ffmpeg lib介绍
ffmpeg lib介绍
我在找 FFmpeg 的 lib 使用的教程,后来我找到了一个 “如何1k行代码写一个播放器” 的教程。
但不巧的是这个项目已经不维护了,所以我才决定写这个教程。
这里大部分的代码都是 c 写的,但是不用担心:你可以非常容易的理解它。
FFmpep libav 有很多语言的版本,比如 python、go,即使你对这些语言不熟悉,你仍然可以通过 ffi 来支持它(这是一个Lua的例子)。
我将会快速的教会大家认识什么是视频、音频、编解码和容器,然后我们尝试使用 FFmpeg 命令行,最终用代码实现一些功能。当然你可以随时跳过这个部分 [艰难的学习FFmpeg](#艰难的学习 FFmpeg)。
很多人都说对于传统的TV来说,视频才是互联网的未来,所以FFmpeg是值得学习的一个工具。
目录
•介绍•视频 - 你可以看见什么!•音频 - 你可以听见什么!•编码 - 压缩数据•容器 - 整合音频和视频的地方•FFmpeg - 命令行•FFmpeg 命令行工具 101•通用的视频操作•转码•转封装•转码率•转分辨率•自适应流•超越•艰难的学习 FFmpeg•章节0 - 著名的hello world•FFmpeg libav 架构•章节1 - 同步音频和视频•章节2 - 重新封装•章节3 - 转码
介绍
视频 - 你可以看见什么!
如果在一个特定的时间内播放一组图片(比如每秒24张图片),你将有一个运动错觉 。总而言之这是视频的基础概念: 一组图片/特定运行速率的帧.
当代插画 (1886)
音频 - 你可以听见什么!
尽管一个没有声音的视频可以表达很多感受和情绪,但如果我们加入音频会带来更多的愉悦体验。
声音是指压力波通过空气或者任何其他介质(例如气体、液体或者固体)传播的震动。
在数字音频系统中,麦克风将声音转换为模拟电信号,然后通常使用脉冲编码调制(PCM)的模数转换器(ADC)将模拟信号转换为数字信号。
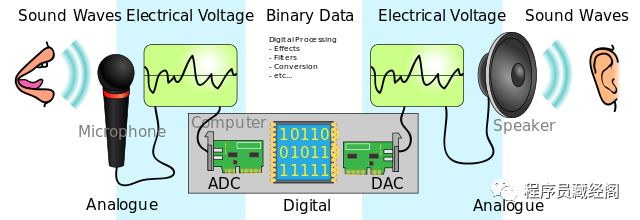
audio analog to digital
图片来源
编解码 - 压缩数据
CODEC是一种压缩或解压缩数字音频/视频的电子软件。它将原始(未压缩的)数字音频/视频转换为压缩格式,反之亦然。
https://en.wikipedia.org/wiki/Video_codec
但是如果我们我们打包数百万张图片到一个电影时,我们会获得一个很大的文件。让我们来计算一下:
假如我们创建一个1080x1920 (高x宽)的视频,每个像素有3 bytes,每秒24帧(每秒播放24张图片,这些图片给我们 16,777,216 种不同的颜色),视频时长为 30 分钟。
toppf = 1080 * 1920 //每帧所有的像素点
cpp = 3 //每个像素的大小
tis = 30 * 60 //时长秒
fps = 24 //每秒帧数
required_storage = tis * fps * toppf * cpp
这个视频需要大约 250.28G 的存储空间,1.11Gbps 的带宽播放才能不卡顿。这就是我们为什么需要编解码的原因。
容器 - 整合音视频的地方
容器或者封装格式描述了不同的数据元素和元数据是如何结合一起的。https://en.wikipedia.org/wiki/Digital_container_format
一个文件包含了所有的流(有音频和视频),并且也提供了音视频同步和通用元数据同步的方式,比如标题、分辨率等等。
通常我们可以通过文件的后缀来判断文件格式:比如 video.webm 是一个 webm 容器格式。
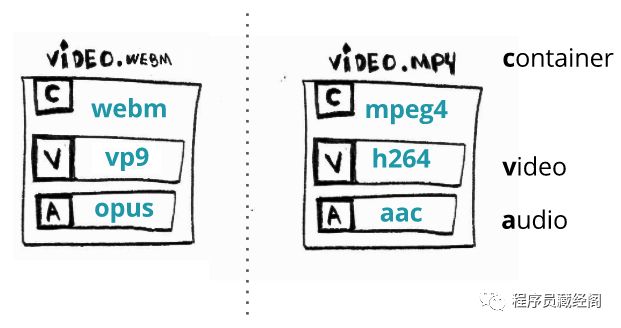
container
FFmpeg - 命令行
一个完整的并且跨平台的解决方法,包括对音视频流的转换等。
我们使用一个非常好的工具 FFmpeg 去播放多媒体文件。你可能直接或者间接的在使用了(你用过 Chrome 吗?)
