用OpenVINO工具包轻松实现PaddleOCR实时推理
简介:
在上篇文章中我们介绍过,光学字符识别(OCR)技术可以将文件、图片或自然场景中的文字信息进行识别并提取,与一系列的自然语言处理技术联合使用,能够完成诸如文档票据的文字信息自动化处理、实时图片文字翻译等任务。通过机器的自动化处理,可以帮助财务人员在处理票据时省却大量手工输入的工作量,也能够方便我们在出国旅游时随时对异域中的外国文字信息进行实时翻译、减少语言不通带来的不便。
既然OCR技术如此实用,有没有什么方法能让我们利用自己手边的设备,随时使用到这项技术呢?答案当然是肯定的。接下来,我们将以百度开源的PaddleOCR【1-2】技术为例,具体介绍如何利用英特尔开源的OpenVINOTM工具套件,仅使用我们手边都有的CPU就能轻松实现对PaddleOCR的实时推理。
本篇是用OpenVINOTM实现基于OCR及NLP轻松实现信息自动化提取的系列博客中的第二篇。我们将简要介绍PaddleOCR的原理,以及利用OpenVINOTM实现PaddleOCR推理加速的工作流程。同样只需利用一页Jupyter notebook,依照简单的三个步骤,即可利用CPU实现基于PaddleOCR的实时文字信息提取。
PaddleOCR原理简介
PaddleOCR是基于深度学习框架PaddlePaddle的一项OCR技术,具有超轻、模型小、便于移动端及服务器端部署等特点。整个PaddleOCR技术的工作流程如下图所示,主要包括文本检测、方向分类、以及文本识别三部分。
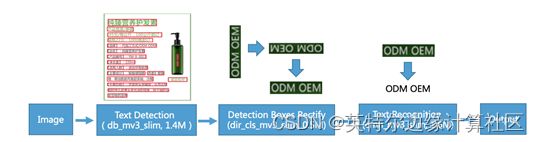
文本检测任务是找出图像或视频中的文字位置。不同于目标检测任务,目标检测不仅要解决定位问题,还要解决目标分类问题。但是,文本检测也面临一些难点,比如:自然场景中的文本具有多样性,文字大小、方向、长度、形状、语言都会有不同。有的时候,文字重叠或者密度较高,这些都会影响最终文本检测的效果。目前常用的文本检测方法有基于回归以及基于分割的方法。而在PaddleOCR中,我们选取的是基于分割的DBNet【3】方法。
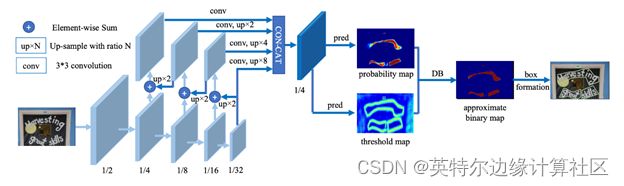
DBNet的工作原理如下图所示。针对基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时的问题,DBNet提出了一种可学习阈值的 方法,并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能。
方向分类指的是针对图片中某些经文本检测得到的bounding box中的文字方向为非水平排列的情况,对bounding box的方向进行检测。如果发现bounding box中的文字方向为非水平排列,则对该bounding box的方向进行纠正,使其旋转为文字水平排列的方向,方便下一步的文本识别。
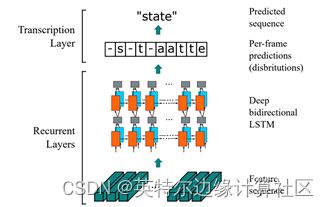
