Python+大数据-Spark技术栈(一) SparkBase环境基础
Python+大数据-Spark技术栈(一) SparkBase环境基础
SparkBase环境基础
Spark学习方法:不断重复,28原则(使用80%时间完成20%重要内容)
Spark框架概述
Spark风雨十年
-
2012年Hadoop1.x出现,里程碑意义
-
2013年Hadoop2.x出现,改进HDFS,Yarn,基于Hadoop1.x框架提出基于内存迭代式计算框架Spark
-

-
1-Spark全家桶,实现离线,实时,机器学习,图计算
-
2-spark版本从2.x到3.x很多优化
-
3-目前企业中最多使用Spark仍然是在离线处理部分,SparkSQL On Hive
Spark 是什么
- Spark是一个处理大规模数据的计算引擎

扩展阅读:Spark VS Hadoop
Spark和Hadoop对比
面试题:Hadoop的基于进程的计算和Spark基于线程方式优缺点?
答案:Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。

Spark 四大特点
1-速度快
2-非常好用
3-通用性
4-运行在很多地方
Spark 框架模块了解
- Spark框架通信使用Netty框架,通信框架
- Spark数据结构:核心数据RDD(弹性 分布式Distrubyte 数据集dataset),DataFrame
- Spark部署模式(环境搭建)
- local
- local 单个线程
- local[*] 本地所有线程
- local【k】 k个线程
- Spark的RDD有很多分区,基于线程执行分区数据计算,并行计算
- standalone
- StandaloneHA
- Yarn
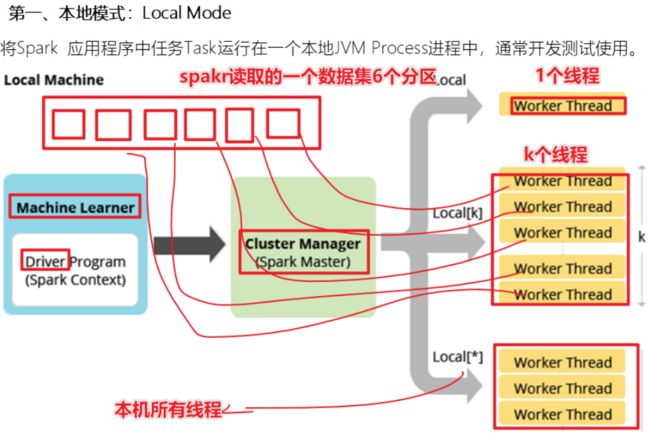
Spark环境搭建-Local
基本原理
1-Spark的Local模式使用的是单机多线程的方式模拟线程执行Spark的计算任务
2-Spark的local[1] 1个线程执行计算 local[*]本地的所有线程模拟
安装包下载
1-搞清楚版本,本机一定得搭建Hadoop集群(Hadoop3.3.0)
2-上传到Linux中,spark3.1.2-hadoop3.2-bin.tar.gz
3-解压Spark的压缩包
tar -zxvf xxx.tar.gz -C /export/server
ln -s spark-3.1.2-bin-hadoop3.2/ /export/server/spark
4-更改配置文件
这里对于local模式,开箱即用
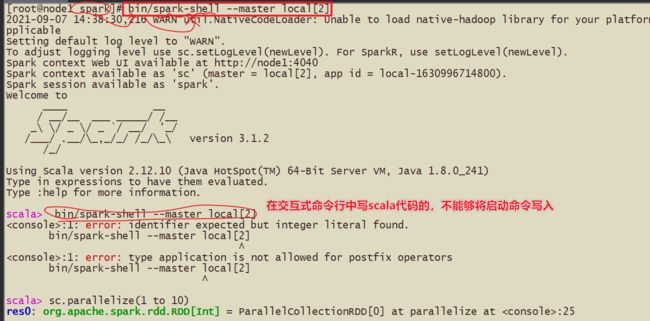
5-测试
spark-shell方式 使用scala语言
pyspark方式 使用python语言



上午回顾:
为什么要学习Spark?
- 答案:首先Spark是基于Hadoop1.x改进的大规模数据的计算引擎,Spark提供了多种模块,比如机器学习,图计算
- 数据第三代计算引擎
什么是Spark?
- Spark是处理大规模数据的计算引擎
- 1-速度快,比Hadoop块100倍(机器学习算法) 2-易用性(spark.read.json) 3-通用性 4-run anywhere
Spark有哪些组件?
- 1-SparkCore—以RDD(弹性,分布式,数据集)为数据结构
- 2-SparkSQL----以DataFrame为数据结构
- 3-SparkStreaming----以Seq[RDD],DStream离散化流构建流式应用
- 4-结构化流structuredStreaming—DataFrame
- 5-SparkMllib,机器学习,以RDD或DataFrame为例
- 6-SparkGraphX,图计算,以RDPG弹性分布式属性图
Spark有哪些部署方式?
- local模式
- standalone模式(独立部署模式)
- standaloneHA模式(高可用模式)
- Yarn模式(Hadoop中分布式资源调度框架)
注意:

PySpark安装
- 1-明确PyPi库,Python Package Index 所有的Python包都从这里下载,包括pyspark
- 2-为什么PySpark逐渐成为主流?
