RetinaNet:Focal Loss for Dense Object Detection
RetinaNet:Focal Loss for Dense Object Detection
文章目录
- RetinaNet:Focal Loss for Dense Object Detection
-
- Focal Loss
- Focal loss*
- Derivatives
-
- Analysis of the Focal Loss
- RetinaNet Detector
-
- Anchor
- Classification Subnet
- Box Regression Subnet
- Experiments
- 参考
一阶段目标检测算法在训练时面临类别不平衡的问题。对一张图片,仅仅只包含几个物体,但是检测器通常会有 1 0 4 − 1 0 5 10^{4}-10^{5} 104−105个候选框。类别不平衡导致训练效率很低,因为easy negative样本会给训练提供无用的学习信号。而且类别不平衡也容易退化模型。通常的解决方法是使用hard negative mining 在训练期间挖掘困难样本。
hard negative ,困难样本,指在对负样本分类时,loss比较大的那些样本或者容易将负样本看成正样本的那些样本。 hard negative mining就是多找一些困难样本加入负样本集,进行训练,这样会比easy negative组成的负样本集效果更好。
Focal Loss
Focal loss的设计是为了解决一阶段目标检测算法前景和背景类别不平衡的问题。
对于二分类问题,假设 y ∈ { ± 1 } y \in \left\{ \pm 1\right\} y∈{±1}表示gt类别标签, p ∈ [ 0 , 1 ] p \in \left[ 0,1 \right] p∈[0,1]表示当 y = 1 y=1 y=1时模型预测的类别概率值,那么 交叉熵函数(cross entropy)定义如下:
C E ( p , y ) = { − l o g ( p ) i f y = 1 − l o g ( 1 − p ) o t h e r w i s e CE\left( p, y \right) = \left\{\begin{matrix} -log\left( p \right) \quad & if y = 1 \\ -log\left( 1- p \right) & otherwise \end{matrix}\right. CE(p,y)={−log(p)−log(1−p)ify=1otherwise
假设定义 p t p_{t} pt如下,那么CE函数重写为 C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE\left( p, y \right) = CE\left( p_{t}\right) = -log\left( p_{t}\right) CE(p,y)=CE(pt)=−log(pt)
p t = { p i f y = 1 1 − p o t h e r w i s e p_{t} = \left\{\begin{matrix} p & if \; y = 1 \\ 1 - p & otherwise \end{matrix}\right. pt={p1−pify=1otherwise
通常情况下,解决类别不平衡的方法是通过对类别 1 1 1引入权重因子 α ∈ [ 0 , 1 ] \alpha \in \left[ 0, 1 \right] α∈[0,1],对类别 − 1 -1 −1引入 1 − α 1 - \alpha 1−α。那么CE函数的一个简单扩展可定义为 C E ( p t ) = − α t l o g ( p t ) CE\left( p_{t}\right) = - \alpha_{t} log\left( p_{t}\right) CE(pt)=−αtlog(pt)。
简单分类的负例是loss的最大组成,并且主导着梯度。当参数 α \alpha α平衡正例/负例的重要性时,它并不能区分easy样本和hard样本。论文中重塑了loss函数,降低easy样本的权重,并且在训练时关注hard negatives.
