实现 Castor 数据绑定--转
第 1 部分: 安装和设置 Castor
数据绑定风靡一时
在 XML 新闻组、邮件列表和网站的讨论论坛中(在 参考资料 中可以找到这些内容的链接),最常见的一个主题就是数据绑定。Java 和 XML 开发人员正在寻求一种在 Java 对象与 XML 文档之间来回转换的简单方法。
Sun 借助其 JAXB,即 Java Architecture for XML Binding(如果您在其他地方看到缩写词 JAXB,那也是正常的;Sun 似乎每年都会更改 JAXB 所代表的含义), 在数据绑定领域占据了主导地位。然而,JAXB API(如果您喜欢,也可以称为架构)存在着一些不足,并且更新速度较慢。它也不能处理到关系数据库的映射,而这种映射是一种很常见的请求。
Castor 的诞生
正是在这种情形下,Castor 出现了。Castor 是一种开源框架,它可用于无法使用 JAXB 的领域。Castor 一直在发展之中,并且早于 JAXB 代码库和 SUN 数据绑定规范。实际上,Castor 已经实现了更新,可结合 JAXB 方法实现数据绑定,因此使用 JAXB 的编程人员可以很容易地移动代码。
Castor 的优势
在讨论安装和使用 Castor 的细节之前,有必要指出尝试 Castor 以及从 JAXB 转变到 Castor 的理由。
- 首先,Castor 几乎是 JAXB 的替代品。换句话说,可以轻易地将所有 JAXB 代码转变为 Castor(并不是完全取代,但是足以使刚刚接触 Castor 的程序员轻松完成任务)。
- 其次,Castor 在数据绑定领域提供了许多的功能,无需使用模式便可在 Java 和 XML 之间进行转换,提供一种比 JAXB 更易于使用的绑定模式,以及能够对关系数据库和 XML 文档进行编组(marshal)和解组(unmarshal)。
- Castor 还提供了 JDO 功能。JDO 也就是 Java Data Objects,是驱动 Java-to-RDBMS 编组和解组的底层技术。尽管不再像前几年那么流行,JDO 仍然是一个不错的功能。此外,由于 JDO 也是一种 Sun 规范,因此不用编写模糊的 API。
下载 Castor
Castor 的安装过程很简单。首先,访问 Castor Web 站点(参见 参考资料 中的链接)并在左侧菜单中单击 Download。选择 latest milestone release,然后向下滚动到 Download sets。您可以下载 Castor JAR、DTD、doc、dependency 等所有内容,预打包的下载套件非常容易使用(参见图 1)。
图 1. Castor Web 站点的下载套件
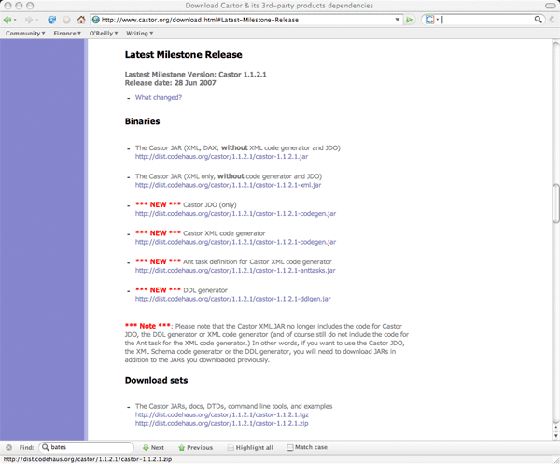
在本文中,我们将使用版本 1.1.2.1。我选择 ZIP 格式的 The Castor JARs, docs, DTDs, command line tools, and examples 下载套件。您将获得一个可以展开的归档文件,其中包含许多 JAR 文件、文档和示例程序(参见图 2)。
图 2. 展开的 Castor 归档文件
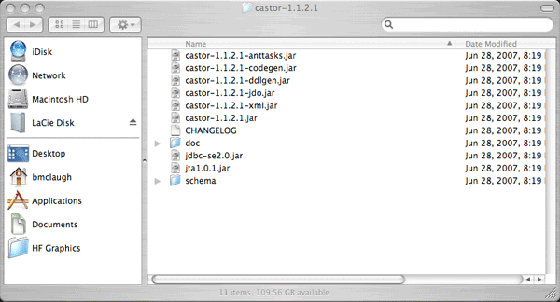
正确放置所有文件
接下来,需要将 Castor 的所有文件安放在系统中的正确位置,使您的 Java 环境能够访问它们。
将 Java 库放在同一个位置
我强烈建议将所有第三方 Java 库放在一个常见位置。您可以将它们随意散放在系统中,但是这样做会带来严重后果,因为如下原因:
- 在大多数情况下很难找到需要的东西。
- 您将会花大量时间来确定使用的库版本,因为您会经常将多个版本放在系统的不同位置。
- 类路径将会变得很长而且难于理解。
我将我的所有库放在 /usr/local/java/ 中,每个库放在自己的子目录中(各个目录通常带有一个版本号)。因此将 Castor 归档文件 — 经过扩展 — 移动到您常用的库位置。在本例中,Castor 的完整路径为:/usr/local/java/castor-1.1.2.1。
为 Castor JavaDoc 添加书签
在系统中设置 Java 库的另一个步骤是定位和链接到文档。您会经常这样做,而且大多数 Java 库都提供文档的本地副本(包括 JavaDoc),使用 HTML 格式。在 Castor 中,这个路径是 castor-1.1.2.1/doc/。因此在我的系统中,我为 /usr/local/java/castor-1.1.2.1/doc/index.html 添加了一个书签。图 3 显示了本地载入的 Castor 文档外观,版本为 1.1.2.1。
图 3. 本地载入的 Castor 文档
在本文中以及在您日常编程中都需要执行这些操作,原因有二:
- 文档是本地的。 在飞机上编写过程序吗?是不是没有网络链接?不能登录到 Starbucks WiFi 吧?本地文档除了能够更快速地访问之外,在这些情形中也发挥着重要作用。
- 本地文档总是适合您自己的需要。随着 Castor 的不断发展,您也许不会经常下载最新的发行版。使用在线文档就意味着使用最新版本的文档,这可能与您系统中的版本不匹配。当使用本地文档时,使用的文档总是和当前使用的库版本对应。因此,不会由于使用不恰当或者库版本中根本不存在的特性而引起混乱和挫折。
下载 Castor 依赖项
Castor 有许多 依赖项:
- Apache Ant
- Jakarta Commons
- JDBC 2.0 Standard Extensions
- Log4J 登录实用程序
- Apache Xerces XML 解析程序
这实际上是适用于大多数 Castor 操作的一个精简的集合。如果想从头构建 Castor、运行这些示例、使用这些测试,或者更深入地研究 Castor,还需要更多的依赖项。必须将这些依赖项放到类路径中,才能使用 Castor。
复杂的方法
要运行 Castor,比较麻烦的方法就是,首先访问 Castor 的下载页面并记下所需的每个依赖项的版本。然后跳转到每个依赖项的 Web 站点,找到该版本,下载并将其添加到类路径中。这种方法会花费较长的 时间,但是更加易于控制。此外,如果您已经设置好并能正常运行大多数库,这仍然是一个可行的方法。
简单的方法
幸运的是,还有一种更好的方法。回到 Castor 的下载页面,找到稳定版本,并定位到另一个下载套件,这个下载套件叫做 Full SVN snapshot: All sources, docs, and 3rd party libraries (big)。尽管标记为 “big”,但只有 10 MB(对于用 DSL 或者电缆上网的用户来说,这根本不算什么)。下载这个文件,并展开(如图 4 所示)。
图 4. Full SVN 截图(已展开)
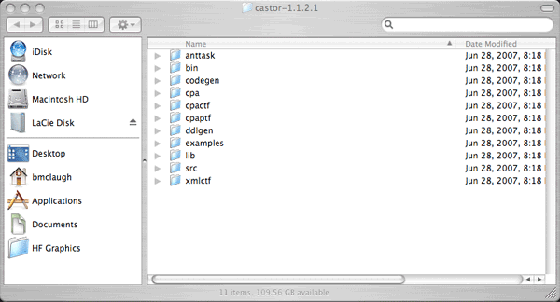
现在可以进入 lib/ 目录了,其中包含大量的 JAR 文件。这些正是 Castor 所需的库。
存放更多库的位置
创建一个新目录 — 在最初的 Castor 安装目录中或者与之同级的目录 — 然后将刚才下载的所有 JAR 文件移动到这个目录中。例如:
[bmclaugh:~] cd /usr/local/java [bmclaugh:/usr/local/java] ls castor-1.1.2.1 xalan-j_2_7_0 [bmclaugh:/usr/local/java] cd castor-1.1.2.1/ [bmclaugh:/usr/local/java/castor-1.1.2.1] ls CHANGELOG castor-1.1.2.1.jar castor-1.1.2.1-anttasks.jar doc castor-1.1.2.1-codegen.jar jdbc-se2.0.jar castor-1.1.2.1-ddlgen.jar jta1.0.1.jar castor-1.1.2.1-jdo.jar schema castor-1.1.2.1-xml.jar [bmclaugh:/usr/local/java/castor-1.1.2.1] mkdir lib [bmclaugh:/usr/local/java/castor-1.1.2.1] cd lib [bmclaugh:/usr/local/java/castor-1.1.2.1/lib] cp ~/downloads/castor-1.1.2.1/lib/*.jar . [bmclaugh:/usr/local/java/castor-1.1.2.1/lib]
