论文阅读|POET
POET:End-to-End Trainable Multi-Instance PoseEstimation with Transformers
目录
Abstract
Introduction
Related Work
Transformers in vision and beyond
Pose estimation
The POET model
POET architecture
CNN backbone
Encoder-Decoder transformer
Pose prediction head
Training loss
Experiments
COCO keypoint detection challenge
Implementation details
Qualitative results定性结果
Quantitative evaluation定量结果
Analysis
Transformer attention
Learned Centers
Visibility
Decoder Analysis
Conclusions
Abstract
我们通过将卷积神经网络与transformer相结合,提出了一种用于多实例姿态估计的新端到端可训练方法。我们将来自图像的多实例姿态估计转化为一个直接集合预测问题。受最近使用transformer进行端到端可训练对象检测工作的启发,我们使用transformer的encoder-decoder架构和二部匹配方案来直接回归给定图像中所有个体的姿势。我们的模型称为 POse Estimation Transformer (POET),使用一种新的基于集合的全局损失进行训练,该损失由关键点损失、关键点可见性损失、中心损失和类别损失组成。 POET 推理检测到的人与完整图像上下文之间的关系,以直接并行预测姿势。我们表明,POET 可以在具有挑战性的 COCO 关键点检测任务上实现高精度。据我们所知,该模型是第一个端到端可训练的多实例人体姿态估计方法。
Introduction
从单一图像中进行多人姿态估计,即预测每个人身体部位的位置,是计算机视觉的一个重要问题。姿态估计有广泛的应用,从医疗保健和生物学的行为测量到虚拟现实和人机交互。
多人姿态估计可以看作是一个层次化的集合预测任务。一个算法需要预测所有个体的身体部位,并将它们正确地分组归类为人体。由于这一过程的复杂性,目前的方法由多个步骤组成,并不是端到端可训练的。基本上,Top-down和Bottom-up的方法是主要的方法。Top-down方法首先基于目标检测算法预测所有个体的位置(bounding boxes),然后使用单独的网络预测每个裁剪个体的所有身体部位的位置。Bottom-up方法首先预测所有身体部位,然后将它们分组为个体。然而,这两种方法要么需要后处理, 要么需要两个不同的网络。这促使人们寻求端到端解决方案。
受最新的基于Transformer的目标检测体系结构DETR的启发,我们提出了一种新颖的端到端可训练的多实例姿态估计方法。POse Estimation Transformer(POET)是第一个端到端用于多实例姿态估计的模型,不需要像自上而下方法那样进行后处理或使用两个网络。POET无需任何后期处理就能预测所有人类姿势,并通过一个新颖但简单的损失函数进行训练,它允许预测的和groundtruth之间的人体姿势二部图匹配。我们的方法在难度较大的COCO关键点挑战上取得了出色的结果,特别是对于图像中占比较大的人体,即使在更高的空间分辨率下也比基线模型表现得更好(图1)。
Related Work
Transformers in vision and beyond