- http://spark.apache.org/releases/spark-release-3-0-0.html
- Python is now the most widely used language on Spark. PySpark has more than 5 million monthly downloads on PyPI, the Python Package Index.
- 记住如果安装特定的版本需要使用指定版本,pip install pyspark2.4.5
- 本地安装使用pip install pyspark 默认安装最新版
PySpark Vs Spark
Python作为Spark的主流开发语言
PySpark安装
1-如何安装PySpark?
- 首先安装anconda,基于anaconda安装pyspark
- anaconda是数据科学环境,如果安装了anaconda不需要安装python了,已经集成了180多个数据科学工具
- 注意:anaconda类似于cdh,可以解决安装包的版本依赖的问题
Linux的Anaconda安装
2-如何安装anconda?
- 去anaconda的官网下载linux系统需要文件 Anaconda3-2021.05-Linux-x86_64.sh
- 上传到linux中,执行安装sh Anaconda3-2021.05-Linux-x86_64.sh或bash Anaconda3-2021.05-Linux-x86_64.sh
- 直接Enter下一步到底,完成
- 配置环境变量,参考课件
3-Anaconda有很多软件
IPython 交互式Python,比原生的Python在代码补全,关键词高亮方面都有明显优势
jupyter notebook:以Web应用启动的交互式编写代码交互式平台(web平台)
180多个工具包
conda和pip什么区别?
conda和pip都是安装python package
conda list可以展示出package的版本信息
conda 可以创建独立的沙箱环境,避免版本冲突,能够做到环境独立
conda create -n pyspark_env python==3.8.8
4-Anaconda中可以利用conda构建虚拟环境
- 这里提供了多种方式安装pyspark
- (掌握)第一种:直接安装 pip install pyspark
- (掌握)第二种:使用虚拟环境安装pyspark_env中安装,pip install pyspark
- 第三种:在PyPi上下载下来对应包执行安装
5-如何查看conda创建的虚拟环境?
- conda env list
- conda create -n pyspark_env python==3.8.8
- pip install pyspark
PySpark安装
- 1-使用base的环境安装
- 2-使用pyspark_env方式安装
-
查看启动结果
-
-
简单的代码演示
-
-
在虚拟环境下的补充
-
-
webui
-
-
注意:
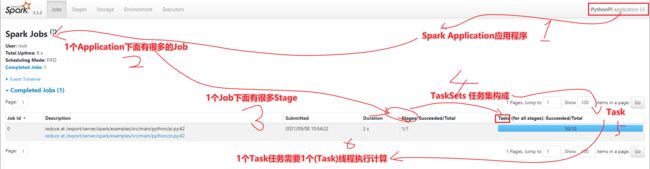
- 1-1个Spark的Applicaition下面有很多Job
- 2-1个Job下面有很多Stage
Jupyter环境设置
监控页面
- 4040的端口
运行圆周率
回顾Hadoop中可以使用
hadoop jar xxxx.jar 100
yarn jar xxxx.jar 1000
跑的mr的任务
Spark中也有对应的提交任务的代码
spark-submit 提交圆周率的计算代码 */examples/src/main/python/pi.py*
提交的命令:
bin/spark-submit --master local[2] /export/server/spark/examples/src/main/python/pi.py 10
或者基于蒙特卡洛方法求解的Pi,需要参数10,或100代表的次数
bin/spark-submit
–master local[2]
/export/server/spark/examples/src/main/python/pi.py
10*  * 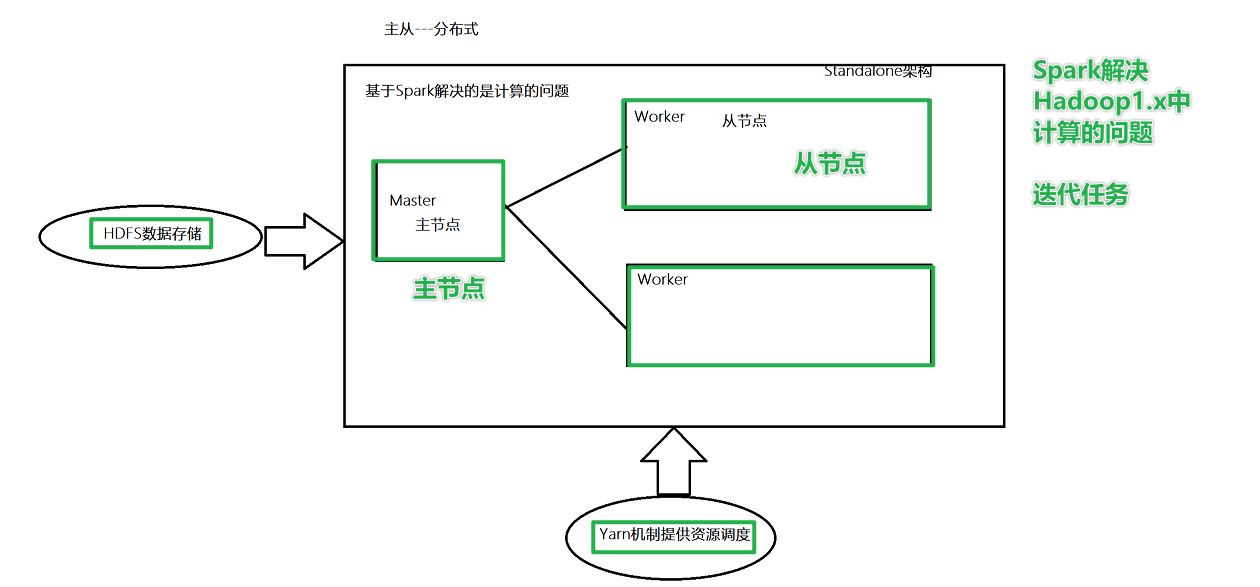 * 蒙特卡洛方法求解PI *  * 采用的扔飞镖的方法,在极限的情况下,可以用落入到圆内的次数除以落入正方形内的次数 * hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 10 10 * hadoop提交任务中使用 第一个10代表是map任务,第二10代表每个map任务投掷的次数 * spark-submit的提交的参数10的含义是投掷的次数 * 简单的py代码 * ``` # def pi(times): # times的意思是落入到正方形的次数 x_time = 0 for i in range(times): # 有多少落入到圆内 x = random.random() y = random.random() if x * x + y * y <= 1: x_time += 1 return x_time / times * 4.0print(pi(10000000))#3.1410412
环境搭建-Standalone
- 完成了Spark的local环境搭建
- 完成了Spark的PySpark的local环境搭建
- 基于PySpark完成spark-submit的任务提交
Standalone 架构
- 如果修改配置,如何修改?