此处,我在 Castor 文件夹中创建了一个 lib/ 目录,将所有的 JAR 文件移到其中,供 Castor 使用。
设置类路径
现在需要设置类路径中的所有东西。我在 Mac OS X 配置中使用一个 .profile 文件处理所有这些问题。您也许想将您的 profile 也设置为这样,或者在 Windows 中设置一个系统环境变量。在任何情况下,都需要将如下 JAR 文件添加到类路径:
- castor-1.1.2.1.jar(在 Castor 主目录中)
- castor-1.1.2.1-xml.jar(在 Castor 主目录中)
- xerces-J-1.4.0.jar(放在与 Castor 依赖项库相同的位置)
- commons-logging-1.1.jar(放在与 Castor 依赖项库相同的位置)
作为参考,以下是我的 .profile,从中可以看到我是如何设置的:
export JAVA_BASE=/usr/local/java
export JAVA_HOME=/Library/Java/Home
export XERCES_HOME=$JAVA_BASE/xerces-2_6_2
export XALAN_HOME=$JAVA_BASE/xalan-j_2_7_0
export CASTOR_HOME=$JAVA_BASE/castor-1.1.2.1
export EDITOR=vi
export CASTOR_CLASSES=$CASTOR_HOME/castor-1.1.2.1.jar:
$CASTOR_HOME/castor-1.1.2.1-xml.jar:
$CASTOR_HOME/lib/xerces-J_1.4.0.jar:
$CASTOR_HOME/lib/commons-logging-1.1.jar
export CVS_RSH=ssh
export PS1="[`whoami`:\w] "
export CLASSPATH=$XALAN_HOME/xalan.jar:$XALAN_HOME/xml-apis.jar:
$XALAN_HOME/xercesImpl.jar:
~/lib/mclaughlin-xml.jar:$CASTOR_CLASSES:.
请确保将所有这些文件都放到了类路径中,接下来将做一个快速测试。
测试安装
首先构建一个非常 简单的类,然后构建一个实用程序将其在 XML 和 Java 之间来回转换。这里并不会演示 Castor 的所有功能,而只是一个非常基本的测试。清单 1 显示了我将使用的一个 CD 类。输入这些源代码并保存为 CD.java(或者从 参考资料 下载这些代码)。
清单 1. CD 类(用于测试)
package ibm.xml.castor;
import java.util.ArrayList;
import java.util.List;
/** A class to represent CDs */
public class CD implements java.io.Serializable {
/** The name of the CD */
private String name = null;
/** The artist of the CD */
private String artist = null;
/** Track listings */
private List tracks = null;
/** Required no-args constructor */
public CD() {
super();
}
/** Create a new CD */
public CD(String name, String artist) {
super();
this.name = name;
this.artist = artist;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setArtist(String artist) {
this.artist = artist;
}
public String getArtist() {
return artist;
}
public void setTracks(List tracks) {
this.tracks = tracks;
}
public List getTracks() {
return tracks;
}
public void addTrack(String trackName) {
if (tracks == null) {
tracks = new ArrayList();
}
tracks.add(trackName);
}
}
现在需要一个类处理编组。如清单 2 所示。
清单 2. 用于测试编组的类
package ibm.xml.castor;
import java.io.FileWriter;
import org.exolab.castor.xml.Marshaller;
public class MarshalTester {
public static void main(String[] args) {
try {
CD sessions = new CD("Sessions for Robert J", "Eric Clapton");
sessions.addTrack("Little Queen of Spades");
sessions.addTrack("Terraplane Blues");
FileWriter writer = new FileWriter("cds.xml");
Marshaller.marshal(sessions, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
最后一个类如清单 3 所示,是一个用于解组的类。
清单 3. 用于测试解组的类
package ibm.xml.castor;
import java.io.FileReader;
import java.util.Iterator;
import java.util.List;
import org.exolab.castor.xml.Unmarshaller;
public class UnmarshalTester {
public static void main(String[] args) {
try {
FileReader reader = new FileReader("cds.xml");
CD cd = (CD)Unmarshaller.unmarshal(CD.class, reader);
System.out.println("CD title: " + cd.getName());
System.out.println("CD artist: " + cd.getArtist());
List tracks = cd.getTracks();
if (tracks == null) {
System.out.println("No tracks.");
} else {
for (Iterator i = tracks.iterator(); i.hasNext(); ) {
System.out.println("Track: " + i.next());
}
}
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
像下面这样编译这些类:
[bmclaugh:~/Documents/developerworks/castor] javac -d . *.java Note: CD.java uses unchecked or unsafe operations. Note: Recompile with -Xlint:unchecked for details.
