前向型神经网络之BPNN(附源码)
人工神经网课的大作业~~转自http://blog.csdn.net/heyongluoyao8/article/details/48213345
BPNN
人工神经网络
我们知道,人的脑袋具有很强的学习、记忆、联想等功能,虽然人类还没有完全搞明白人类的大脑,但是我们已经知道它的基本单位就是一个个神经元,即一个神经细胞,人的神级细胞个数大约为 1011 个,海兔大约为2000多个,数目越多就越复杂,处理信息的能力就越强。如下图所示,每个神经元由细胞体与突起构成,细胞体的结构与一般的细胞相似,包括细胞膜,细胞质与细胞核,突起是神经元胞体的延伸部分,按照功能的不同分为树突与轴突。树突的功能是接受冲动并将冲动传入细胞体,即接受其它神经元传来的信号,并将信号传给神经元它是传入神经末梢。而轴突将本神经元的冲动传递给其它的与之相连的神经元,因此它是输出神经末梢。
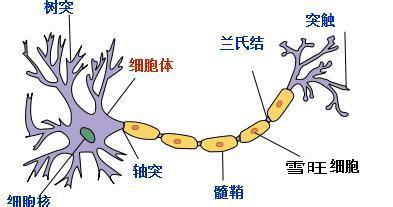
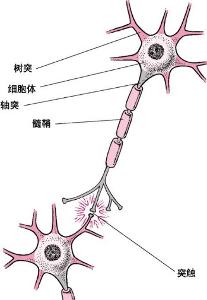
大脑的神经元便是通过这样的连接进行信号传递来处理信息的,每个神经元通过其接受的信号来使得其兴奋或抑制。神经元内部信号的产生、传导采用电信号的方式进行,而神经元之间、神经元与肌肉之间则通常采用化学递质方式进行传导,即上级神经元的轴突在有电信号传递时释放出化学递质,作用于下一级神经元的树突,树突受到递质作用后产生出点信号,从而实现了神经元间的信息传递。而神经元的兴奋与抑制是由接受到的递质决定,有些递质起兴奋作用,有些起抑制作用。当传入神经元的冲动经整合,使细胞膜电位升高,超过动作电位的阈值时,为兴奋状态,产生神经冲动,由轴突神经末梢传出。当传入神经元的冲动经整合,使得细胞膜电位降低,低于阈值时,为抑制状态,不产生神经冲动。
大脑可通过自组织、自学习,不断适应外界环境的变化。大脑的自组织、自学习性,来源于神经网络结构的可塑性,主要反映在神经元之间连接强度的可变性上。由于神经元结构的可塑性,突触的传递作用可增强与减弱,因此神经元具有学习与遗忘功能。
人工神经网络起源于上世纪40~50年代,它是在基于人脑的基本单元-神经元的建模与联结,模拟人脑神经系统,形成一种具有学习、联想、记忆和模式识别等智能信息处理的人工系统,称为人工神经网络(Artificial Neural Networks,简称ANN),它是一种连接模型(Connection Model)。1943年神经生物学家MeCulloch与青年数学家Pitts合作,提出了第一个人工神经网络模型,并在此基础上抽象出神经元的数理模型(即神经元的阈值模型,超过阈值则兴奋,否则抑制),被称为MP模型(名字命名),这是ANN的启蒙阶段,ANN正式进入研究阶段。1958年Rosenblatt在原有的MP模型的基础上增加了学习机制,他提出的感知器模型,首次把神经网络理论付诸于工程实现,ANN研究迎来第一次高潮期。1969年出版的轰动一时的《Perceptrons》一书指出简单的线性感知器的功能是有限的,它无非解决线性不可分的而分类问题,如简单的线性感知器不能实现“异或”的逻辑关系,加上神经网络就和黑夹子一样,很多东西不透明,模型的解释性不强,参数过多,容易出错,容易过拟合,无法保证全局最优等问题,同时70年代集成电路和微电子技术的迅猛发展,使得传统的Von Neumenn计算机进入全盛时期,基于逻辑符号处理方法的人工智能得到了迅速发展并取得了显著的成果。ANN进入了长达10年的低潮期。1982年,美国科学院发表了著名的Hopfield网络模型的理论,不仅对ANN信息存储和提取功能进行了非线性数学概括,提出了动力方程和学习方程,使得ANN的构造与学习有了理论指导。这一研究激发了ANN的研究热情。1986年,由Rumelhat和McChekkand等16位作者参加撰写的《Parallel Distributed Processing: Exploration in Microstructures of Cognition》一书,建立了并行分布式处理理论,并提出了BP算法,解决了长期以来ANN中的权值调整问题没有有效解决方法的难题,可以求解感知器所不能解决的问题,回答了《Perceptrons》一书中关于神经网络局限性的问题,从实践中证实了ANN的有效性。BP算法产生了深远而广泛的影响,从至ANN的研究进入了蓬勃发展期。后来学者与研究者们又不断提出了RNN(Recurrent Neural Networks,递归神经网络)以及Deep Learning(深度学习)等模型。
本文主要对前向神经网络中的BP网络进行讲解.