- 1-设定谁是主节点,谁是从节点
- node1是主节点,node1,node2,node3是从节点
- 2-需要在配置文件中声明,
- 那个节点是主节点,主节点的主机名和端口号(通信)
- 那个节点是从节点,从节点的主机名和端口号
- 3-现象:进入到spark-shell中或pyspark中,会开启4040的端口webui展示,但是一旦交互式命令行退出了,wenui无法访问了,需要具备Spark的历史日志服务器可以查看历史提交的任务

角色分析
Master角色,管理节点, 启动一个名为Master的进程, *Master进程有且仅有1个*(HA模式除外)
Worker角色, 干活节点,启动一个名为 Worker的进程., Worker进程****最少1个, 最多不限制****
Master进程负责资源的管理, 并在有程序运行时, 为当前程序创建管理者Driver
Driver:驱动器,使用SparkCOntext申请资源的称之为Driver,告诉任务需要多少cpu或内存
Worker进程负责干活, 向Master汇报状态, 并听从程序Driver的安排,创建Executor干活
在Worker中有Executor,Executor真正执行干活
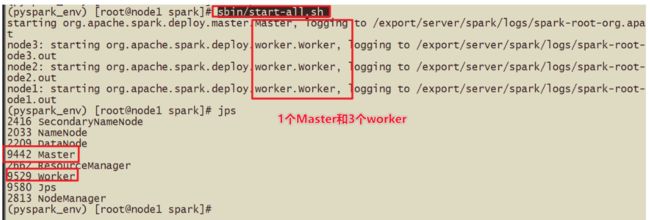
集群规划
谁是Master 谁是Worker
node1:master/worker
node2:slave/worker
node3:slave/worker
为每台机器安装Python3
安装过程
- 1-配置文件概述
- spark-env.sh 配置主节点和从节点和历史日志服务器
- workers 从节点列表
- spark-default.conf spark框架启动默认的配置,这里可以将历史日志服务器是否开启,是否有压缩等写入该配置文件
- 2-安装过程
- 2-1 修改workers的从节点配置文件
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W2MnBXFE-1667913989156)(C:\Users\liuyikang\AppData\Roaming\Typora\typora-user-images\image-20221108210820464.png)]
- 2-2 修改spark-env.sh配置文件
- hdfs dfs -mkdir -p /sparklog/
- 2-3 修改spark-default.conf配置文件
- 2-4 配置日志显示级别(省略)
测试
WebUi
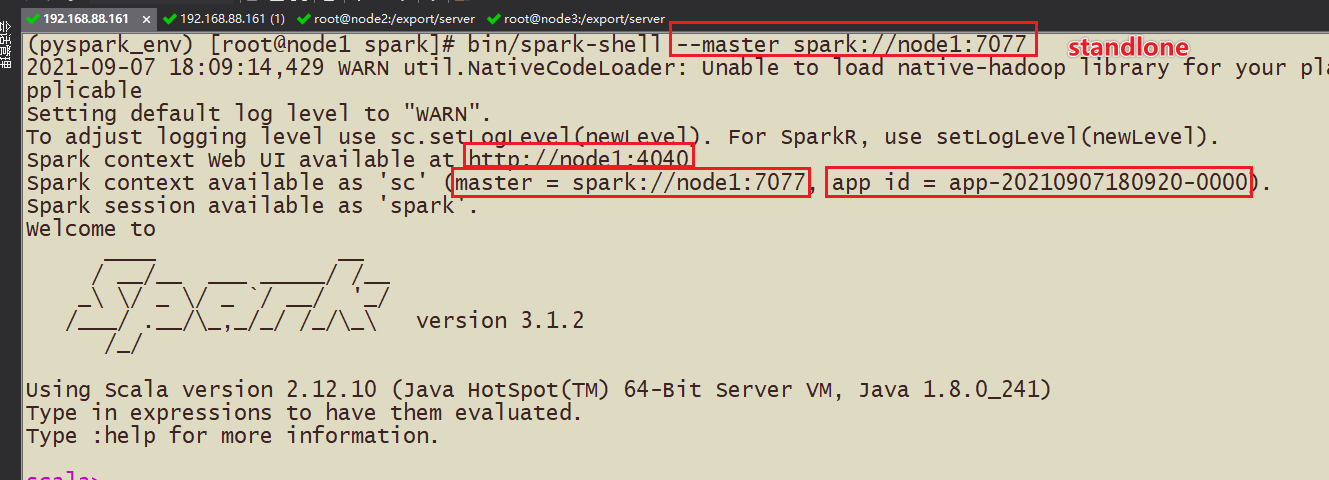
(1)Spark-shell
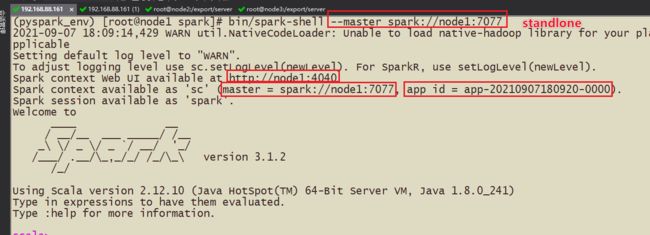
bin/spark-shell --master spark://node1:7077