如果使用的是 Java 5 或更高的版本,而在 CD.java 中没有使用参数化的类型,就会出现上面的警告。不要担心,这不会有什么影响。现在需要运行编组程序测试类。
[bmclaugh:~/Documents/developerworks/castor] java ibm.xml.castor.MarshalTester
找到并打开 cds.xml。其内容应该像这样:
<?xml version="1.0" encoding="UTF-8"?>
<CD>
<artist>Eric Clapton</artist>
<name>Sessions for Robert J</name>
<tracks xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="java:java.lang.String">Little Queen of Spades</tracks>
<tracks xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="java:java.lang.String">Terraplane Blues</tracks>
</CD>
这些内容可读性不太好,但是应该能在 XML 文档中看到在 MarshalTester 类中创建的 CD 的所有信息。
现在需要确保可以将 XML 文档转换回 Java。运行解组测试程序:
[bmclaugh:~/Documents/developerworks/castor] java ibm.xml.castor.UnmarshalTester CD title: Sessions for Robert J CD artist: Eric Clapton Track: Little Queen of Spades Track: Terraplane Blues
这些代码非常简单,无需解释。如果你获得了这样的输出,就说明已经用 Castor 打开了 XML 文件,并且已经将其转换为一个 Java 类。
现在 — 我们假设您已经用 UnmarshalTester 获得了相同的 cds.xml 和输出 — 您安装的 Castor 能够正常运行。您还没有使用 Castor 做任何比较复杂的工作,只是确保了它能正常运行、正确设置了 JAR 文件以及 Castor 能够根据需要实现不同的功能。
结束语
现在,您有了一个能够正常运行的 Castor 环境。清单 1、2 和 3 让您对 Castor 的工作原理有了一定的了解。看看自己能否实现编组和解组功能吧。在下一篇文章中,您将会更进一步了解 Castor 的 XML 特性,以及如何使用映像文件。到那时,请继续体验 Castor 的功能。
原文:http://www.ibm.com/developerworks/cn/xml/x-xjavacastor1/index.html
第 2 部分: 编组和解组 XML
需要准备什么
开始之前需要保证具备了本文所需要的前提条件。确保满足这些要求最简单的办法就是按照 本系列第一篇文章(链接参见本文 参考资料 部分)介绍的步骤操作。第一篇文章介绍了如何下载、安装和配置 Castor,并用一些简单的类进行了测试。
从您手头的项目中选择一些类转换成 XML 然后再转换回来也没有问题。本文(以及上一期文章)提供了一些例子,但是要掌握 Castor,最好的办法是把这里学到的东西应用到您自己的项目中。首先从一些简单的对象类开始,比如代表人、唱片、图书或者某种其他具体对象的类。然后可以阅读本文中关于映射的内容,从而增加一些更复杂的类。
编组 101
Castor 最基本的操作是取一个 Java 类然后将类的实例编组成 XML。可以把类本身作为顶层容器元素。比如 Book 类很可能在 XML 文档中得到一个名为 “book” 的根元素。
类的每个属性也表示在 XML 文档中。因此值为 “Power Play” 的 title 属性将生成这样的 XML:
<title>Power Play</title>
很容易由此推出一个简单 Java 类所生成的 XML 文档的其余部分。
编组类的实例
开始编组代码之前有几点需要注意。第一,只能编组类的实例而不能编组类本身。类是一种结构,等同于 XML 约束模型,如 DTD 或 XML Schema。类本身没有数据,仅仅定义了所存储的数据的结构和访问方法。
实例化类(或者通过工厂以及其他实例生成机制获得)将赋予它具体的形式。然后用实际数据填充实例的字段。实例是惟一的,它和同一类的实例具有相同的结构,但数据是不同的。图 1 直观地说明了这种关系。
图 1. 类提供结构,实例即数据
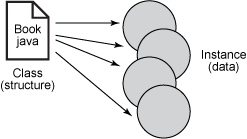
因而编组的只能是实例。后面将看到如何使用约束模型和映射文件改变 XML 的结构。但是现在要做的是让 XML 结构(元素和属性)和 Java 结构(属性)匹配。
基本的编组
清单 1 是本文中将使用的一个简单的 Book 类。
清单 1. Book 类
package ibm.xml.castor;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The author's name */
private String authorName;
public Book(String isbn, String title, String authorName) {
this.isbn = isbn;
this.title = title;
this.authorName = authorName;
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getAuthorName() {
return authorName;
}
}
编译上述代码将得到 Book.class 文件。这个类非常简单,只有三个属性:ISBN、标题和作者姓名(这里有些问题,暂时先不管)。仅仅这一个文件还不够,Castor 还需要几行代码将 Book 类的实例转化成 XML 文档。清单 2 中的小程序创建了一个新的 Book 实例并使用 Castor 转化成 XML。
清单 2. Book 编组器类
package ibm.xml.castor;
import java.io.FileWriter;
import org.exolab.castor.xml.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Book book = new Book("9780312347482", "Power Play", "Joseph Finder");
FileWriter writer = new FileWriter("book.xml");
Marshaller.marshal(book, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
编译然后运行该程序。将得到一个新文件 book.xml。打开该文件将看到如下所示的内容:
清单 3. 编译后的程序创建的 XML
<?xml version="1.0" encoding="UTF-8"?> <book><author-name>Joseph Finder</author-name> <isbn>9780312347482</isbn><title>Power Play</title></book>
为了清晰起见我增加了断行。实际生成的 XML 文档在 author-name 元素的结束标记和 isbn 元素的开始标记之间没有断行。
Castor 遗漏了什么
在改进这个例子之前 — 很有必要改进— 先看看 Castor 在 XML 中漏掉 了什么:
- Java 类的包。Java 包不属于类结构。这实际上是一个语义问题,和 Java 名称空间有关。因此可以将这个 XML 文档解组 — 从 XML 转换为 Java 代码 — 到任何具有相同的三个属性的
Book实例,不论是什么包。 - 字段顺序。这是 XML 的顺序问题,和 Java 编程无关。因此尽管源文件按某种顺序列出字段,但 XML 文档可能完全不同。这对于 XML 来说至关重要,但是和
Book类声明无关。 - 方法。和包声明一样,方法也和数据结构无关。因此 XML 文档没有涉及到这些方面,将其忽略了。
那么就要问 “那又怎么样呢?” 如果不重要,XML 忽略这些细节又有什么关系呢?但是这些信息很 重要。之所以重要是因为它们提供了超出预想的更大的灵活性。可以将这些 XML 解组为满足最低要求的任何类:
- 类名为 “Book”(使用映射文件可以改变,但这一点后面再说)。
- 这个类包括三个字段:
authorName、title和isbn。
仅此而已!看看能否编写满足这些要求的几个类,并改变类的其他 字段或者包声明、方法……很快您就会发现这种方法使得 Castor 多么灵活。
添加更复杂的类型
Book 类最明显的不足是不能存储多个作者。修改类使其能处理多个作者也很容易:
清单 4. 存储多个作者的 Book 类
package ibm.xml.castor;
import java.util.LinkedList;
import java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List authorNames;
public Book(String isbn, String title, List authorNames) {
this.isbn = isbn;
this.title = title;
this.authorNames = authorNames;
}
public Book(String isbn, String title, String authorName) {
this.isbn = isbn;
this.title = title;
this.authorNames = new LinkedList();
authorNames.add(authorName);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthorNames(List authorNames) {
this.authorNames = authorNames;
}
public List getAuthorNames() {
return authorNames;
}
public void addAuthorName(String authorName) {
authorNames.add(authorName);
}
}
如果使用 Java 5 或 6 技术,将会显示一些未检查/不安全操作的错误,因为这段代码没有使用参数化的 Lists。如果愿意可以自己增加这些代码。
这样的修改很简单,不需要对编组代码作任何修改。但是,有必要用一本多人编写的图书来验证 Castor 编组器能否处理集合。修改BookMarshaller 类如下:
清单 5. 处理收集器的 Book 类
package ibm.xml.castor;
import java.io.FileWriter;
import java.util.ArrayList;
import java.util.List;
import org.exolab.castor.xml.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Book book = new Book("9780312347482", "Power Play", "Joseph Finder");
FileWriter writer = new FileWriter("book.xml");
Marshaller.marshal(book, writer);
List book2Authors = new ArrayList();
book2Authors.add("Douglas Preston");
book2Authors.add("Lincoln Child");
Book book2 = new Book("9780446618502", "The Book of the Dead",
book2Authors);
writer = new FileWriter("book2.xml");
Marshaller.marshal(book2, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
第一本书的处理方式没有变,重新打开 book.xml 将看到和原来相同的结果。打开 book2.xml 看看 Castor 如何处理集合:
清单 6. 带有收集器的 XML 结果
<?xml version="1.0" encoding="UTF-8"?> <book><isbn>9780446618502</isbn><title>The Book of the Dead</title> <author-names xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="java:java.lang.String">Douglas Preston</author-names> <author-names xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="java:java.lang.String">Lincoln Child</author-names> </book>
显然,Castor 处理作者姓名列表没有问题。更重要的是,Castor 不仅为作者名称创建了一个 blanket 容器,这个框架实际上看到了列表的内部,并认识到内容是字符串(要记住,这不是参数化列表,Castor 必须自己确定列表成员的类型)。因此 XML 进行了一些非常具体的类型化工作。这是个不错的特性,尤其是如果需要将 XML 转化回 Java 代码之前进行一些处理的话。
添加自定义类
我们朝着真正实用的程序再前进一步。存储字符串作者姓名肯定最终会出现重复的数据(多数作者写了不只一本书)。清单 7 增加了一个新的类 Author。
清单 7. Author 类
package ibm.xml.castor;
public class Author {
private String firstName, lastName;
private int totalSales;
public Author(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setTotalSales(int totalSales) {
this.totalSales = totalSales;
}
public void addToSales(int additionalSales) {
this.totalSales += additionalSales;
}
public int getTotalSales() {
return totalSales;
}
}
是不是很简单?在 Book 类的下面作上述修改以便能够使用新的 Author 类。
清单 8. 使用自定义作者类的 Book 类
package ibm.xml.castor;
import java.util.LinkedList;
import java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List authors;
public Book(String isbn, String title, List authors) {
