梯度下降法写多元一次方程
在做线性回归的时候,很多情况下因变量是由多个自变量所决定的,本文局一个案例说明。
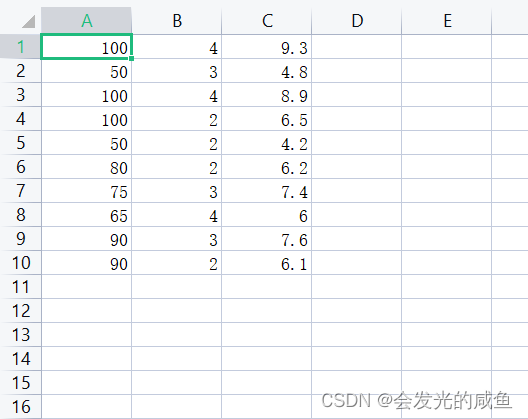
第一列和第二列都是自变量,第三列是因变量
代码如下:
import numpy as np
import matplotlib.pyplot as plt
导入数据集并划分数据
data = np.genfromtxt("C:/Users/Lenovo/Desktop/shuzizuoye/Delivery.csv",delimiter=",")
print(data)
x_data0=data[:,0] #x0取第一列
x_data1=data[:,1] #x1取第二列
y_data =data[:,2] #y取第三列
print(x_data0)
print(x_data1)
采用梯度下降算法
#定义学习率
lr=0.0001
# y=ax0+bx1+c
a=0
b=0
c=0
#最大迭代次数
epochs=1000
#最小二乘法定义损失函数
def loss(a,b,c,x_data0,x_data1,y_data):
totalloss=0
for i in range(0,len(x_data0)):
totalloss += (y_data[i]-(a*x_data0[i]+b*x_data1[i]+c))**2
return totalloss / float(len(x_data0)) / 2.0
#梯度下降法
def gradient_descent (a,b,c,x_data0,x_data1,y_data,lr,epochs):
m=float(len(x_data0))
#循环epochs次
for i in range (epochs):
a_grad = 0
b_grad = 0
c_grad = 0
for j in range (0,len(x_data0)):
a_grad += -(1/m)*x_data0[j]*(y_data[j]-(a*x_data0[j]+b*x_data1[j]+c))
b_grad += -(1/m)*x_data1[j]*(y_data[j]-(a*x_data0[j]+b*x_data1[j]+c))
c_grad += -(1/m)*(y_data[j]-(a*x_data0[j]+b*x_data1[j]+c))
a=a-(lr*a_grad)
b=b-(lr*b_grad)
c=c-(lr*c_grad)
return a,b,cprint ("starting a={0},b={1},c={2},error={3}".format(a,b,c,loss(a,b,c,x_data0,x_data1,y_data)))#开始迭代前a,b,c的值以及损失值
print("running...")
a,b,c=gradient_descent (a,b,c,x_data0,x_data1,y_data,lr,epochs)
print("after {0} iterations a = {1},b={2},c={3},error={4}".format(epochs,a,b,c,loss(a,b,c,x_data0,x_data1,y_data)))![]()
可以看出刚开始的损失函数值为23.6399.....,经过1000次迭代之后损失值为0.38656....,降低了很多同时多元线性回归方程也可求出。
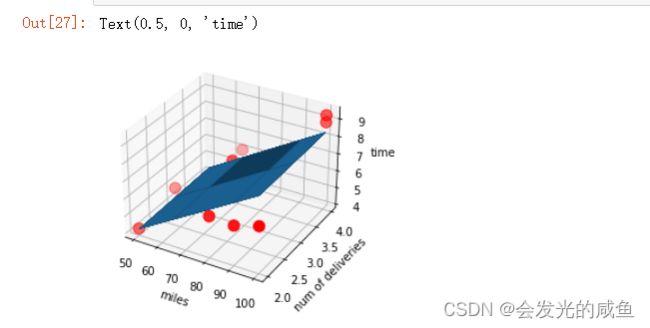
画出图像:
ax=plt.figure().add_subplot(111,projection = '3d')
ax.scatter(x_data0,x_data1,y_data,c='r',marker='o',s=100)
x0=x_data0
x1=x_data1
#生成网格矩阵
x0,x1=np.meshgrid(x0,x1)
z=a*x0+b*x1+c
#画3d图
ax.plot_surface(x0,x1,z)
#设置坐标轴
ax.set_xlabel('miles')
ax.set_ylabel('num of deliveries')
ax.set_zlabel('time')