【NLP Tool -- NLTK】NLTK进行英文情感分析、分词、分句、词性标注(附代码)
NLP Tool 系列文章
NLP--Jieba中文文本--关键词提取、自定义词典、分词、词性标注
NLP--NLTK英文文本--情感分析、分词、分句、词性标注
工具介绍
NLTK,Natural Language Toolkit是一个Python模块,提供了多种语料库(Corpora)和词典(Lexicon)资源,比如WordNet等,以及一系列基本的自然语言处理工具集,包括:分句,标记解析(Tokenization),词干提取(Stemming),词性标注(POS Tagging)和句法分析(Syntactic Parsing)等,是对英文文本数据进行处理的常用工具。
注意:该工具主要是针对英文文本数据,那如果用中文数据会有怎样的效果呢?本文章以下内容会有具体介绍
安装库
pip install nltk
安装语料库
方式一:在控制台直接安装
import nltk
nltk.download()方式二:因为要下载的语料库太大了,所以方式一有时候不会成功,所以可以考虑手动下载
1 进入官网地址下官网地址 GitHub - nltk/nltk_data: NLTK Data

2 查看解压后的语料库可以放在本地的哪些位置,在控制台中输入以下内容
from nltk.corpus import brown
brown.categories()
假如是在选择E:\\nltk_data,那就在E盘中创建nltk_data文件,随后将下载的语料库中的packages包下的所有文件复制到nltk_data
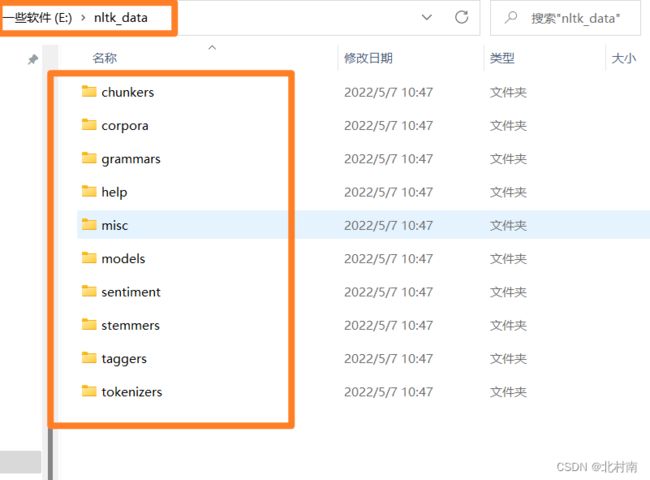
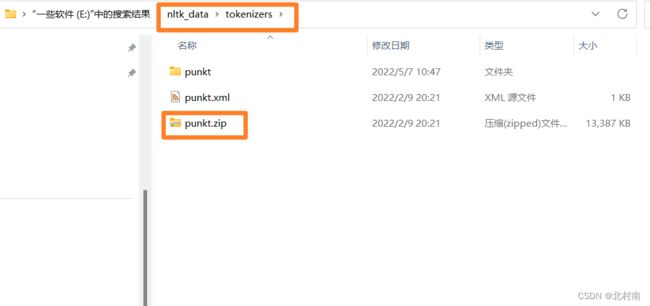
进入nltk_data/tokenizers文件夹下解压punkt.zip文件
完整代码
import nltk
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
from nltk.corpus import brown
brown.categories()
s = '近日,中国短道速滑队队员@武大靖,在直播中歪嘴喝水的画面走红,此后他本人还亲自教学。于是,短道速滑国家队的成员们相继挑战,还出了一人炫三瓶的升级版。网友:终于找到进短道速滑队的方法!'
s1 = 'Along with the development of society , more and more problems are brought to our attention , one of the most serious problems is involution and lying flat . Involution means that when social resources cannot meet the needs of everyone, people compete to obtain more resources. An important feature of involution is internal competition , Internal competition is becoming increasing prevalent at an amazing rate. '
englishTokens = word_tokenize(s1)
chineseTokens = word_tokenize(s)
# 分句和分词
print("英文分句", sent_tokenize(s1))
print("英文分词", englishTokens)
print("中文分句", sent_tokenize(s))
print("中文分词", chineseTokens)
# 词性标注
# 分词之后才可以进行词性标注
englishTags = nltk.pos_tag(englishTokens)
chineseTags = nltk.pos_tag(chineseTokens)
print("英文词性标注", englishTags)
print("中文词性标注", chineseTags)
# 情感分析
#compound表示复杂程度,neu表示中性,neg表示负面情绪,pos表示正面情绪
from nltk.sentiment.vader import SentimentIntensityAnalyzer
s2 = ['This is a good book', 'This is a bad book']
s3 = ['这是一本好书', '这是一本糟糕的书']
# 创建分类器
sid = SentimentIntensityAnalyzer()
#英文情感分析
for sentence in s2:
print(sentence)
print("情感得分", sid.polarity_scores(sentence))
#中文情感分析
for sentence in s3:
print(sentence)
print("情感得分", sid.polarity_scores(sentence))结果
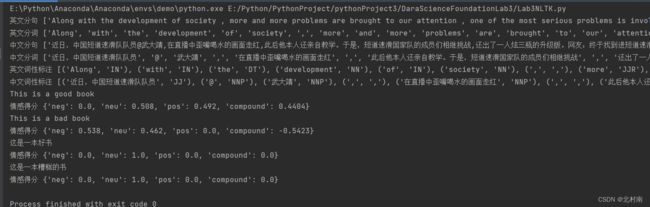
结果分析
1分词、分句、词性标注

2 情感分析
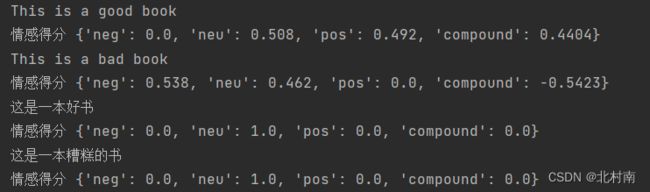
可以明显的看到在英文的实现效果是比较好的,而中文的在分词阶段的效果就比较糟糕,因此,以分词为基础的分句、词性标注、情感分析的实现效果也比较糟糕