this.isbn = isbn;
this.title = title;
this.authors = authors;
}
public Book(String isbn, String title, Author author) {
this.isbn = isbn;
this.title = title;
this.authors = new LinkedList();
authors.add(author);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthors(List authors) {
this.authors = authors;
}
public List getAuthors() {
return authors;
}
public void addAuthor(Author author) {
authors.add(author);
}
}
测试上述代码需要对 BookMarshaller 略加修改:
清单 9. 增加了作者信息的 BookMarshaller 类
package ibm.xml.castor;
import java.io.FileWriter;
import java.util.ArrayList;
import java.util.List;
import org.exolab.castor.xml.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Author finder = new Author("Joseph", "Finder");
Book book = new Book("9780312347482", "Power Play", finder);
FileWriter writer = new FileWriter("book.xml");
Marshaller.marshal(book, writer);
List book2Authors = new ArrayList();
book2Authors.add(new Author("Douglas", "Preston"));
book2Authors.add(new Author("Lincoln", "Child"));
Book book2 = new Book("9780446618502", "The Book of the Dead",
book2Authors);
writer = new FileWriter("book2.xml");
Marshaller.marshal(book2, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
仅此而已!编译然后运行编组器。看看两个结果文件,这里仅列出 book2.xml,因为这个文件更有趣一点。
清单 10. 包括作者和图书信息的 XML 结果
<?xml version="1.0" encoding="UTF-8"?> <book><authors xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" total-sales="0" xsi:type="java:ibm.xml.castor.Author"><last-name>Preston</last-name> <first-name>Douglas</first-name></authors><authors xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" total-sales="0" xsi:type="java:ibm.xml.castor.Author"><last-name>Child</last-name> <first-name>Lincoln</first-name></authors><isbn>9780446618502</isbn> <title>The Book of the Dead</title></book>
Castor 同样能办到。它说明了如何同时编组 Book 和 Author 类(再看看 authors 列表)。Castor 甚至为 Author 增加了 totalSales 属性,可以试试看结果如何。
Castor 对泛型的处理
也许听起来像是全天候的推销频道,但 Castor 确实支持泛型和参数化列表。因此如果习惯 Java 5 或 Java 6,可以这样修改 Book:
清单 11. 处理泛型和参数化列表的 Book 类
package ibm.xml.castor;
import java.util.LinkedList;
import java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List<Author> authors;
public Book(String isbn, String title, List<Author> authors) {
this.isbn = isbn;
this.title = title;
this.authors = authors;
}
public Book(String isbn, String title, Author author) {
this.isbn = isbn;
this.title = title;
this.authors = new LinkedList<Author>();
authors.add(author);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthors(List<Author> authors) {
this.authors = authors;
}
public List<Author> getAuthors() {
return authors;
}
public void addAuthor(Author author) {
authors.add(author);
}
}
这样作者列表就只 接受 Author 实例了,这是一个非常重要的改进。可以对 BookMarshaller 作类似的修改,重新编译,并得到相同的 XML 输出。换句话说,可以为 Castor 建立非常具体的类。
类变了但 Castor 没有变
在最终讨论解组之前,还需要做一项重要的观察。前面对类作的所有修改都没有改变编组代码!我们增加了泛型、自定义类、集合等等,但是编组 XML,Castor API 只需要一次简单的调用。太令人吃惊了!
解组
花了很多时间详细讨论完编组以后,解组非常简单。有了 XML 文档,并保证具有和数据匹配的 Java 类之后,剩下的工作交给 Castor 就行了。我们来解组前面生成的两个 XML 文档。如清单 12 所示。
清单 12. 解组图书
package ibm.xml.castor;
import java.io.FileReader;
import java.util.Iterator;
import java.util.List;
import org.exolab.castor.xml.Unmarshaller;
public class BookUnmarshaller {
public static void main(String[] args) {
try {
FileReader reader = new FileReader("book.xml");
Book book = (Book)Unmarshaller.unmarshal(Book.class, reader);
System.out.println("Book ISBN: " + book.getIsbn());
System.out.println("Book Title: " + book.getTitle());
List authors = book.getAuthors();
for (Iterator i = authors.iterator(); i.hasNext(); ) {
Author author = (Author)i.next();
System.out.println("Author: " + author.getFirstName() + " " +
author.getLastName());
}
System.out.println();
reader = new FileReader("book2.xml");
book = (Book)Unmarshaller.unmarshal(Book.class, reader);
System.out.println("Book ISBN: " + book.getIsbn());
System.out.println("Book Title: " + book.getTitle());
authors = book.getAuthors();
for (Iterator i = authors.iterator(); i.hasNext(); ) {
Author author = (Author)i.next();
System.out.println("Author: " + author.getFirstName() + " " +
author.getLastName());
}
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
编译代码并运行。您可能会得到意料之外的结果!我遇到的错误和堆栈记录如下所示:
清单 13. 解组遇到的错误和堆栈记录
[bmclaugh:~/Documents/developerworks/castor-2]
java ibm.xml.castor.BookUnmarshaller
ibm.xml.castor.Book
org.exolab.castor.xml.MarshalException: ibm.xml.castor.Book{File:
[not available]; line: 2; column: 7}
at org.exolab.castor.xml.Unmarshaller.
convertSAXExceptionToMarshalException(Unmarshaller.java:755)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:721)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:610)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:812)
at ibm.xml.castor.BookUnmarshaller.main
(BookUnmarshaller.java:14)
Caused by: java.lang.InstantiationException: ibm.xml.castor.Book
at java.lang.Class.newInstance0(Class.java:335)
at java.lang.Class.newInstance(Class.java:303)
at org.exolab.castor.util.DefaultObjectFactory.createInstance(
DefaultObjectFactory.java:107)
at org.exolab.castor.xml.UnmarshalHandler.createInstance(
UnmarshalHandler.java:2489)
at org.exolab.castor.xml.UnmarshalHandler.startElement(
UnmarshalHandler.java:1622)
at org.exolab.castor.xml.UnmarshalHandler.startElement(
UnmarshalHandler.java:1353)
at org.apache.xerces.parsers.AbstractSAXParser.startElement
(Unknown Source)
at org.apache.xerces.impl.dtd.XMLDTDValidator.startElement
(Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanStartElement(
Unknown Source)
at org.apache.xerces.impl.XMLDocumentScannerImpl
$ContentDispatcher.
scanRootElementHook(Unknown Source)
at org.apache.xerces.impl.
XMLDocumentFragmentScannerImpl
$FragmentContentDispatcher.dispatch(
Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanDocument(
Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XMLParser.parse(Unknown Source)
at org.apache.xerces.parsers.AbstractSAXParser.parse(Unknown
Source)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:709)
... 3 more
Caused by: java.lang.InstantiationException: ibm.xml.castor.Book
at java.lang.Class.newInstance0(Class.java:335)
at java.lang.Class.newInstance(Class.java:303)
at org.exolab.castor.util.DefaultObjectFactory.createInstance(
DefaultObjectFactory.java:107)
at org.exolab.castor.xml.UnmarshalHandler.createInstance(
UnmarshalHandler.java:2489)
at org.exolab.castor.xml.UnmarshalHandler.startElement
(UnmarshalHandler.java:1622)
at org.exolab.castor.xml.UnmarshalHandler.startElement
(UnmarshalHandler.java:1353)
at org.apache.xerces.parsers.AbstractSAXParser.startElement
(Unknown Source)
at org.apache.xerces.impl.dtd.XMLDTDValidator.startElement
(Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanStartElement(
Unknown Source)
at org.apache.xerces.impl.XMLDocumentScannerImpl
$ContentDispatcher.
scanRootElementHook(Unknown Source)
at org.apache.xerces.impl.
