New Pointer-Generator Networks for Summarization
指针生成网络之文本摘要
文章目录
- 文本摘要任务介绍
- 模型
- 数据
- 数据集来源
- 数据分析
- 数据预处理
- 实验
- 结果
- 结果分析
- 改进措施,及实验效果
文本摘要任务介绍
文本摘要主要分为两种模式:一种是生成式,一种是抽取式。
其中抽取式是根据词语重要性、句子重要性排序,抽取出重要度高的句子,从而形成摘要。主要是对文本的选择,过程相对更容易,但是对于复杂的文本时,很难仅仅通过选择文本来形成摘要,如小说。
sequence-to-sequence为生成式摘要提供了一种可行的新方法。然而,这些模型有两个缺点:
它们容易复制事实上的细节不准确,他们倾向于重复自己
而指针生成网络从两方面做了改进:
第一,使用指针生成器网络可以通过指向从源文本中复制单词,这有助于准确复制信息,同时保留generater的生成能力
第二,使用coverage跟踪摘要的内容,不断更新注意力,从而阻止文本不断重复
模型

以上就是paper中模型的架构。模型的介绍,可以参考:指针生成网络(Pointer-Generator-Network)原理与实战。
数据
数据来源
- 英文数据:
cnn 和 dalymail 源数据链接
国内的百度网盘我打包了一份,与源数据相同 链接 提取码:k8v3
其中分词需要用到stanford-corenlp,stanford-corenlp下载链接
国内的有一个已经下载好的版本,在百度网盘链接 提取码:pnzk - 中文数据:
微博中文数据 密码:9yqt。
新闻中文数据集
250万篇新闻( 原始数据9G,压缩文件3.6G;新闻内容跨度:2014-2016年)
Google Drive下载或百度云盘下载,密码:k265
数据分析
- 英文数据分析
先统计英文数据集,每则故事正文和摘要的长度,是一个怎么样的分布
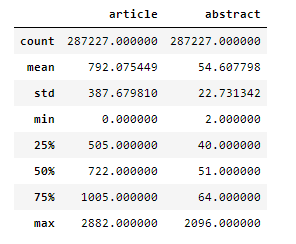
上图是文章的长度和对应摘要长度的统计。可以看到有些正文是没有的,因此在处理数据的过程中,把正文和摘要对应不上的情况清楚掉。(标准的数据是一篇正文对应一句摘要,数据集中有只有正文,只有摘要的情况,那么把这些情况的数据忽略掉)
将正文的长度排序,和摘要的长度进行画图。如下图所示:

上图的横坐标是正文的长度进行排序,纵坐标是和正文对应摘要的长度。一般来说,正文长度是大于摘要长度,正文长度和摘要长度都不为0,可以从上图看出,有一些离群点,那么进行处理的时候将摘要过长的,正文过长的,进行裁剪。对缺失的进行去除。
- 中文数据分析
首先分析中文数据正文和摘要长度
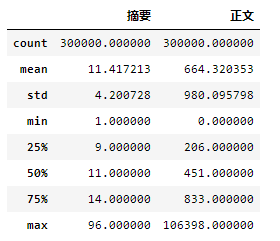
上图可以看出摘要和正文都有缺失的情况,需要清洗。
再分析正文长度和摘要长度的对比
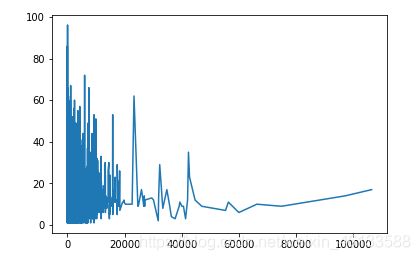
横坐标是升序排序正文长度,纵坐标是摘要长度。这个数据集正文长度比较集中,同时也有正文和摘要对应不上的情况,数据处理的时候需要将其清洗掉。
数据预处理
英文数据预处理:
主要完成的工作:将cnn和dailymail下面的story整理tokenized下面/train、/test、/val文件,里面的每个文件存储着100000个example,然后构建整个数据集的词表。
中文的数据处理:
主要完成的工作:将news2016zh_train.json和news2016zh_valid.json数据按10000的数量切分到sub文件夹中,然后读取sub文件夹中的文件,进行数据的处理和分词以及构建词表。
实验
原论文代码链接:https://github.com/becxer/pointer-generator
参考项目指针生成网络(Pointer-Generator-Network)原理与实战是对原论文的复现。论文所对应的具体环境是:Centos7.4/python3.6/pytorch1.0.1 GPU:Tesla V100-SXM2-16GB。
由于上面项目的数据集是使用 微博中文数据集 是中文的,数据集的质量一般。
在分析完原项目的基础上,对原项目做出了修改和更换了数据集。本次我们复现结果时所用的代码时是自己实现的pytorch版本,有两个版本
- 英文数据集
https://github.com/hquzhuguofeng/New-Pointer-Generator-Networks-for-Summarization - 中文数据集
https://github.com/hquzhuguofeng/New-Pointer-Generator-Networks-for-Summarization-Chinese
具体环境是:windows10 + python3.6 + pytorch1.1.0 GPU NVIDIA GeForce GTX 1050 Ti 4G
本次实验,模型使用的参数如下:
hidden_dim = 256, embedding dimension = 128, coverage_loss_weight = 1.0, eps = 1e-12, dropout = 0.5等
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
结果
- 参考论文纠错
参考论文下cnn/dailymail数据集实验和微博中文数据集的实验结果和原论文结果差不多,不进一步的分析。
接下来具体分析原论文有一处出现的错误:在batcher.py下 fill_example_queue函数中:
def fill_example_queue(self):
input_gen = self.text_generator(data.example_generator(self._data_path, self._single_pass))
while True:
try:
# 提取出文章和摘要
(article, abstract) = input_gen.__next__() # read the next example from file. article and abstract are both strings.