人工神经网络拓扑结构
ANN使对大脑信息处理机制的模拟,是由大量简单的神经元广泛地互相连接而形成的复杂网络系统。它反映了人脑功能的许多基本特性,但它并不是人脑神经网络系统的真实写照,人脑神经系统比ANN要复杂地多,而ANN只是对其作某种简化抽象和机制模拟。ANN的目的在于探索人脑加工、存储和处理信息的机制,进而研制基本具有人类智能的机器。ANN是一个高度复杂的非线性动力学系统。虽然每个神经元的结构和功能十分简单,但大量神经元构成的网络系统的功能是强大的,能够以任何精度去逼近线性与非线性函数.
ANN中的每一个节点作为一个神经元,是对生物神经元的仿照,如下图:
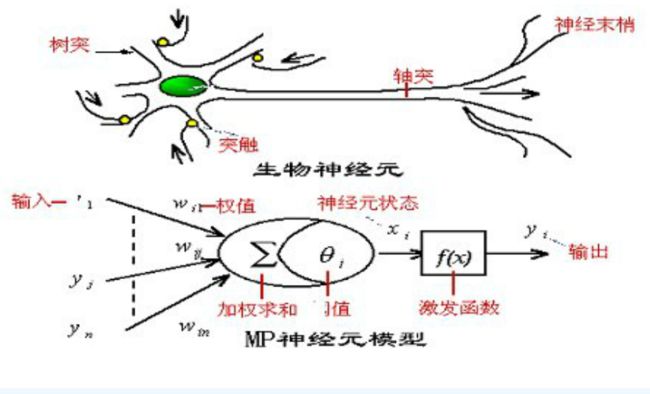
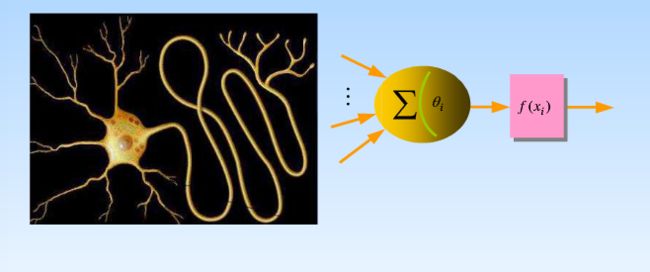
神经元 i 的输入为 y=(y1,...,yn) ,输出为 yi ,通过在神经元加权求和作用于激活函数再输出:
其中 f 为激活函数. 每一神经元的输出为0或1,表示“抑制”或“兴奋”状态. 具体根据使用的激活函数而定.
上面是一个神经元的结构与原理,那么将多个神经元排列组成便得到了ANN的结构,如图:
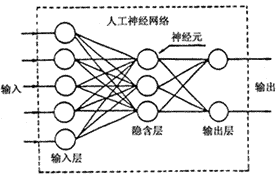
人工神经网络一般包含输入层、隐含层与输出层这三层结构,其中隐含层可包括多层,如下图二层隐藏层神经网络:
相同层之间的节点无连接,层与层之间的节点采用全连接结构,输入层对于输入的元素不作任何处理,即经输入层节点的输入与该节点输出相同,除了输入层的节点外的节点都有一个激活函数,这些节点的每个节点都对输入矢量的各个元素进行相应的加权求和,然后使用激活函数作用于上面作为输出。
那么网络便可简化为输入、权值、偏置、输出矩阵:
其中 W 矩阵与 b 向量均有有 T−1 个, T 为网络的层数. 网络节点之间的连接强度通过连接权值来反映.