XMLDocumentFragmentScannerImpl
$FragmentContentDispatcher.dispatch(
Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanDocument(
Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XMLParser.parse(Unknown Source)
at org.apache.xerces.parsers.AbstractSAXParser.parse(Unknown
Source)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:709)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:610)
at org.exolab.castor.xml.Unmarshaller.unmarshal
(Unmarshaller.java:812)
at ibm.xml.castor.BookUnmarshaller.main
(BookUnmarshaller.java:14)
那么到底是怎么回事呢?您遇到了直接使用 Castor 进行数据绑定必须要做出的几个让步中的第一个。
Castor 要求使用无参数的构造器
Castor 主要通过反射和调用 Class.forName(类名).newInstance() 这样的方法进行解组,因而 Castor 不需要了解很多就能实例化类。但是,它还要求类必须能通过不带参数的构造器实例化。
好消息是 Book 和 Author 类只需简单修改就能避免这些错误。只需要为两个类增加不带参数的构造器,public Book() { } 和 public Author() { }。重新编译并运行代码。
想想这意味着什么。有了无参数的构造器,不仅仅是 Castor,任何 类或者程序都能创建类的新实例。对于图书和作者来说,可以创建没有 ISBN、标题和作者的图书,或者没有姓和名的作者 — 这肯定会造成问题。如果 Castor 没有更先进的特性(下一期再讨论)这种缺陷就不可避免,因此必须非常注意类的使用。还必须考虑为任何可能造成 NullPointerException 错误的数据类型设置具体的值(字符串可以设为空串或者默认值,对象必须初始化等等)。
第二步:null 引起的更多问题
为 Book 和 Author 类增加无参数构造器,重新运行解组器。结果如下:
清单 14. 添加无参数构造器后的结果
[bmclaugh:~/Documents/developerworks/castor-2] java ibm.xml.castor.BookUnmarshaller Book ISBN: null Book Title: Power Play Author: null null Book ISBN: null Book Title: The Book of the Dead Author: null null Author: null null
看来还有问题没解决(不是说解组很简单吗?先等等,后面还要说)。值得注意的是,有几个字段为空。把这些字段和 XML 比较,会发现这些字段在 XML 文档都有正确的表示。那么是什么原因呢?
为了找出根源,首先注意图书的标题都 设置正确。此外仔细观察第二本书 The Book of the Dead。虽然初看起来似乎两本书的作者都没有设置,但问题不在这里。事实上,第二本书正确引用了两个 Author 对象。因此它引用了这两个对象,但是这些对象本身没有设置姓和名。因此图书的标题设置了,作者也一样。但是 ISBN 是空的,作者的姓和名也是空的。这是另一条线索:如果显示作者图书的总销售量,这些值就不会 是空。
发现了吗?空值字段都没有 setter(或 mutator)方法。没有 setIsbn()、setFirstName() 等等。这是因为类被设计成需要构造信息(一旦书有了自己的 ISBN,这个 ISBN 实际上就不能改变了,基本上就意味着一本书形成了,因此最好要求构造/实例化新图书的时候提供新的 ISBN)。
还记得吗?Castor 使用反射机制。恰恰因为只有对象提供无参数构造器的时候它才能创建对象,因为没有 setFieldName() 方法就无法设置字段的值。因此需要为 Book 和 Author 类增加一些方法。下面是需要添加的方法(实现很简单,留给读者自己完成):
setIsbn(String isbn)(Book类)setFirstName(String firstName)(Author类)setLastName(String lastName)(Author类)
增加上述方法之后重新编译就行了。
第三步:成功解组
再次尝试运行解组器,将得到如下所示的结果:
清单 15. 增加作者和 ISBN setter 方法后的解组结果
[bmclaugh:~/Documents/developerworks/castor-2] java ibm.xml.castor.BookUnmarshaller Book ISBN: 9780312347482 Book Title: Power Play Author: Joseph Finder Book ISBN: 9780446618502 Book Title: The Book of the Dead Author: Douglas Preston Author: Lincoln Child
终于得到了我们需要的结果。必须对类作几方面的修改。但是前面我曾提到解组非常简单。但是这和上面的情况不符,解组不是需要对类作很多修改吗?
实际上的确很简单。修改都是在您的类中,而和 Castor 解组过程无关。Castor 用起来非常简单,只要类的结构符合 Castor 的要求 — 每个类都要有无参数构造器,每个字段都要有 get/set 方法。
代价是值得的
现在的类和最初相比没有很大变化。Book 和 Author 没有面目全非,功能上没有很大不同(实际上没有什么区别)。但是现在设计还有一点问题。图书必须 有 ISBN(至少在我看来),因此能够创建没有 ISBN 的图书 — 无参数构造器 — 令我感到困扰。此外,我也不愿意别人随便改动图书的 ISBN,这样不能正确地表示图书对象。
作者的修改不那么严重,因为对于作者这个对象来说姓名可能不是很重要的标识符。名字可以改,现在甚至姓都可以改。另外,两位作者如果同名,目前也没有区分的现成办法。但即使增加了更具唯一性、更合适的标识符(社会安全号码、驾驶证号、其他标识符),仍然需要无参数构造器和字段 setter 方法。因此问题仍然存在。
这就变成了效益和控制的问题:
- Castor 是否提供了足够的好处 — 简化数据绑定 — 足以抵得上设计所要做出的让步?
- 对代码库是否有足够的控制权,避免滥用为 Castor 增加的方法?
只有您才能代表您的企业回答这些问题。对于多数开发人员来说,权衡的结果倾向于 Castor,就必须做出适当的让步。对于那些沉醉于设计或者由于特殊需求无法做出这些让步的少数人,可能更愿意自己编写简单的 XML 序列化工具。无论如何,应该将 Castor 放到您的工具包里。如果它不适合当前的项目,也许下一个用得上。
结束语
到目前为止还没有提到的 Castor 的一大特性是映射文件。我们是直接从 Java 代码翻译成 XML。但是有几个假定:
- 需要把 Java 类中的所有字段持久到 XML。
- 需要在 XML 中保留类名和字段名。
- 有一个类模型和需要反序列化的 XML 文档中的数据匹配。
对于企业级编程,这些假定都有可能不成立。如果将字段名和类名存储到 XML 文档中被认为是一种安全风险,可能会过多泄露应用程序的结构,该怎么办?如果交给您一个 XML 文档需要转化成 Java 代码,但希望使用不同的方法名称和字段名称,怎么办?如果只需要少数类属性存储到 XML 中,怎么办?
