强化学习和知识图谱实体对齐
《Deep Reinforcement Learning for Entity Alignment》精读
在本文中,作者将实体对齐建模为一个顺序决策任务,其中agent(智能体)根据实体的表征向量顺序地决定两个实体是匹配还是不匹配。所提出的端到端的基于强化学习(Reinforcement Learning, RL)的实体对齐(end-to-end RL-based entity alignment, RLEA)框架可以灵活地适应大多数给予嵌入的实体对齐方法。
文章链接
1 强化学习的组成
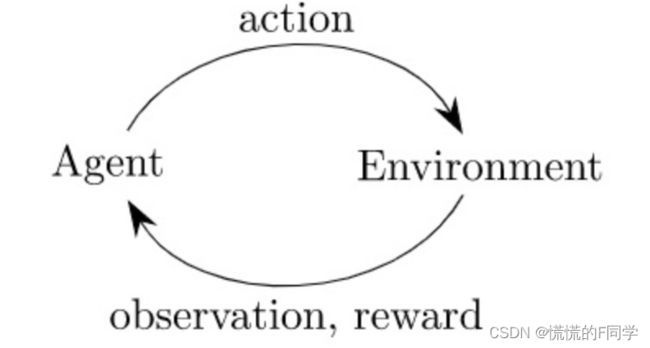
在强化学习里有两大基本组成模块:Environment和Agent。Environment指外部环境,如果在游戏中就是游戏环境。Agent指智能体,如果在游戏中就是玩家,在本文中就是作者写的算法。
其中Environment具备State(状态)和Reward(回馈)属性, Agent具备Action(行动)的能力。整个训练过程大致是:Agent通过一套策略(Policy)输出一个action作用到Environment, Environment则反馈State和Reward到Agent,同时Environment会转移到下一个State。如此不断循环,直至Agent最终找到一个最优策略,使得可以尽可能多的获得来自Environment的Reward。整个过程可参见链接:强化学习训练流程
2 实体对齐任务
实体对齐任务旨在寻找两个知识图谱之间指向真实世界同一现实对象的实体对,以便将不同知识图谱链接起来(可以链接分布式知识)以更好支持下游应用程序。作者并不直接使用实体嵌入的相似度作为两个实体是否对齐的判断依据,而是把嵌入作为输入,训练一个策略网络(Policy Network)使其能够寻找到尽可能多的对齐实体对,以实现最大回馈(Reward)。
3 方法
3.1 Preliminaries
定义源知识图谱和目标知识图谱分别为:![]()
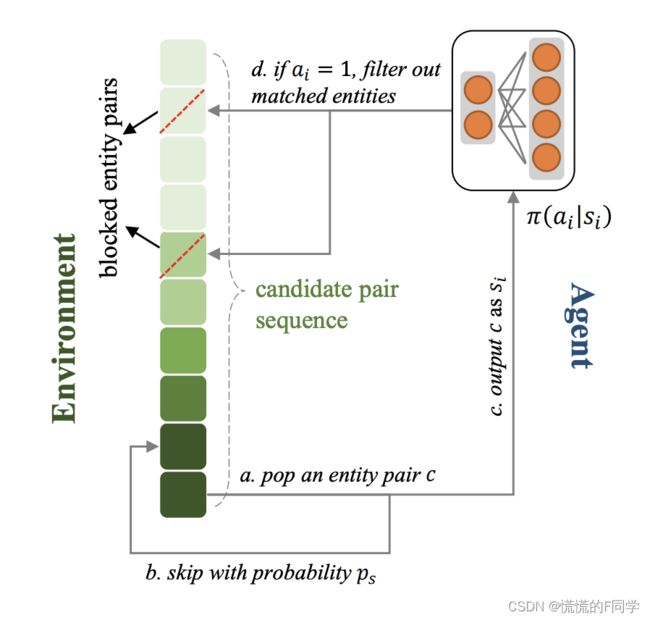
所提出的RLEA框架包括两个module: environment和agent。基于嵌入实体对齐模型的输出作为agent的输入,训练集是一组已知的实体对齐对。在每一个训练episode中,states和actions由environment和agent以交替顺序生成。定义state s为由environment所给予的任意实体对![]() ,其中
,其中![]()
分别来源于各自的知识图谱,就是说environment的初始state是分别来自两个知识图谱的实体组成的实体。action ![]() 代表着agent的decision,判断实体对是匹配还是不匹配。每一个state(实体对)本身还有一个label
代表着agent的decision,判断实体对是匹配还是不匹配。每一个state(实体对)本身还有一个label ![]() ,代表着正确的决策(即真值)。当action的值不等于实体对的label值时,这个action的值仍然可能具有积极的影响,比如说一个不正确的match动作也能排除掉2个错误的实体。
,代表着正确的决策(即真值)。当action的值不等于实体对的label值时,这个action的值仍然可能具有积极的影响,比如说一个不正确的match动作也能排除掉2个错误的实体。
![]() : true mismatch,
: true mismatch, ![]() : false match
: false match
![]() : false match,
: false match, ![]() : true match
: true match
3.2 Agent
State: 初始state ![]() 是由environment提供的。作者考虑以下特征:(1)两个实体
是由environment提供的。作者考虑以下特征:(1)两个实体![]() 的 嵌入;(2)两个实体
的 嵌入;(2)两个实体![]() 的邻居嵌入;(3)实体
的邻居嵌入;(3)实体![]() 的对手实体嵌入集
的对手实体嵌入集![]() 。实体
。实体![]() 的k近邻候选对齐实体,当然排除
的k近邻候选对齐实体,当然排除![]() ,被称为
,被称为![]() 的对手实体。这些对手实体能提供附加信息,用来接受或拒绝输入的实体对。
