论文阅读笔记-GT U-Net: A U-Net Like Group TransformerNetwork for Tooth Root Segmentation
目录
摘要
1.引言
2.方法
2.1 U-net like group transformer network
2.2.1 理论层面
2.2.2 代码层面
2.2 Shape-sensitive Fourier Descriptor Loss Function
2.2.1 理论层面
2.2.2 代码层面
3.结果
3.1 Tooth Root Segmentation Dataset
3.2 Implementation Details
3.3实验结果
3.4 Performance on the Public DRIVE Dataset
摘要
为了实现对根管治疗的准确评估,一个基本的步骤是对口腔x线图像进行牙根分割,因为牙根边界的位置是根管治疗评估中重要的解剖信息。然而,模糊边界使得牙根的分割非常具有挑战性。在本文中,我们提出了一种新的端到端U-Net like Group Transformer Network(GTU-Net)用于牙根的分割。该网络保留了U-Net的基本结构,但每个编码器和解码器都被一个组Transformer所取代,利用分组结构和bottleneck结构,大大降低了传统transformer结构的计算成本。此外,所提出的GT U-Net是由卷积和transformer的混合结构组成的,这使其独立于训练前的权值。为了进行优化,我们还提出了一个形状敏感的傅里叶描述符(FD)损失函数来利用形状先验知识。实验结果表明,该网络在采集的牙根分割数据集上取得了最先进的性能。
作者想解决的问题:通过人工智能对模糊边界的牙根进行分割,简化根管治疗评估难度。
作者解决问题的理论/模型:提出一种新的端到端U-Net like Group Transformer Network,将U-Net中的每个编码器和解码器都被一个组Transformer给取代
这个方法的优越性(创新点)在哪?:①U-net中的每个编码器和解码器都被一个组Transformer所取代,利用分组结构和bottleneck结构,大大降低了传统transformer结构的计算成本 ②提出了一个形状敏感的傅里叶描述符(FD)损失函数来利用形状先验知识
1.引言
进行精确的牙根分割是一项非常具有挑战性的任务,原因如下:1)牙根边界模糊,牙齿周围的一些组织与牙齿的强度相似,如图所示。1(a);2)口腔x线图像中的其他骨骼和组织可能与牙根重叠,如图所示。1(b);3)x射线图像的质量可能很差,如过度曝光或曝光不足,如图所示。1 (c)