命令行 ffmpeg 是一个简单而强大的二进制。例如,下面的命令你可以转换一个 mp4 格式到 avi 的格式:
$ ffmpeg -i input.mp4 output.avi
我们仅仅做了重新封装,把一个容器转换为另外一个容器。FFmpeg 也可以做一些编解码的工作,但是我们稍后在讨论它。
FFmpeg 命令行工具 101
FFmpeg 有一个非常完善的文档来说明它如何使用和工作的。
为了更简单的理解,FFmpeg 命令行需要下面的几个参数: ffmpeg {1} {2} -i {3} {4} {5}:
1.全局参数2.输入参数3.输入内容4.输出选项5.输出内容
选项 2、3、4、5 可以可以根据自己的需求添加参数。下面有一个非常好理解的示例:
# WARNING: 这个文件大约 300MB
$ wget -O bunny_1080p_60fps.mp4 http://distribution.bbb3d.renderfarming.net/video/mp4/bbb_sunflower_1080p_60fps_normal.mp4
$ ffmpeg \
-y \ # 全局参数
-c:a libfdk_aac -c:v libx264 \ # 输入选项
-i bunny_1080p_60fps.mp4 \ # 输入内容
-c:v libvpx-vp9 -c:a libvorbis \ # 输出选项
bunny_1080p_60fps_vp9.webm # 输出内容
这个命令行作用是转换一个 mp4 文件(包含了 aac 格式的音频流,h264 编码格式的视频流),我们将它转换为 webm,并且改变了音视频的编码格式。
我们可以简化命令行,因为 FFmpeg 会猜测你的意图。例如我们仅仅输入 ffmpeg -i input.avi output.mp4 ,FFmpeg 意图要编码为 output.mp4 ?
Werner Robitza 写了一篇 关于 ffmpeg 编码和编辑的教程。
通用的视频操作
当我对音视频做编解码的时候,其实会做一系列的操作。
转码
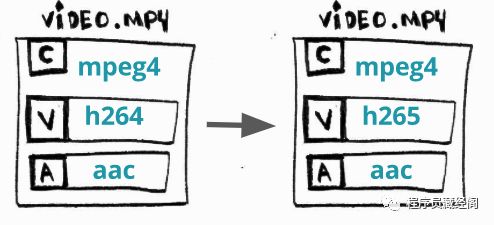
transcoding
是什么? 将一个视频流或者音频流从一个编码格式转换到另一个格式
为什么? 有时候有些设备(TV,智能手机,游戏机等等)不支持 X ,但是支持 Y和一些更新的编码方式,这些方式能提供更好的压缩比
如何做? 转换 H264(AVC)到 H265(HEVC)
$ ffmpeg \
-i bunny_1080p_60fps.mp4 \
-c:v libx265 \
bunny_1080p_60fps_h265.mp4
转封装
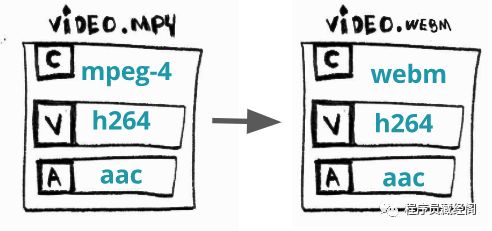
transmuxing
是什么? 将视频的从某一格式(容器)转换成另外一个
为什么? 有时候有些设备(TV,智能手机,游戏机等等)已经不支持 X ,但是支持 Y和一些新的容器提供了更现代的特征
如何做? 转换一个 mp4 为 webm
$ ffmpeg \
-i bunny_1080p_60fps.mp4 \
-c copy \ # 告诉ffmpeg跳过编解码的过程
bunny_1080p_60fps.webm
转码率

transrating
是什么? 改变视频码率。
为什么? 人们尝试用手机 2G 的网络来观看视频,也有用 4K 的电视来观看视频,我们需要提供不同的码率来满足不同的需求。
如何做? 生成视频码率在 3856k 和 964k 之间浮动。
$ ffmpeg \
-i bunny_1080p_60fps.mp4 \
-minrate 964K -maxrate 3856K -bufsize 2000K \
bunny_1080p_60fps_transrating_964_3856.mp4
我们通常使用改变码率和改变大小来做编解码。Werner Robitza 写了另外一片文章做参考 关于 FFmpeg 码率控制。
转分辨率
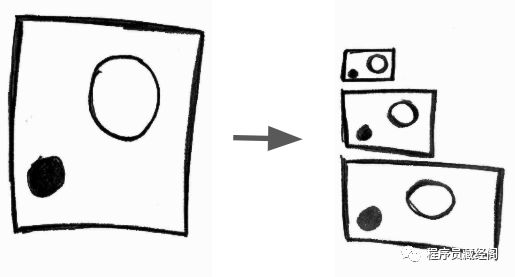
transsizing
是什么? 将视频从一个分辨率转为不同的分辨率。
为什么? 原因与转码率相同
如何做? 从 1080p 转成 480p
$ ffmpeg \
-i bunny_1080p_60fps.mp4 \
-vf scale=480:-1 \
bunny_1080p_60fps_transsizing_480.mp4
自适应流

adaptive streaming
是什么? 生成很多不同分辨率的视频,并且把视频切分成块文件,最终通过http来分发不同分辨率的视频块。
为什么? 为了提供一个更加灵活的观看体验在不同的终端和网络环境,比如用智能手机或者4K电视都能轻松的调整码率观看。
如何做? 用 DASH 创建一个自适应的 WebM。
# 视频流
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:v libvpx-vp9 -s 160x90 -b:v 250k -keyint_min 150 -g 150 -an -f webm -dash 1 video_160x90_250k.webm
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:v libvpx-vp9 -s 320x180 -b:v 500k -keyint_min 150 -g 150 -an -f webm -dash 1 video_320x180_500k.webm
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:v libvpx-vp9 -s 640x360 -b:v 750k -keyint_min 150 -g 150 -an -f webm -dash 1 video_640x360_750k.webm
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:v libvpx-vp9 -s 640x360 -b:v 1000k -keyint_min 150 -g 150 -an -f webm -dash 1 video_640x360_1000k.webm
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:v libvpx-vp9 -s 1280x720 -b:v 1500k -keyint_min 150 -g 150 -an -f webm -dash 1 video_1280x720_1500k.webm
# 音频流
$ ffmpeg -i bunny_1080p_60fps.mp4 -c:a libvorbis -b:a 128k -vn -f webm -dash 1 audio_128k.webm
# DASH 格式
$ ffmpeg \
-f webm_dash_manifest -i video_160x90_250k.webm \
-f webm_dash_manifest -i video_320x180_500k.webm \
-f webm_dash_manifest -i video_640x360_750k.webm \
-f webm_dash_manifest -i video_640x360_1000k.webm \
-f webm_dash_manifest -i video_1280x720_500k.webm \
-f webm_dash_manifest -i audio_128k.webm \
-c copy -map 0 -map 1 -map 2 -map 3 -map 4 -map 5 \
-f webm_dash_manifest \
-adaptation_sets "id=0,streams=0,1,2,3,4 id=1,streams=5" \
manifest.mpd
PS: 我拿了一个例子 播放自适应 WebM 的说明
超越
这里有很多FFmpeg其他的用途很多FFmpeg其他的用途。
我使用 FFmpeg 结合 iMovie 为 YouTube 编辑视频,其实你也可以更专业的用它。
艰难的学习 FFmpeg
Don’t you wonder sometimes 'bout sound and vision? David Robert Jones
既然用 FFmpeg 做视频的编解码如此强大,我们如何在程序里使用它呢?