的对手实体。这些对手实体能提供附加信息,用来接受或拒绝输入的实体对。
Action: 一个action a 被二进制成0或1. 这种二进制机制的好处是:(1)相应的最优Policy能被近似成一个简单的函数;(2)二进制机制使得agent能暂停当前的候选对。举个例子,如果agent选择了mismatch, 源知识图谱中的source entity在下一个交互中仍然有正确匹配的机会。但是在分类任务中,agent必须选择出来一个entity作为最终的选择。
Policy Network: 对于Policy Network的输入,除了输入实体和候选实体,作者还选择了额外k个与输入实体接近的实体(即![]() 的Opponent entities)作为context信息(可以用来拒绝当前匹配)。对于每个实体,作者使用图神经网络(Graph Neural Networks, GNN)模型同时编码其和其邻居向量以得到中间表征
的Opponent entities)作为context信息(可以用来拒绝当前匹配)。对于每个实体,作者使用图神经网络(Graph Neural Networks, GNN)模型同时编码其和其邻居向量以得到中间表征 ![]() ,再馈送到输出层。在输出层,除了线性层用来组合
,再馈送到输出层。在输出层,除了线性层用来组合 ![]() 以外,还考虑了实体对间的互信息
以外,还考虑了实体对间的互信息 ![]() 。最后综合两个评估器得到最终的action分布函数:
。最后综合两个评估器得到最终的action分布函数:
![]()
,即通过计算action的数值来判断两个源自不同知识图谱的实体是匹配或不匹配。

Reward: 定义environment的reward为r:  。agent的最终目标是最大化全局的Reward。(正确的对齐实体对的数量应该等于true match的数量。)
。agent的最终目标是最大化全局的Reward。(正确的对齐实体对的数量应该等于true match的数量。)
Optimization: 使用策略梯度算法:REINFORCE,去训练策略网络的参数集合,以产生较大的Overall Reward。
3.3 Environment
Dependency: Agent的输出action可能会改变Environment后面的state。对于顺序实体对齐,一个true match不仅会产生正确的实体对齐对,还会排除一些可能的候选者,从而提高Environment的overall Reward。即使是一个false match也有过滤掉两个错误实体的价值。因此应该考虑长期依赖。
设定Environment维护了一个实体对序列 ![]() :其中
:其中![]() 来自源知识图谱,
来自源知识图谱,
![]() 来自目标知识图谱。在训练的第i步,如果Environment抛出了一个候选实体对
来自目标知识图谱。在训练的第i步,如果Environment抛出了一个候选实体对![]() 作为
作为![]() ,并且它从Agent接受到的action为
,并且它从Agent接受到的action为![]() ,那么所有包括或的候选实体对都会从sequence中去除。
,那么所有包括或的候选实体对都会从sequence中去除。
Dynamics: Environment通常是动态的。State-Action序列在不同的情节中是不同的。 动态Environment使Agent能够捕获到游戏的一般规则,这对于避免过度拟合至关重要。为了保证动态特性,作者设置了一个跳跃概率ps 。Environment以概率ps随机跳过一个候选实体对,然后pop出下一个实体对。因此,Environment中候选实体对的长度和元素在每个episode中都会发生变化。
Difficulty: 通常,随着级别的增加,游戏的难度会逐渐提高。 例如,视频游戏中敌人的生命值和速度通常会随着游戏时间的增加而增加。对于实体对齐case,Environment中一个候选实体对的难度可以基于两个实体之间的嵌入表征余弦相似度和它们的label进行评估:
![]()
