ICLR2021对比学习(Contrastive Learning)NLP领域论文进展梳理
作者|对白
出品|公众号:对白的算法屋
大家好,我是对白。
本次我挑选了ICLR2021中NLP领域下的六篇文章进行解读,包含了文本生成、自然语言理解、预训练语言模型训练和去偏、以及文本匹配和文本检索。从这些论文的思想中借鉴了一些idea用于公司自身的业务中,最终起到了一个不错的效果。
Contrastive Learning with Adversarial Perturbations for Conditional Text Generation
任务:端到端文本生成
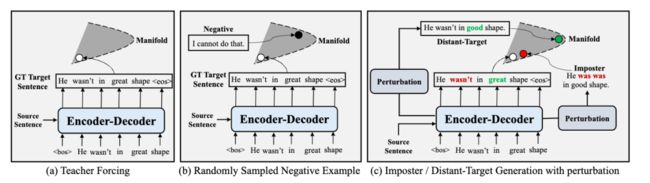
本文要解决的是文本生成任务中的暴露偏差(exposure bias)问题,即在文本生成自回归形式的生成任务中,解码器的输入总是ground truth的token,没有遇到过错误的生成结果。
本文通过引入对比学习损失,让模型从负样本中区分正样本,使得模型暴露于不同的噪声情况下,来解决这一问题。然而,完全随机生成噪声样本会导致模型非常容易区分,特别是对于预训练模型而言。因此,本文提出了一种对抗扰动方法,添加扰动使得正样本具有较高的似然度;是的负样本具有较低的似然度。
CoDA: Contrast-enhanced and Diversity-promoting Data Augmentation for Natural Language Understanding
任务:自然语言理解、在fine-tune阶段增强文本表示
本文主要研究文本领域的数据增强方法,研究了如下问题:
-
可以将哪些增强方法应用于文本?
-
这些增强方式是互补的吗,是否可以找到一些策略来整合它们以产生更多不同的增强示例?
-
如何有效地将获得的增强样本融入训练过程?
作者考虑了五种针对于文本的数据增强方法:
-
回译(back-translation)
-
c-BERT 词替换
-
mixup
-
cutoff
-
对抗训练
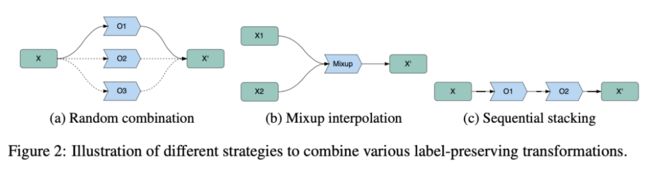
进一步,作者考虑了三种不同的数据增强的策略,以探究问题1和问题2,如上图所示:
随机选择:为mini-batch内的每一条样本,随机选择一种数据增强方法;
mixup:将mini-batch内的两条样本通过mixup的策略随机组合
将不同的增强方法堆叠:
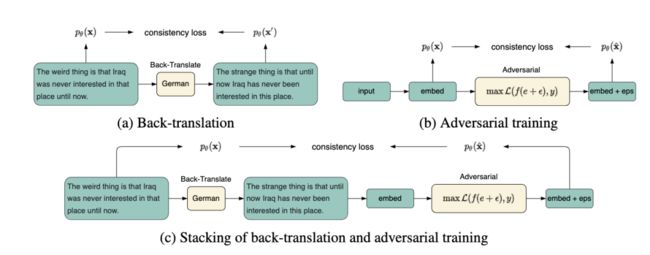
在第三个问题——如何将其更好地融入finetune任务上,提出了对比损失。
实验发现,两种增强方式的堆叠能进一步增强性能。在GLUE上进行了实验,均分相比Baseline提升了2个点。
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
任务:预训练语言模型去偏
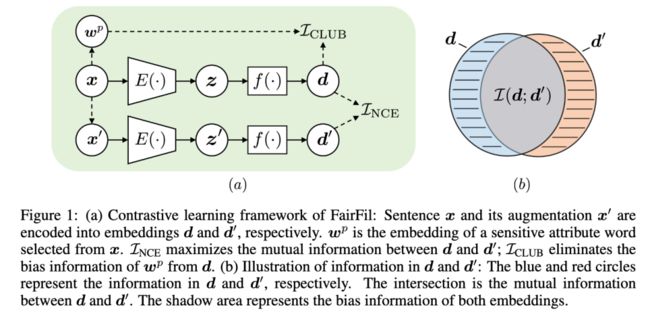
本文将对比学习用于消除预训练语言模型生成的文本表示中的偏见因素(例如性别偏见、种族偏见等)。为了做到这一点,本文训练一个额外的映射网络,将语言模型生成的文本表示转换成另一个表示,在新生成的表示上能达到消除偏见的效果。本文的创新点在于:
-
将原文本中的偏见词替换成其反义词(如man<->woman; her<->his; she<->he),这样可以构建一个增强的文本。通过对比损失,在转换后的表示中,最大化这两者的互信息;
-
为了进一步消除文本中隐含的偏见,额外提出了一个损失,去最小化生成的句子表示和偏见词表示的互信息。