FFmpeg 有几个lib库是可以集成到我们程序里的。通常在你安装FFmpeg的时候,这些库是自动安装好的。我们将这些库统一叫做 FFmpeg libav。
这个标题是对 Zed Shaw 的一系列丛书学习X的困难,特别是学习C语言困难。
章节 - 著名的 hello world
这里说的 hello world 实际上不会在终端里输出 “hello world”
而是输出视频信息,信息包括:时长、分辨率、音频轨道。最后我们将解码一些帧,并且保存为图片。
FFmpeg libav 架构
在我们开始学习之前,我们先了解一下FFmpeg libav 架构的工作流程,和各个组建之间的工作方式。
下面有一张解码视频的处理流程:
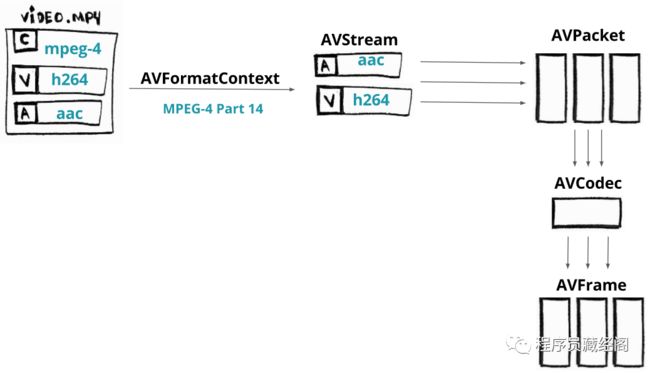
ffmpeg libav architecture - decoding process
首先我们需要加载媒体文件到 AVFormatContext 组件(容器这个词你认为是文件格式就好了),它并不是真正的加载整个文件,它只是加载了文件头。
首先我们加载了容器的头信息,这样我们就可以访问媒体文件流(流只是最基本的音频和视频数据)。
每个流对于AVStream都是有用的。
流只是数据流的一个昵称
Suppose our video has two streams: an audio encoded with AAC CODEC and a video encoded with H264 (AVC) CODEC. From each stream we can extract pieces (slices) of data called packets that will be loaded into components named AVPacket.
假如我们的视频文件有两个流:一个是 AAC 的音频流,一个是 H264(AVC)视频流。我们可以从每一个流中提取出数据包,这些数据包将被加载到 AVPacket。
数据包中的数据仍然是被编码的(也就是被压缩的),我们为了解码这些数据,我们需要将这些数据给到 AVCodec。
AVCodec将解压这些数据到 AVFrame,最后我们将得到解码后的帧。这个处理流程适用于视频流和音频流。
构建要求
当我们编译或者运行例子时,很多人都会碰到问题,所以我们用docker来构建我们的开发和运行环境。我们将使用一个兔巴哥的视频来作为示例,如果你没有这个视频,你可以运行 make fetch_small_bunny_video 来获取。
章节 0 - 代码一览
展示代码并执行。
$ make run_hello
我们将跳过一些细节,不过不用担心,我的代码都在Github上。
首先我们为 AVFormatContext 分配内存,我们将获得容器的信息。
AVFormatContext *pFormatContext = avformat_alloc_context();
我们将打开一个文件,利用 AVFormatContext 来读取文件的头信息.