文本识别的任务是将文本检测得到的bounding box中的具体的文字内容识别出来。文本识别的算法有针对规则文本以及不规则文本识别的算法。对于规则文本,主流的算法有CTC(Conectionist Temporal Classification) 和基于Sequence2Sequence 的方法。在本文demo中,我们采用的是基于CTC的方法。由于文本识别任务的特殊性,输入数据中存在大量的上下文信息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用CNN很难挖掘到文本之间的上下文联系。为了解决这一问题,首先通过使用CRNN (Convolutional Recurrent Neural Network)【4】,利用卷积网络提取图像特征,并同时引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模。最终将输出的特征序列输入到CTC模块, 通过ctc归纳字符间的连接特性,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中, 如下图所示。
5分钟3步骤快速实现PaddleOCR实时推理
在最新版本的OpenVINOTM 2022.1中,已经实现了对基于PaddlePaddle深度学习框架的深度学习模型的支持。而PaddleOCR作为一项深受广大开发者喜爱的开源技术,其中开源的预训练模型已经可以在OpenVINOTM 2022.1版本中直接进行模型读取以及加速推理。
接下来,我们将通过代码示例,介绍如何按照简单的三个步骤,实现OpenVINOTM对PaddleOCR的加速推理。整个工作流程如下图所示:
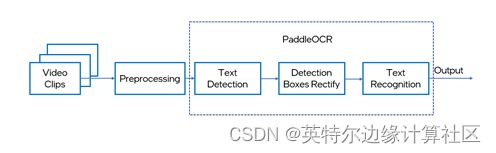
其中OpenVINOTM会对PaddleOCR中的文本检测以及文本识别模型进行读取以及推理加速。本次demo中我们展示的是利用自己的网络摄像头,将实时获取的视频流中的文字信息利用PaddleOCR进行提取。当然,开发者也可以上传图片,利用OpenVINOTM对PaddleOCR的推理实现对图片中的文字信息进行提取。
- 步骤一:下载需要使用的PaddleOCR预训练模型,并完成模型的读取与加载
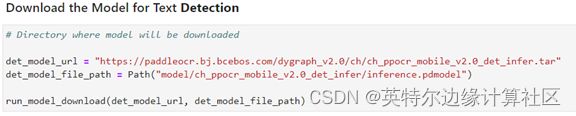
在导入需要使用到的相应Python包后,首先需要对将要使用的PaddleOCR开源预训练模型进行下载。本次demo中使用到的是轻量化的"Chinese and English ultra-lightweight PP-OCR model (9.4M)"模型。由于PaddleOCR中包含了文本检测及文本识别两个深度学习模型,因此,我们首先定义一个模型下载函数,如下图所示。

接下来,完成文本检测模型的下载,
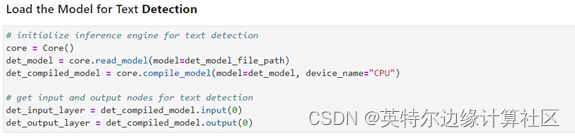
以及推理引擎的初始化、文本检测模型的读取以及在 CPU上面的加载。
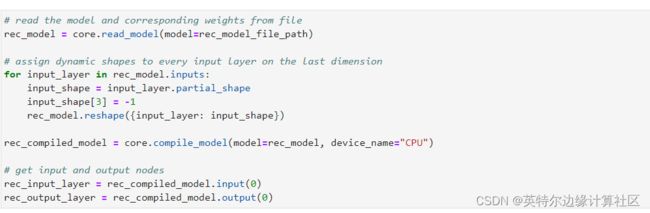
.............. 再然后,完成文本识别模型的下载,

以及文本识别模型的读取以及在CPU上面的加载。其中,有一步需要特别说明的是,动态输入的处理。由于文本识别模型的输入是文本检测得到的一系列bounding box图像,而图像中的字体由于大小和文字长短程度不一,就造成了文本识别模型的输入是动态输入的。与以往版本需要对图像尺寸进行重调整(resize)而将模型输入尺寸固定、从而可能引起性能损失的处理方法不同的是,OpenVINOTM 2022. 1版本已经可以很好的支持模型的动态输入。在CPU上进行文本识别模型加载之前,只需要对于输入的若干维度中具有动态输入的维度赋值-1或申明动态输入尺寸的上限值,比如Dimension(1,512),即可完成对模型动态输入的处理。接下来,即可按常规步骤完成在CPU上加载文本识别模型。