在CE loss 前添加一个调制因子 ( 1 − p t ) γ \left( 1 - p_{t} \right)^{\gamma} (1−pt)γ,其中可调参数 γ ≥ 0 \gamma \geq 0 γ≥0。focal loss定义如下:
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL\left( p_{t} \right) = - \left( 1 - p_{t} \right)^{\gamma} log \left( p_{t} \right) FL(pt)=−(1−pt)γlog(pt)
下图可视化了focal loss在可调参数取值 γ ∈ [ 0 , 5 ] \gamma \in \left[ 0, 5 \right] γ∈[0,5]时的函数曲线。当一个样本被误分且 p t p_{t} pt取值较小时,调制参数 ( 1 − p t ) γ \left( 1 - p_{t} \right)^{\gamma} (1−pt)γ接近于1,loss不受影响。随着 p t p_{t} pt越接近于1, ( 1 − p t ) γ \left( 1 - p_{t} \right)^{\gamma} (1−pt)γ接近于0,对于分类正确的样本,loss值的权重被降低。参数 γ \gamma γ平滑地调整easy样本的加权速率。当参数 γ = 0 \gamma=0 γ=0,FL等价于CE,随着 γ \gamma γ的增加,调制参数的影响也随之增加。在论文中的实验,它们发现当 γ = 2 \gamma=2 γ=2时,表现最好。
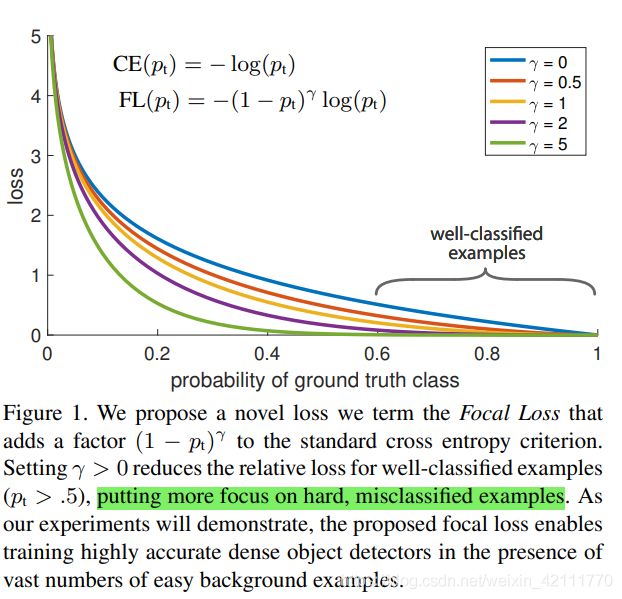
调制因子减少easy样本的loss贡献并且扩展样本接收低loss的范围。例如,设定 γ = 2 \gamma=2 γ=2,当一个样本被正确分类,且它的概率取值 P t = 0.9 P_{t}=0.9 Pt=0.9时, C E ( p t = 0.9 ) = − l o g ( 0.9 ) CE \left( p_{t} = 0.9 \right) = - log \left( 0.9 \right) CE(pt=0.9)=−log(0.9), F L ( p t = 0.9 ) = − ( 1 − 0.9 ) 2 l o g ( 0.9 ) = 1 / 100 C E ( p t = 0.9 ) FL\left( p_{t} = 0.9 \right) = - \left( 1- 0.9 \right)^{2} log \left( 0.9 \right) = 1/100CE\left( p_{t} = 0.9 \right) FL(pt=0.9)=−(1−0.9)2log(0.9)=1/100CE(pt=0.9),调制因子的存在使得此样本的FL值是CE函数值的 1 / 100 1/100 1/100倍。当 P t ≈ 0.968 P_{t} \approx 0.968 Pt≈0.968时,将会有1000倍的差异。当 p t ≤ 0.5 时 p_{t} \leq 0.5时 pt≤0.5时,样本被错误分类时, F L ( p t ≤ 0.5 ) ≤ − ( 1 − 0.5 ) 2 l o g ( p t ) = 1 4 C E ( p t ≤ 0.5 ) FL\left( p_{t} \leq 0.5 \right) \leq - \left( 1- 0.5 \right)^{2} log \left( p_{t} \right) = \frac{1}{4}CE\left( p_{t} \leq 0.5 \right) FL(pt≤0.5)≤−(1−0.5)2log(pt)=41CE(pt≤0.5),loss最多下降四倍,这增加了纠正错误分类样本的重要性。