所有这些问题的答案都是一个:Castor 提供了进一步控制 Java 代码和 XML 之间映射关系的方式。下一期文章我们将详细介绍映射。现在,不要只考虑编组和解组,还要花时间想想为了让 Castor 正常工作所作的那些修改意味着什么。在思考的同时,不要忘记回来看看下一期文章。到时候再见。
原文:http://www.ibm.com/developerworks/cn/xml/x-xjavacastor2/index.html
第 3 部分: 模式之间的映射
您现在应该具备的(回顾)
与前一篇文章一样,本文也对您系统的设置情况和您的技能做一些假设。首先,需要按照本系列的第 1 部分中的描述下载并安装 Castor 的最新版本,设置类路径和相关的 Java 库(参见 参考资料 中本系列第一篇文章的链接)。然后,按照第 2 部分中的描述,熟悉 Castor 的基本编组和解组设施。
所以,您应该能够使用 Castor 提取出 XML 文档中的数据,并使用自己的 Java 类处理数据。用数据绑定术语来说,这称为解组(unmarshalling)。反向的过程称为编组(marshalling):您应该能够把 Java 类的成员变量中存储的数据转换为 XML 文档。如果您还不熟悉 Castor 的解组器和编组器,那么应该阅读 第 2 部分(参见 参考资料 中的链接)。
非理想环境下的数据绑定
初看上去,您似乎已经掌握了有效地使用 Castor 所需了解的所有过程:设置、编组和解组。但是,您到目前为止学到的所有东西只适用于所谓的理想环境。在这样的环境中,每个人编写的 XML 都是完美的,其中的元素名是有意义的,比如 “title” 和 “authorAddress”,而不是 “t” 或 “aa”。Java 类是按照有组织的方式创建的,采用单数作为类名(比如 “Book”),采用单数名词作为成员变量名(比如 “isbn” 和 “price”)。另外,数据类型也是正确的:没有开发人员把 price 的数据类型设置为 int 而不是 float,或者使用 char 数组存储字符串数据(这是 C 语言的做法)。
但是,大多数程序员所处的环境并不完美(我真想找到一个能够把我送到完美世界的魔法衣厨)。在大多数程序员所处的环境中有许多不理想的情况:XML 文档常常有糟糕的元素名和属性名,还要应付名称空间问题。元素数据存储在属性中,一些数据甚至由管道符或分号分隔。
Java 类是继承的,对它们进行重新组织在时间和工作量方面的成本可能会超过带来的好处。这些类常常无法简洁地映射到 XML 模式(认为 XML 和数据人员会与 Java 程序员相互妥协的想法也是非常不可思议的),而且在某些情况下,即使实现了简洁映射,也肯定不会跨所有类和数据。XML 元素名可能不合适,许多 Java 变量名也可能不合适。甚至可能遇到使用 Hungarian 表示法的名称,按照这种表示法,所有成员变量都以 “m” 开头,比如 mTitle。这很不好看。
在这些情况下,您目前学到的数据绑定方法就无能为力了。XML 文档中可能会出现 Hungarian 风格的元素名,Java 类中也可能出现没有意义的结构。这种情况是无法接受的。如果不能按照您希望的方式获取和操作 XML 文档的数据,那么 Castor(或任何数据绑定框架)又有什么意义呢?
灵活数据绑定的目标
首先要注意,在 Castor 或任何其他数据绑定框架中,使用映射文件都要花一些时间。必须先学习一些新语法。尽管映射文件使用 XML 格式(大多数框架都是这样的),但是您需要学习一些新元素和属性。还必须做一些测试,确保 XML 和 Java 代码之间的相互转换产生您希望的结果。最后,如果亲自指定映射,而不是让框架处理映射,就可能在数据绑定中遇到更多的错误。例如,如果希望让框架把 XML 中的 fiddler 元素映射到 Java 代码中的 violin 属性,但是错误地声明这个属性是在 player 类中(应该是在 Player 类中),那么就会遇到错误。因此,在亲自指定映射时,必须非常注意拼写、大小写、下划线、单引号和双引号。
在学习使用映射文件之前,应该确定确实需要这么做。如果掌握了映射文件,但是却不使用它,那就是浪费时间。但是,映射确实有一些优点。
Java 代码不再受 XML 命名方式的限制
前面曾经提到,在把 XML 转换为 Java 代码时,大小写可能会导致错误。在 XML 中,最常用的做法是名称全部小写并加连字符,比如 first-name。有时候,甚至会看到 first_name。这样的名称会转换为很难看的 Java 属性名;没人愿意在代码中调用 getFirst-name()。实际上,在大多数由程序员(而不是 XML 开发人员或数据管理员)编写的文档中,往往使用驼峰式(camel-case)命名法,比如 firstName。通过使用映射文件,很容易把 XML 风格的名称(比如 first-name)映射为 Java 风格的名称(比如 firstName)。最棒的一点是,不需要强迫 XML 人员像 Java 程序员那样思考,这往往比学习新的映射语法困难得多。
XML 不再受 Java 命名方式的限制
是的,这似乎很明显。既然可以调整 XML 到 Java 的命名转换,反过来肯定也可以:在把 Java 类和属性包含的数据转换为 XML 时,可以修改 Java 名称。但是,有一个更重要,也更微妙的好处:不再受到 Java 类名和包名的限制。
这很可能成为一个组织问题。例如,在大多数情况下,XML 中的嵌套元素转换为类结构,最内层的嵌套元素转换成类属性(成员变量)。看一下清单 1 中的 XML:
清单 1. 代表图书的 XML
<?xml version="1.0" encoding="UTF-8"?> <book> <authors total-sales="0"> <last-name>Finder</last-name> <first-name>Joseph</first-name> </authors> <isbn>9780312347482</isbn> <title>Power Play</title> </book>
Castor(或任何其他数据绑定框架)可能假设您需要一个 Book 类,这个类引用几个 Author 类实例。author 类应该有成员变量 lastName 和firstName(这里会出现前面提到的命名问题,Author 中的成员变量应该是 last-name,还是 lastName?对于名字也有这个问题)。但是,如果这不是您希望的结果,应该怎么办?例如,您可能在一个称为 Person 或 Professional 的类中存储所有作家、会议演讲人和教授。在这种情况下就真有麻烦了,而且您不会愿意全面修改 XML 元素的结构和名称来解决这个问题。实际上,在这种情况下,要想原样保持 XML,使用映射是惟一的办法。
映射允许我们在 Java-XML 转换的两端指定命名方式。我们不希望由于 XML 文档的原因修改 Java 代码,同样不愿意修改 XML 结构来适应 Java 类和成员变量。另外,Java 包也会增加复杂性。尽管在 Castor 中包并不是大问题,但是仍然必须在编组的 XML 中存储 Java 类和包的相关信息,这对于业务逻辑(Java 类)和数据(XML)的隔离很不利。映射可以解决所有这些问题。
映射允许在现有环境中添加数据绑定
前两个问题(对 XML 和 Java 代码的限制)实际上与一个更大的问题相关。大多数情况下,您已经有了一组 Java 对象和一个或多个 XML 文档。因此,不具备前两篇文章中的那种自由度:不能让 Castor 根据它自己的规则把 Java 代码解组为 XML,或者为 XML 文档生成 Java 类。
相反,更为常见的情况是,您需要把一种新技术 — 数据绑定 — 添加到现有的结构中。在这种情况下,映射文件就是使用数据绑定的关键。在两个 “端点”(当前的对象模型和当前的 XML 结构)固定的情况下,映射使我们仍然能够把这两者的数据联系起来。简而言之,良好的映射系统使数据绑定能够在真实环境中发挥作用,而不仅仅停留在理论上。
一个映射场景示例
我们先来看一个简单的映射场景。在前一篇文章中,我们开发了 Book 和 Author 类。清单 2 是 Book 类。
清单 2. Book 类
package ibm.xml.castor;
import java.util.LinkedList;
import java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List<Author> authors;
public Book() { }
public Book(String isbn, String title, List<Author> authors) {
this.isbn = isbn;
this.title = title;
this.authors = authors;
}
public Book(String isbn, String title, Author author) {
this.isbn = isbn;
this.title = title;
this.authors = new LinkedList<Author>();
authors.add(author);
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthors(List<Author> authors) {
this.authors = authors;
}
public List<Author> getAuthors() {
return authors;
}
public void addAuthor(Author author) {
authors.add(author);
}
}
清单 3 是 Author 类。
清单 3. Author 类
package ibm.xml.castor;
public class Author {
private String firstName, lastName;
public Author() { }
public Author(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
}
注意:与前一篇文章相比,惟一的修改是在 Author 中删除了总销售额(totalSales 变量)。我发现它的意义不大,所以在这个版本中删除了它。
一个比较麻烦的 XML 文档
这一次不使用前一篇文章中的 XML,而是使用一个不太容易映射的 XML 文档。清单 4 给出希望绑定到 清单 2 和 清单 3 中的 Java 类的 XML 文档。
清单 4. 用于数据绑定的 XML
<?xml version="1.0" encoding="UTF-8"?> <book> <author> <name first="Douglas" last="Preston" /> </author> <author> <name first="Lincoln" last="Child" /> </author> <book-info> <isbn>9780446618502</isbn> <title>The Book of the Dead</title> </book-info> </book>
需要映射哪些数据?