(2)pyspark
前提:需要在三台机器上都需要安装Anaconda,并且安装PySpark3.1.2的包
步骤:
如果使用crt上传文件一般使用rz命令,yum install -y lrzsz
1-在3台虚拟机上准备anconda
2-安装anaconda,sh anaconda.sh
3-安装pyspark,这里注意环境变量不一定配置,直接进去文件夹也可以
4-测试
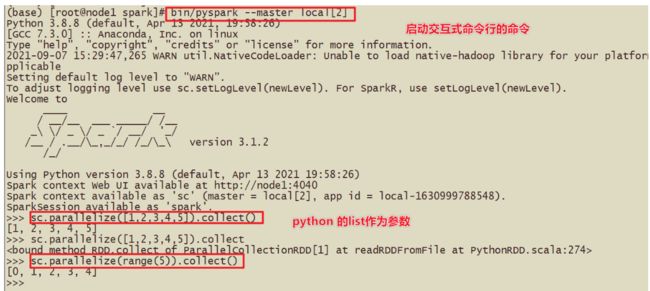
调用:bin/pyspark --master spark://node1:7077
(3)spark-submit
#基于Standalone的脚本
#driver申请作业的资源,会向–master集群资源管理器申请
#执行计算的过程在worker中,一个worker有很多executor(进程),一个executor下面有很多task(线程)
bin/spark-submit
–master spark://node1:7077
–driver-memory 512m
–executor-memory 512m
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
/export/server/spark/examples/src/main/python/pi.py
10
- 完毕




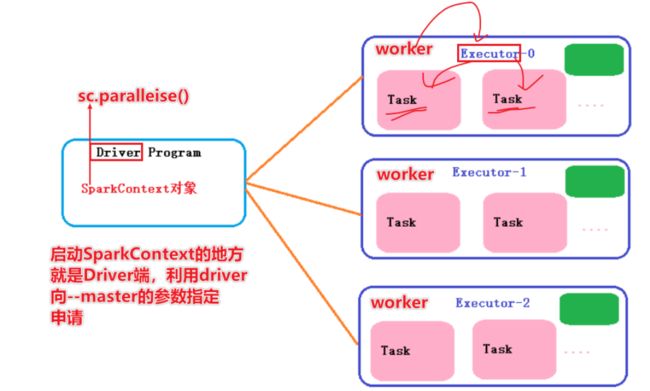
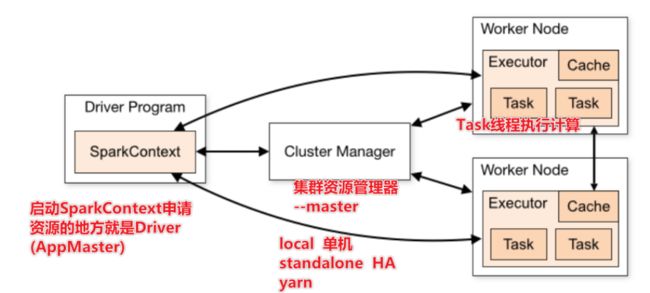
Spark 应用架构
两个基础driver和executor
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
2)、Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task;
3)、Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver;
4)、Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)、Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止;
环境搭建StandaloneHA
- 回顾:Spark的Standalone独立部署模式,采用Master和Worker结构进行申请资源和执行计算
- 问题:如果Master出问题了,整个Spark集群无法工作,如何处理?
- 解决:涉及主备,需要一个主节点,需要一个备用节点,通过ZK选举,如果主节点宕机备份节点可以接替上主节点继续执行计算
高可用HA
- 架构图
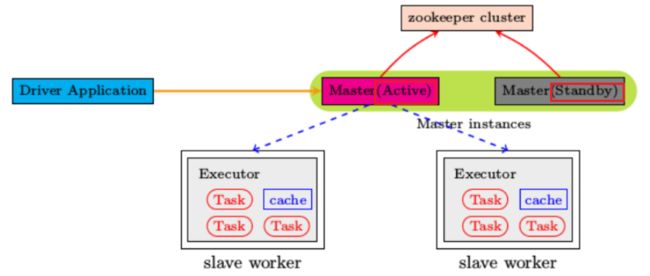
基于Zookeeper实现HA
- 如何实现HA的配置?
