redis笔记
背景:
nosql:not-only-sql对关系性数据库进行补充
问题:海量用户,高并发 罪魁祸首:性能瓶颈;磁盘IO性能低下(SQL),数据关系复杂
解决:降低磁盘IO次数,去除关系
特征:可扩容,可伸缩 高性能 高可用 灵活数据类型
常见NOSQL数据库:redis ,mencache,HBase,MongoDB
举例 电商:
商品基本信息:mysql
商品附件信息(如商品详细信息):MongoDB
图片:分布式文件系统
搜索关键字:ES Lucene solr
热点信息:高频,波段性 Redis mencache,tair

命令行工具
1.功能性命令
2.清除屏幕信息
3.帮助信息查阅
4.退出指令
1代表成功 0代表失败
string
mset mget 可以一次设置或获取多个
strlen key获取数据字符串个数 append key value在原始信息上面追加
但数据操作和多数据操作
多操作可减少指令传输时间
拓展操作
1数据分表:incr,decr,incrby ,decrby,incrbyfloat
案例:场景,投票,每个微信号没4小时只能投一票
设置数据指定声明周期
setex key seconds value
psetex key milliseconds value
注意事项:数字计算有范围
案例:显示粉丝数与微博数量
set user3506728370:fans 32425235
或json字符串
redis应用于各种结构和非结构型高热度数据访问加速
hash
一个Key对应一堆数据
存储结构优化
field数量少的时候,存储结构优化为类数组结构,
field比较多的时候,存储结构使用HashMapj结构
多个hmset hmget
hlen key field field的数量
hexits key field field是否存在
hkey key获取哈希表中所有字段或字段值
hvals key
设置指定字段的数值数据增加指定范围
hincrby key field increment
注意:value值只能存字符串
不可滥用
数值类型范围2^32-1
hgetall 可获得全部属性,但是当field过多时,遍历整体数据效率会变低
应用:场景电商网站购物车
用户ID为Key,商品为field 数量为value每位顾客一个Hash
每条购物车中的商品记录保存成俩条field 格式为商品id:nums 商品ID:info
信息重复:独立列出来,将商品信息独立为一个Hash
hsetnx key field values 当前key有值,什么都不做,没值,添加
场景:买手机卡三种手机卡,30,50,100,每种限购1000张
应用:商家ID为key ,商品ID为field ,数量为value
list
需求:存储多个数据,并对数据进入存储空间的顺序进行区分双向链表
双向链表:有去有回
因为是双向链表,可以从左边进,也可以从右边进
lpush key value
rpush key vlaue
lrange key start stop
lindex key index
llen key
获取并移除数据
lpop key
list阻塞数据获取
规定时间内获取并移除数据
blpop key1 timeout
当在规定时间内,有数据就取,没有时间就等,直到有数据,或者时间超时
业务场景:朋友圈点赞,按照点赞顺序实显示点赞好友,或者取消点赞
解决:lrem key count value 删除指定数据
注意事项:
1数据都是string 总量有限
2 具有索引概念 不是栈就是队列
3 可以对数据进行分页操作,通常第一页信息来自List
set
存储大量数据,查询方面提供更高的效率
基于hash,只不过value没有用罢了
命令:
添加:sadd key member1 …
获取:smembers key
删除:
scard key:获取数据总量
slsmember key member:判断集合是否有该数据
拓展操作:
场景:头条分类,设置爱好内容 随机推荐信息检索
srandmember key count 随机获取集合中指定的数量的数据
spop key 随机获取集合中的某个数据并将改数据移出集合
场景:脉脉 微信好友 求两个集合的交,并,差集
sinter key1 key2
sunion key1 key2
sdiff key1 key2
两个集合的交,并,差存储到指定集合中
sinterstore destination key1 key2
sunionstore destination key1 key2
sdiffstore destination key1 key2
将指定数据从原始集合中移动到目标集合中
smove source destination member
注意事项:
1 不重复
2虽然是hash 结构,但是无法启用Hash存储结构
应用场景:角色权限操作
应用场景:新网站推广 统计网站的访问量 独立访客 独立IP
应用场景:黑白名单
黑名单过滤名单,进行控制
sortedset
展示的时候排序
在set的基础上添加了可排序字段,后面又加一列,
zadd key score1 member1 score2 member2
zrange key start stop
zrevrange key start stop
srem key member
排序字段在前 值在后
zrangebyscore key min max withscore limit
zrevrangebyscore key max min
条件删除数据
zremrangeby rangk key start stop
zremrangebyscore key min max
zcard key
zcount key min max
zinterstore destination numkeys key
zunionstore destination numkeys key
拓展操作
排序:榜单
zrank key member
zrevrank key member
score值的获取和修改
zscore key member
zincrby key increment member
注意事项:
score是个数字,有范围
可以保存一个双精度的数字,可能会丢失精度,使用时要慎重
sorted_set 基于set,不可重复,score覆盖效果
业务场景:会员管理限时操作
数据类型实践:
场景:对试用用户试用行为进行限速,每个用户每分钟最多发起10次调用
解决:uid:00415 判断是否为空和超限
达到上限:setex 414 60 9223372036854775797 (…80为上限,到达上限抛出异常),只要抛出异常
redis应用于限时按次结算的服务控制
场景:微信消息按照什么样的顺序展示
解决:set置顶,分两个list,普通list,和置顶list
通用命令
key特征:
一.对于key自身状态的相关操作:删除,判定存在,获取类
del key
exists key
type key
二.对于可以有效性控制的相关操作,如有效期设定,判断是够有效,有效状态;的切换