Transformer被引入机器翻译,并极大地提高了语言任务中的深度学习模型的性能。它们的架构本质上允许建模和发现数据中的远程交互。其用途最近已经扩展到语音识别、自动定理证明和许多其他任务。在计算机视觉中,不管是结合CNN使用还是作为CNN的替代,Transformer都取得了巨大的效果。值得注意的是,Visual Transformer (ViT)在纯Transformer模型的图像识别任务上展示了最先进的性能。在其他可视化任务中,如文本到图像,已经显示了出色的结果,例如DALL-E。
最近,Carion等人开发了一种新的端到端模式,用于用Transformer检测视觉对象,这一任务以前需要两阶段方法或后处理。这种方法,即DETR,将目标检测定义为一个结合了二部图匹配损失的集合预测问题。DETR是一种优雅的解决方案,然而,该模型需要较长的训练时间,并且在小对象上表现得相对较差。这些问题通过进一步的工作得到了缓解; Deformable DETR提出了一种多尺度注意变形模型multi-scale Deformable Attention Module,针对不同尺度只关注feature map中的一定数量的点,从而减少了训练时间,提高了小目标检测性能。Sun等人(Rethinking Transformer-based Set Prediction for Object Detection)去掉了Transformer解码器,并将来自CNN Backbone的特征输入到特征金字塔网络(27)。
重要的是,端到端的方法已经成功应用于许多复杂的预测任务,如语音识别或机器翻译,但多实例姿态估计中仍缺乏端到端的预测方法。
Pose estimation
多人姿态估计可分为自顶向下(Top-down)和自底向上(Bottom-up)两种。Top-down方法基于Bounding box用单独的网络定位个体(目标检测网络),再预测每个个体的每个身体部位的位置(单人姿态识别网络)。Bottom-up方法首先预测所有身体部位,然后通过部分亲和场(part affinity fields, OpenPose[9])、成对预测(pairwise predictions [10] [11] [14] [35] [36])、复合场(composite fields [13] [16])或关联嵌入(associative embeddings,[12] [15])将其分组。无论是Top-down还是Bottom-up的方法,都需要后处理步骤或两个不同的神经网络(用于定位然后进行姿态估计)。
最新的(最先进)方法是完全卷积和预测关键点热图。最近,Yang等人提出了TransPose(2021ICCV),这是一种Top-down的方法用于预测热图,是CNN backbone + Transformer Encoder的结构。Transformer还用于(单个)人体的3D姿势和mesh重建,在Human3.6M上达到了最先进的水平(End-to-end human pose and mesh reconstruction with transformers)。扩展这项工作,我们在 DETR (17) 的基础上提出了一种端到端的可训练姿态估计方法,用于直接将姿态输出为向量(没有热图)的多个实例。 为了将姿态估计转换为层次化集合预测问题,我们采用了 Center-Net (36) 和 Single-Stage Multi-Person Pose Machines (14) 的姿态表示。
The POET model
POET的整体架构如图2所示,我们的工作和DETR密切相关,并在根本上将该目标检测框架扩展到多实例姿态估计。与DETR一样,POET由两个主要成分组成:
- 一种基于transformer的架构,可以并行预测一组人体姿势;
- 一组预测损失的集合,它是类、关键点坐标和可见性的简单子损失的线性组合。
为了将多实例姿态估计作为一个集合预测问题,我们将每个个体的姿态表示为中心(质量)以及每个身体部分的相对偏移量。 每个身体部位都可以被遮挡或可见。 POET 被训练直接输出包含中心、相关身体部位以及(二进制)身体部位可见性指标的向量(图 2b)。

