生存分析之Cox模型简述与参数求解
最近布置的任务里需要用到Cox模型去评估企业风险趋势分析并建模,讨论Cox模型在企业风险量化建模过程中有实际的意义;从知网关键词检索结果可以看出Cox模型主要集中使用在医学信息工程、金融统计学领域,比如:研究多对基因对癌症发病的影响、分析癌症病人存活时间、银行客户资产风险评估等;Cox模型对企业风险趋势预测是一个相对比较新的idea。
1、引子
先抛开定义、公式,直观地来看,假设你要研究某个对象(假如就是一个人)在时间t的生存概率,影响他生存概率的因素可以总结为两大类:
a:时间:也就是说随着时间的推进,一个人会逐渐衰老到死亡,不论外界环境如何时间都是必须考虑的因素。
b:主观因素:具象地来说一个不抽烟的人从常识上来看会比抽烟的人寿命要长,一个长期生活在核辐射下的人必定会比普通人有着更短的寿命,所以,这些主观的因素、特征也是研究一个人生存(死亡)概率一定要考虑的。
一句话来说:随着时间的推移,死亡概率一定会不断增大,同时受到主观因素的制约,至于该主观因素是提高死亡率还是降低死亡率,每个个体情况并不相同;
这两大因素我认为正是Cox基本模型的直观思想,大胆地写出这种思想下的表达式:风险率=关于时间的函数 x 关于主观因素的函数,至于每个部分的具体表达形式,之后Cox模型中会给出。
2、生存分析一些基础知识
1、生存分析:研究的是对象生存时间的分布情况,从而了解实验条件对生存时间的影响。这里的“生存时间”并不狭义地被认为是生物体的生存时间,也可以分析企业从建立到破产的经历、一件产品从出厂到发生故障的过程,之所以使用“生存”这个词,是因为这种分析技术常用于描述病人在接受某种治疗后,他们生存时间的分布情况,但在应用方面是绝不仅限于此的。
2、删失:这个词是censor音译过来的,所有没有观察到的或者没有观察完整的数据都叫做删失,其中删失又分为了左右删失和区间删失:
右删失:比如在对于癌症患者进行生存跟踪研究中,在观察结束时刻t某些患者依然存活,只知道的信息是这某些患者存活时间T>t,这就叫做右删失;
左删失:在进行研究前研究对象就发生了特征事件,这其实对于企业风险评估并没有什么帮助,因为如果在研究该企业前该企业就已经破产/倒闭了,那就没有任何研究的必要了,所以对左删失我也没有作过多的了解;
区间删失:在跟踪研究过程中,研究对象比如病人、企业中途一段时间不配合记录相关数据,这种即区间删失。
3、生存函数S(t):即![]() ,其中T是对象存活时间,意义是对象存活时间超过某一时间t的概率值。
,其中T是对象存活时间,意义是对象存活时间超过某一时间t的概率值。
4、累计死亡函数F(t):即![]() ,同上,意义是对象存活时间不超过某一时间t的概率值。它其实是时间T分布的累计分布函数(Cumulative Distribution Function),显然有
,同上,意义是对象存活时间不超过某一时间t的概率值。它其实是时间T分布的累计分布函数(Cumulative Distribution Function),显然有 ![]()
5、死亡概率函数f(t):根据概率论的知识,这个函数即累积分布的导数,意义是对象在某时刻t的一瞬间死亡的概率,精确的定义为:![]()
6、风险率:非常重要的概念,因为后续Cox模型基本假设的定义就是使用风险率来给出的,比如t时刻之前有100个存活病人,t时刻一瞬间有10个人死亡,这时候风险率为  ,Cox模型的因变量就是风险率值,精确的定义为:
,Cox模型的因变量就是风险率值,精确的定义为:![]() ,仔细看它与死亡概率函数的定义是有区别的,多了一个条件
,仔细看它与死亡概率函数的定义是有区别的,多了一个条件 ![]() 时。
时。
3、Cox模型基本形式
有了前面的铺垫,直接给出Cox模型的基本形式: ![]() (t与X就是之前提到的影响寿命的两大因素)
(t与X就是之前提到的影响寿命的两大因素)
符号解释:
1、 :是引子中提到的主观因素,在Cox模型中叫做协变量,不同的研究个体有不同的协变量,从公式中可以看出他对于风险率是有影响的。
:是引子中提到的主观因素,在Cox模型中叫做协变量,不同的研究个体有不同的协变量,从公式中可以看出他对于风险率是有影响的。
2、β:协参数,类似线性回归里的参数向量,他也是一个向量,向量的长度同主观因素的个数是相同的(类似线性回归特征个数和参数个数相同),我们建立模型过程大部分的精力就是放在求解协参数β上,求解用到了部分似然估计,具有一定的技巧性,也是看了很久才看懂,之后会给出求解过程。
3、![]() :风险基准函数,就是引子中提到的关于时间t的函数,这个函数只与时间t有关,与特征X无关,并且该模型中没有给出风险基准函数的基本形式,只要满足非负连续即可,当
:风险基准函数,就是引子中提到的关于时间t的函数,这个函数只与时间t有关,与特征X无关,并且该模型中没有给出风险基准函数的基本形式,只要满足非负连续即可,当 ![]() 为0时,Cox模型只与风险基准函数有关。
为0时,Cox模型只与风险基准函数有关。
Cox模型的前提条件(判断能否用来预测企业风险趋势的关键):
1、比例风险假定:各主观因素的作用不随时间的变化而变化;因此,该模型又叫做比例风险率模型(Proportional Hazard Model)。换句话说,如果某个因素对于企业发展的影响力在第一年、第二年、第三年等随着时间变化也在变化时,那么Cox模型就不可用了,在医学上的意义来说,如果在观察初对象A的死亡风险是对象B死亡风险的常数C倍,那么在之后任意一个时间点:A与B的死亡风险之比都应该是常数C。
2、对数线性假定:模型中的协变量与对数风险比呈现线性关系,将原模型简单变形即可得: ![]()
其他关于Cox的一些总结:
1、Cox比例风险回归模型其实非常类似于Logistic回归的,可以说Cox模型是加入了时间的Logistic回归,Logistic回归是删去了时间的Cox回归模型。
