LESSON 9.1 随机森林回归器的实现
目录
三 随机森林RandomForest
1 RamdomForestRegressor的实现
2 随机森林回归器的参数
2.1 弱分类器结构
2.2 弱分类器数量
2.3 弱分类器训练的数据
2.4 其他参数
四 增量学习:随机森林处理巨量数据
1 普通学习vs增量学习
2 增量学习在Kaggle数据上的应用
五 原理进阶:Bagging方法6大面试热点问题
六 随机森林的参数空间与自动优化
三 随机森林RandomForest
随机森林是机器学习领域最常用的算法之一,其算法构筑过程非常简单:从提供的数据中随机抽样出不同的子集,用于建立多棵不同的决策树,并按照Bagging的规则对单棵决策树的结果进行集成(回归则平均,分类则少数服从多数)。只要你充分掌握了决策树的各项属性和参数,随机森林的大部分内容都相当容易理解。
虽然原理上很简单,但随机森林的学习能力异常强大、算法复杂度高、又具备一定的抗过拟合能力,是从根本上来说比单棵决策树更优越的算法。即便在深入了解机器学习的各种技巧之后,它依然是我们能够使用的最强大的算法之一。原理如此简单、还如此强大的算法在机器学习的世界中是不常见的。在机器学习竞赛当中,随机森林往往是我们在中小型数据上会尝试的第一个算法。
在sklearn中,随机森林可以实现回归也可以实现分类。随机森林回归器由类sklearn.ensemble.RandomForestRegressor实现,随机森林分类器则有类sklearn.ensemble.RandomForestClassifier实现。我们可以像调用逻辑回归、决策树等其他sklearn中的算法一样,使用“实例化、fit、predict/score”三部曲来使用随机森林,同时我们也可以使用sklearn中的交叉验证方法来实现随机森林。其中回归森林的默认评估指标为R2,分类森林的默认评估指标为准确率。
class sklearn.ensemble.RandomForestRegressor(n_estimators=100, *, criterion='squared_error', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
不难发现,随机森林回归器和分类器的参数高度一致,因此我们只需要讲解其中一个类即可。任意集成算法在发源时都是回归类算法,因此我们的重点将会放在回归类算法上。随机森林有大量的参数,幸运的是,随机森林中所有参数都有默认值,因此即便我们不学习任何参数,也可以调用随机森林算法。我们先来建一片森林看看吧:
1 RandomForestRegressor的实现
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.model_selection import cross_validate, KFold
#这里我们不再使用cross_val_score,转而使用能够输出训练集分数的cross_validate
#决策树本身就是非常容易过拟合的算法,而集成模型的参数量/复杂度很难支持大规模网格搜索
#因此对于随机森林来说,一定要关注算法的过拟合情况
data = pd.read_csv('/Users/zhucan/Desktop/train_encode.csv',index_col=0)
data.head()结果:

data.shape
#(1460, 81)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
y #注意,y的类型是整数型,并且y的均值很大,可想而知整体的MSE一定会很大
#0 208500
#1 181500
#2 223500
#3 140000
#4 250000
# ...
#1455 175000
#1456 210000
#1457 266500
#1458 142125
#1459 147500
#Name: SalePrice, Length: 1460, dtype: int64
y.mean()
#180921.19589041095
X.shape
#(1460, 80)
X.columns.tolist()
#['Id',
# '住宅类型',
# '住宅区域',
# '街道接触面积(英尺)',
# '住宅面积',
# '街道路面状况',
# '巷子路面状况',...]与sklearn中其他回归算法一样,随机森林的默认评估指标是R2,但在机器学习竞赛、甚至实际使用时,我们很少使用损失以外的指标对回归类算法进行评估。对回归类算法而言,最常见的损失就是MSE。