打开文件经常用到方法 avformat_open_input。avformat_open_input 需要参数 AVFormatContext,媒体文件和两个参数,如果AVInputFormat为NULL,FFmpeg将猜测格式。AVDictionary 参数(是一个解封装参数)
avformat_open_input(&pFormatContext, filename, NULL, NULL);
我们可以打印视频的格式和时长:
printf("Format %s, duration %lld us", pFormatContext->iformat->long_name, pFormatContext->duration);
为了访问数据流,我们需要从媒体文件中读取数据。函数 avformat_find_stream_info 是做这个的。pFormatContext->nb_streams 将获取所有的流信息,并且通过 pFormatContext->streams[i] 获取到指定的流数据(AVStream)。
avformat_find_stream_info(pFormatContext, NULL);
现在我们使用循环来获取所有流数据:
for (int i = 0; i < pFormatContext->nb_streams; i++)
{
//
}
每一个流都是 AVCodecParameters 类,这个类描述了流的编码属性。
AVCodecParameters *pLocalCodecParameters = pFormatContext->streams[i]->codecpar;
我们通过 avcodec_find_decoder 来查看编码的属性,这个函数不仅能找到codec id,并且会返回 AVCodec类型的变量,这个组件能让我们知道如何去编解码这个流。
AVCodec *pLocalCodec = avcodec_find_decoder(pLocalCodecParameters->codec_id);
我们现在可以打印一些 codecs 的信息。
// 只要视频和音频
if (pLocalCodecParameters->codec_type == AVMEDIA_TYPE_VIDEO) {
printf("Video Codec: resolution %d x %d", pLocalCodecParameters->width, pLocalCodecParameters->height);
} else if (pLocalCodecParameters->codec_type == AVMEDIA_TYPE_AUDIO) {
printf("Audio Codec: %d channels, sample rate %d", pLocalCodecParameters->channels, pLocalCodecParameters->sample_rate);
}
// 通用参数
printf("\tCodec %s ID %d bit_rate %lld", pLocalCodec->long_name, pLocalCodec->id, pCodecParameters->bit_rate);
当我们编码的时候,我们首先要为 AVCodecContext 分配内存,因为我们存放处理解码/编码的内容。然后我们使用 avcodec_parameters_to_context 来为 AVCodecContext 赋值。
当我们完成赋值,我们就可以调用 avcodec_open2 来使用这个变量了。
AVCodecContext *pCodecContext = avcodec_alloc_context3(pCodec);
avcodec_parameters_to_context(pCodecContext, pCodecParameters);
avcodec_open2(pCodecContext, pCodec, NULL);
首先我们要为 AVPacket 和 AVFrame 来分配内存,然后我们将从流中读取数据包并且解码数据包为帧数据。
AVPacket *pPacket = av_packet_alloc();
AVFrame *pFrame = av_frame_alloc();
我们使用函数 av_read_frame 来填充包数据。
while (av_read_frame(pFormatContext, pPacket) >= 0) {
//...
}
我们使用函数 avcodec_send_packet 来把原数据包(未解压的帧)发送给解码器。
avcodec_send_packet(pCodecContext, pPacket);
我们使用函数 avcodec_receive_frame 来接受原数据帧(解压后的帧)从解码器。
avcodec_receive_frame(pCodecContext, pFrame);
我们可以打印 frame 的编号,包括 PTS、DTS、frame类型等等都可以打印。
printf(
"Frame %c (%d) pts %d dts %d key_frame %d [coded_picture_number %d, display_picture_number %d]",
av_get_picture_type_char(pFrame->pict_type),
pCodecContext->frame_number,
pFrame->pts,
pFrame->pkt_dts,
pFrame->key_frame,
pFrame->coded_picture_number,
pFrame->display_picture_number
);
最后我们可以保存我们解码出来的帧到一个简单的灰色图片。这个处理过程非常简单,我们使用 pFrame->data 查看 planes Y, Cb and Cr 相关数据,但是我们只取0(Y)数据保存为灰色图片。
save_gray_frame(pFrame->data[0], pFrame->linesize[0], pFrame->width, pFrame->height, frame_filename);
static void save_gray_frame(unsigned char *buf, int wrap, int xsize, int ysize, char *filename)
{
FILE *f;
int i;
f = fopen(filename,"w");
// writing the minimal required header for a pgm file format
// portable graymap format -> https://en.wikipedia.org/wiki/Netpbm_format#PGM_example
fprintf(f, "P5\n%d %d\n%d\n", xsize, ysize, 255);
// writing line by line
for (i = 0; i < ysize; i++)
fwrite(buf + i * wrap, 1, xsize, f);
fclose(f);
}
现在我们有一张2MB大小的图片:

saved frame
章节 1 - 同步音频和视频
播放器 - 一个年轻的 JS 开发者写了一个新的 MSE 的视频播放器。
在我们编写一个 编解码的例子 之前,我们来谈谈时间线,或者说播放器如何知道在正确的时间来播放每一帧。
再上一个例子中,我们可以在这看到我们保留了一些帧:
frame 0
frame 1
frame 2
我们设计一个播放器的时候,我们需要在合适的时间播放每一帧。否则,我们很难快乐的去观看一个视频,因为在观看的过程中很可能太快或者太慢。
因此我们需要有一些策略能平滑的播放每一帧。所以每一帧都有一个播放时间戳(PTS),PTS是一个持续增长的数字,可以通过一个时间基数除以**帧率(fps)**来获得。
这个很容易懂,让我们来看几个例子就很容易懂了,我们来模仿几个场景。
比如 fps=60/1 , timebase=1/60000, 每一个 PTS 的增长 timescale / fps = 1000,因此每一帧 PTS 的时间如下(假设开始为0):
•frame=0, PTS = 0, PTS_TIME = 0•frame=1, PTS = 1000, PTS_TIME = PTS * timebase = 0.016•frame=2, PTS = 2000, PTS_TIME = PTS * timebase = 0.033
几乎相同的场景,我们把 timebase 改成了 1/60。
•frame=0, PTS = 0, PTS_TIME = 0•frame=1, PTS = 1, PTS_TIME = PTS * timebase = 0.016•frame=2, PTS = 2, PTS_TIME = PTS * timebase = 0.033•frame=3, PTS = 3, PTS_TIME = PTS * timebase = 0.050
例如 fps=25,timebase=1/75,PTS 的增长将会是 timescale / fps = 3,如下:
•frame=0, PTS = 0, PTS_TIME = 0•frame=1, PTS = 3, PTS_TIME = PTS * timebase = 0.04•frame=2, PTS = 6, PTS_TIME = PTS * timebase = 0.08•frame=3, PTS = 9, PTS_TIME = PTS * timebase = 0.12•…•frame=24, PTS = 72, PTS_TIME = PTS * timebase = 0.96•…•frame=4064, PTS = 12192, PTS_TIME = PTS * timebase = 162.56
现在通过 pts_time 我们找到一个方式去同步音频的 pts_time。FFmpeg libav 提供了接口:
•fps = AVStream->avg_frame_rate•tbr = AVStream->r_frame_rate•tbn = AVStream->time_base
出于好奇,我们的编码顺序 DTS 是(帧:1,6,4,2,3,5),但是我们的播放顺序是(帧:1,2,3,4,5)。同时我们可以看到B帧相对于P帧和I帧是比较节约空间的。
LOG: AVStream->r_frame_rate 60/1
LOG: AVStream->time_base 1/60000
...