为了解决上述问题,赵等人提供了一个两阶段的注意分割网络,通过聚焦于自动捕捉真实的牙齿区域,可以有效地缓解非均匀强度分布问题。Lee等人。采用微调掩模R-CNN算法来实现牙齿分割。然而,这些方法并不能有效地解决模糊边界的分割问题,而且性能的提高大多是增量式的。陈晓强等人。提出了一种具有多尺度结构相似性(MS-SSIM)损失的新型MSLPNet,增强了具有模糊根边界的牙齿分割。Cheng等人提出了U-Net+DFM来学习一个方向场。它表征了像素之间的方向性关系,并隐式地限制了分割结果的形状。
虽然这些方法在分割任务中都取得了良好的效果,但它们仍然受到卷积神经网络(CNNs)固有局部性的限制,不能很好地处理全局特征。为了缓解这个问题,非常希望通过非本地操作实现长期依赖,并进行转换。Transformer提供了一个建模管道来实现这一点。陈晓强等人提出了一种基于变压器的transUnet编码器,采用具有12层transformer的ViT作为编码器。然而,ViT依赖于预先训练的训练由一个巨大的图像语料库获得的权值,这导致了在不足的数据集上的性能不佳。为了解决这个问题,阿拉文德等人结合transformer和卷积,提出了一种有效的实例分割骨干BoTNet。由于Transformer的计算复杂度较高,BoTNet只用Transformer取代了ResNet最后几层的部分卷积。
为了缓解现有方法中存在的问题,我们的网络GTU-Net采用了卷积和变压器的组合,没有训练前的权重,以及利用分组结构和瓶颈结构,显著减少了计算量。此外,FD损失还通过充分利用形状先验知识,解决了模糊边界分割的问题。本文的主要贡献如下:
为什么研究这个课题:进行精确的牙根分割是一项非常具有挑战性的任务。牙根边界可能模糊,牙齿周围的一些组织与牙齿的强度相似口腔x线图像中的其他骨骼和组织可能与牙根重叠,x射线图像的质量可能很差,如过度曝光或曝光不足。
研究进行到了哪个阶段:虽然这些方法在分割任务中都取得了良好的效果,但它们仍然受到卷积神经网络(CNNs)固有局部性的限制,不能很好地处理全局特征。
使用理论基于哪些假设:①保留了一般的U-Net框架的优势,并将Transformer引入医学图像分割应用,以解决卷积的限制。②我们设计了一个分组结构和一个瓶颈结构,这大大降低了变压器的计算负荷,使其在图像分割中可行。③对于根的分割任务,我们提出了一个形状敏感的傅里叶描述器损失函数来处理模糊边界分割的问题。
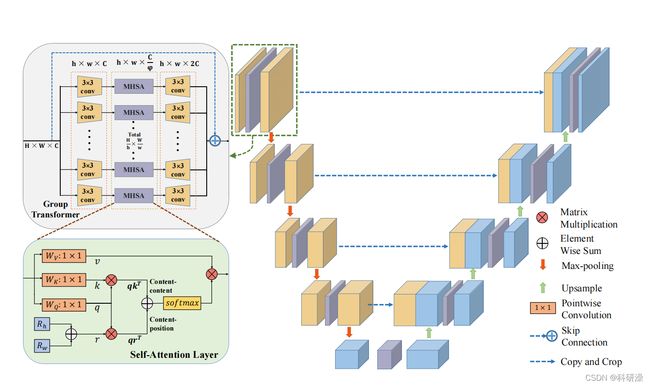
GT U-Net的结构由一个u型通用框架和group transformer组成。自注意层是多头自注意(MHSA)的基本结构,其中我们的MHSA有4个head。
2.方法
GTU-Net遵循整体的u型结构,其中编码器和解码器都由group transformer组成。它的工作与一个形状敏感的傅里叶描述(FD)损失函数的牙根分割。下面将详细描述所提出的方法
2.1 U-net like group transformer network
2.2.1 理论层面
总体结构:我们的group transfomer是由一个shortcut connection、一个分组模块、3×3卷积、多头自注意(MHSA)模块和一个合并模块组成的。
其中,利用shortcut connection解决梯度消失的问题,保持低水平信息。考虑到MHSA在跨n个实体进行全局执行时需要O(n2d)内存和计算,我们设计了分组模块和3×3卷积来减少MHSA的计算量。
分组结构和Bottleneck结构:由于自然语言和图像之间的差异,很难将tranformer直接应用于医学图像任务。自然语言中的单词数量有限,但像素数随着图像大小的增加而呈二次增长。因此,我们设计了group transformer来解决医学图像分割中由于图像特征而造成的计算过多的问题。
2.2.2 代码层面

#structure of encoder
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
# structure of decoding + concat path
d5 = self.Up5(x5)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d1 = self.Conv_1x1(d2)conv结构:
def _make_bot_layer(ch_in, ch_out):
W = H = 4
dim_in = ch_in
dim_out = ch_out
stage5 = []
stage5.append(
BotBlock(in_dimension=dim_in, curr_h=H, curr_w=W, stride=1 , target_dimension=dim_out)
)
return nn.Sequential(*stage5)Botblock的构造如下: Q_h和Q_w是每个块的大小,P_h和P_w是块的数量。
Q_h = Q_w = 4
N, C, H, W = x.shape
P_h, P_w = H // Q_h, W // Q_w
x = x.reshape(N * P_h * P_w, C, Q_h, Q_w)
out = self.conv1(x)
out = self.mhsa(out)
out = out.permute(0, 3, 1, 2)
out = self.conv2(out) # Avgpool2d and Relu
out = self.conv3(out)Up x 构造:
self.Up5 = up_conv(ch_in=1024,ch_out=512)
class up_conv(nn.Module):
def __init__(self,ch_in,ch_out):
super(up_conv,self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.up(x)
return x2.2 Shape-sensitive Fourier Descriptor Loss Function
2.2.1 理论层面
牙根都具有相似的形状。可将形状信息添加到损失函数中,有助于更好地指导模型分割牙根。(xm,ym)是齿根边界上包含N个像素的坐标之一,边界形状可以形成一个复数z(m)=xm+jym。该形状的傅里叶描述符被定义为DFT(z(m)),即、z(k)。