*图注:a): POET combines a CNN backbone and a transformer to directly predict the pose of multiple humans.
b):每个姿势被表示为一个向量包括中心![]() ,每个身体部位i的相对偏移量
,每个身体部位i的相对偏移量![]() 和它的可见性
和它的可见性 .
.
c):POET 通过最接近groundtruth姿势的预测的二部图匹配进行端到端训练,然后反向传播损失。
POET architecture
POET 架构包含三个主要元素:提取输入图像特征的 CNN 主干、编码器-解码器transformer和输出估计姿势集的前馈网络 (FFN) 头。
CNN backbone
CNN backbone的输入为一组图像![]() ,B是batch size,3个颜色通道,图像尺寸为(H,W)。通过几个计算和下采样步骤,CNN生成了低分辨率的feature map
,B是batch size,3个颜色通道,图像尺寸为(H,W)。通过几个计算和下采样步骤,CNN生成了低分辨率的feature map![]()
其中S是stride步长,详情在实验部分
Encoder-Decoder transformer
编码器-解码器Transformer模型遵循标准Transformer架构。Encoder和decoder都由6个层组成,每个层有8个attention head。该Encoder利用CNN Backbone的输出特征,通过1×1卷积降低其通道维数。这个下采样后的张量沿着空间维度折叠为一维,为multi-head机制希望提供序列化的输入。我们为Encoder输入添加一个固定位置编码(fixed positional encoding),因为Transformer架构是排列不变的,若不添加位置信息则会忽略图像的空间结构。
相比之下,解码器的输入embeddings是可学习的位置编码,我们称之为对象查询(object queries)。 由于排列不变性,这些queries必须不同,解码器才能产生不同的结果。它们和编码器输出相加作为解码器的输入。解码器将queries转换为output embeddings,然后输入到姿态预测头(pose prediction head)中,并独立解码为最终的姿态集和类标签。因此,每个query都可以搜索一个object/instance,并预测其姿态pose和类class。我们将object queries的数量N设置为25,因为这大约比COCO数据集中的一张图像中出现的最大人类数量高两倍。借助编码器和解码器中的self-attention,网络能够利用它们之间的成对关系(pairwise relationship)对所有对象进行全局推理,同时利用整个图像作为上下文信息。这个Transformer解码器(以及DETR(17)中的解码器)与原始公式的不同之处在于每一层的N个对象的并行解码,与Vaswani等人(Attention is all you need, 18)使用的自回归模型形成对比。
Pose prediction head
最终的姿态估计由一个带有ReLU激活的3层感知器和一个线性投影层(FFN head)进行。该头部输出中心坐标、相对于中心的所有身体部位的位移以及单个向量中每个身体部位的可见性得分(图2b),线性层使用softmax函数输出类标签。因此,我们将中心和偏移量归一化到图像大小。
Training loss
为了并行预测所有人体姿态,网络用最优匹配后的损失进行训练,该损失是在找到预测值与真实值的最优匹配后对个体进行求和后计算出来的。因此,我们的损失必须根据类别(class)、关键点坐标(keypoint coordinates)及其可见性(visibilities)进行相应的评分,生成匹配,然后优化多实例特定姿势的损失。
对于每一个实例i,在groundtruth当中,我们将中心计算为所有可见关键点的质心(例如COCO),包含没有注释的人可见性设置为0。对于实例i的groundtruth的向量然后是![]() ,中心是
,中心是![]() ,每个bodypart i的偏移量是
,每个bodypart i的偏移量是![]() 和它的可见度。
和它的可见度。
为了增加损失函数的可读性,将这个向量分为![]() ,包含了目标的类别标签(人/非目标)
,包含了目标的类别标签(人/非目标) ,中心坐标
,中心坐标![]() ,相对姿势
,相对姿势![]() (距中心Ci的相对关节位移)和一个二元可见性的向量
(距中心Ci的相对关节位移)和一个二元可见性的向量![]() 对图像中的所有关节进行编码,无论它是否可见。
对图像中的所有关节进行编码,无论它是否可见。
然后将网络中对实例i的预测定义为![]() ,其中
,其中![]() 对于类别的预测概率,
对于类别的预测概率,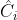 是预测中心,
是预测中心,![]() 是预测姿势,
是预测姿势,![]() 是预测的可见性。注意网络不能预测人体中心的可见性。
是预测的可见性。注意网络不能预测人体中心的可见性。
接下来,用y来表示姿势的groundtruth集合,![]() 表示N个预测集,在这里y是图像中用非对象填充的人类集合。 我们将 Ground-truth
表示N个预测集,在这里y是图像中用非对象填充的人类集合。 我们将 Ground-truth  与索引为 σ(i) 的预测之间的成对匹配成本定义为:
与索引为 σ(i) 的预测之间的成对匹配成本定义为:

![]() 是姿势特定成本,我们将会在下面定义,它涉及中心,身体部位以及它们的可见性的成本。
是姿势特定成本,我们将会在下面定义,它涉及中心,身体部位以及它们的可见性的成本。
然后根据匈牙利算法,找到具有最低匹配成本的二部匹配的最优解。

一旦得到最佳匹配,我们可以计算所有匹配对的匈牙利损失。与匹配成本一样,它包含一个对姿势进行评分的损失部分,它是一个线性组合,用于计算相对关键点坐标之间的差异的 L1 loss、中心坐标的 L2 loss和可见性的 L2 loss,具有超参数λL1, λL2 和 λctr:

因此, 代表逐点相乘,这三个损失是根据batch内的人的数量来归一化的。
代表逐点相乘,这三个损失是根据batch内的人的数量来归一化的。
最终的损失为匈牙利损失,其是类别预测的对数似然函数的负值和上述定义的关键点特定损失的线性组合,对于最优分配 的所有对来说,损失如下:
的所有对来说,损失如下:

COCO数据集中的图像只包含少量的带注释的人,为了解释这种类不平衡,我们对所有non-objects对数概率项的权重降低了10倍。
Experiments
COCO keypoint detection challenge
我们在复杂的COCO关键点估计挑战(29)上对POET进行了评估,说明了定性结果,并表明它达到了良好的性能(特别是对于体型较大的人),然后我们证明它优于我们基于已建立的自下而上方法训练的基线方法,该方法使用具有相同主干的关联嵌入 (12, 45)。 然后,我们分析了架构的不同方面和损失。最后,我们讨论了挑战和未来的工作。
Implementation details
在关键点损失中使用以下超参数设置训练所有POET模型:![]() ,transformer的初始学习率设置为
,transformer的初始学习率设置为 ,CNN Backbone为
,CNN Backbone为 ,权重衰减到,使用AdamW,dropout=0.1,并使用Xavier初始化(47)对其进行初始化。对于编码器,我们选择了不同步长s的ResNet50,模型分别称为POET-R50和POET-DC5-R50(当使用扩张卷积的C5级(将步幅从32减少到16)。在主干的最后阶段用扩张代替步幅将特征分辨率提高了两倍,但同时计算成本也增加了相同的因素。
,权重衰减到,使用AdamW,dropout=0.1,并使用Xavier初始化(47)对其进行初始化。对于编码器,我们选择了不同步长s的ResNet50,模型分别称为POET-R50和POET-DC5-R50(当使用扩张卷积的C5级(将步幅从32减少到16)。在主干的最后阶段用扩张代替步幅将特征分辨率提高了两倍,但同时计算成本也增加了相同的因素。
在训练期间,我们通过应用从 (−25,+25) 度均匀绘制的旋转、随机裁剪、水平翻转和粗略丢弃 (48) 来增加数据,每个概率为 0.5。 此外,我们调整图像的大小,使最短边落在 [400,800] 范围内,最长边最多为 1,333。 我们将预测槽的数量 N 设置为 25,因为 COCO 图像中的最大关键点注释人类数量为 13。
我们进行了两组不同的实验:
(1)训练从 ImageNet 权重初始化的 POET 以与当前最先进的模型进行比较;
(2)训练多个模型以及基线模型,由MMPose的COCO关键点挑战预训练权重来初始化。
为了与最先进的模型进行比较,我们对POET-R50以batch size=6 在两个NVIDIA V100 gpu上进行300个epoch的训练(因此总batch size为12),学习速率在200个epoch之后下降10倍,在250个epoch之后再次下降10倍。在这种设置中,一个epoch大约需要一个小时。图4和图6可以看到COCO-val上mAP的损失曲线和演化。

*图注: POET-R50在训练时期不同损失部分的变化(公式4)。实线对应于训练损失,虚线对应于验证损失(在COCO数据集上)。

*图注:在经过300个epochs训练的POET-R50的COCO验证集上的mAP演化, 与最先进的模型进行比较。学习速率在200和250个epochs后下降
Qualitative results定性结果
当我们用公式 4 中的损失以及交叉验证的超参数训练 POET-R50 时,我们发现类、关键点、可见性和中心损失减少了(图 4)。 然后,我们检查了测试图像上的预测是否准确。 图 3 描绘了 POET-R50 在 COCO-val 示例图像上的预测。此外,我们绘制了失败案例并得出结论,POET 可以成功解决多实例姿态估计的问题。

*上面一行:正确示例 下面一行:错误示例
Quantitative evaluation定量结果
首先,为了量化性能,我们计算了学习过程中的 mAP,发现它达到了高性能(图 6)。 接下来,我们将我们的结果与 COCO test-dev 上最先进的方法进行比较(表 1)。 我们将这些方法分为自上而下和自下而上的方法,并在没有多尺度测试或额外训练数据的情况下报告数字,以便进行公平比较。我们发现 POET-R50 与其他自下而上的大型人类 (![]() ) 方法相比表现具有竞争力,但对中小型人类的表现较低。
) 方法相比表现具有竞争力,但对中小型人类的表现较低。

