【数据博彩】如何使用大数据机器学习预测NBA比赛结果?
引言
伴随着大数据时代的来临,机器学习、深度学习、人工智能等越来越多的出现在我们的视野中,数据技术正在颠覆着包括体育和博彩在内的各行各业,本文着手于使用大数据机器学习预测NBA比赛结果,希望给相关行业从业者和爱好者带来启迪,目前模型表现良好,预测准确率高达70%。本文所给出的结果不宜直接用于博彩,更多资料请见数据驱动建模中心。
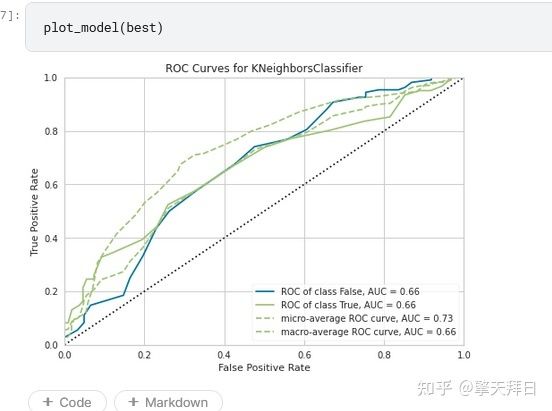
用于NBA预测的模型评估曲线
方法基础
机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
代理模型
代理模型采用一个数据驱动的、自下而上的办法来建立。一般假定原模拟过程的内部精确处理过程未知(有时也可能已知),但是该模型的输入-输出行为则非常重要。通过在仔细选择的有限个点(输入)计算原模型的响应(输出),从而建立代理模型。这一过程也被称为行为建模或者黑箱模型,但是这两个名字会造成歧义。如果只涉及唯一的变量,这一过程也被称为曲线拟合。
实现工具
PyCaret
PyCaret是一个代码量超低的机器学习库,它有效的自动化了机器学习工作流。实现了端到端的机器学习和模型管理工具,可以成倍地加快机器学习的学习、部署和实践速度。
实现过程
第一步 安装PyCaret
!pip install pycaret --ignore-install llvmlite第二步 获取NBA球队全方面数据
import pandas as pd
result = pd.read_csv('/kaggle/input/nba-prediciton/result.csv')
team = pd.read_csv('/kaggle/input/nba-prediciton/team.csv')
time_table = pd.read_csv('/kaggle/input/nba-prediciton/timetable.csv')
result['result'] = (result['PTS'] > result['PTS.1'])
df = result.loc[:,['Date','Start (ET)','Visitor/Neutral','Home/Neutral','Arena','result']]
time_table = time_table.loc[:,['Date','Start (ET)','Visitor/Neutral','Home/Neutral','Arena']]
df = pd.merge(df, team, how='right', left_on='Visitor/Neutral',right_on='Team')
df = pd.merge(df, team, how='right', left_on='Home/Neutral',right_on='Team')
time_table = pd.merge(time_table, team, how='right', left_on='Visitor/Neutral',right_on='Team')
time_table = pd.merge(time_table, team, how='right', left_on='Home/Neutral',right_on='Team')第三步 清洗数据
del df['Date']
del df['Team_x']
del df['Team_y']
del time_table['Date']
del time_table['Team_x']
del time_table['Team_y']
df.info()第四步 数据预处理
from pycaret.classification import *
clf = setup(df, target = 'result', n_jobs=1) 第五步 模型选择
best = compare_models()第六步 预测后续的比赛结果
output = predict_model(best, raw_score = True, data = time_table)
output.to_csv('output.csv')总结
本文仅结合代码对思路做大概阐述,全部代码和详细解析请见:【重磅】大数据机器学习预测NBA比赛结果独家方案+代码