功能已被高度优化,以使许多计算机视觉应用至接近运行以实时的,优化的嵌入式实现是常优选的。
本应用笔记介绍设计流程使OpenCV的程序重新定向到ZYNQ设备。设计流程利用了HLS技术在Vivado设计套件,具有优化的综合视频库一起。该库可以直接使用,或与特定应用程序代码来构建针对特定应用定制的加速器。这种流动可以启用许多计算机视觉算法与高性能和低功耗的快速实施。流也使设计目标的高数据率的像素处理任务到可编程逻辑,而基于帧更低的数据速率处理任务保留在ARM®内核。
如下面的图所示,OpenCV的可在多个点处的视频处理系统的设计中使用。在左边,一种算法可以被设计并实现完全使用OpenCV的函数调用,既输入和输出图像使用文件访问的功能和处理图像。接着,该算法可以在嵌入式系统(如ZYNQ基地TRD)来实现,访问使用特定平台的函数调用的输入和输出的图像。在这种情况下,视频处理仍然实现使用OpenCV函数调用的处理器(如在ZYNQ处理器系统的CortexTM-A9处理器内核)上执行。可替代地,OpenCV的函数调用可通过从Xilinx Vivado HLS视频库对应合成函数来代替。然后OpenCV的函数调用可用于访问输入和输出图像,并提供一个视频处理算法的金色参考实现。合成后,将处理块可被集成到ZYNQ可编程逻辑。根据在可编程逻辑中实现的设计,集成块可以是能够处理由处理器,创建的视频流,例如从文件,或从外部输入的现场实时视频流读出的数据。
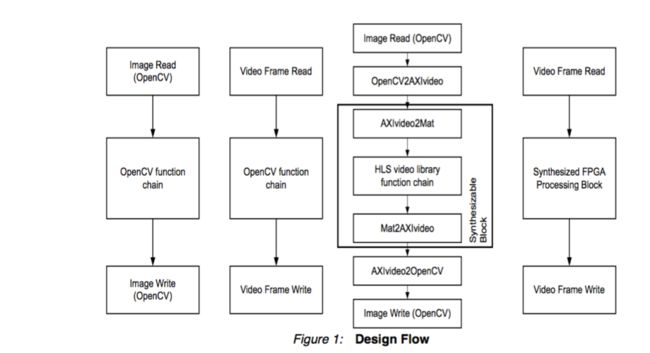
本应用笔记的设计流程一般遵循以下步骤:
1.制定并执行桌面的应用程序的OpenCV 。
2.重新编译和执行的ZYNQ SoC的OpenCV的应用,无需修改。
3.使用I / O功能封装加速器函数 重构OpenCV的应用。
4.用加速器函数的综合视频库函数调用代替OpenCV的函数的调用。
5.使用Vivado HLS生成加速器函数和相应的API 。
6.通过调用加速器API函数代替调用加速器函数
7.重新编译并执行加速应用程序
Reference Design
The reference design files can be downloaded from:
https://secure.xilinx.com/webreg/clickthrough.do?cid=323570
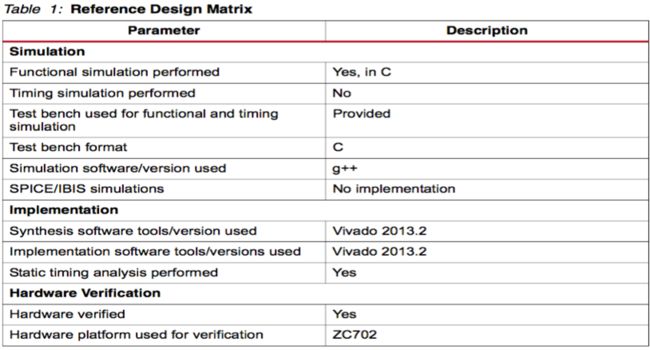
The reference design matrix is shown in Table 1.