*图注:与 COCO test-dev 上最先进的模型进行比较。 请注意,大多数模型在提取特征时使用 4 (或更小)的整体步幅,而 POET 使用 32 步幅,因此特征图要小得多,这会损害![]() 的性能。 然而,关于
的性能。 然而,关于 ![]() ,它可以与最先进的模型竞争。(感觉除了参数少一点完全不不过Higherhrnet等,也比不过TransPose)
,它可以与最先进的模型竞争。(感觉除了参数少一点完全不不过Higherhrnet等,也比不过TransPose)
我们推断这是由于所有strong models中编码器的步幅较大(例如≥4,见表1),这导致输入到transformer的空间分辨率较差。 Transformers 在输入维度上以二次方 O((H·W/S2)2) 进行缩放,因此增加步幅的成本很高。 为了展示我们方法的强大潜力,与以前的方法相比,我们接下来将 POET 与具有 ResNet backbones 的基线模型(以及不同的步幅)进行比较。
我们选择Associative Embedding (AE)(12,45)作为模型进行比较,因为该方法被证明是一种强大的自底向上方法,在目前是最先进的方法高分辨率主干HigherHRNet(15)中应用。我们创建基线模型,使用相同的预训练ResNet Backbone,输入图像大小和类似的数据增强。
我们将 AE 的 ResNet 主干的整体步幅从 4 变为 32,以确保两种方法接收相同的特征维度作为输入。 表 2 显示了基线和 POET 模型的 COCO-val 上的 AP 和 AR 值。 POET 大大优于基线方法(步幅相同),并且(步幅为 16)即使步幅为 4 也优于基线模型,这证明了 Transformer 头部适合学习图像中的多个姿势, 即使来自低分辨率特征图(图 1)。 未来的工作应该集中在寻找超参数来训练 POET 以更小的步幅,这可能会大大提高性能。

Analysis
Transformer attention
为了更好地理解编码器和解码器在transformer架构中的作用,我们在样本图像上描绘了注意力图(图 5)。 我们发现,Transformer 的编码器关注每个人,而解码器特别关注每个人看似最可区分的部分,即他的脸。

*图注:a) 以红色突出显示的编码器自注意参考点。 编码器在本地照顾每个人。 b) 预测个体的解码器注意力分数。 解码器处理人类最可区分的部分,即面部区域。 图片来自 COCO 验证集。
Learned Centers
有趣的是,POET 学习头部左侧的人体中心(图 7)。 我们假设头部是人体最容易区分的部分,因此将中心放在它旁边有助于作为预测身体其他部分的参考点。 事实上,当通过在训练损失中增加中心损失的权重(方程3),来强制模型学习的中心更接近人类质心时,POET很容易学会预测质心,但不能正确地学习关键点。

*图注:左图:在一个示例图像中,每个身体部位的预测中心(红色)和相对偏移量作为多个个体的蓝色向量。右:预测中心相对于ground truth中心的相对偏移量的散点图和平面直方图(用Bounding box对角线归一化)。大多数数据点位于第二象限,这表明POET-R50确实学到了偏向于左上方的偏置
Visibility
损失公式还使模型学习每个关键点的可见性以及位置。但是,用于 COCO 关键点检测挑战的指标没有考虑预测的可见性。 我们发现 POET 准确地预测了每个预测的身体部位的相应可见性(图 8)。

Decoder Analysis
我们通过查看解码每个阶段的预测来分析 Transformer 解码器及其层的作用。 我们发现平均性能在 3-5 个解码器层后趋于稳定(图 9)。

Conclusions
我们提出了 POET,这是一种基于卷积编码器、Transformers 和二分匹配损失的新型姿态估计方法,用于直接集合预测。 我们的方法在困难的 COCO 关键点挑战中取得了很好的结果,并且是第一个端到端可训练的方法。 POET 的灵感来自最近的 DETR (17),它使用转换器处理对象识别和全景分割。
目前,POET还没有达到最先进的性能,但我们希望它能激发未来的研究来解决这些挑战。类似地,与POET相比(见表1),DETR在小物体上的表现更差,只能达到最先进性能的80% 。POET和DETR的一个主要限制是收敛速度慢,并且需要大量的内存,这使得高分辨率Backbone的实验成本很高,而这对于精确的姿态估计是很重要的。但我们的方法很简单,可以应用于任何经过端到端训练的Backbone进行多实例姿态估计。