reg_f = RFR() #实例化随机森林
reg_t = DTR() #实例化决策树
cv = KFold(n_splits=5,shuffle=True,random_state=1412) #实例化交叉验证方式
result_t = cross_validate(reg_t #要进行交叉验证的评估器
,X,y #数据
,cv=cv #交叉验证模式
,scoring="neg_mean_squared_error"
#评估指标,sklearn中默认为负,负的程度越深模型越糟糕
,return_train_score=True #是否返回训练分数
,verbose=True #是否打印进程
,n_jobs=-1 #线程数
)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 1.1s remaining: 1.6s
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 1.1s finished
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 1.4s remaining: 2.1s
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 2.1s finished
'''建立了100颗树,但由于树是并行增长的,所以建立只会比决策树慢一点,随着数据量增长,
随机森林会越来越慢'''
result_t #超级过拟合
# {'fit_time': array([0.03513908, 0.02617216, 0.02826715, 0.03085804, 0.03072166]),
# 'score_time': array([0.00184107, 0.00152969, 0.00140595, 0.00212121, 0.00243092]),
# 'test_score': array([-1.32676659e+09, -3.30251909e+09, -1.57903793e+09, -1.50256213e+09,
# -1.57774956e+09]),
# 'train_score': array([-0., -0., -0., -0., -0.])}
result_f #训练集和测试在交叉验证上的分数差异更小,因此森林的过拟合程度没有决策树高
# {'fit_time': array([1.30783272, 1.37094092, 1.34987903, 1.40098619, 1.32293487]),
# 'score_time': array([0.00880313, 0.00958204, 0.00925899, 0.00892091, 0.00915027]),
# 'test_score': array([-7.78513095e+08, -2.03928947e+09, -7.46760247e+08, -4.73092198e+08,
# -8.86053174e+08]),
# 'train_score': array([-1.22052661e+08, -1.04873049e+08, -1.37851525e+08, -1.30651561e+08,
# -1.26205314e+08])}在集成学习中,我们衡量回归类算法的指标一般是RMSE(根均方误差),也就是MSE开根号后的结果。现实数据的标签往往数字巨大、数据量庞杂,MSE作为平方结果会放大现实数据上的误差(例如随机森林结果中得到的,7∗1087∗108等结果),因此我们会对平房结果开根号,让回归类算法的评估指标在数值上不要过于夸张。同样的,方差作为平方结果,在现实数据上也会太大,因此如果可以,我们使用标准差进行模型稳定性的衡量。
trainRMSE_f = abs(result_f["train_score"])**0.5
testRMSE_f = abs(result_f["test_score"])**0.5
trainRMSE_t = abs(result_t["train_score"])**0.5
testRMSE_t = abs(result_t["test_score"])**0.5
trainRMSE_f.mean()
#10949.819569879735
testRMSE_f.mean()
#30452.218280217272
trainRMSE_f.std() #方差数额太大,使用标准差
#373.26874603409686
#默认值下随机森林的RMSE与标准差std
xaxis = range(1,6)
plt.figure(figsize=(8,6),dpi=80)
#RMSE
plt.plot(xaxis,trainRMSE_f,color="green",label = "RandomForestTrain")
plt.plot(xaxis,testRMSE_f,color="green",linestyle="--",label = "RandomForestTest")
plt.plot(xaxis,trainRMSE_t,color="orange",label = "DecisionTreeTrain")
plt.plot(xaxis,testRMSE_t,color="orange",linestyle="--",label = "DecisionTreeTest")
plt.xticks([1,2,3,4,5])
plt.xlabel("CVcounts",fontsize=16)
plt.ylabel("RMSE",fontsize=16)
plt.legend()
plt.show()结果: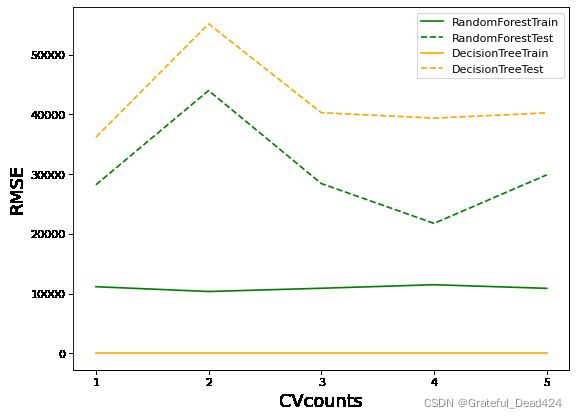
- 横坐标:交叉验证次数
- 纵坐标:RMSE数值
从图像来看,森林与决策树都处于过拟合状态,不过森林的过拟合程度较轻,决策树的过拟合程度较强。两个算法在训练集上的结果都比较优秀,决策树的可以完美学习训练集上的内容,达到RMSE=0的程度,而随机森林在训练集上的RMSE大约在1w上下徘徊,测试集上的结果则是随机森林更占优。可见,与填写的参数无关,随机森林天生就是比决策树更不容易过拟合、泛化能力更强的。
2 随机森林回归器的参数
当填写参数之后,随机森林可以变得更强大。比起经典机器学习算法逻辑回归、岭回归等,随机森林回归器的参数数量较多,因此我们可以将随机森林类的参数分为如下4大类别,其中标注为绿色的是我们从未学过的、只与集成算法相关的参数:

2.1 弱分类器结构
在集成算法当中,控制单个弱评估器的结构是一个重要的课题,因为单个弱评估器的复杂度/结果都会影响全局,其中单棵决策树的结构越复杂,集成算法的整体复杂度会更高,计算会更加缓慢、模型也会更加容易过拟合,因此集成算法中的弱评估器也需要被剪枝。随机森林回归器的弱评估器是回归树,因此集成评估器中有大量的参数都与弱评估器回归树中的参数重合:

这些参数在随机森林中的用法与默认值与决策树类DecisionTreeRegressor中完全一致,专门用于对决策树进行剪枝、控制单个弱评估器的结构,考虑到大家在决策树中已经充分掌握这些参数,我们不再对这些参数一一进行详细说明了。在这里,我们重点复习一下以下两部分参数:
- 分枝标准与特征重要性
criterion与feature_importances_
与分类树中的信息熵/基尼系数不同,回归树中的criterion可以选择"squared_error"(平方误差),"absolute_error"(绝对误差)以及"poisson"(泊松偏差)。对任意样本而言,为真实标签,帽为预测标签,则各个criterion的表达式为:

其中平方误差与绝对误差是大家非常熟悉的概念,作为分枝标准,平方误差比绝对误差更敏感(类似于信息熵比基尼系数更敏感),并且在计算上平方误差比绝对误差快很多。泊松偏差则是适用于一个特殊场景的:当需要预测的标签全部为正整数时,标签的分布可以被认为是类似于泊松分布的。正整数预测在实际应用中非常常见,比如预测点击量、预测客户/离职人数、预测销售量等。我们现在正在使用的数据(房价预测),也可能比较适合于泊松偏差。
另外,当我们选择不同的criterion之后,决策树的feature_importances_也会随之变化,因为在sklearn当中,feature_importances_是特征对criterion下降量的总贡献量,因此不同的criterion可能得到不同的特征重要性。(criterion和feature_importances_相连,feature_importances_是通过每一个特征贡献的不纯度下降量计算的)
对我们来说,选择criterion的唯一指标就是最终的交叉验证结果——无论理论是如何说明的,我们只取令随机森林的预测结果最好的criterion。
- 调节树结构来控制过拟合
max_depth
最粗犷的剪枝方式,从树结构层面来看,对随机森林抗过拟合能力影响最大的参数。max_depth的默认值为None,也就是不限深度。因此当随机森林表现为过拟合时,选择一个小的max_depth会很有效。
max_leaf_nodes与min_sample_split
比max_depth更精细的减枝方式,但限制叶子数量和分枝,既可以实现微调,也可以实现大刀阔斧的剪枝。max_leaf_nodes的默认值为None,即不限叶子数量。min_sample_split的默认值为2,等同于不限制分枝。
min_impurity_decrease
最精细的减枝方式,可以根据不纯度下降的程度减掉相应的叶子。默认值为0,因此是个相当有空间的参数。
2.2 弱分类器数量
n_estimators
n_estimators是森林中树木的数量,即弱评估器的数量,在sklearn中默认100,它是唯一一个对随机森林而言必填的参数。n_estimators对随机森林模型的精确程度、复杂度、学习能力、过拟合情况、需要的计算量和计算时间都有很大的影响,因此n_estimators往往是我们在调整随机森林时第一个需要确认的参数。对单一决策树而言,模型复杂度由树结构(树深、树宽、树上的叶子数量等)与数据量(样本量、特征量)决定,而对随机森林而言,模型复杂度由森林中树的数量、树结构与数据量决定,其中树的数量越多,模型越复杂。
还记得讲解决策树与逻辑回归时我们绘制的这张图像么?当模型复杂度上升时,模型的泛化能力会先增加再下降(相对的泛化误差会先下降再上升),我们需要找到模型泛化能力最佳的复杂度。在实际进行训练时,最佳复杂度往往是一个比较明显的转折点,当复杂度高于最佳复杂度时,模型的泛化误差要么开始上升,要么不再下降。