Video Processing Libraries in Vivado HLS
Vivado HLS包含了一些视频库,目的是为了使您更容易构建各种视频处理的。这些库被实现为综合的C ++代码,并大致相当于OpenCV的实现视频处理功能和数据结构。许多的视频概念和抽象非常类似于在OpenCV的概念和抽象。特别是,许多OpenCV的imgproc模块中的功能也相应的Vivado HLS库函数。
例如,在OpenCV的最中心的元件中的一个是CV ::Mat类,它通常是用于表示在视频处理系统中的图像。cv::Mat对象通常是声明是这样的:
cv::Mat image(1080, 1920, CV_8UC3);
此声明一个可变图像和初始化它具有1080行和1920列,其中每个像素由3八位无符号数代表的代表图像。该综合库包含相应的HLS ::Mat< >模板类,它代表了一个综合的方式类似的概念:
hls::Mat<2047, 2047, HLS_8UC3> image(1080, 1920);
得到的对象是相似的,除了构造器参数使用模板参数中描述的图像的最大尺寸和格式。这确保了Vivado HLS可以确定要使用的存储器的大小处理该图像时,优化所得电路用于特定像素表示。该HLS ::Mat< >模板类还支持下探构造函数的参数完全当被处理的图像的实际大小相同的最大尺寸:
hls::Mat<1080, 1920, HLS_8UC3> image();
同样, OpenCV库提供了一种机制,以在cvScale函数线性缩放应用到每个像素的值的图像。该功能可能会被调用,如:
cv::Mat src(1080, 1920, CV_8UC3);
cv::Mat dst(1080, 1920, CV_8UC3);
cvScale(src, dst, 2.0, 0.0);
这个功能调用由为2的因子来缩放输入图像的src像素与没有偏移并产生输出图像dst 。在综合库中的相应行为是通过调用HLS ::Scale模板函数来实现:
hls::Mat<1080, 1920, HLS_8UC3> src;
hls::Mat<1080, 1920, HLS_8UC3> dst;
hls::Scale(src, dst, 2.0, 0.0);
1.请注意,虽然hls ::Scale是一个模板功能,模板参数不需要指定,因为它们都是从src和dst的声明模板参数推断。然而hls::Scale模板函数确实需要的是,输入和输出图像具有相同的模板参数。支持的功能的完整列表可在Vivado设计套件的用户指南中找到:高级综合( UG902 ) [4]。
Architectures for Video Processing
视频处理一般在Zynq soc设计遵循以下两个通用架构之一。在第一个架构,被称为“直接流”,像素数据到达可编程序逻辑的输入引脚,直接传输到视频处理组件,然后直接一个视频输出。直接流体系结构通常是最简单、最有效的方式来处理视频,但它要求视频处理组件能够实时处理帧严格。

在第二个架构中,称为“帧缓冲流”,像素数据被处理之前首先存储在外部存储器和存储在外部存储器。视频显示控制器然后输出处理所需的视频。视频帧缓冲流体系结构允许更多的解耦率和视频组件的处理速度,但它需要足够的内存读写带宽视频帧到外部存储器。

本应用笔记重点介绍帧缓冲数据流架构,因为它提供了更大的灵活性和更容易理解如何在处理器核心视频处理可以加速。对于高度优化的系统,它是相对简单的从一个帧缓冲数据流架构建立一个直接的流架构。
AXI 4 Streaming Video :
赛灵思视频处理组件通常使用通用流AXI4协议进行通信的像素数据。这个协议描述视频像素的每条线作为一个AXI4分组,与带有TLAST信号每一行的最后一个像素断言。此外,视频帧的开始是由标记用[0]比特断言用户的第一行的第一像素表示。有关此协议的更多信息,请参见[2]。
虽然底层AXI4视频流协议不需要上的图像中的行的大小的限制,当所有的视频行具有相同的长度时最复杂的视频处理计算都能被大大简化。这种限制几乎总是通过任何数字视频格式满足,也许除了在其发生在视频帧的序列的开始的瞬间。这样的瞬态处理通常只有一个处理模块,需要过渡到连续处理矩形框前,正确处理这个短暂的输入接口上的问题。接收的AXI4视频流协议的输入接口可以确保每个视频帧由恰好ROWS * COLS像素。然后在管道后块可以假设视频帧是完整的,矩形的。
Video Interface Libraries in Vivado HLS :
从这些接口问题抽象编程, Vivado HLS包括一套综合的视频接口库函数。这些功能示于下表中。