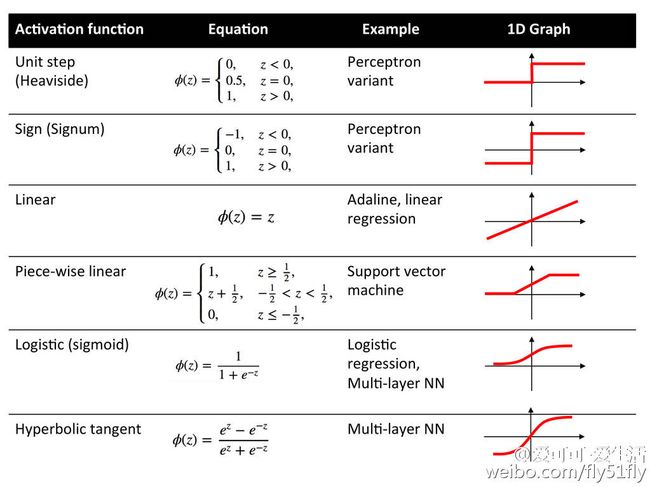
激活函数
除了输出层节点外,每个节点都有一个激活函数,常用的激活函数如下 :
神经网络的类型
神经网络可分类以下四种类型:
- 前向型
BP前向神经网络是中广为应用的一种网络,其原理与算法也是某些其它网络的基础,除此之外还有辐射基函数(RBF)神经网络. - 反馈型
Hopfield神经网络用于非线性动力学问题分析,已在联想记忆和优化计算中得到成功的应用. - 随机型
具有随机性质的模拟退火(SA)算法解决了优化计算过程陷于局部极小的问题,并已在神经网络的学习及优化计算中得到成功的应用. - 竞争型
竞争型网络的特点是能识别环境的特征,并自动聚类。广泛用于自动控制、故障诊断等各类模式识别中.
神经网络的学习方法
当一个神经网络的拓扑结构确定之后,为了使它具有某种职能特性,必须对它进行训练。通过向环境学习获取知识并改进自身性能时神经网络的一个重要特点。学习方法归根结底就是网络连接权值的调整方法,修改权值的规则称为学习算法。学习方式(根据环境提供信息量的多少)包括:
- 监督学习(有教师学习)
这种学习方式需要外界存在一个”教师”,它可对给定一组输入提高应有的输出结果,这组已知的输入输出数据称为训练样本集,网络可根据已知输出与实际输出之间的差别来调节网络参数. - 无监督学习(无教师学习)
无监督学习顾名思义就是没有教师进行指导的学习,网络完全按照环境提供数据的某些统计规律来调节自身参数货结构(这是一种自组织过程),以表示出外部输入的某种固有特性,如聚类或某种统计上的分布特征. - 再励学习(强化学习)
这种学习方式介于前面所讲的两种学习方式之间,外部环境对系统输出结果只给出评价信息(奖或罚)而不是给出正确答案. 学习系统通过强化那些受奖的动作来改善自身的性能.
下面对多层前馈网络的一种学习方法,即反向误差传播算法,进行讲解.
BP算法原理
BP全称为Back Propagation,意思为反向传播,该方法是用来对人工神经网络进行优化的,即误差反向传播算法。
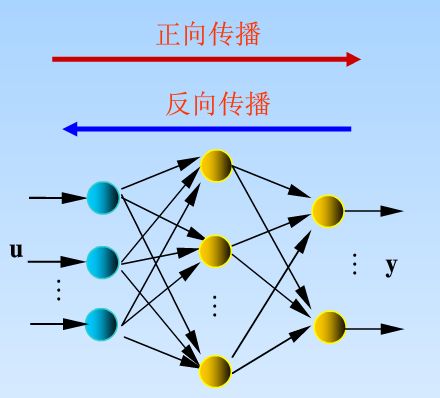
它属于有教师指导的学习方式。包括两个过程:
- 正向传播
输入信号从输入层经隐含层,传至输出层的过程. - 反向误差传播
将误差从输出层反向传至输入层,并通过梯度下降算法来调节连接权值与偏置值的过程.