对随机森林而言,该图像的横坐标可以被无缝切换为参数n_estimators上的值。当n_estimators越大时:
- 模型的复杂程度上升,泛化能先增强再减弱(或不变)
- 模型的学习能力越来越强,在训练集上的分数可能越来越高,过拟合风险越来越高
- 模型需要的算力和内存越来越多
- 模型训练的时间会越来越长
因此在调整n_estimators时,我们总是渴望在模型效果与训练难度之间取得平衡,同时我们还需要使用交叉验证来随时关注模型过拟合的情况。在sklearn现在的版本中,n_estimators的默认值为100,个人电脑能够容忍的n_estimators数量大约在200~1000左右。
def RMSE(cvresult,key):
return (abs(cvresult[key])**0.5).mean()
reg_f = RFR(n_estimators=3)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 1.3s remaining: 1.9s
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 1.3s finished
RMSE(result_f,"test_score")
#35681.96994493137
reg_f = RFR(n_estimators=100)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 1.4s remaining: 2.1s
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 2.0s finished
RMSE(result_f,"test_score")
#30351.359534374766
reg_f = RFR(n_estimators=500)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 7.8s remaining: 11.8s
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 7.9s finished
RMSE(result_f,"test_score")
#30290.45615417552
随机森林bagging生成的树都是独立并行计算的,所以时间不会成倍增加
总结:

2.3 弱分类器训练的数据
还记得决策树是如何分枝的吗?对每个特征决策树都会找到不纯度下降程度最大的节点进行分枝,因此原则上来说,只要给出数据一致、并且不对决策树进行减枝的话,决策树的结构一定是完全相同的。对集成算法来说,平均多棵相同的决策树的结果并没有意义,因此集成算法中每棵树必然是不同的树,Bagging算法是依赖于随机抽样数据来实现这一点的。
随机森林会从提供的数据中随机抽样出不同的子集,用于建立多棵不同的决策树,最终再按照Bagging的规则对众多决策树的结果进行集成。因此在随机森林回归器的参数当中,有数个关于数据随机抽样的参数。
- 样本的随机抽样
bootstrap,oob_score,max_samples
bootstrap参数的输入为布尔值,默认True,控制是否在每次建立决策树之前对数据进行随机抽样。如果设置为False,则表示每次都使用全部样本进行建树,如果为True,则随机抽样建树。从语言的意义上来看,bootstrap可以指代任意类型的随机抽样,但在随机森林中它特指有放回随机抽样技术。
如下图所示,在一个含有m个样本的原始训练集中,我们进行随机采样。每次采样一个样本,并在抽取下一个样本之前将该样本放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集max_samples次,最终得到max_samples个样本组成的自助集。
自助集就是抽取出来的数据集。
 通常来说,max_samples是等于m的(行业惯例),也就是抽样数据集的大小与原始数据集一致,但是如果原始数据集太大、或者太小,我们也可以自由调整
通常来说,max_samples是等于m的(行业惯例),也就是抽样数据集的大小与原始数据集一致,但是如果原始数据集太大、或者太小,我们也可以自由调整max_samples的大小。由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的弱分类器,我们的弱分类器自然也就各不相同了。
然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能被忽略。当抽样次数足够多、且原始数据集足够大时,自助集大约平均会包含全数据的63%,这个数字是有数学依据的。因为在max_samples次抽样中,一个样本被抽到某个自助集中的概率为:

这个式子是怎么来的呢?对于任意一个样本而言:
一次抽样时抽到该样本的概率为1/m
一次抽样时抽不到该样本的概率为1−1/m
总共抽样max_samples次,一次也没有抽到该样本的概率就是

因此1减去该概率,就是一个样本在抽样中一定会被抽到某个自助集的概率。 当m刚好等于max_samples时,公式可以被修改为:
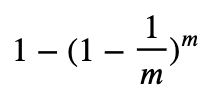
这明显是一个经典的极限问题,由洛必达法则(L'Hôpital's rule)我们可知:当m足够大时(接近极限时),这个概率收敛于1-(1/e),其中e是自然常数,整体概率约等于0.632。因此,会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。在实际使用随机森林时,袋外数据常常被我们当做验证集使用,所以我们或许可以不做交叉验证、不分割数据集,而只依赖于袋外数据来测试我们的模型即可。当然,这也不是绝对的,当树的数量n_estimators不足,或者max_samples太小时,很可能就没有数据掉落在袋外,自然也有无法使用oob数据来作为验证集了。
在随机森林回归器中,当boostrap=True时,我们可以使用参数oob_score和max_samples,其中:
oob_score控制是否使用袋外数据进行验证,输入为布尔值,默认为False,如果希望使用袋外数据进行验证,修改为True即可。(数据量特别大的时候,可以修改为True)
max_samples表示自助集的大小,可以输入整数、浮点数或None,默认为None。
输入整数m,则代表每次从全数据集中有放回抽样m个样本
输入浮点数f,则表示每次从全数据集中有放回抽样f*全数据量个样本
输入None,则表示每次抽样都抽取与全数据集一致的样本量(X.shape[0])
在使用袋外数据时,我们可以用随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果,遗憾的是我们无法调整oob_score_输出的评估指标,它默认是R2。
reg = RFR(n_estimators=20
, bootstrap=True #进行随机抽样
, oob_score=True #按袋外数据进行验证
, max_samples=500
).fit(X,y)
#重要属性oob_score_
reg.oob_score_ #在袋外数据上的R2为83%
#0.8379331878464579
reg = RFR(n_estimators=20
, bootstrap=False
, oob_score=True
, max_samples=500).fit(X,y)
#直接无法运行,因为boostrap=False时oob_score分数根本不存在
reg = RFR(n_estimators=20
, bootstrap=True #允许抽样
, oob_score=False #但不进行计算
, max_samples=500).fit(X,y)
reg.oob_score_ #虽然可以训练,但oob_score_无法被调用- 特征的随机抽样
max_features
数据抽样还有另一个维度:对特征的抽样。在学习决策树时,我们已经学习过对特征进行抽样的参数max_features,在随机森林中max_features的用法与决策树中完全一致,其输入也与决策树完全一致:
输入整数,表示每次分枝时随机抽取max_features个特征
输入浮点数,表示每次分枝时抽取round(max_features * n_features)个特征
输入"auto"或者None,表示每次分枝时使用全部特征n_features
输入"sqrt",表示每次分枝时使用sqrt(n_features)
输入"log2",表示每次分枝时使用log2(n_features)
sqrt_ = []
log_ = []
for n_features in range(1,101,2):
sqrt_.append(np.sqrt(n_features))