- 1-需要修改spark-env.sh中的master的ip或host,注释掉,因为依靠zk来选择
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e4L5V4wc-1667913989175)(https://gitee.com/hu_hao11/blogImage/raw/master/img/image-20210907153335422.png)]
- 2-开启zk,zkServer.sh status
- 3-需要在原来的基础上启动node2的master的命令 start-master.sh
- 4-重启Spark的Standalone集群,然后执行任务
- sbin/stop-all.sh
- sbin/start-all.sh
- webUI

测试运行
spark-shell
pyspark
- bin/pyspark --master spark://node1:7077,node2:7077
spark-submit
#基于StandaloneHA的脚本
bin/spark-submit
–master spark://node1:7077,node2:7077
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
/export/server/spark/examples/src/main/python/pi.py
10
测试:目前node1是主节点,node2是standby备用主节点,这时候将node1 的master进程干掉,然后看node2的master是否能够接替node1的master的作用,成为active的master
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WnwlstfF-1667913989181)(2-SparkBase-基础1.assets/image-20210908115623414.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AD1Mye67-1667913989182)(2-SparkBase-基础1.assets/image-20210908120015930.png)]
如果一个master节点宕机另外一个master启动需要1-2分钟
完毕

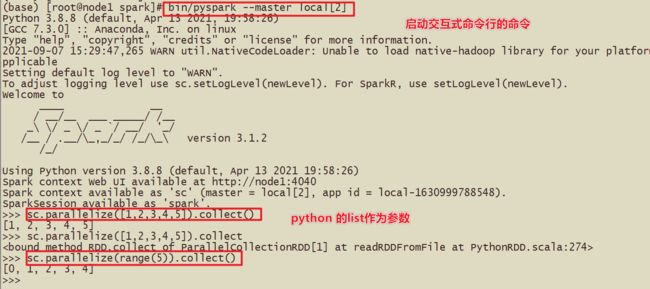
使用Python语言开发Spark程序代码
- Spark Standalone的PySpark的搭建----bin/pyspark --master spark://node1:7077
- Spark StandaloneHA的搭建—Master的单点故障(node1,node2),zk的leader选举机制,1-2min还原
- 【scala版本的交互式界面】bin/spark-shell --master xxx
- 【python版本交互式界面】bin/pyspark --master xxx
- 【提交任务】bin/spark-submit --master xxxx
【学会配置】Windows的PySpark环境配置
- 1-安装Andaconda
- 2-在Anaconda Prompt中安装PySpark
- 3-执行安装
- 4-使用Pycharm构建Project(准备工作)
- 需要配置anaconda的环境变量–参考课件
- 需要配置hadoop3.3.0的安装包,里面有winutils,防止pycharm写代码的过程中报错

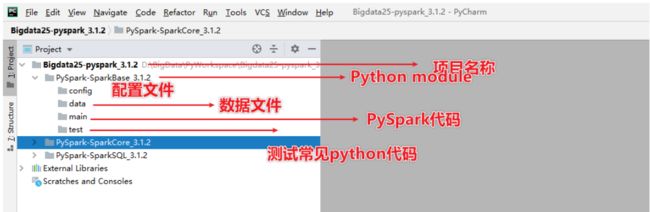
PyCharm构建Python project
- 项目规划
- 项目名称:Bigdata25-pyspark_3.1.2
- 模块名称:PySpark-SparkBase_3.1.2,PySpark-SparkCore_3.1.2,PySpark-SparkSQL_3.1.2
- 文件夹:
- main pyspark的代码
- data 数据文件
- config 配置文件
- test 常见python测试代码放在test中

应用入口:SparkContext
- http://spark.apache.org/docs/latest/rdd-programming-guide.html
WordCount代码实战
需求:给你一个文本文件,统计出单词的数量
算子:rdd的api的操作,就是算子,flatMap扁平化算子,map转换算子
Transformation算子
Action算子
步骤:
1-首先创建SparkContext上下文环境
2-从外部文件数据源读取数据
3-执行flatmap执行扁平化操作
4-执行map转化操作,得到(word,1)
5-reduceByKey将相同Key的Value数据累加操作
6-将结果输出到文件系统或打印代码:
-- coding: utf-8 --
Program function: Spark的第一个程序
1-思考:sparkconf和sparkcontext从哪里导保
2-如何理解算子?Spark中算子有2种,
一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD),
一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子
from pyspark import SparkConf,SparkContext
if name == ‘main’:
1 - 首先创建SparkContext上下文环境
conf = SparkConf().setAppName(“FirstSpark”).setMaster(“local[*]”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“WARN”)#日志输出级别2 - 从外部文件数据源读取数据
fileRDD = sc.textFile(“D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\words.txt”)
print(type(fileRDD))#
all the data is loaded into the driver’s memory.