LOG: Frame 1 (type=I, size=153797 bytes) pts 6000 key_frame 1 [DTS 0]
LOG: Frame 2 (type=B, size=8117 bytes) pts 7000 key_frame 0 [DTS 3]
LOG: Frame 3 (type=B, size=8226 bytes) pts 8000 key_frame 0 [DTS 4]
LOG: Frame 4 (type=B, size=17699 bytes) pts 9000 key_frame 0 [DTS 2]
LOG: Frame 5 (type=B, size=6253 bytes) pts 10000 key_frame 0 [DTS 5]
LOG: Frame 6 (type=P, size=34992 bytes) pts 11000 key_frame 0 [DTS 1]
章节 2 - 重新封装
重新封装的意思就是把一种格式转换为另一种格式。例如:我们可以用 FFmpeg 把 MPEG-4 转换成 MPEG-TS。
ffmpeg input.mp4 -c copy output.ts
我们在不编解码的情况下(-c copy)来对 mp4 做解封装,然后封装为 mpegts 文件。如果不用 -f 来指定的文件格式的话,ffmpeg 会根据文件扩展名来猜测文件格式。
通常 FFmpeg 工作流或者说是 libav 的工作流如下:
•协议层 - 接收输入文件(输入也可以是 rtmp 或者 http)•格式层 - 解封装数据内容,暴露出元数据和流信息•编码层 - 解码原数据流 可选•像素层 - 可以对原数据做 filters(像改变大小)可选•然后反过来做相同的操作•编码层 - 编码(重新编码或者转码)原数据帧可选•格式层 - 封装(或接封装)原数据流(压缩数据)•协议层 - 给到相应的 输出 (文件或者网络数据)
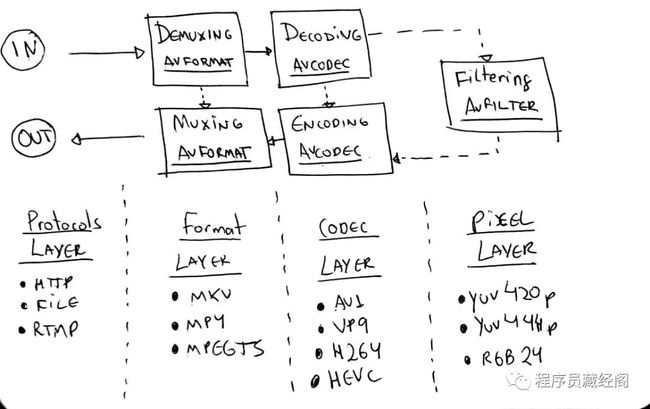
ffmpeg libav workflow
这张图非常感谢 Leixiaohua’s 和 Slhck’s 的工作。
让我们来用 libav 做一个命令行的操作: ffmpeg input.mp4 -c copy output.ts.
我们读取一个输入文件(input_format_context),并且改变为另一个格式的输出(output_format_context)。
AVFormatContext *input_format_context = NULL;
AVFormatContext *output_format_context = NULL;
我们通常的做法就是分配内存并打开一个输入文件。对于这个例子,我们将打开一个文件并为一个输出文件分配内存。
if ((ret = avformat_open_input(&input_format_context, in_filename, NULL, NULL)) < 0) {
fprintf(stderr, "Could not open input file '%s'", in_filename);
goto end;
}
if ((ret = avformat_find_stream_info(input_format_context, NULL)) < 0) {
fprintf(stderr, "Failed to retrieve input stream information");
goto end;
}
avformat_alloc_output_context2(&output_format_context, NULL, NULL, out_filename);
if (!output_format_context) {
fprintf(stderr, "Could not create output context\n");
ret = AVERROR_UNKNOWN;
goto end;
}
我们将解封装视频、音频、字幕流,这些变量我们将存入一个数组。
number_of_streams = input_format_context->nb_streams;
streams_list = av_mallocz_array(number_of_streams, sizeof(*streams_list));
在我们分配完所需要的内存之后,我们遍历所有的流,然后通过 avformat_new_stream 为每一个流输入流创建一个对应的输出流。注意我们只针对视频、音频、字幕流。
for (i = 0; i < input_format_context->nb_streams; i++) {
AVStream *out_stream;
AVStream *in_stream = input_format_context->streams[i];
AVCodecParameters *in_codecpar = in_stream->codecpar;
if (in_codecpar->codec_type != AVMEDIA_TYPE_AUDIO &&
in_codecpar->codec_type != AVMEDIA_TYPE_VIDEO &&
in_codecpar->codec_type != AVMEDIA_TYPE_SUBTITLE) {
streams_list[i] = -1;
continue;
}
streams_list[i] = stream_index++;
out_stream = avformat_new_stream(output_format_context, NULL);
if (!out_stream) {
fprintf(stderr, "Failed allocating output stream\n");
ret = AVERROR_UNKNOWN;
goto end;
}
ret = avcodec_parameters_copy(out_stream->codecpar, in_codecpar);
if (ret < 0) {
fprintf(stderr, "Failed to copy codec parameters\n");
goto end;
}
}
现在我们创建一个输出文件。
if (!(output_format_context->oformat->flags & AVFMT_NOFILE)) {
ret = avio_open(&output_format_context->pb, out_filename, AVIO_FLAG_WRITE);
if (ret < 0) {
fprintf(stderr, "Could not open output file '%s'", out_filename);
goto end;
}
}
ret = avformat_write_header(output_format_context, NULL);
if (ret < 0) {
fprintf(stderr, "Error occurred when opening output file\n");
goto end;
}
之后,我们把输入流一个包一个包的复制到输出流。我们循环来读取每一个数据包(av_read_frame),对于每一数据包我们都要重新计算 PTS 和 DTS,最终我们通过 av_interleaved_write_frame 写入输出格式的上下文。
while (1) {
AVStream *in_stream, *out_stream;