article, abstract = article.decode(), abstract.decode()
上面代码中 (article, abstract) = input_gen.next() 这一句,导致以下情况的发生:正文1,应该对应摘要1,正文2,对应摘要2. 现在是正文1对应摘要2.产生错位了。在输入模型的时候,正文和摘要是不对应的。
将上面那句更改为下面的代码,就可以一一对应上。
article = input_gen.__next__()[0]
abstract = input_gen.__next__()[1]
- 评价标准
论文中使用评价结果的准则是ROUGE。ROUGE是2004年由ISI的Chin-Yew Lin提出的一种自动摘要评价方法,现被广泛应用于DUC(Document Understanding Conference)的摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为摘要评价技术的通用标注之一。 ROUGE准则由一系列的评价方法组成,包括ROUGE-N(N=1、2、3、4,分别代表基于1元词到4元词的模型),ROUGE-L,ROUGE-S, ROUGE-W,ROUGE-SU等。
其公式:
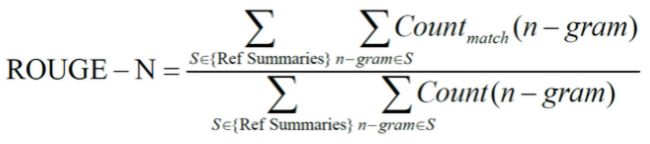
其中,n-gram表示n元词,{Ref Summaries}表示参考摘要,即事先获得的标准摘要,Countmatch(n-gram)表示系统摘要和参考摘要中同时出现n-gram的个数,Count(n-gram)则表示参考摘要中出现的n- gram个数。
不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作“相关文档数目”,即标准摘要中所有的N-gram个数。
英文数据集
指针生成网络原始论文1在cnn/dailymail数据集下的结果如下:

在上表中,上半部分是模型生成的的摘要评估,而下半部分的是提取摘要评估。可以看出抽象生成的效果接近了抽取效果。
在纠错完参考项目模型实验中使用的优化器是adam,train loss 和 val loss 随训练轮次的下降,如下图所示:

我们使用Adam进行模型优化,学习率为0.001,梯度累加步设置成1。我尝试了Adagrad优化,效果不佳。我们使用最大值的梯度剪辑梯度范数为1,但不使用任何形式的正则化。我们在验证集上使用loss来实现早期停止。在train和test期间,我们将文章截断为400个tokens,并将摘要的长度限制为100个tokens用于train和test。这样做是为了加快train和test,但我们还发现截断文章可以提高模型的性能。
本实验( pointer-generator+coverage )复现ROUGE分数如下:
该实验结果是模型跑到43000轮次最佳的模型所预测出来的文本,计算得到的得分。

Rouge1有37.4%,Rouge2有15.8%,Rouge-L有34.2%,分数要比论文中略低的原因是,训练的轮次不够多。但结果是接近的。
首先我们看一下英文输出对比:

可以看出Coverage很好解决了,摘要重复生成的问题。
中文数据集
参考论文在中文数据集下的效果:
模型在跑完了40K个轮次之后,选取最好的模型,生成的摘要和参考位于:rouge_dec_dir和rouge_ref下。
参考论文在纠正,之前提出的错误之后,ROUGE的效果如下:
rouge-1 = 0.3819,rouge-2 = 0.1493
例子1:
- 原文:
河北 小伙 崔联平 游玩 时 在 石家庄市 平山县 太行山 深处 发现 一棵 直径 1.38 米 、 重约 150 斤 的 野生 灵芝 。 崔联平 找 了 几个 村民 才 将 这个 大家伙 抬 下山 。 经 鉴定 该 灵芝 是 上品 云芝 , 如此 硕大 的 云芝 在 我国 北方 相当 罕见 。 网友 : 灵芝 中 的 “ 土豪 ” 啊 ! http : / / t . cn / RhZvF5J - 参考摘要:
“ 巨无霸 ” 灵芝 来 了 ! 河北 野生 灵芝 重 150 斤 [ 吃惊 ] - 生成摘要:
河北 小伙 崔联平 游玩 发现 一棵 直径 1.38 米 、 重约 150 斤 的 我国 罕见 : 的 野生 灵芝
例子2:
- 原文:
近日 , 新疆 乌鲁木齐 931 路 公交车 司机 外力 • 吐尔迪开 着 铺满 “ 草坪 ” 的 公交车 , 为 乘客 们 带来 了 别样 的 感受 。 但 因为 “ 草坪 公交 ” 存在 安全隐患 , 一旦 遇到 火苗 , 便 迅速 融化 燃烧 , 不 符合 消防安全 , 车 内 塑料 草皮 已 被 取消 。 乌鲁木齐 铺 草皮 公交 因 安全隐患 被 叫停 ( 图 ) - 参考摘要
“ 草坪 公交 ” 存 安全隐患 已 被 叫停 - 生成摘要
新疆 乌鲁木齐 铺 草皮 公交 因 安全隐患 被 叫停 ( 图 ) [ 衰 ] [ 衰 ] [ 衰 ]
分析:
可以看到生成的摘要和参考摘要的意思是十分接近的。参考摘要,大都是从原文中的意思中概括出来的,从模型上来说可以理解为大都是生成出来的。而生成摘要,完成的更多是原文片段的截取和拼接组合。例子1中,“河北 小伙 崔联平 游玩” ,“发现 一棵 直径 1.38 米 、 重约 150 斤 的”可以看出是从原文中截取出来的,但总体上来说又不是完全的截取出来的。例子2中,生成的摘要后面有 ( 图 ) [ 衰 ] [ 衰 ] [ 衰 ]。其中(图)是原文中有的成分,[衰] 是学习出来的,应该是模型学习到这篇文章的情感成分和[衰]相近,于是加上去了。而且训练过程中,没有将符号去除掉,且生成过程中,还重复了,显然符号没有进入coverage的计算过程中。
改进措施及实验结果
我只针对中文数据集进行修改。
-
修改前关于模型的考虑
原始论文中模型。用自己的话来说就是,正文通过embedding, 通过lstm 得到正文的表征output和含整个正文的隐状态hidden_state。之后,依据时间步每一步抽取摘要的一个字和摘要的前文来得到摘要的embedding,使用摘要的embedding和正文的hidden_state 经过lstm的decoder的输出output_de和hidden_de。
接下就是使用encoder和decoder来计算给正文使用的attention分布,计算这个attention需要用到encoder的输出含义是正文的上下文的表征,正文的掩码,去除掉mask的影响,摘要和正文一起经过lstm得到hidden_state,coverage给重复计算用。
得到了attention分布,那么正文的attention分布就可以更suitable。那终究还是正文的上下文语义向量。
以上描述的目的在于根据参考摘要和正文,随时间步生成下一个单词。可以描述成以下:下一个单词的分布 = 生成单词的概率 * 正文词汇的分布 + (1 - 生成单词的概率) * 使用encoder和decoder计算出来attention_score的分布
我们可以发现正文和摘要在进行特征提取过程中都是使用LSTM进行提取的,如今transformer的功能相比LSTM好太多了吧!不如尝试将LSTM换成Transformer进行正文和摘要的提取
其中主体的部分还是使用pointer-generate的主体结构,只是特征抽取部分使用Bert结构来进行特征抽取。
- 修改前关于中文数据集的考虑
参考项目使用的是微博数据集,我认真阅读了下数据集中的正文和摘要,发现正文和摘要多多少少是不太合理的。就是数据的质量不怎么好。于是换了一个相对比较靠谱的数据。
其次是原论文和参考项目对中文是使用结巴分词,其分词效果如下:
正文:
[英国 石油 天然气 投资 公司 ( UKOG ) 9 日 说 , 英格兰 南部 地底 探测 到 规模 巨大 的 油田 , 石油 储量