print(fileRDD.collect())
[‘hello you Spark Flink’, ‘hello me hello she Spark’]
3 - 执行flatmap执行扁平化操作
flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" "))
print(type(flat_mapRDD))
print(flat_mapRDD.collect())
#[‘hello’, ‘you’, ‘Spark’, ‘Flink’, ‘hello’, ‘me’, ‘hello’, ‘she’, ‘Spark’]
# 4 - 执行map转化操作,得到(word, 1)
rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1))
print(type(rdd_mapRDD))#
print(rdd_mapRDD.collect())
[(‘hello’, 1), (‘you’, 1), (‘Spark’, 1), (‘Flink’, 1), (‘hello’, 1), (‘me’, 1), (‘hello’, 1), (‘she’, 1), (‘Spark’, 1)]
5 - reduceByKey将相同Key的Value数据累加操作
resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y)
print(type(resultRDD))
print(resultRDD.collect())
[(‘Spark’, 2), (‘Flink’, 1), (‘hello’, 3), (‘you’, 1), (‘me’, 1), (‘she’, 1)]
6 - 将结果输出到文件系统或打印
resultRDD.saveAsTextFile(“D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\output\wordsAdd”)
7-停止SparkContext
sc.stop()#Shut down the SparkContext.
* * 总结: * 
TopK需求
需求:[(‘Spark’, 2), (‘Flink’, 1), (‘hello’, 3), (‘you’, 1), (‘me’, 1), (‘she’, 1)]
排序:[ (‘hello’, 3),(‘Spark’, 2),]
共识:Spark核心或灵魂是rdd,spark的所有操作都是基于rdd的操作
代码:
# -*- coding: utf-8 -*- # Program function: 针对于value单词统计计数的排序 # 1-思考:sparkconf和sparkcontext从哪里导保 # 2-如何理解算子?Spark中算子有2种, # 一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD), # 一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子 from pyspark import SparkConf, SparkContext if __name__ == '__main__': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FirstSpark").setMaster("local[*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") # 日志输出级别 # 2 - 从外部文件数据源读取数据 fileRDD = sc.textFile("D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\words.txt") # print(type(fileRDD))## all the data is loaded into the driver's memory. # print(fileRDD.collect()) # ['hello you Spark Flink', 'hello me hello she Spark'] # 3 - 执行flatmap执行扁平化操作 flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) # print(type(flat_mapRDD)) # print(flat_mapRDD.collect()) # ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] # # 4 - 执行map转化操作,得到(word, 1) rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) # print(type(rdd_mapRDD))# # print(rdd_mapRDD.collect()) # [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] # 5 - reduceByKey将相同Key的Value数据累加操作 resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) # print(type(resultRDD)) print(resultRDD.collect()) # [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)] # 6 针对于value单词统计计数的排序 print("==============================sortBY=============================") print(resultRDD.sortBy(lambda x: x[1], ascending=False).take(3)) # [('hello', 3), ('Spark', 2), ('Flink', 1)] print(resultRDD.sortBy(lambda x: x[1], ascending=False).top(3, lambda x: x[1])) print("==============================sortBykey=============================") print(resultRDD.map(lambda x: (x[1], x[0])).collect()) # [(2, 'Spark'), (1, 'Flink'), (3, 'hello'), (1, 'you'), (1, 'me'), (1, 'she')] print(resultRDD.map(lambda x: (x[1], x[0])).sortByKey(False).take(3)) #[(3, 'hello'), (2, 'Spark'), (1, 'Flink')] # 7-停止SparkContext sc.stop() # Shut down the SparkContext.
- sortBy
- sortByKey操作
从HDFS读取数据
-- coding: utf-8 --
Program function: 从HDFS读取文件
from pyspark import SparkConf, SparkContext
import time
if name == ‘main’:1 - 首先创建SparkContext上下文环境
conf = SparkConf().setAppName(“FromHDFS”).setMaster(“local[*]”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“WARN”) # 日志输出级别2 - 从外部文件数据源读取数据
fileRDD = sc.textFile(“hdfs://node1:9820/pydata/input/hello.txt”)
[‘hello you Spark Flink’, ‘hello me hello she Spark’]
3 - 执行flatmap执行扁平化操作
flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" "))
[‘hello’, ‘you’, ‘Spark’, ‘Flink’, ‘hello’, ‘me’, ‘hello’, ‘she’, ‘Spark’]
# 4 - 执行map转化操作,得到(word, 1)
rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1))
[(‘hello’, 1), (‘you’, 1), (‘Spark’, 1), (‘Flink’, 1), (‘hello’, 1), (‘me’, 1), (‘hello’, 1), (‘she’, 1), (‘Spark’, 1)]
5 - reduceByKey将相同Key的Value数据累加操作
resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y)
print(type(resultRDD))
print(resultRDD.collect())
休息几分钟
time.sleep(600)
7-停止SparkContext
sc.stop() # Shut down the SparkContext.