傅里叶描述符是一种封闭形状的定量表示,独立于它们的起点、缩放、位置和旋转。因此,可以对预测的边界A与人工标记的边界B之间的形状差进行量化,并可以根据Z(k)进行计算。
A:prediction B:target
原始的损失函数是二值交叉熵(BCE)。在所提出的方法中,我们添加了傅里叶描述符来建立一个新的形状敏感损失函数。考虑到它们在整个训练过程中的数量级,我们计算了最终的傅里叶描述符(FD)损失:

新的FD损失同样关注形状损失和BCE损失,无论它们的数量级如何。β由∆Z(k)的数量级决定,本文将设为10。(为参数)
2.2.2 代码层面
def countfly(imageSR,imageGT):
res=[]
for i in range(len(imageSR)):
# imOricpy is for processing, imgOri is for showing
try:
imgOricpy = imageSR[i]
#imgSP = cv2.imread(imageGT , 1)
imgSP = imageGT[i]
templeteComVector = []
sampleComVectors = []
# Get complex vector
templeteComVector=getTempleteCV(imgOricpy,templeteComVector)
sampleComVectors=getSampleCV(imgSP,sampleComVectors)
# Get fourider descriptor
#print(len(templeteComVector))
tpFD = getempleteFD(templeteComVector)
sampleFDs = getsampleFDs(sampleComVectors)
# real match function
res.append(match(tpFD, sampleFDs))
except:
res.append(1)
res= np.mean(res)
return res逐句讲解:
imgOricpy = imageSR[i]
#imgSP = cv2.imread(imageGT , 1)
imgSP = imageGT[i]
imgOricpy与imgSP分别为预测出的分割图像,以及标注的分割图像(可视为predict和target)
templeteComVector = []
sampleComVectors = []
templeteComVector=getTempleteCV(imgOricpy,templeteComVector)
sampleComVectors=getSampleCV(imgSP,sampleComVectors) 通过GetTempleteCV与getSampleCV函数分别得到预测分割图像和标注分割图像的轮廓向量集,具体实现方法如下:
def getTempleteCV(imgOricpy,templeteComVector):
tpContour = getContours(imgOricpy)
for contour in tpContour:
x, y, w, h = cv2.boundingRect(contour) #通过轮廓点绘制出一个矩形框
for point in contour:
templeteComVector.append(complex(point[0][0]-x, (point[0][1]-y))) #形成复数Z(m)
return templeteComVector其中getContours函数主要用于获得轮廓的点集,其函数的主要功能实现代码为如下句段
contours, hierarchy = cv2.findContours(imgray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)findContours会返回输入的灰度分割图像imgray的轮廓的点集进行返回,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE分别表示只检测最外围的轮廓以及保存物体边界上所有连续的轮廓点到contours向量内。
随后得到轮廓点集后,会通过BoundingRect函数绘制出一个包含轮廓大概范围的矩形框
所获得坐标(x,y)是齿根边界上包含N个像素的坐标之一,并计算出复数z(m)=xm+jym,加入到templeteComVector向量集中,SampleComVector的获得方式同理。
for contour in tpContour:
x, y, w, h = cv2.boundingRect(contour) #通过轮廓点绘制出一个矩形框
for point in contour:
templeteComVector.append(complex(point[0][0]-x, (point[0][1]-y))) #形成复数Z(m)而getempleteFD与getsampleFDs函数则是将返回的轮廓点集复数Z(m)放入傅里叶变换之中
tpFD = getempleteFD(templeteComVector) #得到预测的傅里叶算法Z(k)
sampleFDs = getsampleFDs(sampleComVectors)#得到标注的傅里叶算法Z(k)def getsampleFDs(sampleComVectors):
sampleFD = np.fft.fft(sampleComVectors)
return sampleFD即对应论文公式:
随后将对预测的边界A与人工标记的边界B之间的形状差进行量化
res.append(match(tpFD, sampleFDs))def finalFD(fourierDesc):
fourierDesc = rotataionInvariant(fourierDesc)
fourierDesc = scaleInvariant(fourierDesc)
fourierDesc = transInvariant(fourierDesc)
fourierDesc = getLowFreqFDs(fourierDesc)
return fourierDesc
# Core match function
def match(tpFD, spFDs):
tpFD = finalFD(tpFD)
# dist store the distance, same order as spContours
dist = []
font = cv2.FONT_HERSHEY_SIMPLEX
spFD = finalFD(spFDs)
res=np.linalg.norm(np.array(spFD)-np.array(tpFD))
return res即对应论文公式:

3.结果
3.1 Tooth Root Segmentation Dataset
我们在患者同意下建立了一个新的根管治疗x射线图像数据集。牙根分割数据集包含248个根管治疗来自不同患者的X射线图像。三位经验丰富的口腔医生帮助完成了牙根注释。具体来说,为了尽量减少观察者间的变异性,最终的注释结果需要所有三位吻合学家的同意。

3.2 Implementation Details
在我们的实现中,我们比较了三种最先进的方法,U-Net[18],注意U-Net[19],和TransUNet[10]。所有被比较的方法和我们的方法都使用PyTorch实现,并在4个RTX2080Tigpu上进行训练。采用随机中心裁剪、随机旋转和轴向翻转等方法来增强数据避免过拟合。
在训练中,采用Adam优化器,将初始学习速率和动量分别设置为2×10−4和0.5。训练周期的总数为200个,批处理大小为12个。所有的图像的大小都被调整为256×256作为输入。
Group Transformer的h×w设置为8×8,ϕ设置为2。为了评估分割性能,我们将结果与6个评估指标进行了比较,包括准确性(ACC)、灵敏度(SE)、特异性(SP)、Jaccard相似度(JS)和Dice系数(DICE)。此外,我们还采用了3倍交叉验证的方法来测试牙根分割数据集的分割性能。
3.3实验结果

所有方法的平均标准差结果见表1。从这个表中可以总结出,我们提出的GTU-Net获得了最好的精度、灵敏度、Jaccard相似度和骰子系数。
我们定性地比较了三张口腔x射线图像的分割结果。很明显,我们的方法在模糊边界上得到了最好的分割结果。
为了验证FD损失的有效性,我们实现了无FD损失的GTU-Net。根据表1和图中的比较。3、通过利用解剖先验知识隐式限制分割结果的形状,FD损失可以有效地应用于边界模糊但形状相似的分割任务。
3.4 Performance on the Public DRIVE Dataset
为了进一步评估我们的GTU-Net的性能,我们将其应用于广泛使用的视网膜数据集DRIVE。数据集由40张随机选择的565×584的彩色眼底图像组成。根据官方规定,DRIVE被分成两组进行训练和测试。
Group Transformer参数h和w都设为4,ϕ也设为2。由于FD损失被提出用于与形状相似的医学图像分割,如牙根分割,因此我们没有在驱动数据集上实现它。为了有效地训练我们的GTU-Net.
我们从原始图像中裁剪出图像补丁,采用64×64作为样本补丁大小,这在该数据集上被广泛采用。

比较结果见表2。可以观察到,我们的GTU-Net在SE上比其他方法好至少3.2%,在F1上超过2.5%,在ACC上超过0.5%。在SP和AUC方面,我们的GTU-Net与最佳方法相比取得了竞争性能,将它们的差异限制在0.2%以内。同时,图中给出了一些具有代表性的分割结果的可视化情况。 4.我们可以清楚地观察到,通过我们的方法可以很好地分割视网膜的血管部分,除了一些非常小的区域。