在处理映射文件语法或 Castor 的 API 之前,第一个任务是判断需要把 XML(清单 4)中的哪些数据绑定到 Java 类(清单 2 和 清单 3)。请考虑一会儿。
下面简要总结一下这个 XML 文档应该如何映射到 Java 类:
book元素应该映射到Book类的一个实例。- 每个
author元素应该映射到Author类的一个实例。 - 每个
Author实例应该添加到Book实例中的authors列表中。 - 对于每个
Author实例,firstName应该设置为name元素上的first属性的值。 - 对于每个
Author实例,lastName应该设置为name元素上的last属性的值。 Book实例的 ISBN 应该设置为book-info元素中嵌套的isbn元素的值。Book实例的书名应该设置为book-info元素中嵌套的title元素的值。
其中一些映射您已经知道如何实现了。例如,book 到 Book 类实例的映射是标准的,Castor 会默认处理这个任务。但是,也有一些新东西,比如说作者。尽管把一个 author 元素映射到一个 Author 实例没什么问题,但是没有分组元素,比如 authors,它清楚地显示出所有作者属于Book 实例中的一个集合。
这里还有一些元素和属性并不直接映射到 Java 对象模型。Author 类包含表示名字和 姓氏的变量,但是在 XML 中只用一个元素(name)表示作者姓名,这个元素有两个属性。book-info 元素中嵌套的书名和 ISBN 并不映射到任何 Java 对象。
这种情况非常适合使用映射文件。它使我们能够使用这种 XML(包含我们需要的数据,但是结构不符合希望),仍然能够把文档中的数据放到 Java 对象中。而且,映射文件本身并不难编写。
基本的映射文件
Castor 中的映射是通过使用映射文件(mapping file) 实现的。映射文件仅仅是一个 XML 文档,它提供了如何在 Java 代码和 XML 之间进行转换的相关信息。因为您熟悉 XML,所以您会发现编写映射文件是非常容易的。实际上,对于简单的映射(只需修改元素名和 Java 类或成员变量的名称),只需一点儿时间就能编写好映射文件。
然后,当进行编组和解组时(前两篇文章已经介绍过如何在程序中进行编组和解组),Castor 会使用这个文件。只需对 Castor 多做一个 API 调用;其他代码都是一样的。
mapping 元素
Castor 映射文件的开始是一个普通的 XML 文档,然后是根元素 mapping。还可以引用 Castor 映射 DTD。这样就可以检验文档,确保结构和语法没有任何问题。这会大大简化对映射的调试。
清单 5 给出最基本的映射文件。
清单 5. 基本的 Castor 映射文件
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<!-- All your mappings go here -->
</mapping>
这个文件显然没有实质性内容,但它是所有映射文件的起点。
用 class 元素对类进行映射
建立基本的映射文件之后,差不多总是先要把一个 Java 类映射到一个 XML 元素。在这个示例中,需要把 Book 类映射到 book 元素中的数据。映射文件首先考虑类,所以需要添加一个 class 元素,并在这个元素的 name 属性中指定完全限定的 Java 类名,比如:
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
</class>
</mapping>
现在,可以使用 map-to 元素和 xml 属性指定这个类要映射到的 XML 元素。这个元素嵌套在 XML 元素映射到的 Java 类(完全限定,包括包名)的 class 元素中,比如:
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
<map-to xml="book" />
</class>
</mapping>
这非常简单。实际上,到目前为止,这个映射文件只实现 Castor 的默认操作。除非由于以下两个原因,否则可以删除这个部分并让 Castor 处理这个任务:
- 需要指定如何填充
Book中的某些字段,比如书名和 ISBN。 - 如果使用映射文件,那么最好指定所有内容 的映射方式。这会更明确 XML 和 Java 代码之间的配合。
把字段映射到元素
有了基本的类到元素的映射之后,就可以开始把 Book 类的字段映射到 XML 文档中的特定元素。Castor 映射文件使用 field 元素指定要使用的 Java 成员变量,使用其中嵌套的 bind-xml 元素指定映射到的 XML 元素。因此,下面的代码指定把 Book 类中的 title 变量映射到 book 元素中嵌套的 title 元素:
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
<map-to xml="book" />
<field name="Title" type="java.lang.String"> <bind-xml name="title" node="element" /> </field>
</class>
</mapping>
在这里要注意两点。首先,提供了属性名(在这个示例中是 “title”)。这是属性(property) 名,而不是成员变量名。换句话说,Castor 通过调用 set[PropertyName]() 来使用这个属性名。如果提供属性名 “foo”,Castor 就会尝试调用 setfoo() — 这可能不是您希望的情况。因此,要仔细注意大小写,并使用属性 名而不是 Java 类中的变量名。
要注意的第二点是 type 属性。这个属性向 Castor 说明数据究竟是什么类型的。在这个示例中,这很简单;但是在某些情况下,希望将以 XML 文本式数据存储的数字存储为整数、小数或者只是字符串,这时指定正确的数据类型就很重要了。另外,类型应该使用完全限定的 Java 类名,比如 java.lang.String。
在 bind-xml 元素中,指定要绑定到的 XML 元素的名称(在这个示例中是 “title”),并使用 node 属性指定是绑定到元素还是绑定到属性。这样就可以轻松地使用元素和属性数据,只需在映射文件中稍做修改即可。
指定 XML 元素的位置
但是,这里需要解决一个问题:书名和 ISBN 嵌套在 book-info 元素中,而不是直接嵌套在 book 元素中。所以需要在映射文件中指出这一情况。
当遇到这种情况时 — 一个类中的一个字段并不直接映射到与这个类对应的 XML 元素中的数据 — 就需要在 bind-xml 元素中使用 location 属性。这个属性的值应该是 XML 文档中包含您希望绑定到的数据的元素。如果绑定到元素数据,它就应该是目标元素的父 元素;如果绑定到属性数据,它就应该是包含这个属性的 元素。
因此,在这个示例中,希望把 Book 类的书名属性绑定到 title 元素的值,而这个元素嵌套在 book-info 元素中。下面是映射方法:
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
<map-to xml="book" />
<field name="Title" type="java.lang.String">
<bind-xml name="title" node="element" location="book-info"
</field>
</class>
</mapping>
然后为书的 ISBN 添加另一个字段映射:
现在,Book 类的属性都已经设置好了。该处理 Author 类了。
对其他类进行映射
按照相同的方式对其他类进行映射。惟一的差异是在其他类中不需要使用 map-to 元素。
对 Author 类进行映射
需要把 Author 类中的字段映射到 author 元素。请记住,下面是要处理的 XML 片段:
<author> <name first="Lincoln" last="Child" /> </author>
惟一需要注意的是,这里并不用两个元素分别包含名字和姓氏,而是使用一个带两个属性的元素。但是,前面已经使用过 location 属性(需要用这个属性指定 name 元素是映射到的位置)和 node 属性(可以在这里指定要绑定到属性数据,而不是元素)。所以在映射文件中需要以下代码:
现在,您应该很容易看懂这些代码。这里指定了映射到的类(Author)和这个类上要映射的属性(FirstName 和 LastName)。对于每个属性,指定要查看的 XML 元素(都是 name)并指定需要的是属性数据。
把 Book 和 Author 类链接起来
如果看一下 上面 的 XML,就会注意到并没有指定 Author 类应该映射到哪个 XML 元素。这是一个问题,因为 Castor 不会猜测您的意图;只要使用映射文件,最好指定所有映射信息。
如果每本书只有一位作者,那么在 Book 类中可能有一个 Author 属性。在这种情况下,可以在映射文件中插入以下代码:
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
<map-to xml="book" />
<field name="Title" type="java.lang.String">
<bind-xml name="title" node="element" location="book-info" />
</field>
<field name="Isbn" type="java.lang.String">
<bind-xml name="isbn" node="element" location="book-info" />
</field>
<field name="Author" type="ibm.xml.castor.Author"><bind-xml name="author" /></field>
</class>
<class name="ibm.xml.castor.Author">
<field name="FirstName" type="java.lang.String">
<bind-xml name="first" node="attribute" location="name" />
</field>
<field name="LastName" type="java.lang.String">