* 
提交代码到集群执行
关键:sys.argv[1],
代码:
-- coding: utf-8 --
Program function: 提交任务执行
import sys
from pyspark import SparkConf, SparkContext
if name == ‘main’:
1 - 首先创建SparkContext上下文环境
conf = SparkConf().setAppName(“FromHDFS”).setMaster(“local[*]”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“WARN”) # 日志输出级别2 - 从外部文件数据源读取数据
hdfs://node1:9820/pydata/input/hello.txt
fileRDD = sc.textFile(sys.argv[1])
[‘hello you Spark Flink’, ‘hello me hello she Spark’]
3 - 执行flatmap执行扁平化操作
flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" "))
[‘hello’, ‘you’, ‘Spark’, ‘Flink’, ‘hello’, ‘me’, ‘hello’, ‘she’, ‘Spark’]
# 4 - 执行map转化操作,得到(word, 1)
rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1))
[(‘hello’, 1), (‘you’, 1), (‘Spark’, 1), (‘Flink’, 1), (‘hello’, 1), (‘me’, 1), (‘hello’, 1), (‘she’, 1), (‘Spark’, 1)]
5 - reduceByKey将相同Key的Value数据累加操作
resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y)
print(type(resultRDD))
resultRDD.saveAsTextFile(sys.argv[2])
7-停止SparkContext
sc.stop() # Shut down the SparkContext.
* 结果: * 
[掌握-扩展阅读]远程PySpark环境配置
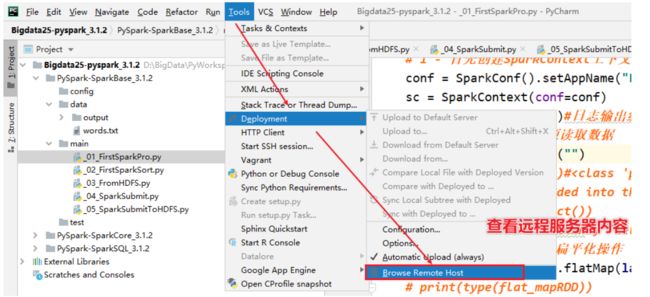
需求:需要将PyCharm连接服务器,同步本地写的代码到服务器上,使用服务器上的Python解析器执行
步骤:
1-准备PyCharm的连接
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pOPG03La-1667913989191)(https://gitee.com/hu_hao11/blogImage/raw/master/img/image-20210907181018963.png)]
2-需要了解服务器的地址,端口号,用户名,密码
设置自动的上传,如果不太好使,重启pycharm
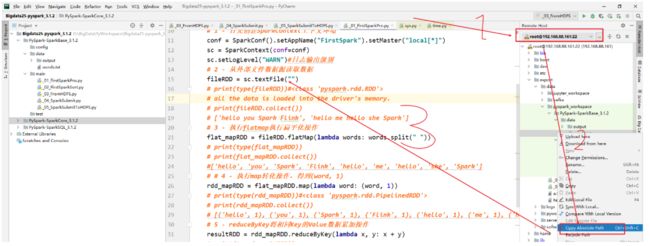
3-pycharm读取的文件都需要上传到linux中,复制相对路径
4-执行代码在远程服务器上
5-执行代码
-- coding: utf-8 --
Program function: Spark的第一个程序
1-思考:sparkconf和sparkcontext从哪里导保
2-如何理解算子?Spark中算子有2种,
一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD),
一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子
from pyspark import SparkConf, SparkContext
if name == ‘main’:
1 - 首先创建SparkContext上下文环境
conf = SparkConf().setAppName(“FirstSpark”).setMaster(“local[*]”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“WARN”) # 日志输出级别2 - 从外部文件数据源读取数据
fileRDD = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkBase_3.1.2/data/words.txt”)
fileRDD = sc.parallelize([“hello you”, “hello me”, “hello spark”])
3 - 执行flatmap执行扁平化操作
flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" "))
print(type(flat_mapRDD))
print(flat_mapRDD.collect())
[‘hello’, ‘you’, ‘Spark’, ‘Flink’, ‘hello’, ‘me’, ‘hello’, ‘she’, ‘Spark’]
# 4 - 执行map转化操作,得到(word, 1)
rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1))
print(type(rdd_mapRDD))#
print(rdd_mapRDD.collect())
[(‘hello’, 1), (‘you’, 1), (‘Spark’, 1), (‘Flink’, 1), (‘hello’, 1), (‘me’, 1), (‘hello’, 1), (‘she’, 1), (‘Spark’, 1)]
5 - reduceByKey将相同Key的Value数据累加操作
resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y)
print(type(resultRDD))
print(resultRDD.collect())
[(‘Spark’, 2), (‘Flink’, 1), (‘hello’, 3), (‘you’, 1), (‘me’, 1), (‘she’, 1)]
6 - 将结果输出到文件系统或打印
resultRDD.saveAsTextFile(“D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\output\wordsAdd”)
7-停止SparkContext
sc.stop() # Shut down the SparkContext.