添加 α \alpha α参数平衡focal loss,实验验证带有 α \alpha α参数的focal loss能够比没有参数 α \alpha α的focal loss提高模型性能。
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL\left( p_{t} \right) = - \alpha_{t} \left( 1 - p_{t} \right)^{\gamma} log \left( p_{t} \right) FL(pt)=−αt(1−pt)γlog(pt)
Focal loss*
focal loss* 是另一种focal loss的实例演示。首先,定义变量 x t x_{t} xt为 x t = y x x_{t} = yx xt=yx,然后设定 p t = σ ( x t ) p_{t} = \sigma \left( x_{t} \right) pt=σ(xt)。当 x t > 0 x_{t} > 0 xt>0时, p t > 0.5 p_{t} > 0.5 pt>0.5,样本被正确分类。下一步,以 x t x_{t} xt的形式,定义focal loss的另一种形式。
p t ∗ = σ ( γ x t + β ) F L ∗ = − l o g ( p t ∗ ) / γ \begin{matrix} p_{t}^{*} &= \sigma \left( \gamma x_{t} + \beta \right) \\ FL^{*} &= - log\left( p_{t}^{*} \right) / \gamma \end{matrix} pt∗FL∗=σ(γxt+β)=−log(pt∗)/γ
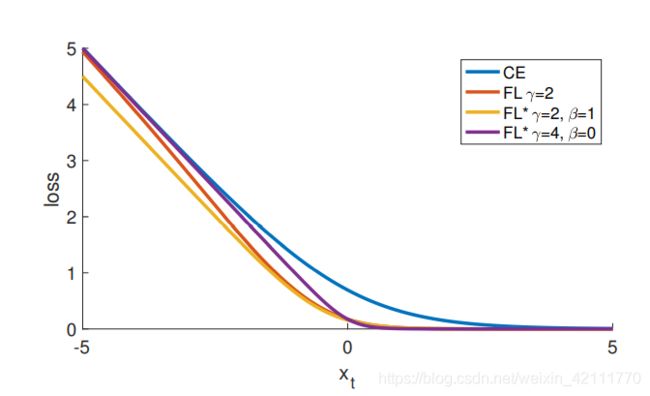
FL有两个参数, γ \gamma γ和 β \beta β,控制loss曲线的坡度和偏倚。下图是FL选择不同参数和CE,FL的曲线图。从图中可以看出,FL和FL*减少分配给分类良好样本的loss值。
Derivatives
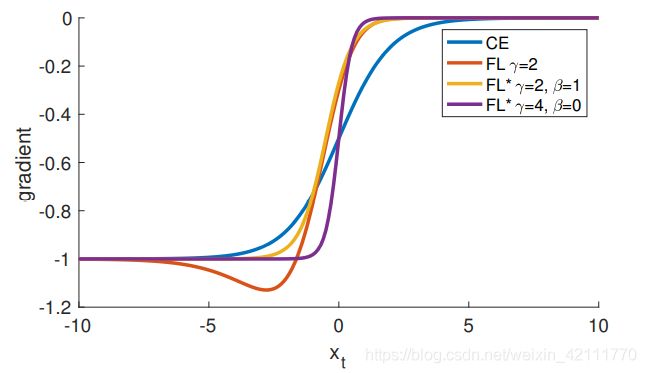
下面是CE,FL和FL的导数,下图是CE,FL和FL导数的图像展示。对所有的loss函数来说,对有高置信度的预测来说,导数值趋近于-1或者0。与CE不同的是,当 x t > 0 x_{t} > 0 xt>0时,FL和FL*的导数值绝对值较小。
d C E d x = y ( p t − 1 ) d F L d x = y ( 1 − p t ) γ ( γ p t l o g ( p t ) + p t − 1 ) d F L ∗ d x = y ( p t ∗ − 1 ) \begin{matrix} \frac{dCE}{dx} = y\left( p_{t} - 1 \right) \\ \frac{dFL}{dx} = y\left( 1 - p_{t} \right)^{\gamma} \left( \gamma p_{t} log\left( p_{t}\right) + p_{t} - 1 \right) \\ \frac{dFL^{*}}{dx} = y\left( p_{t}^{*} - 1 \right) \end{matrix} dxdCE=y(pt−1)dxdFL=y(1−pt)γ(γptlog(pt)+pt−1)dxdFL∗=y(pt∗−1)
# This method is only for debugging
def py_sigmoid_focal_loss(pred,
target,
weight=None,
gamma=2.0,
alpha=0.25,
reduction='mean',
avg_factor=None):
"""PyTorch version of `Focal Loss `_.