或许 高达 1000 亿桶 。 这家 公司 的 首席 执行官 史蒂芬 · 桑德森 当天 在 接受 英国 媒体 采访 时 表示 ,
该 公司 认为 英格兰 南部 地区 地底 储有 巨量 的 石油资源 , 推测储量 在 500 亿至 1000 亿桶 之间 , 或许
是 英国 过去 30 年来 发现 的 最大 陆上 石油资源 。 这 可是 一个 惊人 的 数字 。 要 知道 , 苏格兰 在 北
海 的 所有 石油 公司 在 过去 40 年 的 总产量 也 只有 450 亿桶 。 该 公司 预计 , 这些 石油资源 地下 储存
深度 在 2500 英尺 至 3000 英尺 ( 762 米 至 914 米 ) 之间 , 其中 可以 开发 的 比例 为 5% 至 15% ,
这 意味着 到 2030 年 , 这一 地区 的 石油 产量 将 能够 满足 英国 10% 至 30% 的 石油 需求 。 英格兰 南
部 的 石油 开采 活动 已有 数十年 历史 , 开采 地点 分布 在 肯特郡 、 苏 赛克斯 郡 、 萨里郡 和 汉普郡 等
地 。 去年 , 英国 地质勘探 局曾 发布 报告 称 , 英格兰 南部 地区 拥有 页岩 油 资源 , 储量 约 为 22 亿
至 85 亿桶 。 这一 爆炸性 的 公告 发布 后 , UKOG 的 股票 便 开始 疯涨 。 截至 4 月 9 日 , UKOG 的
股价 从 原先 的 每股 1.1 便士 一路 狂飙 至 3.25 便士 , 涨幅 高达 261.99% , 最高价 甚至 冲到 了 4.7
便士 。 股票 市值 瞬间 飙升 为 原先 的 3 倍 , 达到 1822 万英镑 。]
摘要
[英国 石油 公司 发现 巨型 油田 股价 飙升 3 倍 !]
以上展示的就是一个example,在处理的过程中,由于是结巴分的词,容易出现很多oov的单词,比如这个example,出现以下的oov:
[UKOG 地底 桑德森 储有 石油资源 推测储量 762 914 肯特郡 赛克斯 萨里郡 汉普郡 地质勘探 局曾 便士 3.25 261.99% 1822]
虽然,论文的代码有处理oov的字。可以考虑将中文直接分成一个个的字。这样oov的字可以大大的减少。直接将每个字分成一个个的效果如下:
正文:
['英', '国', '石', '油', '天', '然', '气', '投', '资', '公', '司', '(', 'ukog', ')', '9', '日',
'说', ',', '英', '格', '兰', '南', '部', '地', '底', '探', '测', '到', '规', '模', '巨', '大',
'的', '油', '田', ',', '石', '油', '储', '量', '或', '许', '高', '达', '1000', '亿', '桶', '。',
'这', '家', '公', '司', '的', '首', '席', '执', '行', '官', '史', '蒂', '芬', ' ·', '桑', '德',
'森', '当', '天', '在', '接', '受', '英', '国', '媒', '体', '采', '访', '时', '表', '示', ',',
'该', '公', '司', '认', '为', '英', '格', '兰', '南', '部', '地', '区', '地', '底', '储', '有',
'巨', '量', '的', '石', '油', '资', '源', ',', '推', '测', '储', '量', '在', '500', ' 亿', '至',
'1000', '亿', '桶', '之', '间', ',', '或', '许', '是', '英', '国', '过', '去', '30', '年', '来',
'发', '现', '的', '最', '大', '陆', '上', '石', '油', '资', '源', '。', '这', '可', '是', '一',
'个', '惊', '人', '的', '数', '字', '。', '要', '知', '道', ',', '苏', '格', '兰', '在', '北',
'海', '的', '所', '有', '石', '油', '公', '司', '在', '过', '去', '40', '年', '的', '总', '产',
'量', '也', '只', '有', '450', '亿', '桶', '。', '该', '公', '司', '预', '计', ',', '这', '些',
'石', '油', '资', '源', '地', '下', '储', '存', '深', '度', '在', '2500', '英', '尺', '至', '3000',
'英', '尺', '(', '762', '米', '至', '914', '米', ')', '之', '间', ',', '其', '中', '可', '以',
'开', '发', '的', '比', '例', '为', '5', '%', '至', '15', '%', ',', '这', '意', '味', '着', '到',
'2030', '年', ',', '这', '一', '地', '区', '的', '石', '油', '产', '量', '将', '能', '够', '满',
'足', '英', '国', '10', '%', '至', '30', '%', '的', '石', '油', '需', '求', '。', '英', '格', '兰',
'南', '部', '的', '石', '油', '开', '采', '活', '动', '已', '有', '数', '十', '年', '历', '史',
',', '开', '采', '地', '点', '分', '布', '在', '肯', '特', '郡', '、', '苏', '赛', '克', '斯', '郡',
'、', '萨', '里', '郡', '和', '汉', '普', '郡', '等', '地', '。', '去', '年', ',', '英', '国', '地',
'质', '勘', '探', '局', '曾', '发', '布', '报', '告', '称', ',', '英', '格', '兰', '南', '部', '地',
'区', '拥', '有', '页', '岩', '油', '资', '源', ',', '储', '量', '约', '为', '22', '亿', '至', '85',
'亿', '桶', '。', '这', '一', '爆', '炸', '性', '的', '公', '告', '发', '布', '后', ',', 'ukog',
'的', '股', '票', '便', '开', '始', '疯', '涨', '。', '截', '至', '4', '月', '9', '日', ',', 'ukog',
'的', '股', '价', '从', '原', '先', '的', '每', '股', '1', '.', '1', '便', '士', '一', '路', '狂',
'飙', '至', '3', '.', '25', '便', '士', ',', '涨', '幅', ' 高', '达', '261', '.', '99', '%', ',',
'最', '高', '价', '甚', '至', '冲', '到', '了', '4', '.', '7', '便', '士', '。', '股', '票', '市',
'值', '瞬', '间', '飙', '升', '为', '原', '先', '的', '3', '倍', ',', '达', '到', '1822', '万',
'英', '镑', '。']
摘要:
['英', '国', '石', '油', '公', '司', '发', '现', '巨', '型', '油', '田', '股', '价', '飙', '升', '3', '倍', '!']