特别是, AXIvideo2Mat函数接收使用AXI4流视频图像序列,并产生一个HLS ::Mat模型。同样, Mat2AXIvideo函数接收一个HLS ::Mat的图像序列模型并正确使用AXI4视频流协议编码。
这些功能并不确定基于AXI4视频流图像的大小,而是用在HLS ::Mat构造函数的参数指定的影像尺寸。在设计用来处理与AXI4流接口的任意大小输入图像系统,必须在外部确定的视频库块图像大小。在ZYNQ视频TRD ,由加速器处理的图像尺寸被公开为AXI4-精简版控制寄存器,但是软件和系统的其余部分仅设计成处理1920×1080的分辨率。在更复杂的系统中,在Xilinx视频定时控制器核心[3]可用于检测所接收的视频信号的大小。
视频库还包含以下非合成视频接口库函数:

这些功能结合常用的合成功能,实现基于OpenCV的,测试平台。
Colorspaces :
观察到一个重要的事情是,大多数OpenCV的功能是独立的色彩空间,这意味着它们影响像素的每个组成部分平分。有,但是,除少数例外,在这里必须指定字节顺序,以及少数情况下,在使用默认的字节顺序。这个缺省字节顺序(称为BGR或BGRA),放置在低阶比特的“B”的分量与R或在32位字的高序位的组件。该AXI4视频流协议,但指定了特定的(有点不寻常)字节顺序,它不直接支持的OpenCV。这种格式放置在低阶比特的“G”的分量,随后是“B”和“R”的部件。 在ZYNQ视频TRD,设计的一部分使用AXI4视频流的字节顺序,但在存储器帧存储在更常见的BGR字节顺序。其结果是,本应用笔记的例子代码使用BGR字节顺序,这使得一贯使用的OpenCV作为设计的测试平台。
Limitations :
有若干限制到当前合成库,它可能不以其他方式明显。基本的限制是, OpenCV函数不能直接合成,并且必须由从可综合的库中的函数来代替。这种限制主要是因为OpenCV函数通常包括动态存储器分配,诸如任意大小的cv::Mat对象,这是不可合成的构造中。
第二个限制是,用于模拟图像HLS ::Mat<>数据类型被内部定义为像素的流,使用HLS ::stream<>的数据类型,而不是作为像素的外部存储器阵列。其结果,随机访问不支持的图像并且CV ::Mat<>.at()方法和cvGet2D()函数没有对应关系。流访问还意味着,如果一个图像是由一个以上的功能处理,则必须首先通过使用HLS ::Duplicate<>功能复制为两股流,如。流访问还意味着一个图像的区域不能被修改,当这个图像周围的未修改的象素没有被处理的时候。
另一个限制涉及到数据类型。 OpenCV函数通常支持整数或浮点数的数据类型。但是,浮点往往更加昂贵,针对可编程逻辑时避免。在许多情况下,Vivado HLS支持与Vivado HLS定点模板类ap_fixed <>和ap_ufixed <>替换float和double类型。目前,这不是均匀的综合库的支持,因为某些功能(如HLS :: Filter2D和HLS :: ConvertScale)要求浮点参数。另外,由于OpenCV的执行浮点运算,它不应该预期的是,可合成库的结果通常比特精确到相应的OpenCV函数,虽然意图通常为行为是功能上等同的。在某些情况下,综合库不执行内部定点优化,以减少使用浮点运算。
最后一个限制是,接口功能仅供AXI4视频流。这些接口能够在与赛灵思视频DMA(VDMA)的核心和其他视频处理IP核的系统级集成,但不能直接连接到AXI4从端口或AXI4主端口。这方面的一个含义是,在需要外部存储器帧缓冲器的设计(例如,为了处理多个连续帧一起)帧缓冲器必须从外部与由处理器管理几个VDMA内核来实现。
Reference Designs :
本应用笔记包含两个HLS设计。这些设计修改ZYNQ相应目标参考设计的行为,在使用Vivado HLS和Vivado HLS合成文库产生的过滤器更换该图像处理过滤器中的可编程逻辑。在综合滤波器的金色模型是使用OpenCV的库实现,有助于要验证的合成代码的行为。该设计还修改Linux应用程序,使无论是过滤器的OpenCV的实现或实施综合过滤器要在的Cortex -A9内核执行。此外,该应用笔记还打包带OpenCV的最小预编译的二进制库为目标ARM和x86架构主机。
第一参考设计,命名为“demo” ,包含在图4中所示的功能的简单管道。

