【计算机视觉】计算机视觉与深度学习-09-可视化-北邮鲁鹏老师课程笔记
计算机视觉与深度学习-10-可视化-北邮鲁鹏老师课程笔记
- 可视化
- 第一层可视化
- 第一层之后可视化
- 中间层可视化
-
-
- 可视化激活图
- 最大化激活块
-
- 倒数第二个全连接层
-
-
- 最邻近
- 降维
-
- 哪些像素对分类不起作用
-
- 遮挡实验(Occlusion Experiments)
- 显著图(Saliency Map)
-
- 基于显著图的图像分割
- 如何判断神经网络是否过拟合欠拟合?
-
- 方式一:观察损失函数
- 方式二:反向可视化
- 梯度上升 Gradient Ascent
- 虚假图像
- Deep Dream
- 特征反演(Feature Inversion)
- 纹理生成(Texture Synthesis)
-
- 近邻法
- 格莱姆矩阵(Gram Matrix)
- 神经纹理生成(Neural Texture Synthesis)
- 风格迁移(Style Transfer)
-
- 调整内容权重和纹理权重
- 调整纹理图像尺寸
- 多风格图生成
- 快速风格迁移(Fast style Transfer)
-
- 实例归一化
- 可视化工具Keras-vis
可视化
显示出神经网络在做什么。
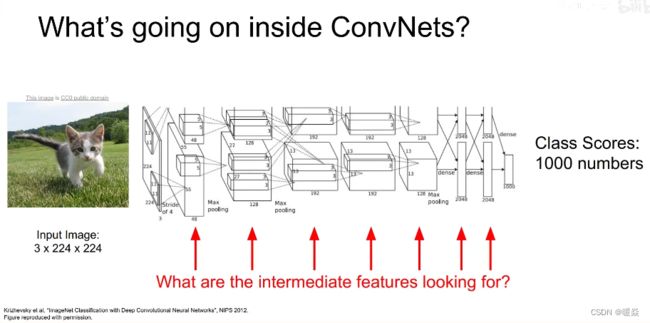
第一层可视化
第一层卷积核的维度与图像通道相同是3,容易可视化。
第一个卷积层相对比较简单,可以把第一层的所有卷积核可视化来描述卷积层在原始图像上寻找什么。之所以可视化卷积核,是因为卷积就是卷积核与图像区域做内积的结果,当图像上的区域和卷积核很相似时,卷积结果就会最大化。所以可以利用可视化卷积核来观察卷积层在图像上寻找什么。常见的CNN架构第一层卷积核如下:

第一层之后可视化
第一层之后的可视化,建立在特征图上,但是特征图通道为1,单通道的可视化肉眼看不出什么规律,需要通过其他方法分析。

中间层可视化
可视化激活图
与可视化卷积核相比,将激活图可视化更有观察意义。比如可视化AlexNet的第五个卷积层的128个13x13的特征图,输入一张人脸照片,画出Conv5的128个特征灰度图,发现其中有激活图似乎在寻找人脸。不过大部分都是噪声。
通过分析,可以知道哪些神经元对特征图像的哪些区域感兴趣。

最大化激活块
观察卷积核记录了什么,对哪些东西感兴趣。
不同的特征图是不同卷积核卷积结果,不同卷积核关注的内容不同,虽然特征图无法可视化,但可以从外部输入一些不同的信号,观察神经网络中的响应。

可视化输入图片中什么类型的小块可以最大程度的激活不同的神经元。比如选择AlexNet的Conv5里的第17个激活图(共128个),然后输入很多的图片通过网络,并且记录它们在Conv5第17个激活图的值。这个特征图上部分值会被输入图片集最大激活,由于每个神经元的感受野有限,我们可以画出这些被最大激活的神经元对应在原始输入图片的小块,通过这些小块观察不同的神经元在寻找哪些信息。如下图所示,每一行都是某个神经元被最大激活对应的图片块,可以看到有的神经元在寻找类似眼睛的东西,有的在寻找弯曲的曲线等。如果不使用Conv5的激活图,而是更后面的卷积层,由于卷积核视野的扩大,寻找的特征也会更加复杂,比如人脸、相机等,对应下图的下面部分。