模型修改之后的代码:
模型的train_loss和val_loss随训练轮次的图如下:

可以从图中看出在30K轮次之后,loss趋于平稳了。
我们来观察生成出来的摘要:
例子1:
- 正文
黄, 辰, 鑫, :, 欧, 行, 维, 持, 低, 利, 率, 重, 挫, 欧, 元, ,, 现, 货, 白, 银, 现, 货, 原, 油, 黯,
然, 下, 行, 市, 场, 消, 息, 面, 指, 引, :, 北, 京, 时, 间, 周, 四, (, 10, 月, 20, 日, ), 晚, 19, :,
45, ,, 欧, 洲, 央, 行, 一, 如, 市, 场, 预, 期, ,, 宣, 布, 维, 持, 三, 大, 基, 准, 利, 率, 不, 变,
,, 维, 持, 基, 准, 利, 率, 0, ., 000, %, 不, 变, ,, 维, 持, 欧, 央, 行, 存, 款, 便, 利, 利, 率, -,
0, ., 400, %, 不, 变, ,, 维, 持, 欧, 洲, 央, 行, 边, 际, 贷, 款, 工, 具, 0, ., 250, %, 不, 变, 。,
欧, 洲, 央, 行, 强, 调, :, 如, 有, 必, 要, ,, 将, 延, 长, 资, 产, 购, 买, 至, 2017, 年, 3, 月, 之,
后, ,, 以, 便, 看, 到, 通, 胀, 路, 径, 出, 现, 可, 持, 续, 的, 调, 整, 。, 北, 京, 时, 间, 周, 四,
(, 10, 月, 20, 日, ), ,, 美, 国, 劳, 工, 部, 公, 布, 的, 数, 据, 显, 示, ,, 美, 国, 10, 月, 15,
日, 当, 周, 初, 请, 失, 业, 金, 人, 数, 为, 26, 万, ,, 创, 下, 五, 周, 新, 高, ,, 数, 据, 差, 于,
预, 期, ,, 并, 但, 仍, 低, 于, 30, 万, 门, 槛, 。, 具, 体, 数, 据, 显, 示, ,, 美, 国, 10, 月, 15,
日, 当, 周, 初, 请, 失, 业, 金, 人, 数, 为, 26, 万, ,, 预, 期, 25, 万, ,, 前, 值, 24, ., 6, 万,
。, 路, 透, 评, 论, 此, 次, 数, 据, 称, ,, 此, 次, 初, 请, 失, 业, 金, 人, 数, 略, 高, 于, 预, 期,
,, 录, 得, 五, 周, 高, 位, ,, 但, 仍, 然, 连, 续, 85, 周, 处, 于, 30, 万, 关, 口, 下, 方, ,, 为,
1970, 年, 以, 来, 最, 长, 连, 续, 周, 期, ,, 本, 周, 初, 请, 人, 数, 增, 加, 主, 要, 原, 因, 在,
于, 飓, 风, 导, 致, 北, 卡, 罗, 莱, 纳, 州, 的, 数, 千, 人, 暂, 缓, 工, 作, ,, 但, 这, 并, 无, 法,
影, 响, 到, 美, 国, 整, 体, 强, 劲, 的, 就, 业, 市, 场, 。, 欧, 洲, 央, 行, 如, 期, 维, 持, 利, 率,
决, 议, 不, 变, ,, 市, 场, 聚, 焦, 德, 拉, 基, 讲, 话, 。, 德, 拉, 基, 任, 何, 有, 关, qe, 减, 码,
的, 暗, 示, ,, 都, 可, 能, 导, 致, 债, 市, 大, 幅, 抛, 售, 。, 利, 率, 决, 议, 公, 布, 后, ,, 欧,
元, 兑, 美, 元, 震, 荡, ,, 黄, 金, 白, 银, 上, 涨, 。, 召, 开, 新, 闻, 发, 布, 会, 之, 际, ,, 欧,
元, 短, 线, 暴, 涨, 。, 截, 至, 北, 京, 时, 间, 20, :, 45, ,, 欧, 元, 兑, 美, 元, 报, 1, ., 098,
;, 黄, 金, 报, 1270, ., 27, 美, 元, /, 盎, 司, ;, 白, 银, 报, 17, ., 611, 美, 元, /, 盎, 司, ;,
wti, 原, 油, 报, 51, ., 059, 美, 元, /, 桶, 。, 技, 术, 面, 《, 现, 货, 白, 银, 分, 析, 》, 华, 商,
白, 银, 现, 报, 3500, 元, /, 千, 克, ,, 今, 晚, 市, 场, 等, 待, 的, 欧, 行, 利, 率, 决, 议, 以, 及,
德, 拉, 基, 讲, 话, ,, 没, 有, 给, 市, 场, 惊, 喜, ,, 欧, 行, 宣, 布, 维, 持, 主, 要, 再, 融, 资,
利, 率, 于, 0, %, 水, 平, 不, 变, ,, 并, 决, 定, 维, 持, 每, 月, 800, 亿, 购, 债, 规, 模, 将, 持,
续, 至, 2017, 年, 3, 月, 底, ,, 其, 后, 德, 拉, 基, 记, 者, 会, 表, 明, 利, 率, 将, 维, 持, 当, 前,
或, 更, 低, 水, 平, ,, 另, 外, 会, 议, 没, 有, 对, 延, 长, qe, 进, 行, 讨, 论, ,, 因, 此, 欧, 元,
兑, 美, 元, 继, 续, 下, 跌, ,, 美, 元, 指, 数, 再, 度, 提, 振, 走, 高, 至, 98, ., 30, ,, 打, 压,
金, 银, 市, 场, ;, 日, 线, 图, 上, 看, ,, 银, 价, 今, 日, 回, 吐, 前, 3, 个, 交, 易, 日, 的, 涨,