<bind-xml name="last" node="attribute" location="name" />
</field>
</class>
</mapping>
在这种情况下,把这一映射放在映射文件的图书部分中,因为映射的是属于 Book 类的一个属性。映射的类型指定为ibm.xml.castor.Author,并指定 XML 元素 author。这样的话,Castor 的映射系统就会使用 class 元素中的 Author 类的定义处理作者的属性。
但是,问题在于 Book 类中没有 Author 属性。相反,这个类中有一个 Authors 属性,其中包含 Author 实例的集合。因此,必须让 Castor 把每个 author 元素映射到一个 Author 实例(这一步差不多已经完成了),然后把所有实例组合成 Book 的 Authors 属性。
把元素映射到集合
为了映射图书和作者的关系,需要把几个元素(XML 文档中的每个 author)映射到一个集合,然后把这个集合分配给 Book 的 Authors 属性。
首先使用 field 元素,因为确实要映射到 Book 的一个字段。还要把 name 属性的值指定为 “Authors”,因为这是 Book 中将映射到的属性:
<field name="Authors"> </field>
接下来,需要提供属性的类型。您可能认为这应该是集合类型。但是,实际上希望指定集合中每个成员的类型。所以类型应该是 ibm.xml.castor.Author。您将会获得 ibm.xml.castor.Author 类的实例,Castor 将把这些实例放到 Authors 属性中:
<field name="Authors" type="ibm.xml.castor.Author"> </field>
下面是关键之处:使用 collection 属性指定这个属性是一个集合。这个属性的值是集合的类型。Castor 当前只支持两个值:vector(代表列表类型)和 array(代表数组类型)。通过标准的 Java 集合 API(比如 next() 等调用)访问第一种集合;管理第二种集合的方法与 Java 数组相似,按照索引来访问它们,比如 ar[2]。在这个示例中,因为 Java 类型是 List,所以使用 vector:
<field name="Authors" type="ibm.xml.castor.Author" collection="vector"> </field>
如果指定了 collection 属性,Castor 就知道应该用与 type 属性对应的值构建这个集合。因此,这里的 Authors 属性应该是ibm.xml.castor.Author 类型的实例的集合。
现在只剩下一步了:指定获取这些 Author 实例的来源。这要使用 bind-xml 元素:
<field name="Authors" type="ibm.xml.castor.Author" collection="vector"> <bind-xml name="author" /> </field>
所有工作都完成了;现在形成了一个完整的映射文件。最终的文件应该像清单 6 这样。
清单 6. 完整的映射文件
<?xml version="1.0"?>
<!DOCTYPE mapping PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN"
"http://castor.org/mapping.dtd">
<mapping>
<class name="ibm.xml.castor.Book">
<map-to xml="book" />
<field name="Title" type="java.lang.String">
<bind-xml name="title" node="element" location="book-info" />
</field>
<field name="Isbn" type="java.lang.String">
<bind-xml name="isbn" node="element" location="book-info" />
</field>
<field name="Authors" type="ibm.xml.castor.Author" collection="vector">
<bind-xml name="author" />
</field>
</class>
<class name="ibm.xml.castor.Author">
<field name="FirstName" type="java.lang.String">
<bind-xml name="first" node="attribute" location="name" />
</field>
<field name="LastName" type="java.lang.String">
<bind-xml name="last" node="attribute" location="name" />
</field>
</class>
</mapping>
在程序中使用映射文件
最后,需要在解组过程中使用这个映射文件。以前,我们静态地使用 Unmarshaller 类,通过调用 Unmarshaller.unmarshal() 把 XML 转换为 Java 代码。但是,因为现在要使用映射文件,所以需要创建一个 Unmarshaller 实例并设置一些选项。清单 7 给出的类处理从 XML 文档到 Java 对象的解组过程。
清单 7. 用映射文件进行解组
package ibm.xml.castor;
import java.io.FileReader;
import java.util.Iterator;
import java.util.List;
import org.exolab.castor.mapping.Mapping;
import org.exolab.castor.xml.Unmarshaller;
public class BookMapUnmarshaller {
public static void main(String[] args) {
Mapping mapping = new Mapping();
try {
mapping.loadMapping("book-mapping.xml");
FileReader reader = new FileReader("book.xml");
Unmarshaller unmarshaller = new Unmarshaller(Book.class);unmarshaller.setMapping(mapping);
Book book = (Book)unmarshaller.unmarshal(reader);
System.out.println("Book ISBN: " + book.getIsbn());
System.out.println("Book Title: " + book.getTitle());
List authors = book.getAuthors();
for (Iterator i = authors.iterator(); i.hasNext(); ) {
Author author = (Author)i.next();
System.out.println("Author: " + author.getFirstName() + " " +
author.getLastName());
}
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
与前两篇文章中的解组器相比,这里的更改非常少。首先,创建一个 Unmarshaller 实例,使用的参数是 Book.class。这告诉解组器要解组的顶级类是哪个类。注意,这个顶级 Java 类对应于使用 map-to 元素的 mapping 元素。然后设置映射,最后调用 unmarshal() 的非静态版本。
现在完成了!这个过程与以前的过程差异并不大。作为练习,您可以自己试着编写把 Java 代码编组为 XML 的代码。请参考前一篇文章中的BookMarshaller 类并设置映射文件,然后尝试在 XML 和 Java 代码之间来回转换。
结束语
数据绑定最终关注的是数据,而不是存储数据的格式。对于大多数 Java 程序员来说,处理 Java 对象是很容易的,而通过数据绑定,能够同样轻松地把来自各种来源(尤其是 XML)的数据转换为 Java 对象。另外,数据绑定环境中的映射甚至更进了一步:在填充 Java 对象时,可以非常灵活地处理数据源格式。因此,如果您喜欢数据绑定,那么一定也会喜欢映射;它使您能够绑定那些与您需要的命名约定不太相符的 XML 文档,也能够使用与您的 Java 对象不相符的结构。
对于数据人员,映射会带来同样的好处。当调用 Java 方法并保存在命名古怪的 XML 风格的变量中,或者 XML 文档中有多个元素全部映射到同一个类,那么不需要构建中间层就可以从 Java 类中取得所需的数据。最重要的是灵活性,能够对数据做您 想做的事情,而不受框架或工具的限制。
后续内容
您已经看到了 Castor 在 XML 环境中提供了什么。但是,这仅仅触及到了 Castor 的皮毛。在下一篇文章中,将进一步扩展简单的 XML 数据绑定并研究 Castor 的 SQL 数据绑定设施。我们将把数据从 Java 类转移到 SQL 数据库中,再转移回来,而且不需要使用 JDBC。请复习一下 XML 和 SQL 知识,下个月我们将进一步体验数据绑定的威力。
学完下一篇文章(本系列的最后一篇)之后,您就能够用相同的 API 在 XML、Java 和 SQL 数据库之间进行转换。这甚至会带来比映射文件更大的灵活性。对于所有数据存储格式,可以使用单一 API 和相似的调用处理数据库、Java 对象和 XML 文档。实际上,对于那些了解 C# 的程序员来说,这听起来非常 像 LINQ(LINQ 是 Visual C# 2008 中最新最热门的技术之一)。相似的功能已经用 Java 技术实现了,而且具有一个稳定的 API。很棒,不是吗?所以请继续研究 Castor,绑定数据,试试您能实现哪些功能。享受创造的乐趣吧!我们网上相见。
原文:http://www.ibm.com/developerworks/cn/xml/x-xjavacastor3/index.html