假设训练样本空间 Ω 中有 n 个训练样本,分别为 Si={xi1,...,xim,y^i1,...,y^il},i=1,...,n ,样本 i 通过神经网络后的输出值(即预测值)为 yi={yi1,...,yil} ,第 i 个训练样本的特征向量 xi 维度为 m ,预测值向量 yi 与真实值向量 y^i 向量维度均为 l .
假设神经网络有T层结构,其中第1层为输入层,第T层为输出层,第2到第T-1层为隐藏层,第t与第t+1层之间的连接权值矩阵为 Wt=[wtst×st+1],t=1,...,T−1 ,第t与第t+1层之间的偏置值为 bt=(bt1,...,btst) ,其中 st,st+1 分别表示第 t 与 t+1 层节点的个数.
BP算法使用梯度下降算法对网络中的各权值进行更新,如果使用批量更新算法,设batch的大小为p,采用平方误差和计算公式,那么一次batch的总误差为:
其中式中的 12 是为了计算方便. 一般我们使用平均平方误差和作为目标函数,即目标函数为:
按照梯度下降公式,每一次batch对各层之间的连接权值与偏置的更新方程为:
其中 α∈(0,+∞) 为学习速率, i 表示第 t 层的第 i 个节点, j 表示第 t+1 层的第 j 个节点.
因此神经网络的求解便落在求解连接权值矩阵 W 与偏置值 b 上面,通过梯度下降算法,我们需要求取 wtij 与 btj 的偏导数.
因为:
设
其中 yij 表示第 i 个训练样本的预测值的第 j 个分量, fT 表示第 T 层的激活函数,可以是sigmoid函数也可以是tanh函数等. T−1 表示网络的第 T−1 层, sT−1 表示第 T−1 层的节点的个数, oT−1ik 表示第 i 个训练样本在第 T−1 层第 k 个节点的输出值, wT−1kj 表示 T−1 层第 k 个节点到 T 层第 j 个节点之间的连接权值, ITij 为第 i 个训练样本时第 T 层第 j 节点的输入, ()′ 表示向量的转置.
那么对于最后一层隐藏层与输出层之间的连接权值矩阵与偏置向量,有:
对于sigmoid函数 f′=f(1−f) ,对于tanh函数 f′=1−f2 .
令
那么第 T−1 到第 T 层之间的连接权值矩阵与偏置值更新方程为:
对于第 T−2 到第 T−1 层之间:
令
那么第 T−2 到第 T−1 层之间的连接权值矩阵与偏置值更新方程为:
那么第 t 到第 t+1,1≤t≤T−2) 之间的连接权值矩阵与偏置值均按照上面的方程进行更新。
第 i 个样本在第一层(输入层)的输出 o1ik 即为第 i 个样本输入矢量的第 k 个输入分量,即为 xik .
算法步骤
- 首先使用随机函数对每一层间的连接权值矩阵和偏置向量进行随机初始化.
- 依次使用一个训练样本对网络进行训练,并按照上面的公式计算每个样本的 Δti,t=1,...,T−1
- 训练 p 个样本后(一次batch),按照更新方程对 W 与 b 进行更新.
- 重复步骤2~3,直到误差小于设定的阈值或者达到设定的batch次数.
BP学习算法相关问题
- 实现输入/输出的非线性映射
若网络输入、输出层的节点个数分别是m、l个,那么该网络实现了从m维到l维欧式空间的映射:
T:Rm→Rl
可知网络的输出是岩本输出在 L2 范数意义下的最佳逼近. 通过若干简单非线性处理单元的复合映射,可获得复杂的非线性处理能力. - BP学习算法的数学分析
BP算法使用梯度下降法进行参数优化,把一组样本的I/O问题,变味非线性优化问题,隐含层使优化问题的可调参数增加,使解更精确. - 全局逼近网络
BP网络时全局逼近网络,即 f(x) 在 x 的相当大的域为非零值. - 学习步长 α