幅, ,, 从, 3560, 跌, 至, 3500, 下, 方, ,, 走, 势, 重, 新, 出, 现, 空, 头, 延, 续, 迹, 象, ,, 晚,
间, 若, 跌, 破, 3500, ,, 下, 跌, 关, 注, 3470, -, 3460, 近, 期, 盘, 整, 低, 位, ,, 操, 作, 上,
反, 弹, 沽, 空, 为, 主, ,, 上, 方, 关, 注, 3550, -, 3560, 阻, 力, 。, 整, 体, 走, 势, 来, 看, ,,
震, 荡, 区, 间, 还, 没, 有, 打, 开, ,, 白, 银, 还, 有, 最, 后, 一, 线, 喘, 气, 机, 会, ,, 今, 晚,
关, 注, 3470, -, 3550, 区, 间, ,, 高, 空, 为, 主, ,, 低, 多, 为, 辅, ;, 华, 商, 白, 银, 操, 作,
建, 议, 参, 考, :, 1, 、, 银, 价, 3520, 附, 近, 做, 空, ,, 止, 损, 3550, ,, 目, 标, 3470, ;, 2,
、, 银, 价, 支, 撑, 3470, 附, 近, 轻, 仓, 多, ,, 止, 损, 3440, ,, 目, 标, 3500, -, 3520, ;, 3,
、, 银, 价, 跌, 破, 3470, ,, 反, 弹, 3500, 继, 续, 做, 空, ;, 《, 现, 货, 原, 油, 分, 析, 》, 先,
看, 国, 际, 原, 油, 走, 势, ,, 国, 际, 原, 油, 现, 报, 50, ., 78, 美, 元, /, 桶, ,, 油, 价, 日,
内, 大, 幅, 回, 调, 1, 美, 元, ,, 跌, 幅, 达, 1, ., 76, %, ,, 日, 内, 最, 高, 51, ., 83, ,, 昨,
日, eia, 利, 好, 走, 出, 的, 反, 弹, 空, 间, 全, 部, 回, 吐, ,, 油, 价, 重, 新, 回, 归, 50, 美, 元,
关, 口, 争, 夺, 战, ,, 短, 线, 上, 油, 价, 今, 日, 回, 调, 下, 行, 为, 主, ,, 大, 趋, 势, 上, 油,
价, 支, 撑, 50, 美, 元, 关, 口, ,, 还, 有, 触, 低, 反, 弹, 的, 机, 会, ;, 今, 晚, 油, 价, 下, 跌,
关, 注, 50, 关, 口, ,, 上, 方, 关, 注, 51, 美, 元, 分, 水, 岭, ,, 操, 作, 上, 做, 空, 为, 主, ,,
支, 撑, 50, 美, 元, 关, 口, 再, 逢, 低, 买, 入, ;, 华, 商, 聚, 丙, 烯, 现, 报, 5100, 元, /, 吨, ,,
日, 线, 图, 上, 看, ,, 聚, 丙, 烯, 上, 方, 5220, 一, 线, 短, 线, 依, 然, 是, 阻, 力, 压, 制, 位,
,, 聚, 丙, 烯, 下, 跌, 关, 注, 5, ., 10, 日, 均, 线, 5100, 价, 格, 位, 置, ,, 跌, 破, 则, 继, 续,
看, 5060, -, 5050, 前, 期, 盘, 整, 支, 撑, 位, ,, 还, 有, 50, 个, 点, 下, 跌, 空, 间, ,, 短, 线,
上, 先, 看, 下, 跌, ,, 支, 撑, 5060, -, 5050, 再, 逢, 低, 买, 入, ;, 华, 商, 原, 油, (, 聚, 丙,
烯, ), 操, 作, 建, 议, 参, 考, :, 1, 、, 聚, 丙, 烯, 5060, 附, 近, 做, 多, ,, 止, 损, 5020, ,,
目, 标, 5100, -, 5120, ;, 2, 、, 聚, 丙, 烯, 5120, 附, 近, 做, 空, ,, 止, 损, 5160, ,, 目, 标,
5060, ;, 3, 、, 聚, 丙, 烯, 反, 弹, 破, 位, 5120, ,, 重, 新, 看, 涨, ,, 目, 标, 5200, ;, 此, 文,
来, 源, 于, 公, 众, 号, :, 辰, 鑫, 析, 市, 。, 温, 馨, 提, 示, :, 由, 于, 各, 平, 台, 点, 位, 不,
一, 及, 文, 章, 发, 布, 时, 间, 关, 系, 以, 上, 点, 位, 以, 国, 际, 盘, 面, 为, 准, ,, 其, 他, 平,
台, 自, 行, 换, 算, ,, 以, 上, 点, 位, 操, 作, 风, 险, 自, 担, ,, 更, 多, 实, 时, 建, 议, 笔, 者,
会, 在, 实, 盘, 中, 给, 出, 。
- 参考摘要
黄 辰 鑫 : 欧 行 维 持 低 利 率 重 挫 欧 元 , 现 货 白 银 现 货 原 油 黯 然 下 行 - 生成摘要
黄 辰 鑫 : 欧 行 维 持 低 利 率 重 挫 欧 元 , 现 货 原 油 黯 然 下 行
例子2:
- 正文