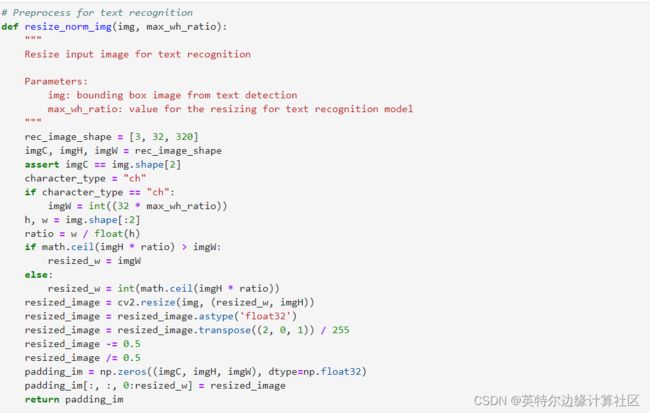
- 步骤二:为文本检测及文本识别定义必要的前处理及后处理函数。
为文本检测模型定义必要的前处理函数,如下图所示

为文本识别模型定义必要的前处理函数,如下图所示

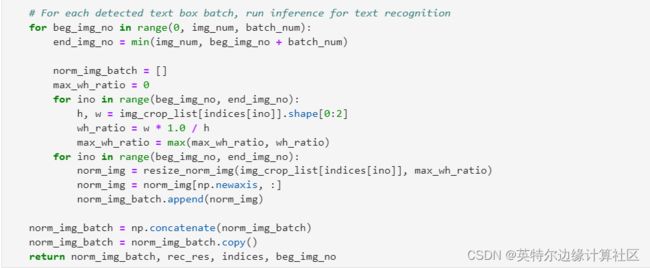
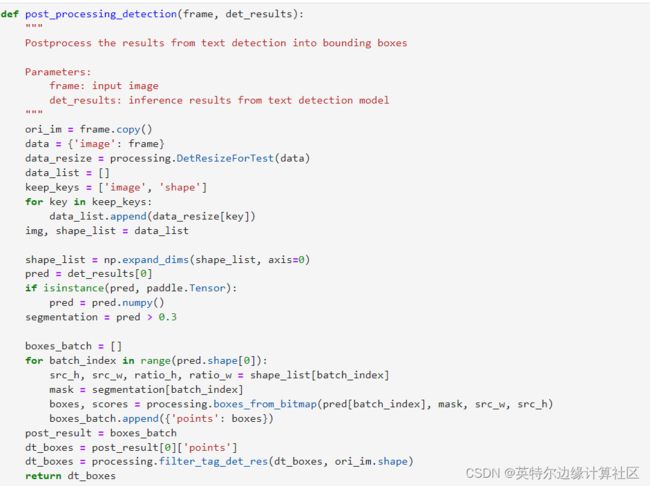
为文本检测模型定义后处理函数,将文本检测模型的推理结果转为bounding box形式,作为文本识别模型的输入,如下图所示。
- 步骤三:利用OpenVINOTM推理引擎(Runtime)针对摄像头采集视频进行实时推理
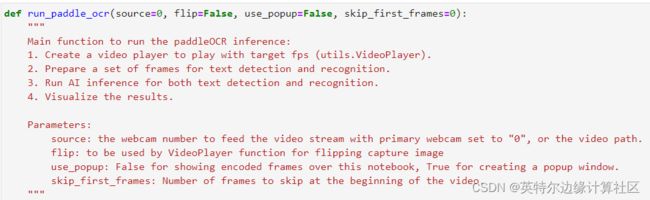
定义运行PaddleOCR模型推理的主函数,主要包括以下四个部分:
1.运行网络摄像头,将捕捉到的视频流作为paddleOCR的输入
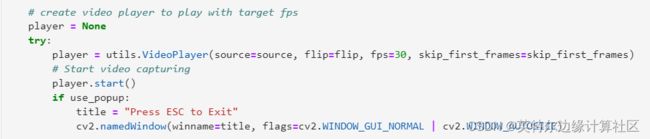
2.准备进行文本检测和文本识别的视频帧
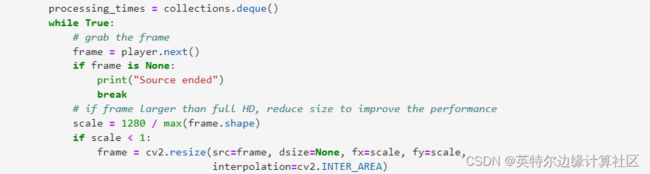
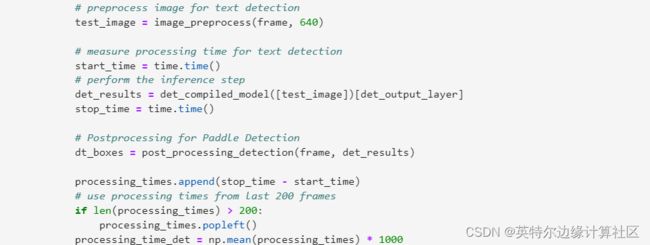
3.针对文本检测进行推理
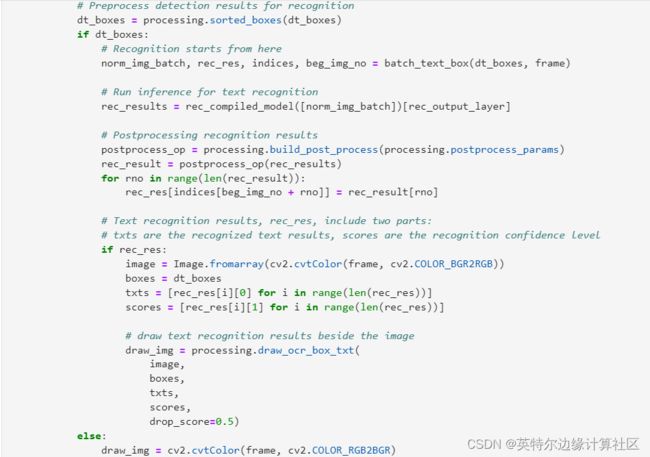
根据文本检测得到的bounding box,进行文本识别推理
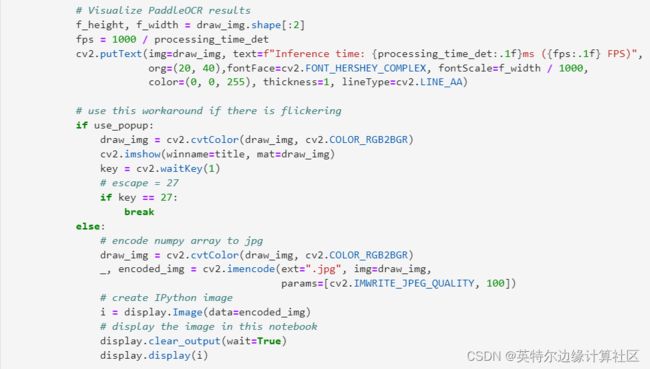
4.将文本提取的结果可视化
整个demo实现的完整代码请您参考这里,(openvino_notebooks/notebooks/405-paddle-ocr-webcam at zhuo-notebook-submission · zhuo-yoyowz/openvino_notebooks · GitHub ),下载使用。
结果讨论:
下面我们来看看运行结果吧:


[('2021年', 0.9998825),
('上海市初中英语', 0.99546415),
('考纲词汇用法手册', 0.9261546),
('配套综合练习', 0.9912483),
('本书编写组', 0.98184997),
('上海译文出版社', 0.99167067)]
我们可以看到,对于网络摄像头采集的视频流中的文字提取效果还是很不错的。仅仅利用CPU进行推理,也可以得到30FPS以上的性能,可以说能够达到实时的推理效果!当然,除了视频流作为输入,开发者还可以上传图片,进行文本信息提取。以下是针对上传图片中印刷体文字和手写体文字信息提取的一些测试效果。

[('结庐在人境品无车马喧', 0.7947353),
('问君何能尔心远地自偏采前', 0.78279585),
('东鹤下您然见南山山气日夕', 0.88027453),
('佳飞鸟相与还此中有真意欲', 0.86756784),