倒数第二个全连接层
最邻近
另一个有价值的观察对象是输入到最后一层用于分类的全连接层的图片向量,比如AlexNet每张图片会得到一个4096维的向量。使用一些图片来收集这些特征向量,然后在特征向量空间上使用最邻近的方法找出和测试图片最相似的图片。作为对比,是找出在原像素上最接近的图片。可以看到,在特征向量空间中,即使原像素差距很大,但却能匹配到实际很相似的图片。比如大象站在左侧和站在右侧在特征空间是很相似的。

降维
另一个观察的角度是将4096维的向量压缩到二维平面的点,方法有PCA,还有更复杂的比如 t-SNE(t-distributed stochastic neighbors embeddings,t-分布邻域嵌入),是一个在深度学习中将特征非线性降维的常用方法。比如手写数字0-9的图片提取特征降到2维画出后,发现都是按簇分布的,分成10簇。如下图所示:
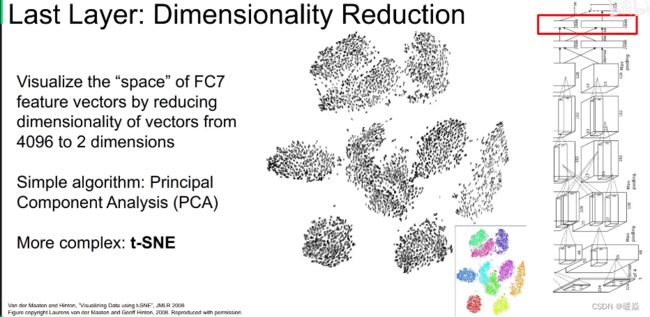
同样可以把这个方法用到AlexNet的4096维特征向量降维中。我们输入一些图片,得到它们的4096维特征向量,然后使用 t-SNE 降到二维,画出这些二维点的网格坐标,然后把这些坐标对应的原始图片放在这个网格里。然后可以发现,相似内容的图片都聚集在一起,比如左下角都是一些花草,右上角聚集了蓝色的天空。


哪些像素对分类不起作用
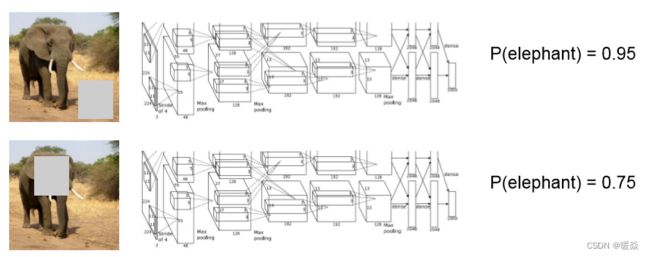
遮挡实验(Occlusion Experiments)
在图片输入网络前,将图片的部分区域遮挡,然后观察对预测概率的影响。导致预测概率降低的部分说明是对分类决策起重要作用的部分。

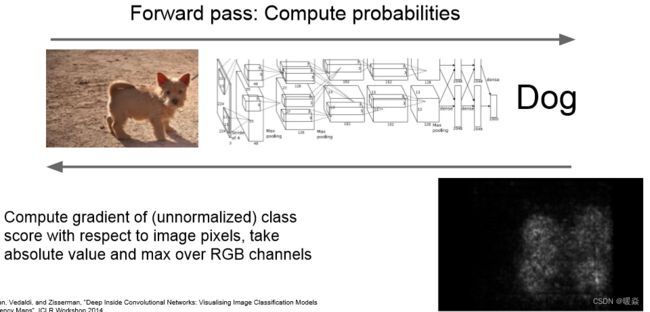
显著图(Saliency Map)
Saliency Maps简单来说可以理解为是用来做模型的解释,可以用来知道哪些变量对于模型来说是重要的。我们也可以理解为Saliency map即特征图,可以告诉我们图像中的像素点对图像分类结果的影响。
给一张狗的图片和它对应的标签,我们想知道图像的哪一些像素对分类的结果影响最大。遮挡是一个方法,显著图从另一个角度来解决这个问题。方法是计算分类得分相对于图像像素的梯度,这将告诉我们在一阶近似意义上对于输入图片的每个像素如果我们进行小小的扰动,那么相应分类的分值会有多大的变化。可以看到基本上找出了小狗的轮廓。
进行语义分割的时候也可以运用显著图的方法,可以在没有任何标签的情况下可以运用显著图进行语义分割。