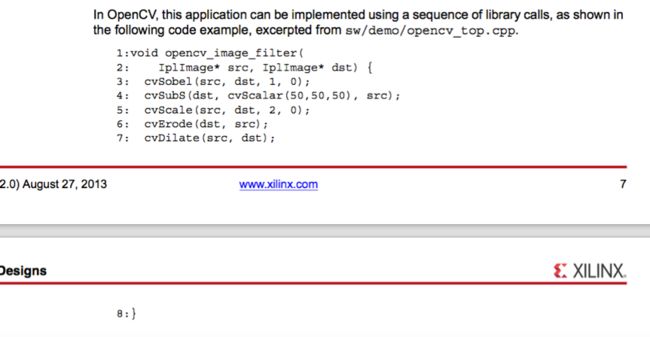
该综合代码还包含一些#pragma指令,使接口方便的。这些指令露出输入和输出流作为AXI 4流接口(线26-29)并暴露其它输入和控制总线为AXI 4精简版从属接口(线30-35 ) 。此外,该行列数输入中指明为稳定输入,因为该块被预期重复处理相同大小的图像(线36-37 ) 。本说明书使得在这些变量额外的优化,因为它们不需要通过管道的每个级别被推动。最后数据流模式被选中( 45行) ,可实现的各种处理功能并发执行,以像素被流从一个块到另一个。

53:} //(注:这是补充上面图片的最后一行代码)
第二参考设计,命名为“first-corner” ,包含了一个更复杂的管道,在图5中所示。


虽然看起来简单,这个应用程序包含没有在综合库相应的功能相当多的功能。的cvCreateImage和cvReleaseImage函数代表动态存储器分配这是不可合成(行2-3和17)。在std :: vector类是不是合成的( 6号线) 。cv:: FAST和cvRectangle功能目前不会在综合库( 行8和12-15 )来实现。
用于实施本申请的一个可能性是进行分区的,运行在可编程逻辑的绿色通道提取和FAST角点检测,而与该处理系统上运行的代码的矩形标记的角。相反,我们选择稍微简化代码,而像素处理范例可在FPGA中实现内停留。代码的简化版本显示在下面的代码示例。
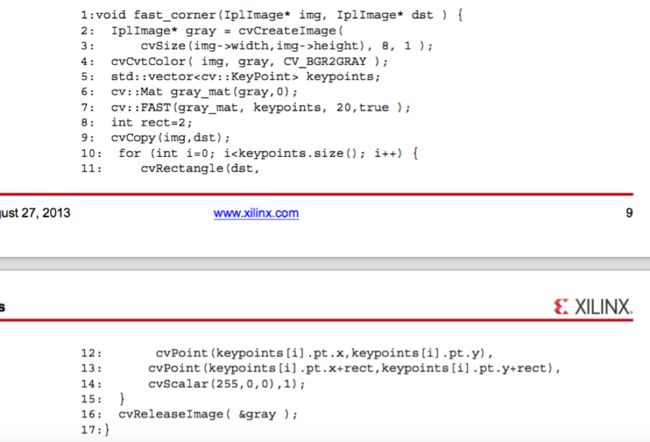
这个代码,虽然写入OpenCV的的方式,是适于转化成综合代码的结构。的显著缺少的功能是CV :: FAST功能和GenMask功能,可使用专用综合代码来实现的结合。特别是,这样的组合产生的关键点作为图像掩模,而不是作为一个动态分配的结构比。该PrintMask函数采用如口罩,借鉴了图像的顶部。
快速弯道应用程序的综合版本显示在下面的代码示例,从fast-corners/top.cpp摘录。在综合实现快速算法的细节可以在fast-corners/hls_video_fast.h找到。

