一个完整的深度学习图像分割例子(四):模型训练
在前面的[项目简介][环境搭建][数据准备]中,我们已经完成了项目简介,环境搭建以及数据准备工作,接下来就要搭建网络和模型训练了。
现实生活中,我们往往把一些问题建模成数学问题,深度学习中的图像分割就是把分割建模成数学模型。
在进入实战之前,首先讲一下什么是模型,大家都听过AlexNet,ResNet,R-CNN,UNet等名词,这些我们都统称为卷积神经网络,也叫CNN,主要应用于计算机视觉领域,是深度学习的一个重要应用分支,另一个应用比较广泛的是循环神经网络,主要应用于自然语言处理,由于注意力机制在自然语言中太成功了,所以近两年基于自注意力机制的视觉模型在CV领域也非常火热,但我们主要以CNN为主。
图像分割问题实质是对图像每个像素进行分类,由于原图像中每个像素语义信息非常稀疏,没办法在原始图像上进行像素分类,所以需要从原始图像域转换到特征图像域,而这个转换过程需要CNN来提取特征,然后针对特征图像素进行分类,同一类物体被分配同一个分类标签,我们称为语义分割,同一类物体的不同实例被分配不同的标签,我们称为实例分割。
前面我们说过,要想提高分割的准确性,可以主要从两个方面下功夫,第一个是数据增广,另一个就是模型的设计上,一般而言,越靠近输入层,模型感受野也小,模型捕获的特征越抽象,网络捕获的是细节信息,例如,边缘,颜色等,越靠近输出端,感受野越大,特征越具体,包含的语义信息越丰富,这种信息对于分类起到很大作用,所以,层数多的模型要比层数少的模型效果要好,但并不是无限多。
上述模型都包括特征提取网络,我们也称为骨干网络,然后根据任务的不同,后面跟不同的操作,例如,对于分类网络,将特征图展开,输入到Softmax分类器输出属于不同类别的概率,对于回归任务,将特征图展开输入到线性回归网络,输出一个实数值,目标检测网络就是针对特征图的每一个点分配不同的Anchor,然后将Anchor的特征图分别输入到两个回归网络来输出类别的概率和Anchor的坐标。
回到我们的例子,那对于初学者而言,模型从哪里来?这些模型都是大牛们根据自己的经验设计出来的,从第一个CNN模型LeNet开始,后续很多模型都是要么看到前一任模型缺点,进行改进,要么提出具有创新性新模型,然后,如果模型被证实很有效,就会被深度学习框架开发者或者社区开发者实现集成到框架中供大家使用,框架中没有的我们需要自己去实现,如果我们积累一定的经验后,我们也能够设计自己的模型。
对于同一个任务,例如图像分割而言,往往会存在很多模型,例如图像分割模型有UNet,VNet,RetinateNet等,我们该选择哪一个?需要考虑两点,一个是模型的精度,另一个是模型的运行效率,这两点一般是互相矛盾的,能够做到精度高且速度快的模型很少,如果遇到,请珍惜,另外,有些模型是掺杂了一些领域的先验知识的,例如UNet就在医疗领域应用非常广泛,一个模型的设计者都会提供该模型在某个大型公开数据集上的精度和运行效率,我们可以进行对比来选择。
根据以上准则,由于我们比较侧重运行效率,所以我们选择BiSeNet,他的网络模型结构如下:
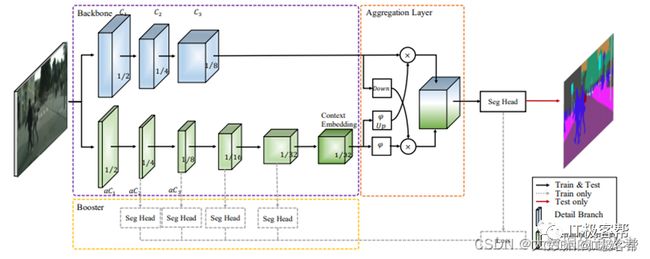
如果从计算机的角度看待模型,那模型就是一个计算图,每个节点都是一个操作,例如,矩阵乘法,激活函数,且每个计算节点都可以计算梯度供反向传播使用,数据从一个节点流向下一个节点,最终得到一个输出,然后通过损失函数来衡量输出和真实标签值差距,并通过优化损失函数来找到使损失函数有最小损失值的参数,寻找最优参数的过程就是模型训练过程。
在计算机中,构建上述模型过程也分为两类,也就是静态图和动态图,静态图就是先定义好整个网络结构,然后计算过程中用定义好得模型进行优化,动态图是一边构图一边计算,这样便于调试,但因为看不到整个图的结构,所以无法优化。

我们将训练完成得到BiSeNet .pdmodel模型文件用Netron模型结构查看工具打开得到下面的计算图结构:
BiSeNet模型在PaddleSegmentation中已经实现,所以我们可以直接拿来用。
构造网络模型:
from paddleseg.models import BiSeNetV2
model = BiSeNetV2(num_classes=2,
lambd=0.25,
align_corners=False,
pretrained=‘/home/aistudio/BiSeNetv2model.pdparams’)
这里说一下pretrained的含义,他叫预训练模型参数,这在实际应用中很有用,他能增加模型精度和收敛速度,思想就是先在大型数据集上训练,获得提取基础特征的能力,然后将参数拿过来,在我们任务的数据集上继续训练,也叫微调;但这并不是万能胶,他需要源域和目标域有交集,如果我们拿ImageNet数据训练好的参数来训练我们的MRI图像,效果会非常不好,因为这两个数据集根本驴唇不对马嘴。
#构建优化器,和loss
from paddleseg.models.losses import CrossEntropyLoss,DiceLoss, MixedLoss
import paddle
设置学习率
base_lr = 0.05
lr = paddle.optimizer.lr.PolynomialDecay(learning_rate=base_lr, decay_steps=4800, verbose=False)
optimizer = paddle.optimizer.Momentum(lr, parameters=model.parameters(), momentum=0.9, weight_decay=4.0e-5)
losses = {}
losses[‘types’] = [CrossEntropyLoss()] * 5
losses[‘coef’] = [1]* 5
我们前面说过,模型的初始参数是随机设置的,优化过程就是更新参数来使得损失函数达到最优,这里面主要涉及选择什么损失函数以及如何优化参数。
图像分割属于像素分类问题,对于分类问题一般选择交叉熵损失函数,回归问题选择均方误差损失函数,损失函数的选择涉及很多学问,我就不展开讲了,讲也讲不好,给大家发几篇链接。
https://mp.weixin.qq.com/s/_h2MEvNgYbfwuVPPpQaXAQ
https://mp.weixin.qq.com/s/AmgztNfsCovz1F7C4GARFA
对于参数的优化,主要是不要死板的根据下面公式进行优化,而是添加一些先验知识。
https://mp.weixin.qq.com/s/pj_Vs_S5Lkc0h3qXOv2mYQ
https://mp.weixin.qq.com/s/pS5_Hf_cHlxGKV_HQLz0tQ
接下来就开始训练:
from paddleseg.core import train
train(
model=model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=optimizer,
save_dir=‘Myoutput2’,
iters=800,
batch_size=8,
save_interval=120,
log_iters=24,
num_workers=0,
losses=losses,
use_vdl=True)
训练完成后会在’Myoutput2’文件夹下生成模型文件和参数文件,在将模型部署到实际产品前往往还会对模型进行验证,看看是否达到集成的标准。
import paddle
from paddleseg.core import evaluate
model = BiSeNetV2(num_classes=2)
model_path = ‘/home/aistudio/Myoutput/best_model/model.pdparams’
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
evaluate(model,val_dataset)
如果达到了标准,那我们就可以将模型文件和参数文件拷贝出来了,供后续推理使用,训练过程到此结束,接下来就是将推理过程。
详情请关注“计算机视觉大讲堂”