Environment可以按照难度升序顺序对候选实体对进行排序,这样Agent就能从相对容易的State开始。但是这种操作不适合实体对label信息未知的测试集,因此作者提出了课程学习策略。即不直接按照难度分数对候选实体对进行排序,而是先根据实体对间的嵌入余弦相似度对它们进行排序,并通过归一化难度分数对每个实体对的skip 概率ps重新加权。因此,在每一个episode,Agent都会从相似度高的候选实体对开始,困难度越高的实体对会以更大的概率被跳过不再馈送到策略网络做匹配判断。随着策略被优化,应该逐步降低ps以使训练环境接近测试环境。即是最终测试阶段的实体对序列应该具有与测试阶段的实体对类似的排列。
课程学习策略(Curriculum Learning) :通过一系列难度递增的学习片段来从易到难的分解复杂知识。本文中作者采用Curriculum Learning策略,在强化学习训练过程中逐步增加难度,避免因任务复杂性而导致学习失败。
策略网络与环境的互动: 在Environment中维护了一个实体对序列(排序方法为实体对间的嵌入表征相似度,以保证在测试阶段该序列仍然可用)。如前文所述,嵌入表征相似度高的实体对未必真正匹配,因此在训练过程中首先通过对比一个实体对的实际label与相似度信息来判断一个实体对匹配的难易程度。并且根据当前的训练轮数,一些匹配难度较高的实体对将有更大的概率直接不被训练。在一个Episode中,Environment所给出的实体对将被策略网络一一判断,一旦一个实体对被认为匹配,Environment中所有设计这些实体的实体对就会被Environment排除,这一过程一直持续,指到实体对序列终止或所有实体均被匹配。
4 实验
4.1 数据集
策略网络的输入,即实体嵌入表征的数据集可以从OpenEA project获得。OpenEA又包括四个子数据集: EN-FR, EN-DE,D-W和D-Y。其中前两个是跨语言数据集,EN、FR、DE 分别表示 DBpedia 的英语、法语和德语版本。后两个是跨源数据集, D、W、Y 分别表示 DBpedia、WikiData 和 Yago。作者使用的是与原始KG具有相似分布的“V1”数据集。OpenEA的source code见链接。
4.2 baselines
作者选定JAPE, SEA, RSN, RDGCN作为baselines。为了方便比较,作者还设计了一个名为Seq的序列策略,并按照BootEA中使用的算法来实现它, 不涉及强化学习。Seq将相似度高于预定义阈值的实体对视为匹配,或根据余弦相似度随机选择actions。
4.3 主要结果
作者设计的RLEA算法在OpenEA全部四种数据集上的performance均相较原有方法有明显提升。

表中的Orig代表目前采用的贪心策略,Hits@1是知识图谱常用指标,该指标越大越好。
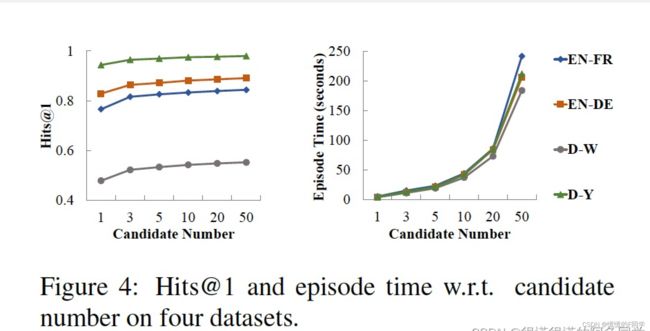
4.4 候选实体对number对performance的影响
出于性能和效率的考虑,作者决定在实际实现中使用前10个候选实体对。
4.5 互信息估计器(MIE)的有效性
MIE提供的估计有助于Agent快速找到最佳Policy,这在应用于更大的数据集时至关重要。
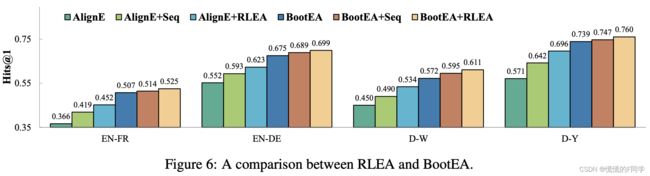
4.6 RLEA和BootEA的对比
BootEA迭代地将可能的实体对齐标记为训练数据。与RLEA一样,BootEA认为候选实体不应对齐两次。AlignE是BootE的一种变体,没有bootstrapping过程。虽然BootEA在提高AlignE的性能方面有更好的效果,但是Seq和RLEA仅使用经过训练的嵌入作为输入,不修改嵌入或训练过程。 因此,它们更具可扩展性并适用于任意 EEA 方法。
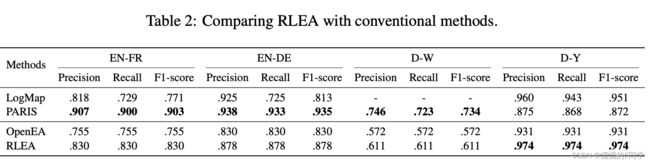
4.7 RLEA和传统方法的对比
作者还和传统实体对齐方法进行了对比。在此之前,尽管基于知识图谱嵌入的方法具有许多优点,但在绝对性能上与基于字符匹配等技术的传统方法有着较大差距。作者所提出的基于强化学习的方法不但缩小了这一差距,并且在一些数据集上(如D-Y)显著优于传统方法。
5 RLEA代码
参见链接, 建议python版本不低于3.7,graph-tool使用最新版(安装见官网链接)。
参考
(1)https://hub.baai.ac.cn/view/15419
(2)https://zhuanlan.zhihu.com/p/150336780
(3)https://blog.csdn.net/weixin_39910711/article/details/124428444