('辩已意言', 0.3859764)]
你还在等什么,快来根据我们提供的源代码,在自己的个人电脑上尝试一下吧!
小结:
OCR具有将图片、扫描文档或自然场景中的文字信息识别转化为数字化、机器编码方式存储的优势。将OCR进行文字识别的结果与自然语言处理中的NLP技术相结合,能够实现自动化的信息提取,为我们免去手动输入信息填写的麻烦,并有助于信息的结构化存储与查找。在本次系列博客的第二篇中,我们简要介绍了PaddleOCR的工作原理,并提供了一个基于OpenVINOTM实现PaddleOCR的Jupyter notebook demo。可以方便读者在阅读的同时,下载源码并在自己的电脑端利用CPU来轻松实现PaddleOCR的加速推理。
关于英特尔OpenVINOTM开源工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握OpenVINOTM的使用,我们还提供了一系列开源的Jupyter notebook demo。运行这些notebook,就能快速了解在不同场景下如何利用OpenVINOTM实现一系列、包括OCR在内的、计算机视觉及自然语言处理任务。OpenVINOTM notebook的资源可以在Github这里下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。
参考文献:
- Du Yuning, Chenxia Li, Guo Ruoyu, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Yu Zilin, Yehua Yang, Qingqing Dang and Haoshuang Wang. PP-OCR: A Practical Ultra Lightweight OCR System. In arXiv: Computer Vision and Pattern Recognition (2020): n. pag.
- Yuning Du, Chenxia Li, Ruoyu Guo, Cheng Cui, Weiwei Liu, Jun Zhou, Bin Lu, Yehua Yang, Qiwen Liu, Xiaoguang Hu, Dianhai Yu and Yanjun Ma. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System. In arXiv: Computer Vision and Pattern Recognition (2021): n. pag.
- Minghui Liao, Zhaoyi Wan, Cong Yao, Kai Chen and Xiang Bai. Real-Time Scene Text Detection with Differentiable Binarization. In National Conference on Artificial Intelligence (2020).
- Baoguang Shi, Xiang Bai and Cong Yao. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (2017): 2298-2304.