Args:
pred (torch.Tensor): The prediction with shape (N, C), C is the
number of classes
target (torch.Tensor): The learning label of the prediction.
weight (torch.Tensor, optional): Sample-wise loss weight.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
alpha (float, optional): A balanced form for Focal Loss.
Defaults to 0.25.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
"""
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
focal_weight = (alpha * target + (1 - alpha) *
(1 - target)) * pt.pow(gamma)
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
if weight is not None:
if weight.shape != loss.shape:
if weight.size(0) == loss.size(0):
# For most cases, weight is of shape (num_priors, ),
# which means it does not have the second axis num_class
weight = weight.view(-1, 1)
else:
# Sometimes, weight per anchor per class is also needed. e.g.
# in FSAF. But it may be flattened of shape
# (num_priors x num_class, ), while loss is still of shape
# (num_priors, num_class).
assert weight.numel() == loss.numel()
weight = weight.view(loss.size(0), -1)
assert weight.ndim == loss.ndim
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss
Analysis of the Focal Loss
为了能够更好地理解focal loss,论文中分析了收敛loss模型的经验分布。默认backbone为ResNet101, γ = 2 \gamma=2 γ=2,输入图像为600像素的模型。首先用模型预测大量的随机图片,然后挑选 1 0 7 10^{7} 107个预测概率为负例的bbox和 1 0 5 10^{5} 105和预测为正例的bbox。接下来,分开正例和负例,计算这些样本的FL值,然后normalize loss值以便总和为1。最后一句依据normalized loss从低到高进行排序,并分别为正例和负例画出它们在不同 γ \gamma γ下的累计分布函数。
观察下图正例的累计分布函数,对于不同的 γ \gamma γ值,它们的CDF很相近。然而负例的CDF 曲线受 γ \gamma γ影响很大。当 γ = 0 \gamma = 0 γ=0时,正例和负例的CDF是相似的。随着 γ \gamma γ值增加,更多的关注集中在hard negative 样本上。当 γ = 2 \gamma=2 γ=2时,loss的绝大部分来自于一小部分样本。可以看出,FL能够有效地降低easy negative的影响,将更多的注意力放在hard negative 样本上。

累计分布函数(cumulative Distribution Function,CDF)是概率密度函数的积分,能完整描述一个实随机变量 X X X的概率分布。 F X ( x ) = P ( X ≤ x ) F_{X}\left( x \right) = P\left( X \leq x \right) FX(x)=P(X≤x)
RetinaNet Detector