ret = av_read_frame(input_format_context, &packet);
if (ret < 0)
break;
in_stream = input_format_context->streams[packet.stream_index];
if (packet.stream_index >= number_of_streams || streams_list[packet.stream_index] < 0) {
av_packet_unref(&packet);
continue;
}
packet.stream_index = streams_list[packet.stream_index];
out_stream = output_format_context->streams[packet.stream_index];
/* 赋值数据包 */
packet.pts = av_rescale_q_rnd(packet.pts, in_stream->time_base, out_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
packet.dts = av_rescale_q_rnd(packet.dts, in_stream->time_base, out_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
packet.duration = av_rescale_q(packet.duration, in_stream->time_base, out_stream->time_base);
// https://ffmpeg.org/doxygen/trunk/structAVPacket.html#ab5793d8195cf4789dfb3913b7a693903
packet.pos = -1;
//https://ffmpeg.org/doxygen/trunk/group__lavf__encoding.html#ga37352ed2c63493c38219d935e71db6c1
ret = av_interleaved_write_frame(output_format_context, &packet);
if (ret < 0) {
fprintf(stderr, "Error muxing packet\n");
break;
}
av_packet_unref(&packet);
}
最后我们要使用函数 av_write_trailer 把流的结束内容写到输出的媒体文件中。
av_write_trailer(output_format_context);
现在我们可以开始测试了,首先我们将转换文件从 MP4 到 MPEG-TS。我们用 libav 来代替命令行 ffmpeg input.mp4 -c copy output.ts 的执行。
make run_remuxing_ts
好了,开始执行了!!!不相信我吗?那不能,让我们来用 ffprobe 来检测一下:
ffprobe -i remuxed_small_bunny_1080p_60fps.ts
Input #0, mpegts, from 'remuxed_small_bunny_1080p_60fps.ts':
Duration: 00:00:10.03, start: 0.000000, bitrate: 2751 kb/s
Program 1
Metadata:
service_name : Service01
service_provider: FFmpeg
Stream #0:0[0x100]: Video: h264 (High) ([27][0][0][0] / 0x001B), yuv420p(progressive), 1920x1080 [SAR 1:1 DAR 16:9], 60 fps, 60 tbr, 90k tbn, 120 tbc
Stream #0:1[0x101]: Audio: ac3 ([129][0][0][0] / 0x0081), 48000 Hz, 5.1(side), fltp, 320 kb/s
总结一下我们在图中所做的事情,我们可以回顾一下 关于libav如何工作的,但我们跳过了编解码器部分。
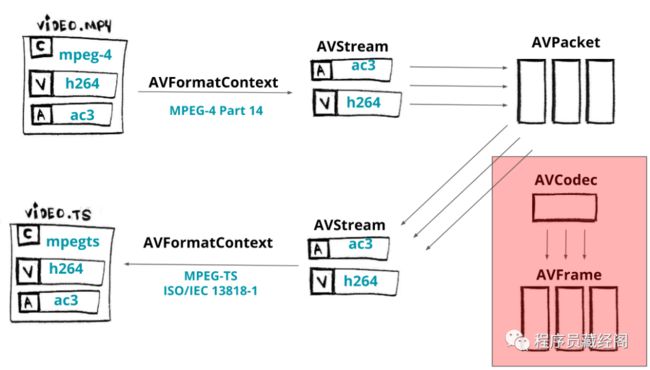
remuxing libav components
在我们结束这章之前,我想让大家看看重新封装的过程,你可以将选项传递给封装器。比如我们要分发 MPEG-DASH 格式的文件,我需要使用 fragmented mp4(有时也叫fmp4)代替 TS 或者 MPEG-4。
如果用命令行我们可以很简单的实现:
ffmpeg -i non_fragmented.mp4 -movflags frag_keyframe+empty_moov+default_base_moof fragmented.mp4
命令行几乎等同于我们调用 libav,当我们写入输出头时,在复制数据包之前只需要传入相应的选项就可以了。
AVDictionary* opts = NULL;
av_dict_set(&opts, "movflags", "frag_keyframe+empty_moov+default_base_moof", 0);
ret = avformat_write_header(output_format_context, &opts);
现在我们生成 fragmented mp4 文件:
make run_remuxing_fragmented_mp4
为了确保我没有骗你们。你可以一个非常棒的工具 gpac/mp4box.js,或者在线工具 http://mp4parser.com/ 去对比差异。
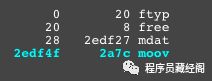
mp4 boxes
如你所见, mdat atom/box 是存放音视频帧的地方。现在我们加载 mp4 分片,看看是如何渲染 mdat 的。
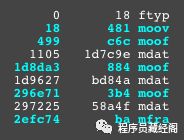
fragmented mp4 boxes
章节 3 - 转码
展示代码并执行
$ make run_transcoding我们跳过一些细节,但是不用担心:源码在 github 上 。
在这一章,我们将用 C 写一个编码器,编码器将会用到 FFmpg/libav 里的 libavcodec,libavformat 和 libavutil 将视频从 H264 转到 H265。
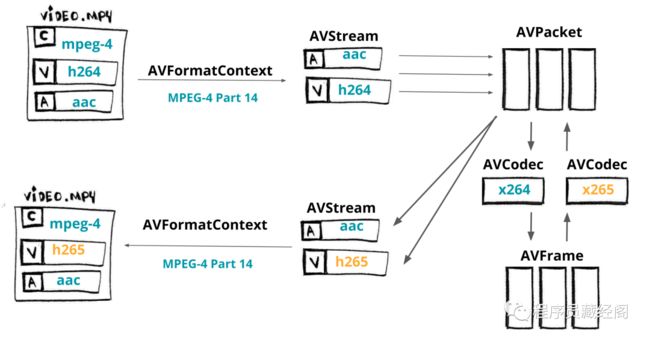
media transcoding flow
快速回顾一下:AVFormatContext 是媒体文件格式的抽象(例如:MKV,MP4,Webm,TS)。 AVStream 代表给定格式的数据类型(例如:音频,视频,字幕,元数据)。 AVPacket 是从
AVStream获得的压缩数据的切片,可由 AVCodec(例如av1,h264,vp9,hevc)解码,从而生成称为 AVFrame 的原始数据。
转封装
让我们编译上面的代码开始转换操作,第一步我们需要加载输入文件。
// 为 AVFormatContext 分配内存
avfc = avformat_alloc_context();
// 打开一个输入流并读取头信息
avformat_open_input(avfc, in_filename, NULL, NULL);