expire key seconds
pexpire key milliseconds
expireat key timestamp
pexpireat key milliseconds-timestamp
获取有效期时间
ttl key
pttl key
parsist key 切换key从时效性转换为永久性
三.对于key 快速查询操作,如置顶测略查询key
查询key
keys */?/[] 任意、一个、
为key改名
rename key newkey
renamenx key newkey 有就失败,没有就成功
对key排序
sort只是排序,不对立面的内容进行操作
数据库通用指令:
redis为每个数据库服务提供16个数据库,每个数据库之间相互独立
select index 切换数据库
quit
ping 测试服务器是否连接
echo message
move key db 数据库移动
dbsize 数据库中|key总数
flushdb 清除操作
flushall 清除操作
jedis:
三步:连接redis 操作redis 关闭redis
以下全是在linux下操作
Redis:多态启用,换端口
redis-server --port 6380
redis-cli -p 6380
redis-cli -h IP地址
redis-server 配置文件(不加的话,用默认配置文件)
起多个Redis服务,就建立多个配置文件
在客户端通过命令shutdown save/nosave来关闭服务端
持久化
将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据 RDB
将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在于数据的操作过程 AOF
RDB
指令save 手动执行一次保存操作
save指令相关配置
1 dbfilename dump.rdb
2 dir 设置存储.rdb文件的路径
3 rdbcompressin yes 设置存储到本地数据库时是否压缩数据
通常为开启,设置为no,可节省cpu运行时间,但会使存储文件变大
4 rdbchecksum yes
设置是否进行RDB文件格式校验,该校验过程在写文件和读文件过程中均进行
redis事务
操作:
开启事务 multi
执行事务:exec 设定事务的结束位置,同时与执行事务
事务取消:discard
事务工作流程
注意事项:
1.如果命令中有语法错误,那么所有的指令将都不执行
2.语法正确,但是不能执行(比如,对一个string进行lpush操作),那么正确的命令将会执行,错误的命令不会执行
3,已经执行完的命令,运行出错不会回滚,必须要让程序员手动实现。
锁
场景:商品热卖,补货操作
解决:启动客户端进行监控,数据变化不操作,没变操作
对key添加监视锁,在执行exec前,如果key发生变化,终止事务执行
watch key1 key2…:设定对某个key的监视,在执行前如果key 发生变化,终止事务执行
unwatch:取消所有key的监视
分布式锁:
一个商品被同时买
解决:
setnx lock-key value 设置一个公共锁,有值则返回失败,无值则返回设置成功
对于设置成功,拥有控制权,进行下一步的具体业务处理,
对于设置失败,不具有控制权,排队或者等待。
操作完毕,通过del操作释放锁
业务场景:依赖分布式锁,某个用户操作时对应的客户端宕机,且此时已经获取到锁。
解决:
expire lock-key second
expire lock-key millisecond 对锁添加时间限定
删除策略
时效性数据的存储结构
定时删除
定时删除:当key设置有过期时间,且到达过期时间,由定时器任务立即执行对键的删除操作
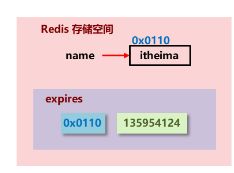
优点:节约内存,快速释放掉不必要的内存占用
缺点:不考虑cpu压力问题
惰性删除
数据到达过期时间,不做处理,等下次访问该数据时
未过期:返回数据值
已过期:删除,返回不存在
优点:节约cpu性能。缺点:存储空间占用量比较大
定期删除
server.hz,设置每秒执行次数,轮训每个数据库,随机挑选一些key进行检查
如删除个数超过一定个数,则在执行一次
如不超过一定个数,则去操作下一个数据库。
逐出算法
问题:当前新数据进入redis时,如果内存不足怎么办?
解决:在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足,
内存不够:Redis要临时删除一些数据为当前指令清理存储空间
相关配置:
maxmemory:最大可使用内存
maxmemory-samples:每此选取待删除数据的个数
maxmemory-policy:删除策略
检测易失数据:
1.volatile-lru:挑选最近最少使用的数据淘汰(least recently used)
2.lfu:使用次数最少的数据(least frequently used)
3.ttl:挑选将要过期的数据
4.random:任意选择数据淘汰
检测全库数据
allkeys-lru
allkeys-lfu
allkeys-random
放弃数据驱逐 no-enviction
redis配置
daemonize yes/no 设置服务器以守护进程的方式运行
bind ip:绑定主机地址
port 6379 设置端口号
databases 16 这是数据库数量
loglevel debug/verbose/notice/warning
logfile 端口号.log
maxclients :最大客户端连接数
timeout 300客户端闲置超时时长
include /path/server-端口号.conf:导入并加载指定配置文化信息
高级数据类型
Bitmaps
场景:拿时间换空间
getbit key offset:获取指定key对应偏移量的bit值
setbit key offset value:设置指定key对应偏移量上的bit值,value只能是0或者1
hyperloglog
基数统计,去重
添加数据:pfadd key element …
统计数据: pfoount key
合并数据: pfmerge destkey sourcekey …
注意:只是数据,只记录数据不是存储的数据,只是一个估算算法,存储空间比较小
GEO
添加坐标点: geoadd key longitude latitude member(将一些坐标放在一个集合中)
获取坐标点:geopos key member…
计算坐标点距离:geodist key member …
根据坐标求范围内数据:georadius key longitude latitude redius 单位
根据点求范围内数据:georadiusbymember key member radius 单位
获取指定点对应的坐标hash值:geohash key member …
Redis集群
3.0之后支持集群,至少需要三个节点