观察了解这个码的一个重要的事情是在管线22中使用的指令来设置流之一的深度。在这种情况下,存在的从重复的路径上几个视频行的延迟 Duplicate> FAST >Dilate扩张> PaintMask因为行缓冲器的存在。在这种情况下,快速招致最多7行延迟,扩张招致最多3行延迟,这意味着需要至少: 1920 * (7 + 3) < 20000像素。另外,在第27行的FASTX call对应于cvCvtColor ,cv::FAST,并且在图6 GenMask功能。
Source Files and Project Directories :
在应用笔记中的文件的整体结构反映了ZYNQ Base TRD的结构。在sd_image目录存在提供的SD卡中预置的image,因此很容易尝试设计出。**此image从ZYNQ Base TRD稍微做了修改,包括在启动时加载在一个单独的 经过ARM的预编译的OpenCV的库的一个ramdisk image。设备树也被修改为包括了(generic-uio Linux内核驱动程序可以访问图像处理滤波器中的控制寄存器的)正确配置(我的理解:设备树做出的修改是为了PS可以访问咱们生成的ip核)。**apps目录包含了“demo”应用程序,并为’first-corner“设计,两个包。为了更容易重建设计,一个Makefile还提供了以下目标:
• make elf – build sw (video_library_cmd)
• make sim – build and run csim test
• make core – synthesis and export IP core
• make bitstream – generate bistream (system.bit)
• make boot – generate boot image
• make all – build sw and hw, generate sd_image
从运行Linux命令行或Windows下的Vivado HLS命令提示符“make all”重建整个设计和生成可运行SD卡的image。新的应用程序可以通过复制初始sw/子目录之一,修改的源代码,并运行相应的makefile的规则进行。 FPGA设计的总体结构的基础上的C代码没有被修改,因此,必须小心,要限制修改—不修改生成的RTL的接口。可替代地,接口可以被修改,只要在FPGA设计中也做出相应的变化。
Steps to Accelerate an OpenCV Application :
在本节中,我们将演示如何加快建设OpenCV的应用程序,并测试它在船上的演练。作为一个例子, OpenCV的应用是图像处理的一个简单的2D滤波器:侵蚀。按照此演练中,可以很容易地通过更换图像处理算法写自己的OpenCV的应用程序,并包中包含了两个参考设计也适用于按照使用说明。 为了实现这一目标,需要几个先决条件:
• Xilinx Zynq-7000 SoC ZC702 Evaluation Kit or Xilinx Zynq-7000 SoC Video and Imaging Kit
• Monitor with HDMITM port or DVI port (HDMI/DVI cable needed), supports 1920x1080 resolution, 60 frame rate display
• Linux/Windows host
• Video library package (ship with this app note)
• ARM GNU tools
• Vivado System Edition
• ISE® Design Suite 14.6 (if using EDK-based design)
Most of the following steps will be demonstrated in Linux command line. For Windows, a batch file that starts the Vivado HLS command prompt with correctly set paths is provided that works with the same commands. This batch file may need to be modified to reflect the installation path of the Vivado tools if they are not installed in the default locations.
最下面的步骤将在Linux命令行来证明。对于Windows,启动(设置了正确设置路径的)批处理文件(我的是Video_Library_Windows.bat),可以在Vivado HLS命令提示符下用相同的命令进行工作。此批处理文件可能需要进行修改,如果你的vivado或ISE没有安装在默认位置,以反映ISE和Vivado工具的安装路径。 (注意:这里很重要,我的vivado就没有安装在默认路径,打开这个文件,在第2,3行把路径改为你自己的安装路径)
首先,提取包的内容,把它作为主目录:
• $ export VIDEO_HOME=/path/to/the/extracted/package/root
• $ cd ${VIDEO_HOME}
• $ ls
boot_image hw opencv_install README.txt sd_image sw