log_.append(np.log2(n_features))
xaxis = range(1,101,2)
plt.figure(figsize=(8,6),dpi=80)
#RMSE
plt.plot(xaxis,sqrt_,color="green",label = "sqrt(n)")
plt.plot(xaxis,log_,color="orange",label = "log2(n)")
plt.xticks(range(1,101,10))
plt.legend()
plt.show()结果:
不难发现,sqrt(n_features)和log2(n_features)都会返回一个比原始特征量小很多的数,但一般情况下log2返回的值比sqrt返回的值更小,因此如果我们想要树之间的差异更大,我们可以设置模式为log2。在实际使用时,我们往往会先使用上述的文字输入,观察模型的结果,然后再在有效的范围附近进行网格搜索。
需要注意的是,无论对数据进行怎样的抽样,我们能够控制的都只是建立单棵树时的数据而已。在总数据量有限的情况下,单棵树使用的数据量越大,每一棵树使用的数据就会越相似,每棵树的结构也就会越相似,bagging的效果难以发挥、模型也很容易变得过拟合。因此,当数据量足够时,我们往往会消减单棵树使用的数据量。
- 随机抽样的模式
random_state
在决策树当中,我们已经学习过控制随机模式的参数random_state,这个参数是“随机数种子”,它控制决策树当中多个具有随机性的流程。在sklearn实现的随机森林当中,决策树上也存在众多有随机性的流程:
- 「强制」随机抽取每棵树建立时分枝用的特征,抽取的数量可由参数max_features决定
- 「强制」随机排序每棵树分枝时所用的特征(工业上不可能一个一个算)
- 「可选」随机抽取每棵树建立时训练用的样本,抽取的比例可由参数max_samples决定
因此每次使用随机森林类时,我们建立的集成算法都是不同的,在同一个数据集上多次建树自然也会产生不同的模型结果。因此在工程部署和教学当中,我们在建树的第一步总是会先设置随机数种子为一个固定值,让算法固定下来。在设置的时候,需要注意两个问题:
1、不同库中的随机数种子遵循不同的规则,对不同库中的随机数种子给与相同的数字,也不会得到相同的结果
import pandas as pd
import random
list_ = [1,2,3,4,5]
list_p = pd.Series(list_)
list_p
#0 1
#1 2
#2 3
#3 4
#4 5
#dtype: int64
#random中的随机抽样
random.seed(1)
random.sample(list_,k=3)
#[2, 1, 5]
#pandas中的随机抽样
list_p.sample(n=3,random_state=1).values
#array([3, 2, 5])同样的,sklearn中的随机抽样、numpy中的随机抽样、cuda中的随机抽样在相同的随机数种子数值下,都会得到不同的结果。
2、如何选择最佳随机数种子?
当数据样本量足够大的时候(数万),变换随机数种子几乎不会对模型的泛化能力有影响,因此在数据量巨大的情况下,我们可以随意设置任意的数值。
当数据量较小的时候,我们可以把随机数种子当做参数进行调整,但前提是必须依赖于交叉验证的结果。选择交叉验证结果中均值最高、方差最低的随机数种子,以找到泛化能力最强大的随机模式。

2.4 其他参数

我们已经了解过前三个参数。需要稍微说明一下verbose参数。随机森林的verbose参数打印的是建树过程,但只有在树的数量众多、建模耗时很长时,verbose才会打印建树的具体过程,否则它只会打印出一行两简单的报告。这些参数中需要重点说明的是warm_start。warm_start是控制增量学习的参数,默认为False,该参数可以帮助随机森林处理巨量数据,解决围绕随机森林的众多关键问题。我们将在之后的章节中重点讲解warm_start的应用。