* 切记忘记上传python的文件,直接执行 * 注意1:自动上传设置 * 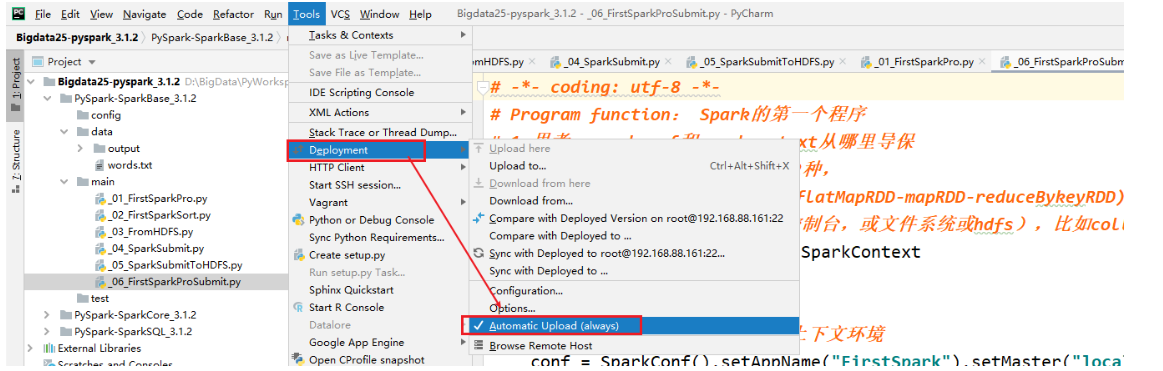 * 注意2:增加如何使用standalone和HA的方式提交代码执行 * 但是需要注意,尽可能使用hdfs的文件,不要使用单机版本的文件,因为standalone是集群模式 * ```python-- coding: utf-8 --
Program function: Spark的第一个程序
1-思考:sparkconf和sparkcontext从哪里导保
2-如何理解算子?Spark中算子有2种,
一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD),
一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子
from pyspark import SparkConf, SparkContext
if name == ‘main’:
1 - 首先创建SparkContext上下文环境
conf = SparkConf().setAppName(“FirstSpark”).setMaster(“spark://node1:7077,node2:7077”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“WARN”) # 日志输出级别2 - 从外部文件数据源读取数据
fileRDD = sc.textFile(“hdfs://node1:9820/pydata/input/hello.txt”)
fileRDD = sc.parallelize([“hello you”, “hello me”, “hello spark”])
3 - 执行flatmap执行扁平化操作
flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" "))
print(type(flat_mapRDD))
print(flat_mapRDD.collect())
[‘hello’, ‘you’, ‘Spark’, ‘Flink’, ‘hello’, ‘me’, ‘hello’, ‘she’, ‘Spark’]
# 4 - 执行map转化操作,得到(word, 1)
rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1))
print(type(rdd_mapRDD))#
print(rdd_mapRDD.collect())
[(‘hello’, 1), (‘you’, 1), (‘Spark’, 1), (‘Flink’, 1), (‘hello’, 1), (‘me’, 1), (‘hello’, 1), (‘she’, 1), (‘Spark’, 1)]
5 - reduceByKey将相同Key的Value数据累加操作
resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y)
print(type(resultRDD))
print(resultRDD.collect())
[(‘Spark’, 2), (‘Flink’, 1), (‘hello’, 3), (‘you’, 1), (‘me’, 1), (‘she’, 1)]
6 - 将结果输出到文件系统或打印
resultRDD.saveAsTextFile(“D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\output\wordsAdd”)
7-停止SparkContext
sc.stop() # Shut down the SparkContext.
*

总结
-
函数式编程
-
#Python中的函数式编程 #1-map(func, *iterables) --> map object def fun(x): return x*x #x=[1,2,3,4,5] y=map(fun,[1,2,3,4,5]) #[1, 4, 9, 16, 25] print(list(map(fun, [1, 2, 3, 4, 5]))) #2-lambda 匿名函数 java: x=>x*x 表达式 Scala:x->x*x g=lambda x:x*x print(g(10)) print(list(map(lambda x:x*x, [1, 2, 3, 4, 5]))) def add(x,y): return x+y print(list(map(add, range(5), range(5, 10)))) print(list(map(lambda x,y:x+y,range(5),range(5,10)))) #3- [add(x,y) for x,y in zip(range(5),range(5,10))] # print(list(zip([1, 2, 3], [4, 5, 6])))#[1,4],[2,5] # print(list(zip([1, 2, 3], [4, 5, 6,7])))#[1,4],[2,5] # print(list(zip([1, 2, 3,6], [4, 5, 6])))#[1,4],[2,5] # 语法 lambda表达式语言:【lambda 变量:表达式】 # 列表表达式 [表达式 for 变量 in 可迭代的序列中 if 条件] print([add(x, y) for x, y in zip(range(5), range(5))]) #[0, 2, 4, 6, 8] #3-reduce from functools import reduce # ((((1+2)+3)+4)+5) print(reduce(lambda x, y: x + y, [1, 2, 3, 4, 5])) # 4-filter seq1=['foo','x41','?1','***'] def func(x): #Return True if the string is an alpha-numeric string return x.isalnum() print(list(filter(func,seq1))) #返回 filter 对象 # sorted() # 最后我们可以看到,函数式编程有如下好处: # 1)代码更简单了。 # 2)数据集,操作,返回值都放到了一起。 # 3)你在读代码的时候,没有了循环体,于是就可以少了些临时变量,以及变量倒来倒去逻辑。 # 4)你的代码变成了在描述你要干什么,而不是怎么去干。 -
重点操作:
-
1-搭建完成Standalone的PySpark
- 为每台机器安装python3
- wordcount测试
-
2-搭建完成StandaloneHA
- 自己保存镜像
- spark-shell
- pyspark
- spark-submit
-
3-完成Python连接远程服务器
- 要求:能够使用Python提交local任务到远程集群上
-
4-有时间的化,windows上安装pyspark在连接
-
5-明天休息的时候
- 需要将wordcount代码熟练写5遍
- 熟练常用的快捷键
- 能够基于wordcount掌握topk