各, 有, 关, 高, 校, :, 为, 贯, 彻, 落, 实, 党, 中, 央, 、, 国, 务, 院, 《, 关, 于, 发, 展, 众, 创, 空, 间, 推, 进, 大, 众, 创, 新, 创, 业, 的, 指, 导, 意, 见, 》, (, 国, 办, 发, 〔, 2015, 〕, 9, 号, ), 和, 《, 关, 于, 深, 化, 高, 等, 学, 校, 创, 新, 创, 业, 教, 育, 改, 革, 的, 实, 施, 意, 见, 》, (, 国, 办, 发, 〔, 2015, 〕, 36, 号, ), 文, 件, 精, 神, ,, 激, 发, 高, 校, 大, 学, 生, 创, 业, 活, 力, ,, 增, 强, 大, 学, 生, 创, 新, 意, 识, 和, 实, 践, 能, 力, ,, 推, 动, 我, 区, 科, 技, 创, 新, 活, 动, 的, 深, 入, 开, 展, ,, 教, 育, 厅, 联, 合, 新, 疆, 大, 学, 信, 息, 技, 术, 创, 新, 园, 举, 办, “, 寻, 找, 新, 疆, 最, 美, 创, 客, ”, 活, 动, ,, 相, 关, 情, 况, 通, 知, 如, 下, :, 一, 、, 大, 赛, 目, 的, 大, 力, 宣, 传, 国, 家, 的, 创, 新, 创, 业, 政, 策, ,, 使, 大, 众, 创, 业, 、, 万, 众, 创, 新, 深, 入, 人, 心, ;, 展, 示, 大, 学, 生, 创, 业, 团, 队, 风, 采, ,, 激, 发, 创, 新, 创, 业, 热, 情, ,, 营, 造, 良, 好, 的, 创, 业, 环, 境, ;, 征, 集, 优, 秀, 创, 新, 创, 业, 项, 目, ,, 培, 育, 创, 新, 创, 业, 团, 队, ;, 建, 立, 服, 务, 创, 新, 创, 业, 的, 机, 制, ,, 搭, 建, 创, 新, 创, 业, 孵, 化, 平, 台, ,, 推, 动, 创, 新, 促, 进, 创, 业, ,, 创, 业, 带, 动, 就, 业, 的, 双, 创, 新, 局, 面, 。, 二, 、, 大, 赛, 组, 织, 机, 构, 主, 办, 单, 位, :, 新, 疆, 维, 吾, 尔, 自, 治, 区, 教, 育, 厅, 高, 等, 教, 育, 处, ;, 承, 办, 单, 位, :, 新, 疆, 大, 学, 信, 息, 技, 术, 创, 新, 园, 有, 限, 公, 司, 、, 新, 疆, 大, 学, 草, 根, 众, 创, ;, 协, 办, 单, 位, :, 有, 关, 高, 等, 院, 校, 、, 中, 亚, 众, 投, 、, 众, 投, 邦, 、, 自, 治, 区, 人, 民, 广, 播, 电, 台, 、, 乌, 鲁, 木, 齐, 晚, 报, 、, 新, 疆, 广, 电, 网, 络, 、, 疆, 外, 足, 迹, 。, 三, 、, 参, 赛, 对, 象, 新, 疆, 高, 校, 在, 校, 生, 或, 毕, 业, 3, 年, 内, 的, 大, 学, 生, 创, 业, 团, 队, 及, 企, 业, 。, 四, 、, 大, 赛, 宗, 旨, 专, 业, 引, 领, 、, 大, 众, 参, 与, 、, 公, 开, 透, 明, 、, 公, 平, 公, 正, 。, 五, 、, 比, 赛, 时, 间, 2016, 年, 10, 月, 14, 日, —, —, 2016, 年, 12, 月, 15, 日, 六, 、, 比, 赛, 流, 程, (, 一, ), 第, 一, 阶, 段, :, 宣, 传, 发, 动, 时, 间, :, 2016, 年, 10, 月, 14, 日, 至, 11, 月, 15, 日, 24, 时, 。, 在, 各, 大, 高, 校, 校, 内, 、, 大, 赛, 官, 方, 微, 信, 公, 众, 平, 台, ,, 宣, 传, 此, 次, 大, 赛, 的, 目, 的, 、, 参, 赛, 条, 件, 、, 比, 赛, 流, 程, 、, 激, 励, 措, 施, 以, 及, 就, 业, 创, 业, 政, 策, ,, 线, 下, 举, 行, 创, 业, 大, 赛, 活, 动, 启, 动, 仪, 式, ,, 营, 造, 大, 众, 创, 业, 、, 万, 众, 创, 新, 的, 浓, 厚, 社, 会, 氛, 围, ,, 为, 大, 赛, 活, 动, 造, 势, 。, 符, 合, 条, 件, 的, 参, 赛, 人, 员, (, 团, 队, 或, 企, 业, ,, 下, 同, ), 可, 通, 过, 所, 在, 高, 校, 进, 行, 报, 名, 。, 另, 设, 大, 赛, 移, 动, 端, 报, 名, 入, 口, (, 微, 信, 公, 众, 平, 台, ), ,, 通, 过, 手, 机, 微, 信, 扫, 描, 二, 维, 码, 报, 名, 。, 大, 赛, 组, 委, 会, 将, 在, 对, 参, 赛, 者, 所, 报, 材, 料, 进, 行, 审, 核, 的, 基, 础, 上, ,, 确, 认, 参, 赛, 人, 员, 是, 否, 符, 合, 参, 赛, 资, 格, 。, (, 二, ), 第, 二, 阶, 段, :, 校, 园, 初, 赛, (, 11, 月, 16, 日, 至, 11, 月, 30, 日, ), 1, ., 初, 赛, 通, 过, 各, 高, 校, 自, 行, 征, 集, 创, 新, 创, 意, 项, 目, 并, 公, 开, 筛, 选, :, 高, 校, 统, 一, 安, 排, 参, 赛, 团, 队, 或, 企, 业, 完, 成, 创, 业, 计, 划, 书, 投, 送, (, 投, 送, 时, 请, 注, 明, “, 寻, 找, 新, 疆, 最, 美, 创, 客, 大, 赛, 项, 目, ”, 及, 姓, 名, 、, 团, 队, 、, 院, 校, 等, 字, 样, ), ,, 每, 个, 学, 校, 限, 投, 送, 5, 个, 优, 秀, 项, 目, 参, 加, 决, 赛, ;, 组, 委, 会, 将, 邀, 请, 自, 治, 区, 主, 流, 媒, 体, 和, 投, 资, 机, 构, 进, 入, 组, 织, 得, 力, 的, 高, 校, 开, 展, 校, 内, 创, 业, 对, 接, 服, 务, 。