NLP-D23-cs224n&kaggle房价预测复习&chap5深度学习计算&算法R2D7&Unicorn
—0525早上4点起,还是看了cs224n作为听力练习。
然后就看论文了。好饿,吃了很多面包片,看沐沐讲课好治愈啊。看完这个QA继续看论文了。
–0544大概看了overview,不想看了。继续看pytorch实践叭!
—0801
—0815说去看个视频,结果去看起了沐沐,太真实了。现在开始敲代码叭!
–0822哦吼!看完第四章了!想自己再做一遍这个比赛!
1、
AssertionError: Size mismatch between tensors
这个问题是DataLoader里两个array的维度不同

应该是我写的时候抄错了,没过脑子
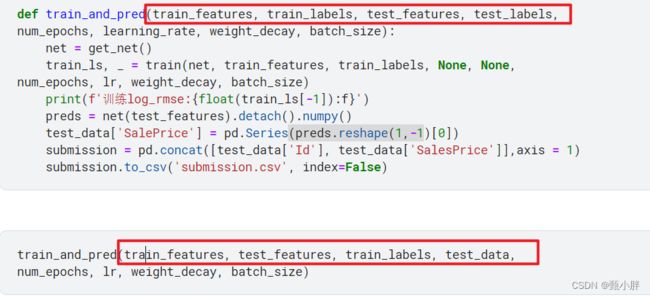
、磕磕绊绊,一上午,在闲适的状态下,终于半独立地写完了一个kaggle比赛。想要完全独立对我来说还是很难。总结一下。
一、流程
1、读数据,做数据的预处理
2、定义dataloader
from torch.utils.data import TensorDataset, DataLoader
def load_array(data_arrays, batch_size, is_train=True):
dataset = TensorDataset(*data_arrays)
return DataLoader(dataset, batch_size, shuffle=is_train)

3、定义模型、初始化参数、选择优化器、定义损失函数
4、k折交叉验证(这里我们是自己写的,但其实应该有api,并没有,在李沐大大的书里没翻到,去网上查,发现和书中代码一样)
因为用的k折交叉验证,我们就没有单独切割数据集的part了。
5、不断调试超参数(这里我们没做)
6、最后再train以及predict。
踩的坑:
1、函数参数定义和传递时的顺序不一样,导致疯狂报错。dataload的时候,两个array的样本数应该是一样的。
2、df[‘aaa’]或者df.iloc[:,:]
—1045哎,感觉放松下来,又挺有意思的,不要把自己蹦的太紧了啊。去吃饭了。
—1443中午睡了个好觉,2点醒了,没有立刻起来学习,而是特意让自己在床上看了会手机,强制放松。现在开始继续敲代码了!
1、深度学习关键组件
模型构建、参数访问与初始化、设计自定义层和块、将模型读写到磁盘、利用GPU实现显著加速。
2、块好神奇!!!
之前看视频的时候还不太理解块的作用,现在看完了resnet再看书,感觉能够更好地理解了。块可以看做是层的集合,或者是块的集合,通过init对参数进行初始化;通过forward支持自由地构建模型,同时由于继承nn.Module,自带了反向传播的功能。
块支持套娃行为。
之前的sequential也是一个块,它实现的功能主要是顺序执行参数中的module实例。
3.nn.Module类的_modules属性
这个属性用来存放参数中传过来的modules;
我猜测:
如果在init中建立,会直接添加到这个字典中。而参数传过来的modules则需要我们手动加入。
加入后的好处在于,其他模块可以承认这个module,比如初始化。在初始化的时候,系统会查找这个字典中的字块,将其自动初始化。就相当于在我这个module里对他们进行了注册。

3、在列表之前的作用
在练习里,多次看到,查了一下。
和我们定义函数时用的是一样的,就是将列表的值解开;同理**,作用于字典。另外,作用于字典的时候字典的键,要和形参名字相同。
*字典,是获取字典的键
参考:https://blog.csdn.net/qq_42031142/article/details/115305956
自己做了个小实验

—1605想先去吃饭了!
突然觉得,如果你不觉得coding是一件难事,它其实挺简单的。比如说,现在我就觉得,“无他,唯手熟尔。”
干饭去!
–1830
加了大佬微信,收到综述。
认识了一个做nlp的小姐姐,被鼓励多做几个数据集,要努力。
现在开始刷题,一会去做核酸。
—1928做完核酸了,今天的新题还没做,复习做完了,去做下新题。好想吃蛋白棒!!!但是还是忍一忍叭!
—1946一维前缀和,还可以写的更简洁,明天实现。
去看看翻译。
–2010啦啦啦!!!看完翻译啦!!继续看pytorch了!
感觉自定义块和自定义层的区别在于:
自定义块在操作层(__init__中是层);自定义层在操作X和参数(__init__中是Parameter)。
实例化层之后,便将参数初始化完成。传入X后,则完成前向传播(有一个隐藏的接收X的函数,接收X后,直接传给forward并执行)

保存模型和参数

字符串前加f的作用:格式化字符串
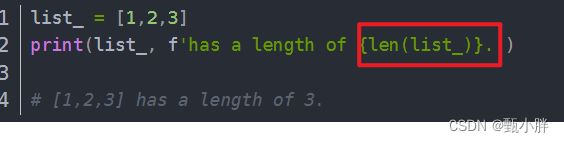
参考
https://blog.csdn.net/qq_43463045/article/details/93890436
把数据挪到cuda上去
可以用to;也可以device=

也可以
Z = X.cuda(1)
//在cuda1上复制X,并将其分配给Z
查看net在哪个设备,其实就是查看他的weight在哪里。allinall,存的还是参数嘛,模型本身就只是逻辑,找了半天查找语句,没想到就在书上。

不经意移动数据,可能会显著降低性能。
比如,每个小batch,打印一下损失,或者记录在numpy ndarray中。

在GPU上分配日志内存,并且只移动较大的日志===》不频繁切换,只有在gpu上积累到较大数量后才切换。
![]()
—2157完成了chap5!!!准备收工!