RetinaNet是一个简单的统一的网络,由backbone网络和两个特定任务子网络组成。backbone选用Resnet和FPN架构,构建 P 3 P_{3} P3到 P 7 P_{7} P7的特征图金字塔,其中 P l P_{l} Pl中的 l l l表示 2 l 2^{l} 2l个像素低于输入图像。金字塔每层的特征都有256个通道。
P 3 P_{3} P3到 P 7 P_{7} P7的特征是从相应的Resnet阶段计算得来( C 3 C_{3} C3到 C 5 C_{5} C5), P 6 P_{6} P6由 C 5 C_{5} C5后接一个 3 × 3 3\times 3 3×3卷积核,步长为 2 2 2的卷积层得到, P 6 P_{6} P6同样后接一个同样的卷积,并计算ReLU函数得到 P 7 P_{7} P7。 P 6 P_{6} P6使用卷积步长代替下采样, P 7 P_{7} P7是为了提高大目标的检测。这些微调在保证准确率的同时提升速度。

Anchor
特征金字塔 P 3 P_{3} P3到 P 7 P_{7} P7,anchor的面积依次是 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \left\{ 32^{2},64^{2},128^{2},256^{2},512^{2}\right\} {322,642,1282,2562,5122}。anchor的aspect ratio为 { 1 : 2 , 1 : 1 , 2 : 1 } \left\{ 1:2, 1:1, 2:1 \right\} {1:2,1:1,2:1},anchor的scale大小为 { 2 0 , 2 1 / 3 , 2 2 / 3 } \left\{ 2^{0}, 2^{1/3}, 2^{2/3} \right\} {20,21/3,22/3},每一特征层共有 A = 9 A=9 A=9个anchors。
anchors依据IoU值进行正负例判定。当一个anchor的 I o U ≥ 0.5 IoU \geq 0.5 IoU≥0.5时,这个anchor则被设为gt目标框;当一个anchor的 0 ≤ I o U < 0.4 0 \leq IoU < 0.4 0≤IoU<0.4,这个anchor则被认为是背景框;当一个anchor的 0.4 ≤ I o U < 0.5 0.4 \leq IoU < 0.5 0.4≤IoU<0.5,在训练时,忽略这个anchor。
Classification Subnet
分类子网络是与FPN每一层特征图相连接的一个小的全卷积网络FCN,它预测特征图上每一个空间位置上 A A A个anchor分别在 K K K目标物体上的概率。分类子网络的参数对FPN不同层次特征图是共享的。以FPN上任意一个具有 C C C通道的特定特征图为输入,经过 4 4 4个卷积大小为 3 × 3 3 \times 3 3×3,通道为 C C C,激活函数为ReLU的卷积层后,进入具有 K A KA KA个filters的 3 × 3 3 \times 3 3×3卷积层。
Box Regression Subnet
回归子网络和分类子网络结构类似,只是输出方式有所不同。分类子网络和回归子网络平行存在,参数各异,不共享。
Experiments
初始化:对于backbone,ResNet-50/Resnet101需在数据集ImageNet1k上进行预训练。对于RetinaNet自网络上除了最后一层的所有新卷积层,初始偏置量为 b = 0 b=0 b=0,初始权重为 σ = 0.01 \sigma=0.01 σ=0.01的高斯。对于分类子网络中的最后一层卷积,初始偏置量 b = − l o g ( ( 1 − π ) / π ) b=-log\left( \left( 1 - \pi \right) / \pi \right) b=−log((1−π)/π)。
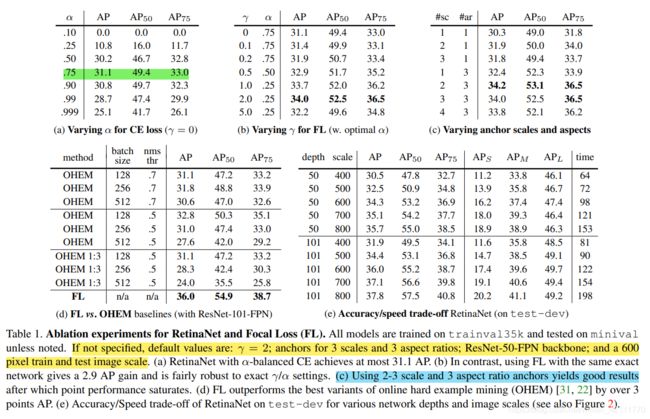
上图是对RetinaNet和focal loss的 ablation实验。如果没有特殊制定,默认 γ = 2 , α = 0.25 \gamma=2, \alpha=0.25 γ=2,α=0.25,anchor默认3个scale和3个aspect ratios。
inference阶段,为了提升速度,对于FPN每一层,设置检测置信度为0.05, 阈值选择后,至多选取前1k分数较高的预测框进行解码,然后合并FPN所有层的候选框,再进行NMS操作,NMS阈值为0.05,生成最后的检测结果。
参考
- Focal Loss for Dense Object Detection