深度学习之——损失函数(loss)
深度学习中的所有学习算法都必须有一个 最小化或最大化一个函数,称之为损失函数(loss function),或“目标函数”、“代价函数”。损失函数是衡量模型的效果评估。比如:求解一个函数最小点最常用的方法是梯度下降法:梯度下降详解
(比如:全批量梯度下降 Batch GD、随机梯度下降 SGD、小批量梯度下降 mini-batch GD、Adagrad法,Adadelta法、Adam法等)。损失函数就像起伏的山,梯度下降就像从山上滑下来到达最底部的点。
显然,不存在一个损失函数可以适用于所有的任务。损失函数的选择需要取决于很多因素,其中包括异常值的处理、深度学习算法的选择、梯度下降的时间效率等。本文的目的介绍损失函数,以及它们的基本原理。
损失函数(Loss_function):
在前面的学习中我们学习过机器学习模型(分类、回归、聚类,降维):机器学习基本模型介绍,在深度学习中:损失函数严格上可分为两类:分类损失和回归损失,其中分类损失根据类别数量又可分为二分类损失和多分类损失。在使用的时候需要注意的是:回归函数预测数量,分类函数预测标签。
1、均方差损失(MSE)
均方差 Mean Squared Error (MSE) 损失是机器学习、深度学习回归任务中最常用的一种损失函数。从直觉上理解均方差损失,这个损失函数的最小值为 0(当预测等于真实值时),最大值为无穷大。MSE就是计算预测值和真实值之间的欧式距离。预测值和真实值越接近,两者的均方差就越小,均方差函数常用于线性回归(linear regression),即函数拟合(function fitting)。
均方差损失函数是预测数据和原始数据对应点误差的平方和的均值,公式为:
![]()
N:样本个数, :样本真实值,y为输出值
:样本真实值,y为输出值
MSE代码实现:
import torch.nn as nn
import torch
import random
#MSE损失参数
# loss_fun=nn.MSELoss(size_average=None, reduce=None, reduction='mean')
input=torch.randn(10)#定义输出(随机的1,10的数组)可以理解为概率分布
#tensor([-0.0712, 1.9697, 1.4352, -1.3250, -1.1089, -0.5237, 0.2443, -0.8244,0.2344, 2.0047])
print(input)
target= torch.zeros(10)#定义标签
target[random.randrange(10)]=1#one-hot编码
#tensor([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.])
print(target)
loss_fun= nn.MSELoss()
output = loss_fun(input, target)#输出,标签
print(output)#loss:tensor(0.8843)
#=============不用nn.MSELoss实现均方差===================
result=(input-target)**2
result =sum(result)/len(result)#求和之后求平均
print(result)#tensor(0.8843)
#其结果和上面一样注意:若多分类任务中要使用均方差作为损失函数,需要将标签转换成one-hot编码形式:one-hot编码,这与交叉熵损失函数恰巧相反。均方差不宜和sigmoid函数一起使用(sigmoid函数有一个特点,那就是横坐标越远离坐标原点,导数越接近于0,当输出越接近1时导数越小,最终会造成梯度消失。)
2、交叉熵损失(Cross Entropy)
关于交叉熵损失函数的来厉和介绍我在这篇文章里有详细阐述:深度学习入门理解——从概率和信息的角度(数学篇后记)
我们现在可以这样它理解:在机器学习中,使用KL散度就可以评价真实标签与预测标签间的差异,但由于KL散度的第一项是个定值,故在优化过程中只关注交叉熵就可以了。一般大多数机器学习算法会选择交叉熵作为损失函数。
根据交叉熵的公式:

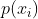 代表真实标签,在真实标签中,除了对应类别其它类别的概率都为0,所以可以简写为:
代表真实标签,在真实标签中,除了对应类别其它类别的概率都为0,所以可以简写为:
![]()
这里的![]() 代表标签(label)
代表标签(label)
Cross Entropy代码实现:
#交叉熵
import torch.nn as nn
nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
import torch
import torch.nn as nn
# #假设batch size为4,待分类标签有3个,隐藏层的输出为:
input = torch.tensor([[ 0.8082, 1.3686, -0.6107],#1
[ 1.2787, 0.1579, 0.6178],#0
[-0.6033, -1.1306, 0.0672],#2
[-0.7814, 0.1185, -0.2945]])#取1
target = torch.tensor([1,0,2,1])#假设标签值(不是one-hot编码,直接代表类别)
loss = nn.CrossEntropyLoss()#定义交叉熵损失函数(自带softmax输出函数)
output = loss(input, target)
print(output)#tensor(0.6172)
#======不用 nn.CrossEntropyLoss(),解释其计算方法======
net_out=nn.Softmax(dim=1)(input)#input前面已经定义
print(net_out)
out= torch.log(net_out)#对每个size(每行求log)
"""
tensor([[-1.0964, -0.5360, -2.5153],
[-0.6111, -1.7319, -1.2720],
[-1.2657, -1.7930, -0.5952],
[-1.6266, -0.7267, -1.1397]])
"""
print(out)
#根据公式求和
out=torch.max(out,dim=1)#我们默认取每个size的输出最大值为类别
print(out)
"""
torch.return_types.max(
values=tensor([-0.5360, -0.6111, -0.5952, -0.7267]),
indices=tensor([1, 0, 2, 1]))
"""
#tages=(1,0,2,2),这里的输出out就是每一个size(样本)的交叉熵损失
#别忘了除以batch size(4),我们最后求得的是整个batch(批次,一批次4个样本)的平均loss
#out求和再除以size(4)————————求平均
out_Input=-torch.mean(out.values)#这里求平均时只取max输出的values
print(out_Input)#tensor(0.6172)
注意:除了torch.nn.CrosEntropyLoss()函数外还有一个计算交叉熵的函数torch.nn.BCELoss(),与前者不同,该函数是用来计算二项分布(0-1分布)的交叉熵(含sigmiod输出函数)。
总结:
由于本人现阶段能力有限,没办法对这两个函数进行细致的比较,也没有了解更多的损失函数,还望见谅,后面通过学习,我会慢慢完善。
总的来说MSE要得到一个线性的梯度,必须输出不经过激活函数才行。这样的情况只有线性回归,所以SE较适合做回归问题,而CE更适合做分类问题,在分类问题中,CE都能得到线性的梯度,能有效的防止梯度的消失;MSE作为分类问题的loss时,由于激活函数求导的影响,造成连续乘以小于1大于0的数造成梯度的消失,同时也使得error曲面变的崎岖,更慢的到的局部最优值。