基于显著图的图像分割

参考:Saliency Maps的原理与简单实现(使用Pytorch实现)
论文:Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps – Karen Simonyan, Andrea Vedaldi, Andrew Zisserman
参考:Lecture 12 可视化和理解CNN – HRain
如何判断神经网络是否过拟合欠拟合?
方式一:观察损失函数
观察验证集和训练集上的损失函数是否都在下降,如果验证集上出现了上升,说明模型过拟合。
方式二:反向可视化
观察学习到的图像显著信息是否和人眼识别的图像显著信息是否是一个区域。如果相同,则模型正确。
如果学习到的图像显著区域和人眼识别的图像显著区域不在一个区域,则模型有错误。


梯度上升 Gradient Ascent
引导式反向传播会寻找与神经元联系在一起的图像区域,另一种方法是梯度上升,合成一张使神经元最大激活或分类值最大的图片。
在训练神经网络时用梯度下降来使损失最小,现在要修正训练的卷积神经网络的权值,并且在图像的像素上执行梯度上升来合成图像,即最大化某些中间神将元和类的分值来改变像素值。
在执行梯度上升过程中,输入一张所有像素为0或者高斯分布的初始图片,训练过程神经网络中的权重保持不变,计算神经元的值或这个类的分值相对于像素的梯度,使用梯度上升改变一些图像的像素使这个分值最大化。同时,需要正则项来阻止生成的图像过拟合,生成很奇怪的东西。
总之,生成图像具备两个属性:1 使最大程度地激活分类得分或神经元的值,2 使希望生成的这个图像看起来是自然的。正则项强制生成的图像看起来是自然的图像。

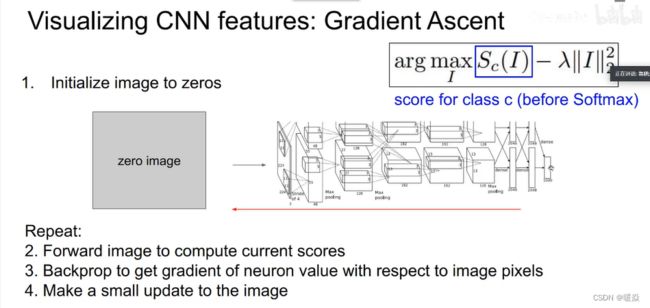
比如使用L2正则来约束像素,正则项作用在图像上。针对分类得分生成的图片如下所示:



层数越高,语义越丰富,生成的结构越复杂。
也可以使用一些其他方法来优化正则,比如对生成的图像进行高斯模糊处理、将像素值特别小或梯度值特别小的值去掉。这些方法会使生成的图像更清晰。也可以针对某个神经元进行梯度上升。


添加多模态(multi-faceted)可视化可以提供更好的结果(加上更仔细的正则化,中心偏差)。
正则项作用在FC6而不是原始图像上,会得到更加自然的图像。

虚假图像


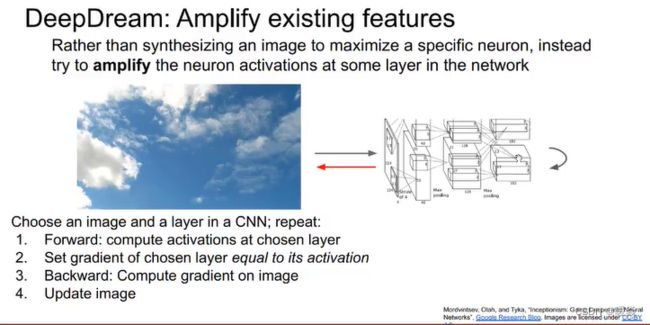
Deep Dream
仍然利用梯度上升的原理,不再是通过最大化神经元激活来合成图片,而是直接放大某些层的神经元激活特征。首先选择一张输入的图像,通过神经网络运行到某一层,接着进行反向传播并且设置该层的梯度等于激活值,然后反向传播到图像并且不断更新图像。对于以上步骤的解释:试图放大神经网络在这张图像中检测到的特征,无论那一层上存在什么样的特征,现在我们设置梯度等于特征值,以使神经网络放大它在图像中所检测到的特征。