, 2, ., 参, 赛, 提, 交, 的, 材, 料, :, 《, 创, 业, 项, 目, 计, 划, 书, 》, ,, 同, 时, 可, 提, 供, 辅, 助, 材, 料, ,, 主, 要, 包, 括, :, 项, 目, 图, 片, (, 照, 片, 不, 少, 于, 2m, ,, jpg, 或, jpeg, 格, 式, ), 或, 者, 手, 绘, 工, 艺, 图, 、, 项, 目, 各, 部, 分, 创, 意, 说, 明, 视, 频, (, 大, 小, 在, 50m, 以, 内, ,, 格, 式, 为, wmv, 、, mp4, 文, 件, ,, 长, 宽, 应, 为, 512×384, ,, 音, 频, 为, 32kbps, ,, 视, 频, 比, 特, 率, 为, 360kbps, ), ,, 项, 目, 详, 细, 说, 明, 及, 创, 新, 创, 意, 的, 目, 的, 、, 方, 法, 、, 过, 程, 和, 效, 果, 等, 。, (, 注, 意, :, 以, 上, 图, 片, 及, 音, 视, 频, 需, 调, 试, 后, 上, 报, ), 。, (, 三, ), 第, 三, 阶, 段, :, 网, 络, 评, 选, 及, 决, 赛, (, 12, 月, 1, 日, 至, 12, 月, 15, 日, ), 1, ., 根, 据, 各, 高, 校, 提, 交, 项, 目, 情, 况, 评, 比, 出, 优, 秀, 者, 数, 名, (, 具, 体, 数, 量, 根, 据, 提, 交, 情, 况, 待, 定, ), 进, 入, 决, 赛, ,, 并, 安, 排, 集, 中, 路, 演, 。, 入, 围, 决, 赛, 阶, 段, 的, 项, 目, 将, 在, 比, 赛, 官, 方, 微, 信, 平, 台, 进, 行, 展, 示, ,, 供, 网, 民, 进, 行, 投, 票, 。, 决, 赛, 成, 绩, 分, 为, 网, 上, 投, 票, 和, 专, 家, 评, 分, 相, 结, 合, 的, 形, 式, 。, 2, ., 网, 络, 投, 票, 结, 果, (, 转, 发, 微, 信, 投, 票, ), 占, 决, 赛, 成, 绩, 的, 10, %, ,, 评, 委, 打, 分, 占, 决, 赛, 成, 绩, 的, 90, %, 。, 3, ., 大, 赛, 组, 委, 会, 将, 组, 织, “, 新, 疆, 最, 美, 创, 客, ”, 表, 彰, 大, 会, ,, 并, 在, 大, 赛, 微, 信, 平, 台, 集, 中, 展, 示, 所, 有, 获, 奖, 的, 创, 业, 项, 目, (, 前, 10, 名, ), ,, 给, 予, 证, 书, 和, 奖, 品, 奖, 励, ,, 并, 积, 极, 组, 织, 投, 资, 机, 构, 的, 对, 接, 和, 洽, 谈, 。, 4, ., 决, 赛, 流, 程, 决, 赛, 将, 通, 过, “, 自, 我, 展, 示, +, 现, 场, 答, 辩, +, 专, 家, 点, 评, ”, 的, 方, 式, 进, 行, 综, 合, 评, 审, 。, 参, 赛, 选, 手, 依, 据, 提, 交, 的, 《, 创, 业, 项, 目, 计, 划, 书, 》, 进, 行, 现, 场, 6, 分, 钟, 的, 自, 我, 展, 示, 和, 3, 分, 钟, 的, 评, 委, 互, 动, 答, 辩, ,, 最, 后, 由, 专, 家, 负, 责, 点, 评, 。, 决, 赛, 期, 间, ,, 大, 赛, 组, 委, 会, 将, 根, 据, 具, 体, 情, 况, 为, 参, 赛, 项, 目, 组, 织, 安, 排, 融, 资, 路, 演, 、, 股, 权, 众, 筹, 、, 产, 品, 众, 筹, 等, 活, 动, 。, 七, 、, 其, 他, 事, 项, (, 一, ), 本, 次, 大, 赛, 分, 别, 设, 优, 秀, 单, 项, 奖, 10, 名, 、, 优, 秀, 组, 织, 奖, 5, 名, 和, 优, 秀, 辅, 导, 老, 师, 奖, 5, 名, 。, (, 二, ), 相, 关, 事, 宜, 及, 比, 赛, 评, 分, 规, 则, 请, 关, 注, 大, 赛, 官, 方, 微, 信, 。, (, 三, ), 为, 了, 保, 护, 创, 新, 创, 意, 人, 的, 合, 法, 权, 益, ,, 避, 免, 知, 识, 产, 权, 纠, 纷, 的, 发, 生, ,, 请, 相, 关, 参, 赛, 选, 手, 对, 项, 目, 进, 行, 严, 格, 的, 自, 我, 审, 核, ,, 对, 是, 否, 侵, 犯, 他, 人, 知, 识, 产, 权, 进, 行, 充, 分, 检, 索, ,, 并, 在, 报, 名, 时, 由, 参, 赛, 选, 手, 签, 字, 确, 认, 。, (, 四, ), 大, 赛, 奖, 品, 如, 下, :, 第, 1, 名, :, 戴, 尔, 15, 寸, i7, 笔, 记, 本, 电, 脑, +, 价, 值, 10000, 元, 创, 业, 能, 量, 礼, 包, (, 包, 括, :, 创, 业, 相, 关, 法, 律, 咨, 询, 服, 务, ,, ppt, 及, 创, 业, 计, 划, 书, 服, 务, ,, 优, 先, 推, 荐, 申, 请, 乌, 鲁, 木, 齐, 天, 使, 投, 资, 基, 金, (, 基, 金, 池, 总, 额, 2, 亿, 元, ), ,, 优, 先, 推, 荐, 到, 国, 内, 知, 名, 众, 筹, 平, 台, 参, 加, 众, 筹, 、, 一, 线, 媒, 体, 免, 费, 宣, 传, 、, 大, 型, 商, 务, 平, 台, 对, 接, 、, 免, 费, 使, 用, 新, 疆, 大, 学, 信, 息, 技, 术, 创, 新, 园, 园, 区, 孵, 化, 资, 源, ), 。