// 获取流信息
avformat_find_stream_info(avfc, NULL);
我们先开始设置解码的操作,我们用 AVFormatContext 可以获取到所有的 AVStream,我们可以获得相应的 AVCodec,并且创建特定的 AVCodecContext,最终我们将打开给定的编码器来做解码的操作。
AVCodecContext 保存有关媒体的数据包括 码率,帧率,采样率,通道,高还有其他。
for (int i = 0; i < avfc->nb_streams; i++)
{
AVStream *avs = avfc->streams[i];
AVCodec *avc = avcodec_find_decoder(avs->codecpar->codec_id);
AVCodecContext *avcc = avcodec_alloc_context3(*avc);
avcodec_parameters_to_context(*avcc, avs->codecpar);
avcodec_open2(*avcc, *avc, NULL);
}
现在我们需要准备输出文件,首先我们为 AVFormatContext 来分配内存。我们为每一个流创建输出的格式。为了正确打包流,我们从解码器复制编解码参数。
我们通过设置 AV_CODEC_FLAG_GLOBAL_HEADER 来告诉编码器可以使用这个全局头信息,最终我们保持这些头信息写入到输出文件中。
avformat_alloc_output_context2(&encoder_avfc, NULL, NULL, out_filename);
AVStream *avs = avformat_new_stream(encoder_avfc, NULL);
avcodec_parameters_copy(avs->codecpar, decoder_avs->codecpar);
if (encoder_avfc->oformat->flags & AVFMT_GLOBALHEADER)
encoder_avfc->flags |= AV_CODEC_FLAG_GLOBAL_HEADER;
avio_open(&encoder_avfc->pb, encoder->filename, AVIO_FLAG_WRITE);
avformat_write_header(encoder->avfc, &muxer_opts);
我们从解码器获得 AVPacket,调整时间戳后写到输出文件。尽管 av_interleaved_write_frame 从函数名上来看是 “写入帧信息”,但我们实际存储的是数据包。我们通过写入流的尾部到文件来结束转封装操作。
AVFrame *input_frame = av_frame_alloc();
AVPacket *input_packet = av_packet_alloc();
while (av_read_frame(decoder_avfc, input_packet) >= 0)
{
av_packet_rescale_ts(input_packet, decoder_video_avs->time_base, encoder_video_avs->time_base);
av_interleaved_write_frame(*avfc, input_packet) < 0));
}
av_write_trailer(encoder_avfc);
转码
前面的章节我们展示了一个转封装的程序,现在我们将对文件做转码,我们会把视频从 h264 转到 h265。
在我们解码之后和输出之前,我们将要开始设置我们的编码器。
•使用 avformat_new_stream 来创建编码的 AVStream•我们使用 libx265 做为 AVCodec,avcodec_find_encoder_by_name•创建 AVCodecContext 作为编码器的基础,avcodec_alloc_context3•为编解码设置基础属性,并且打开编码器,将参数从上下文复制到流中,使用 avcodec_open2 和 avcodec_parameters_from_context
AVRational input_framerate = av_guess_frame_rate(decoder_avfc, decoder_video_avs, NULL);
AVStream *video_avs = avformat_new_stream(encoder_avfc, NULL);
char *codec_name = "libx265";
char *codec_priv_key = "x265-params";
// 我们将对 x265 使用内部的参数
// 禁用场景切换并且把 GOP 调整为 60 帧
char *codec_priv_value = "keyint=60:min-keyint=60:scenecut=0";
AVCodec *video_avc = avcodec_find_encoder_by_name(codec_name);
AVCodecContext *video_avcc = avcodec_alloc_context3(video_avc);
// 编码参数
av_opt_set(sc->video_avcc->priv_data, codec_priv_key, codec_priv_value, 0);
video_avcc->height = decoder_ctx->height;
video_avcc->width = decoder_ctx->width;
video_avcc->pix_fmt = video_avc->pix_fmts[0];
// 控制码率
video_avcc->bit_rate = 2 * 1000 * 1000;
video_avcc->rc_buffer_size = 4 * 1000 * 1000;
video_avcc->rc_max_rate = 2 * 1000 * 1000;
video_avcc->rc_min_rate = 2.5 * 1000 * 1000;
// 时间基数
video_avcc->time_base = av_inv_q(input_framerate);
video_avs->time_base = sc->video_avcc->time_base;
avcodec_open2(sc->video_avcc, sc->video_avc, NULL);
avcodec_parameters_from_context(sc->video_avs->codecpar, sc->video_avcc);
为了视频编码,我们需要展开解码的步骤:
•发送空的 AVPacket 给解码器,avcodec_send_packet•接收解压完的 AVFrame,avcodec_receive_frame•开始编码元数据•发送元数据, avcodec_send_frame•基于编码器,接受编码数据, AVPacket,avcodec_receive_packet•设置时间戳, av_packet_rescale_ts•写到输出文件 av_interleaved_write_frame
AVFrame *input_frame = av_frame_alloc();
AVPacket *input_packet = av_packet_alloc();