Step 1. Create new design
这个“demo”的设计包括用于图像处理的功能的组合的基本结构。要创建新的削弱设计,复制SW目录中的演示设计目录:
$ cd ${VIDEO_HOME}/sw
$ cp –r demo erode
$ cd erode
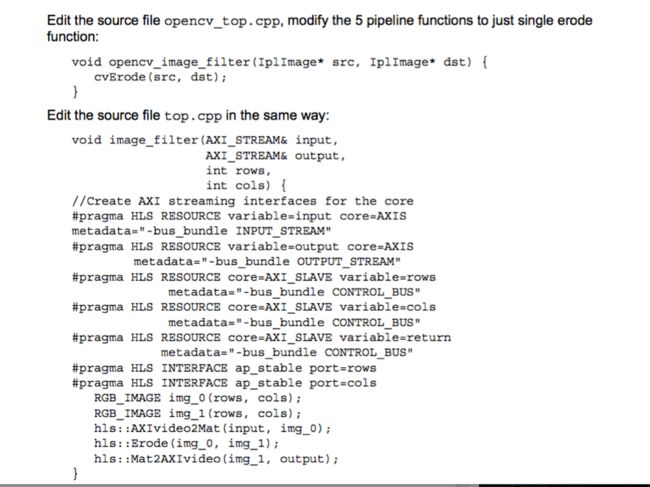
注意:在新top.cpp ,我们使用了相应的功能在HLS空间侵蚀的图像。
运行C仿真验证算法:
$ make sim
它将建立一个测试运行HLS ::Rrode(侵蚀)生成输出图像与OpenCV的功能cvErode产生的金像比较。见“测试通过! ”来验证两个图像是完全一样的。此外,还建议查看输出图像,验证侵蚀的结果。
Step 2. Build OpenCV application for ARM
要在主机交叉编译ARM应用, ARM GNU工具必须安装。 ARM的GNU工具中包含了赛灵思软件开发工具包(SDK) 。该opencv_install目录还包括OpenCV库为ARM在${VIDEO_HOME}/opencv_install/ARM预编译的版本。有关使用ARM GNU工具或建立OpenCV库的更多信息,请参见http://opencv.org/ 。
对于这样的设计,运行下面的生成规则来构建ARM应用程序:
$ make elf
一旦建设完成后, ARM可执行video_library_cmd是在当前目录中。 ARM的应用程序选项来运行OpenCV erode(的侵蚀)和HLS视频库中的处理器erode(侵蚀)。
Step 3. Run Vivado HLS to create an IPcore
这个步骤将使用Vivado HLS合成视频库函数,然后为下一个工序的IP核。运行以下命令进行。
$ make core
注意:为了加快这一步骤,因此这里省略C / RTL协同仿真。您可以通过在run.tcl取消注释与’ cosim_design “该行,然后重新运行Vivado HLS运行的协同仿真:
$ vivado_hls run.tcl
注意:运行C / RTL协同仿真始终处于Vivado HLS设计推荐的一个步骤。
Step 4. Build new system with the accelerator
以下命令将新生成的IP核复制到硬件项目,运行FPGA实现流程产生的比特流:
$ make bitstream
接下来,将通过与预编译FSBL可执行文件和预编译的U-boot可执行比特流文件生成SD卡的启动映像:
$ make boot
引导映像是: ./boot_image/BOOT.bin 。在这一点上,无论是硬件和新设计的软件,可以在开发板上测试。 注意:您可以运行“make all”设计目录要经过2-4步。一旦完成,准备就绪使用SD卡图像将准备在./sd_image 。
Step 5. Test on board
在目录$ {VIDEO_HOME}/sd_image ,取代旧的ARM可执行video_library_cmd和引导映像BOOT.BIN与新生成的一个,然后将sd_image/中的所有文件复制到SD卡。
板的设置:
• 将显示器连接到HDMI输出使用HDMI或HDMI / DVI电缆ZC702板的端口。
• 一个USB mini-B电缆连接到上ZC702板上的Mini USB接口J17标有USB UART和USB A型连接线一端插入主机PC的UART通信在一个开放的USB端口。
• 将电源连接到ZC702板。
• (可选)端口的视频来源,输出视频1080p60的连接至HDMI上FMC_IMAGE_ON板,使现场输入。
• (可选)连接在ZC702板上以太网端口使用RJ45以太网电缆网络。

确保如图6 ,它允许ZC702板从SD卡引导开关设置:

打开一个终端程序(例如TeraTerm ) ,设置波特率= 115200 ,日期位为8 ,奇偶校验=
无,停止位= 1,流量控制为无。
插入包含sd_image内容的ZC702板上的SD插槽的SD卡。接通电路板电源,等待长大登录与root/root系统。
运行在命令行模式下应用:
cd /mnt
./video_library_cmd
Conclusion
OpenCV的是开发计算机视觉设计一个有用的框架。 OpenCV的应用程序可以在嵌入式系统中重新编译他们为ARM架构和ZYNQ设备上执行他们也有使用。此外,通过利用在Vivado HLS的综合视频库, OpenCV的应用程序可以加速处理实时高清晰度视频。
Reference
www.opencv.org
AXI Reference Guide (UG761)
pg016 Video Timing Controller
Vivado Design Suite User Guide: High-Level Synthesis (UG902)
Zynq Base TRD (UG925)
Vivado HLS web page: www.xilinx.com/hls