Towards Robust and Efficient Contrastive Textual Representation Learning
任务:语言模型预训练
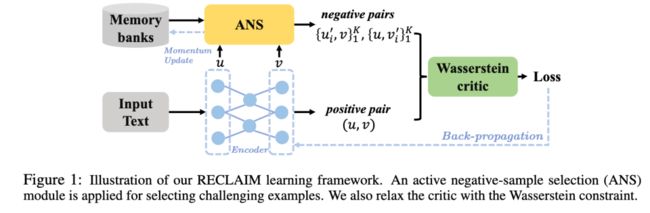
本文分析了目前将对比学习用于文本表示学习存在的问题(2.2节),包括:
-
对比学习中,如果采用KL散度作为训练目标,训练过程会不稳定;
-
对比学习要求一个较大的负样本集合,效率低。
对于第一个问题,作者添加了一个Wasserstein约束,来增强其训练时的稳定性;对于第二个问题,作者提出了只采样最近的K个负样本,称为Active Negative-sample selection(和NIPS那篇:Hard Negatives Mixing比较类似)。
Self-supervised Contrastive Zero to Few-shot Learning from Small, Long-tailed Text data
任务:文本匹配;多标签文本分类
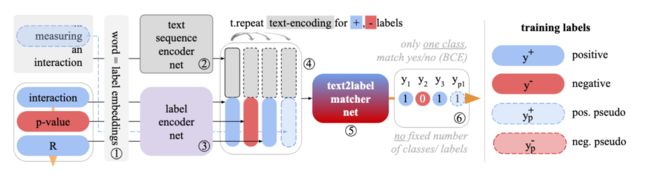
本文主要尝试解决多标签文本分类问题,特别是其存在的长尾标签问题(即当数据较少时,类别分布往往不均匀,会存在大量很多只出现了一两次的标签,同时少量类别频繁出现)。
本文主要将多标签分类任务建模成类似文本匹配的形式。将采样不同的正负标签,同时也会从句子中采样文本片段,构成伪标签。这四种形式的标签(正标签、负标签、正伪标签、负伪标签)编码后,和句子编码拼接,经过一个匹配层,通过二分类交叉熵损失(BCE),或NCE损失(将正例区别于负例)训练匹配模型。
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
任务:稠密文本检索
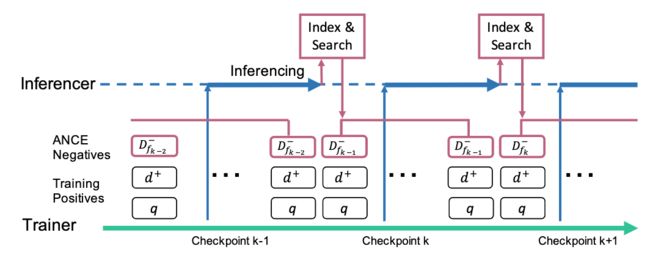
本文研究文本检索领域,不同于传统的利用词级别进行检索(稀疏检索),本文通过训练文本表示进行文本检索(称为Dence Retrieval,DR)。DR包含两个阶段:
-
预训练一个模型,将文本编码成一个向量,训练目标是使得similar pairs具有最大的相似度分数;
-
通过训练好的编码模型,将文本编码、索引,根据query的相似度执行检索。
本文主要关注于第一阶段,即如何训练一个好的表示。本文从一个假设出发:负样本采样方法是限制DR性能的瓶颈。本文的贡献:
-
提出了一种更好的负采样方法,用于采样优质的dissimilar pairs;
-
本文提出的效果能让训练更快收敛;
-
本文提出的方法相比基于BERT的方法提升了100倍效率,同时达到了相似的准确率。
本文所提出的负采样方法是一种不断迭代的形式,将ANN索引的结果用于负样本采样,随后进一步训练模型;模型训练完之后,用于更新文档表示以及索引。
对比学习算法交流群
已建立对比学习算法交流群!想要进交流群学习的同学,可以直接加我的微信号:duibai996。加的时候备注一下:昵称+学校/公司。群里聚集了很多学术界和工业界大佬,欢迎一起交流算法心得,日常还可以唠嗑~
关于我
你好,我是对白,硕士毕业于清华,现大厂算法工程师,拿过八家大厂的SSP级以上offer。
本科时独立创业五年,成立两家公司,并拿过总计三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研后选择退出。
我每周至少更新一篇原创,分享自己的算法技术、创业心得和人生感悟。我正在努力实现人生中的第一个小目标,上方关注后可以加我私信交流。
期待你关注我的公众号,我们一起前行。