, 第, 2, -, 5, 名, :, 惠, 普, 激, 光, 打, 印, 机, +, 价, 值, 8000, 元, 创, 业, 能, 量, 礼, 包, (, 包, 括, :, 优, 先, 推, 荐, 申, 请, 高, 新, 区, 产, 业, 投, 资, 基, 金, (, 基, 金, 池, 总, 额, 1, 亿, 元, ), ,, 优, 先, 推, 荐, 到, 国, 内, 知, 名, 众, 筹, 平, 台, 参, 加, 众, 筹, 、, 一, 线, 媒, 体, 免, 费, 宣, 传, 、, 友, 好, 集, 团, 商, 务, 平, 台, 对, 接, 、, 免, 费, 使, 用, 新, 疆, 大, 学, 信, 息, 技, 术, 创, 新, 园, 园, 区, 孵, 化, 资, 源, ), 。, 第, 6, -, 10, 名, :, 惠, 普, 喷, 墨, 打, 印, 机, 一, 台, +, 价, 值, 6000, 元, 创, 业, 能, 量, 礼, 包, (, 包, 括, :, 优, 先, 推, 荐, 到, 国, 内, 知, 名, 众, 筹, 平, 台, 参, 加, 众, 筹, 、, 友, 好, 集, 团, 商, 务, 平, 台, 对, 接, 、, 免, 费, 使, 用, 新, 疆, 大, 学, 信, 息, 技, 术, 创, 新, 园, 园, 区, 孵, 化, 资, 源, ), 。, 其, 他, 奖, 项, 颁, 发, 获, 奖, 证, 书, 。, 如, 果, 有, 任, 何, 疑, 议, ,, 请, 咨, 询, 组, 委, 会, :, 电, 话, :, 0991, -, 4534256, (, 杨, 老, 师, ), 邮, 箱, :, yangchuanhai, @, 21cn, ., com, 附, 件, :, “, 寻, 找, 新, 疆, 最, 美, 创, 客, ”, 报, 名, 表, 新, 疆, 维, 吾, 尔, 自, 治, 区, 教, 育, 厅, 高, 等, 教, 育, 处, 2016, 年, 10, 月, 14, 日, 点, 击, 阅, 读, 原, 文, 下, 载, 附, 件
- 参考摘要
关 于 开 展 “ 寻 找 新 疆 最 美 创 客 ” 活 动 的 通 知 - 生成摘要
寻 找 新 疆 最 美 创 客 的 通 知
其中Rouge的得分如下:
rouge-1 = 0.41, rouge-2=0.189, rouge-L=0.3812·
分析生成出来的摘要可以看出,摘要和参考项目比起来,效果比较好,虽然没有生成概括性很强的话语,但是大都语言都是从正文中截取出来,进行组合的。且组合后的效果比较好。得分也是比较高。
总结
项目历程
刚开始是学习别人的关于指针生成网络的项目,看论文https://arxiv.org/pdf/1704.04368.pdf , 参考的项目运行过程中出现:编码格式问题,引用问题、版本支持问题等,需要进行稍微修改。最后还是能跑通,但自己跑完终究觉得有些地方不合理的地方。于是开始着手修改原来项目的工程框架,于是有了英文数据集下的指针生成网络。再后面觉得模型都可以进一步的修改,于是将正文和摘要进行特征提取的LSTM结构换成,能力更强的Transformer结构,输入层的修改,那么整个模型也需要随着修改,但整体的模型的框架还是没有变换的。再分析完参考项目的中文微博数据集的结果后,发现中文的结巴分词不好,分完后会出现很多oov的单词,而这些单词在平时的语句是挺常出现的,虽然原项目中有很好处理oov的方法,但是自己在想,换成单字粒度的输入,效果会不会更好。于是在变更完整个项目。做了单字粒度输入+ 修改成Transformer进行特征提取的模型的工作。
| 模型 | 数据 |
|---|---|
| 1-原指针生成网络 | cnn/dailymail |
| 2-原指针生成网络 | 微博中文数据集 |
| 3-新指针生成网络 | 新闻中文数据集(jieba分词) |
| 4-新指针生成网络 | 新闻中文数据集(单字分词) |
上面表格的数字表示时间顺序,表格展示的是整个项目的历程。
项目总结
不管是英文数据集,还是中文数据集,观察生成出来的结果,很大一部分是从原文中截取出来的,然后通过生成概率进行截取部分的组合,其实效果还是可以的,但是完成生成原文的高度概括的词汇,还是很难的,这和我们进行loss的计算有关,目前我们还没有找到一个比ROUGE更好的评估准则。一旦确定了这种评价方式,模型大都是从原文中截取答案的。
模型有时候出现以下的情况:
1、同义词会让句子的通顺程度降低
2、模型在截取原文后,会进行错误的组合,导致语句不通畅,语义不符合
展望
通过这次的项目,我觉得在进行文本摘要的过程中,在正文和摘要特征抽取的时候,加入预训练,让embedding学习到一些通用的语义,那么在生成语句的时候可以减少犯语法的错误,加入预训练势必需要高级的模型比如:bert、xlnet等模型,在摘要和文本atten到重要的信息,我觉得甚至可以学到更加抽象的语义,而不单单是从文中截取,评估准则我觉得是比较偏从文章中选取,那么有没有一种评价loss的机制是比较符合语义生成的呢? 未来的路还是很多种可能的哈哈~
原始论文 ↩︎