特征反演(Feature Inversion)
特征反演是为了查看不同层的特征向量能保留多少原始的图片信息。
任选一张图片,前向传播到已经训练好的CNN,选取其在CNN某一层产生的特征向量,记住这个向量。现在,我们要生成一张图片,尽量让它在该层产生一样的特征向量。这个任务仍然是用梯度上升来做,目标函数定义为最小化生成图片的特征向量与给定特征向量的L2距离,并且加一些正则化项保证生成图片的平滑:
 用这种方法,可以看到不同层的特征向量所包含的信息完整度:
用这种方法,可以看到不同层的特征向量所包含的信息完整度:
 在relu2_2层,可以根据特征向量几乎无损地恢复出原图片;但是尝试从ReLU4_3 ReLU5_1重构图像时,可以看到图像的一般空间结构被保留了下来,仍可以分辨出大象,苹果和香蕉。但是许多低层次的细节并比如纹理、颜色在神经网路的较高层更容易损失。
在relu2_2层,可以根据特征向量几乎无损地恢复出原图片;但是尝试从ReLU4_3 ReLU5_1重构图像时,可以看到图像的一般空间结构被保留了下来,仍可以分辨出大象,苹果和香蕉。但是许多低层次的细节并比如纹理、颜色在神经网路的较高层更容易损失。
纹理生成(Texture Synthesis)
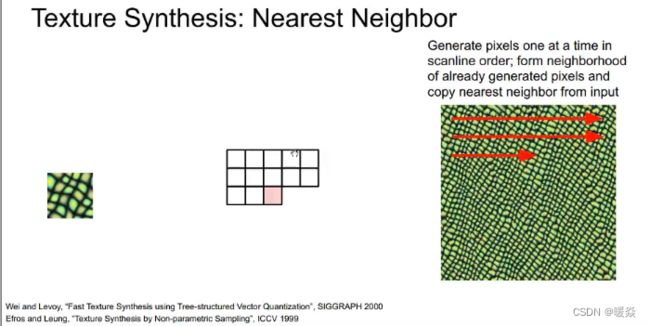
近邻法
传统的纹理生成方法有近邻法。根据已经生成的像素查看当前像素周围的邻域,并在输入图像的图像块中计算近邻,然后从输入图像中复制像素。
但是近邻法只适用于简单的纹理,当原图像使用的是复杂纹理时,直接从输入图像的图像块复制像素的方法可能会行不通。


格莱姆矩阵(Gram Matrix)
将一张图片传入一个已经训练好的CNN,选定其中一层激活,其大小是CxHxW,可以看做是H x W 个C维向量。从这个激活图中任意选取两个C维向量,做矩阵乘法可以得到一个 CxC 的矩阵。然后对激活图中任意两个C维向量的组合,都可以求出这样一个矩阵。把这些矩阵求和并平均,就是Gram Matrix。
格莱姆矩阵告诉我们两个点代表的不同特征的同现关系,矩阵中位置索引为 ij 的元素值非常大,这意味着这两个输入向量的位置索引为 i 和 j 的元素值非常大。这以某种方式捕获了一些二阶统计量,即映射特征图中的哪些特征倾向于在空间的不同位置一起激活,这就是纹理。
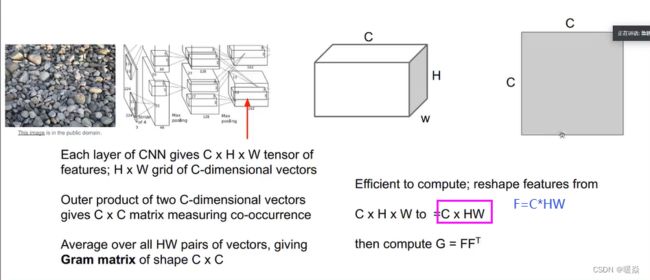
Gram Matrix其实是feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵)。其计算了每个通道特征之间的相关性,考察哪些特征是此消彼长的,哪些特征是同时出现的。我们认为Gram Matrix度量了图片中的纹理特性,并且不包含图像的结构信息,因为我们对图像中的每一点所对应的特征向量取平均值,它只是捕获特征间的二阶同现统计量,这最终是一个很好的纹理描述符。事实上,使用协方差矩阵代替Gram Matrix也能取得很好的效果,但是Gram Matrix有更高效的计算方法:将激活图张量C*H*W展开成C*HW的形式,然后将其乘以其转置,即得到gram矩阵。
神经纹理生成(Neural Texture Synthesis)
当有了Gram矩阵这一度量图像纹理特性的工具后,就可以使用类似于梯度上升算法来产生特定纹理的图像。算法流程为:
 首先使用ImageNet的数据预训练一个VGG网络,然后把含有纹理的图像输入到VGG网络,记录其每一层的激活图并计算每一层的gram矩阵。接着随机初始化一张要生成的新的图像,同样把这张初始化图像通过VGG并且计算每一层的gram矩阵。然后计算输入图像纹理矩阵和生成图像纹理矩阵之间的加权L2损失,进行反向传播,并计算相对于生成图像的像素的梯度。最后根据梯度上升一点点更新图像的像素,不断重复这个过程,即计算两个gram矩阵的L2范数损失和反向传播图像梯度,最终会生成与纹理图像相匹配的纹理图像。效果如下:
首先使用ImageNet的数据预训练一个VGG网络,然后把含有纹理的图像输入到VGG网络,记录其每一层的激活图并计算每一层的gram矩阵。接着随机初始化一张要生成的新的图像,同样把这张初始化图像通过VGG并且计算每一层的gram矩阵。然后计算输入图像纹理矩阵和生成图像纹理矩阵之间的加权L2损失,进行反向传播,并计算相对于生成图像的像素的梯度。最后根据梯度上升一点点更新图像的像素,不断重复这个过程,即计算两个gram矩阵的L2范数损失和反向传播图像梯度,最终会生成与纹理图像相匹配的纹理图像。效果如下:

使用底层的gram矩阵,生成细节纹理。
使用高层的gram矩阵,生成有概念性的纹理。

风格迁移(Style Transfer)
如果结合特征反演和纹理生成,就可以实现所谓的风格迁移。

需要两张图像,一张图像称为内容图像,需要引导生成图像的主题;另一张图像称为风格图像,生成图像需要重建它的纹理结构。然后共同做特征识别,最小化内容图像的特征重构损失,以及风格图像的gram矩阵损失。使用下面的框架完成这个任务:

内容图片选择relu3_3是因为低层包含了太多细节,relu3_3包含的更多是概念性结构信息。
在这个框架中,使用随机噪声初始化生成图像,同时优化特征反演和纹理生成的损失函数(生成图像与内容图像激活特征向量的L2距离以及与风格图像gram矩阵的L2距离的加权和),计算图像上的像素梯度,重复这些步骤,在生成图像上执行梯度上升。经过一些迭代后会生成风格迁移后的图像。这样生成图像既具有内容图像的空间结构,又具有风格图像的纹理结构。
调整内容权重和纹理权重
由于网络使用的总损失是特征反演和纹理生成的两部分损失的加权和,所以调整这个加权值可以得到不同风格的输出:

调整纹理图像尺寸

多风格图生成

快速风格迁移(Fast style Transfer)
上面的风格迁移框架,每生成一张新的图像都需要迭代数次,计算量非常大。因此有研究提出了下面的Fast style Transfer的框架:
该网络与图像分割网络的差别,图像分割的结果 y ^ , H ∗ W ∗ C \hat{y},H*W*C y^,H∗W∗C的深度C是类别个数,而该网络的结果为 y ^ , H ∗ W ∗ 3 \hat{y},H*W*3 y^,H∗W∗3是一张彩色图。
在一开始就训练好我们想要迁移的风格,训练一个可以输入内容图像的前馈网络,直接输出风格迁移后的结果。训练前馈神将网络的方法是在训练期间计算相同内容图像和风格图像的损失,然后使用相同梯度来更新前馈神经网络的权重,一旦训练完成,只需在训练好的网络上进行单一的前向传播。
实例归一化
 风格迁移任务中批归一化不合适,Batch Norm注重对batchsize数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对HW维度进行归一化。
风格迁移任务中批归一化不合适,Batch Norm注重对batchsize数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对HW维度进行归一化。
风格迁移任务中Layer Norm不合适,风格迁移中又希望每个层记录的风格是不一样的,所以希望单层考虑归一化。
实例归一化,IN保留了N、C的维度,只在Channel内部对于H和W进行求均值和标准差的操作。
在风格迁移中适用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响。
参考:深度学习中的归一化方法总结 – xdhe1216