while (av_read_frame(decoder_avfc, input_packet) >= 0)
{
int response = avcodec_send_packet(decoder_video_avcc, input_packet);
while (response >= 0) {
response = avcodec_receive_frame(decoder_video_avcc, input_frame);
if (response == AVERROR(EAGAIN) || response == AVERROR_EOF) {
break;
} else if (response < 0) {
return response;
}
if (response >= 0) {
encode(encoder_avfc, decoder_video_avs, encoder_video_avs, decoder_video_avcc, input_packet->stream_index);
}
av_frame_unref(input_frame);
}
av_packet_unref(input_packet);
}
av_write_trailer(encoder_avfc);
// 使用函数
int encode(AVFormatContext *avfc, AVStream *dec_video_avs, AVStream *enc_video_avs, AVCodecContext video_avcc int index) {
AVPacket *output_packet = av_packet_alloc();
int response = avcodec_send_frame(video_avcc, input_frame);
while (response >= 0) {
response = avcodec_receive_packet(video_avcc, output_packet);
if (response == AVERROR(EAGAIN) || response == AVERROR_EOF) {
break;
} else if (response < 0) {
return -1;
}
output_packet->stream_index = index;
output_packet->duration = enc_video_avs->time_base.den / enc_video_avs->time_base.num / dec_video_avs->avg_frame_rate.num * dec_video_avs->avg_frame_rate.den;
av_packet_rescale_ts(output_packet, dec_video_avs->time_base, enc_video_avs->time_base);
response = av_interleaved_write_frame(avfc, output_packet);
}
av_packet_unref(output_packet);
av_packet_free(&output_packet);
return 0;
}
我们转换媒体流从 h264 到 h265,和我们预期的差不多,h265 的文件小于 h264,从创建的程序能够看出:
/*
* H264 -> H265
* Audio -> remuxed (untouched)
* MP4 - MP4
*/
StreamingParams sp = {0};
sp.copy_audio = 1;
sp.copy_video = 0;
sp.video_codec = "libx265";
sp.codec_priv_key = "x265-params";
sp.codec_priv_value = "keyint=60:min-keyint=60:scenecut=0";
/*
* H264 -> H264 (fixed gop)
* Audio -> remuxed (untouched)
* MP4 - MP4
*/
StreamingParams sp = {0};
sp.copy_audio = 1;
sp.copy_video = 0;
sp.video_codec = "libx264";
sp.codec_priv_key = "x264-params";
sp.codec_priv_value = "keyint=60:min-keyint=60:scenecut=0:force-cfr=1";
/*
* H264 -> H264 (fixed gop)
* Audio -> remuxed (untouched)
* MP4 - fragmented MP4
*/
StreamingParams sp = {0};
sp.copy_audio = 1;
sp.copy_video = 0;
sp.video_codec = "libx264";
sp.codec_priv_key = "x264-params";
sp.codec_priv_value = "keyint=60:min-keyint=60:scenecut=0:force-cfr=1";
sp.muxer_opt_key = "movflags";
sp.muxer_opt_value = "frag_keyframe+empty_moov+delay_moov+default_base_moof";
/*
* H264 -> H264 (fixed gop)
* Audio -> AAC
* MP4 - MPEG-TS
*/
StreamingParams sp = {0};
sp.copy_audio = 0;
sp.copy_video = 0;
sp.video_codec = "libx264";
sp.codec_priv_key = "x264-params";
sp.codec_priv_value = "keyint=60:min-keyint=60:scenecut=0:force-cfr=1";
sp.audio_codec = "aac";
sp.output_extension = ".ts";
/* WIP :P -> it's not playing on VLC, the final bit rate is huge
* H264 -> VP9
* Audio -> Vorbis
* MP4 - WebM
*/
//StreamingParams sp = {0};
//sp.copy_audio = 0;
//sp.copy_video = 0;
//sp.video_codec = "libvpx-vp9";
//sp.audio_codec = "libvorbis";
//sp.output_extension = ".webm";
现在,说实话,这比我想象中的难,我必须深入理解 FFmpeg 命令行源码,并且做很多测试,我想我肯定搞错了一些细节,因为我为 h264 强制
force-cfr才能工作,并且仍然能看见一些warning 信息(强制帧类型(5)为真类型(3))。
原文地址:
ffmpeg-libav-tutorial : https://github.com/leandromoreira/ffmpeg-libav-tutorial
most star golang ffmpeg bindings: https://github.com/giorgisio/goav
