学习率
学习率
学习率(learning_rate):表示了每次参数更新的幅度大小。
学习率过大:会导致待优化的参数在最小值附近进行波动;
学习率过小:会导致待优化参数收敛的速度慢
参数更新
在训练过程中,参数更新向着损失函数梯度下降的方向
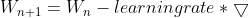
其中 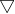 :是梯度,就是损失函数loss的导数
:是梯度,就是损失函数loss的导数
学习率的设置
一般情况下,学习学习都是根据经验,设置一个较小的定值
指数衰减学习率
指数衰减学习率:学习率随着训练轮数变化而动态更新。
在TensorFlow中,通过tf.train.exponential_decay()实现。
exponential_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None):
'''
Args:
learning_rate: A scalar `float32` or `float64` `Tensor` or a
Python number. The initial learning rate.
global_step: A scalar `int32` or `int64` `Tensor` or a Python number.
Global step to use for the decay computation. Must not be negative.
decay_steps: A scalar `int32` or `int64` `Tensor` or a Python number.
Must be positive. See the decay computation above.
decay_rate: A scalar `float32` or `float64` `Tensor` or a
Python number. The decay rate.
staircase: Boolean. If `True` decay the learning rate at discrete intervals
name: String. Optional name of the operation. Defaults to
'ExponentialDecay'.
Returns:
A scalar `Tensor` of the same type as `learning_rate`. The decayed
learning rate.
'''其中:
learning_rate :学习率的初始值
global_step :记录训练的次数
decay_steps :学习率衰减速度,通常为 = 总样本数/BATCH_SIZE
decay_rate :学习衰减系数
staircase :如果为真,学习成阶梯型下降
decay_steps 和decay_rate 通常都是经验之谈。
#step0 准备工作
import tensorflow as tf
import os
import numpy as np
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # 忽略tensorflow警告信息
learning_rate_base = 0.1
learning_rate_decay = 0.99
learning_rate_step = 1
STEPS = 40
global_step = tf.Variable(0,trainable=False)
#step1 前向传播
learning_rate = tf.train.exponential_decay(learning_rate_base,
global_step,
learning_rate_step,
learning_rate_decay,
staircase=True)
w = tf.Variable(tf.constant(5,dtype=tf.float32)) #赋初值5
#step2 反向传播
loss = tf.square(w+1) #直接从loss开始,这里没有数据集和标签
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
#step3 循环迭代
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(STEPS):
sess.run(train_step)
v_learning_rate=sess.run(learning_rate)
print("step:%d,learining_rate:%g,loss:%g,w:%g" % (i,v_learning_rate,sess.run(loss),sess.run(w)))
print('final w:',sess.run(w))运行效果
step:0,learining_rate:0.099,loss:23.04,w:3.8
step:1,learining_rate:0.09801,loss:14.8194,w:2.8496
step:2,learining_rate:0.0970299,loss:9.57903,w:2.095
step:3,learining_rate:0.0960596,loss:6.22196,w:1.49439
step:4,learining_rate:0.095099,loss:4.06089,w:1.01517
step:5,learining_rate:0.094148,loss:2.66305,w:0.631886
step:6,learining_rate:0.0932065,loss:1.75459,w:0.324608
step:7,learining_rate:0.0922745,loss:1.1614,w:0.0776838
step:8,learining_rate:0.0913517,loss:0.772287,w:-0.121202
step:9,learining_rate:0.0904382,loss:0.515867,w:-0.281761
step:10,learining_rate:0.0895338,loss:0.346128,w:-0.411674
step:11,learining_rate:0.0886385,loss:0.233266,w:-0.517024
step:12,learining_rate:0.0877521,loss:0.157891,w:-0.602644
step:13,learining_rate:0.0868746,loss:0.107334,w:-0.672382
step:14,learining_rate:0.0860058,loss:0.0732756,w:-0.729305
step:15,learining_rate:0.0851458,loss:0.0502352,w:-0.775868
step:16,learining_rate:0.0842943,loss:0.0345827,w:-0.814036
step:17,learining_rate:0.0834514,loss:0.0239051,w:-0.845387
step:18,learining_rate:0.0826169,loss:0.0165914,w:-0.871193
step:19,learining_rate:0.0817907,loss:0.0115614,w:-0.892476
step:20,learining_rate:0.0809728,loss:0.00808834,w:-0.910065
step:21,learining_rate:0.0801631,loss:0.00568072,w:-0.924629
step:22,learining_rate:0.0793614,loss:0.0040052,w:-0.936713
step:23,learining_rate:0.0785678,loss:0.00283467,w:-0.946758
step:24,learining_rate:0.0777822,loss:0.00201381,w:-0.955125
step:25,learining_rate:0.0770043,loss:0.00143599,w:-0.962106
step:26,learining_rate:0.0762343,loss:0.00102774,w:-0.967942
step:27,learining_rate:0.075472,loss:0.000738235,w:-0.97283
step:28,learining_rate:0.0747172,loss:0.000532191,w:-0.976931
step:29,learining_rate:0.0739701,loss:0.000385019,w:-0.980378
step:30,learining_rate:0.0732304,loss:0.000279526,w:-0.983281
step:31,learining_rate:0.0724981,loss:0.000203643,w:-0.98573
step:32,learining_rate:0.0717731,loss:0.000148869,w:-0.987799
step:33,learining_rate:0.0710553,loss:0.000109198,w:-0.98955
step:34,learining_rate:0.0703448,loss:8.03662e-05,w:-0.991035
step:35,learining_rate:0.0696413,loss:5.93437e-05,w:-0.992297
step:36,learining_rate:0.0689449,loss:4.39641e-05,w:-0.993369
step:37,learining_rate:0.0682555,loss:3.26757e-05,w:-0.994284
step:38,learining_rate:0.0675729,loss:2.43633e-05,w:-0.995064
step:39,learining_rate:0.0668972,loss:1.82229e-05,w:-0.995731
final w: -0.9957312