2、Cox是一个半参数模型,其中前半部分(与时间有关的函数)是完全没有给定的是属于非参部分,后半部分(关于主观因素的函数)是给定的线性函数,是属于参数部分,两者综合叫做半参数模型。
4、β 求解
之所以专门写参数β的求解是因为原论文在这里有一些小技巧在,直接看的话不容易看明白。
在引出似然函数之前,先说一个例子,如果有三个人,分别用三个特征向量来表示:![]() ,使三人分别在
,使三人分别在 ![]() 时刻处死亡;在t=1时刻,我们希望最大概率地使
时刻处死亡;在t=1时刻,我们希望最大概率地使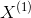 死亡,
死亡,![]() 最大概率地存活;在t=2时,
最大概率地存活;在t=2时,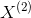 死亡,
死亡,![]() 存活;在t=3时,
存活;在t=3时,![]() 死亡。
死亡。
再用数学符号来描述一下刚才每个时刻的语言描述,t=1时:![]() ,其中
,其中 ![]() 就是Cox模型函数,指的是X1个体在t=1时刻一瞬间死亡的风险,max这个函数也就达到了"最大概率地使死亡,
就是Cox模型函数,指的是X1个体在t=1时刻一瞬间死亡的风险,max这个函数也就达到了"最大概率地使死亡,![]() 最大概率地存活"的目的;同理,t=2时:
最大概率地存活"的目的;同理,t=2时:![]() 没有问题;但是在t=3时,已经没有存活的对象,分母为0了,于是考虑在分母处加上与分子相同的一项作为平滑项。添加平滑项后的三个时刻的概率表示为:
没有问题;但是在t=3时,已经没有存活的对象,分母为0了,于是考虑在分母处加上与分子相同的一项作为平滑项。添加平滑项后的三个时刻的概率表示为:![]() 、
、![]() 、
、![]() 。
。
写出似然函数为:
下面对似然函数抽象化,假如有N个个体,第i个个体的特征向量为 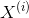 ,时间为
,时间为  ,可得表达式为:
,可得表达式为:
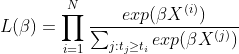
得到对数偏似然函数为 * 之所以叫偏似然函数(partial likelihood funtion)是因为我们把基准风险函数![]() 约去了,与时间无关
约去了,与时间无关
![ln[L(\beta)] = l(\beta) = \sum^{N}_{i=1} [ ln(exp(\beta X^{(i)})) - ln(\sum_{j:t_j\geq t_i}exp(\beta X^{(j)})) ]](http://img.e-com-net.com/image/info8/334dc867abab43229ae9aa9302c4cbca.gif)
![= \sum^{N}_{i=1}[ \beta X^{(i)} - ln(\sum_{j:t_j\geq t_i}exp(\beta X^{(j)})) ]](http://img.e-com-net.com/image/info8/baf59ef03f6f4b838d6b833d35d62b84.gif)
对β求偏导:
![\frac{\partial l(\beta)}{\partial \beta} = \sum^{N}_{i=1}[X^{(i)} - \frac{\sum_{j:t_j\geq t_i} X^{(j)}exp(\beta X^{(j)})}{\sum_{j:t_j\geq t_i} exp(\beta X^{(j)})}]](http://img.e-com-net.com/image/info8/40930089542e4094b5dc7d901e683ebf.gif)
最后令导数为0:![]() ,求解这个关于β的函数即可,此时求出的β就是在其他参数保持不变时能够使似然函数达到最大概率值的β取值。
,求解这个关于β的函数即可,此时求出的β就是在其他参数保持不变时能够使似然函数达到最大概率值的β取值。
5、更多思考
从似然函数中可以看出来Cox模型并没有考虑在同一时刻多个对象死亡的情况,假设都是在每个独立的时间死亡,这种情况其实主要在理论上会遇到,在现实中,可以通过提高时间精度来解决:例如如果按照天数来计算时间的话可以增加精度到小时,以此类推。如果不增加时间精度,也可以通过"Exact Method" 精确模型,这种方法原理是把在同一时刻死亡的对象做排列组合,给他们"强行排序",把所有可能的排序加到似然函数中,但是在数据样本相当大的时候作全排列时间复杂度相当高,这时候就只有用专业处理 tied times 的方法比如:Breslow、Efron;这些方法我也还没有研究过,以后如果需要用再说。
6、参考资料
[1] Cox D R . Regression Models and Life‐Tables[J]. Journal of the Royal Statal Society: Series B (Methodological), 1972, 34(2).
[2] 周艳巍. Cox模型及其应用[D]. 延边:延边大学理学院数学系, 2009.
[3] 百度百科. “Cox回归”词条[EB]/[OL].
https://baike.baidu.com/item/COX%E5%9B%9E%E5%BD%92%E6%A8%A1%E5%9E%8B/8894307?fr=aladdin
[4] 知乎 胡保强. "如何理解和使用生存分析?". https://zhuanlan.zhihu.com/p/49482538
[5] Wikipedia. "Proportional Hazards model". https://en.wikipedia.org/wiki/Proportional_hazards_model
[6] 邵斌. 关于Cox回归模型你需要知道的数学. http://blog.sciencenet.cn/blog-927304-876450.html