【动手学数据分析】 Task05 - 模型建立和评估
建模和评估的基本流程:
读入数据集
特征工程
分割训练集和测试集
创建模型
输出模型预测结果
模型评估
零、特征工程
导入数据:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from IPython.display import Image
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小
# 读取训练数集
train = pd.read_csv('train.csv')

在读入数据集后,需要对数据的处理进行某些操作以方便后续的模型建立及训练。
1. 填充缺失值:.fillna()
- 连续变量:平均数、中位数、众数
- 分类变量:NA、最多的类别
# 检查缺失值比例
train.isnull().sum().sort_values(ascending=False)
Embarked 0
Cabin 0
Fare 0
Ticket 0
Parch 0
SibSp 0
Age 0
Sex 0
Name 0
Pclass 0
Survived 0
PassengerId 0
dtype: int64
2. 对分类变量编码:pandas.get_dummies()
例如只有两种可能的类别
# 取出所有的输入特征
data = train[['Pclass','Sex','Age','SibSp','Parch','Fare', 'Embarked']]
# 进行虚拟变量转换
data = pd.get_dummies(data)

一、建立模型
处理数据后就需要建立模型了,在建模之前需选择合适的模型。
- 先确定数据集的种类:监督学习,无监督学习
- 选择依据:任务、数据样本量、特征的稀疏性
- 步骤:先尝试使用一个基本的模型作为其baseline,之后再用其他模型做对比,最后选择泛化能力或性能较好的模型。
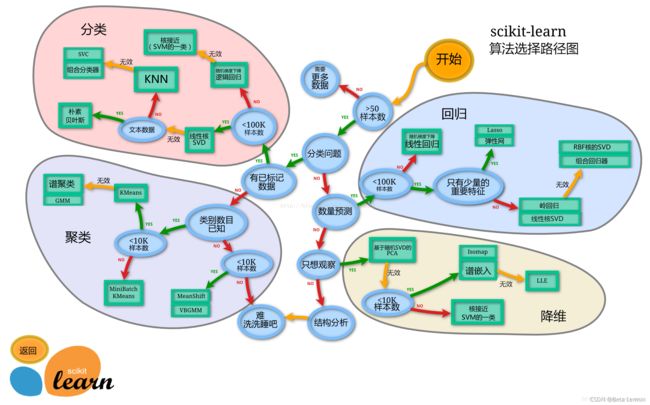
1.1 切割训练集和测试集
- 目的:便于后续评估模型的泛化能力
- 切割方法:
- 按比例切割:一般有30%、25%、15%和10%
- 按目标变量分层等比切割
- 设置随机种子复现结果
- sklearn中切割数据的方法:
train_test_split()
切割数据集的时候不用进行随机选取的情况:数据集本身已经经过随机处理或样本量足够大。
from sklearn.model_selection import train_test_split
# 一般先取出X和y后再切割,当使用到未切割的时候就可以用X和y
X = data
y = train['Survived']
# 对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 查看训练集测试集大小
X_train.shape, X_test.shape
# ((668, 10), (223, 10))
1.2 模型创建
模型类别
- 基于线性模型(
sklearn.linear_model)的分类模型:逻辑回归(逻辑回归是分类模型,线性回归才是回归模型) - 基于树(
sklearn.ensemble)的分类模型:决策树、随机森林(随机森林是决策树集为了降低决策树过拟合的情况)
证明为什么可以使用线性回归来做二元分类问题:《机器学习笔记-利用线性模型进行分类》
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# 默认参数逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)
# 查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))
# 调整参数后的逻辑回归模型
lr2 = LogisticRegression(C=100)
lr2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(lr2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))
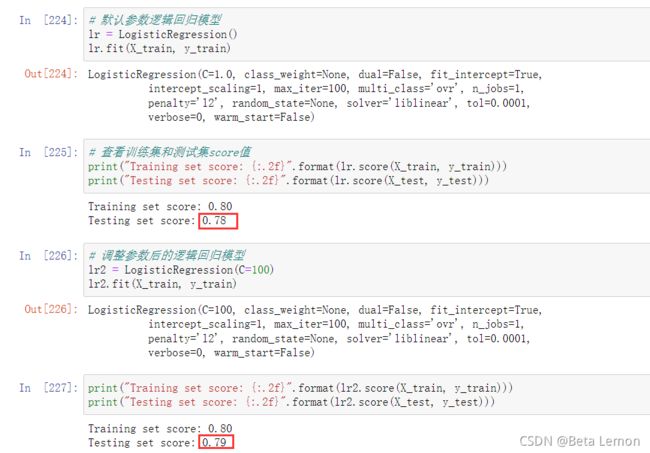
测试集上的分数在调参之后提升了。
# 默认参数的随机森林分类模型
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc.score(X_test, y_test)))
# 调整参数后的随机森林分类模型
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc2.score(X_test, y_test)))

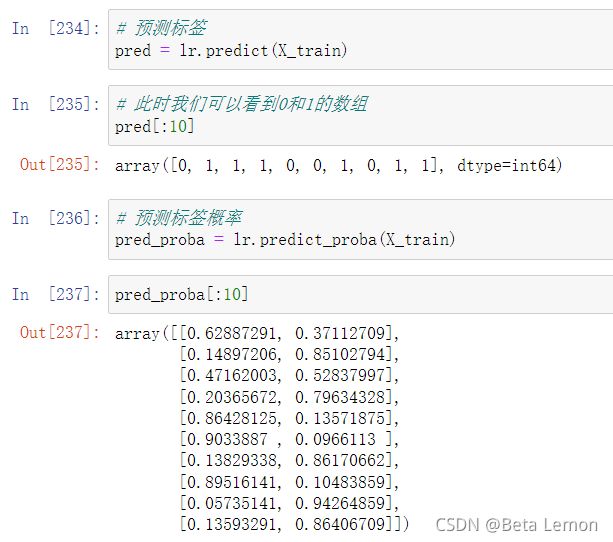
1.3 输出模型预测结果
一般监督模型在sklearn里面,predict输出预测标签,predict_proba输出标签概率
# 预测标签
pred = lr.predict(X_train)
# 预测标签概率
pred_proba = lr.predict_proba(X_train)
二、模型评估
- 目的:获得模型的泛化能力
- 方法:交叉验证(cross-validation)
- 数据被多次划分,并且需要训练多个模型
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 参考 李宏毅《机器学习》Task03 - 误差和梯度下降 中误差的第3节
- 准确率(precision)度量被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量正类样本中有多少被预测为正类(TP)
- f-分数是准确率与召回率的调和平均
2.1 交叉验证
sklearn中的模块:
sklearn.model_selection

from sklearn.model_selection import cross_val_score
# 用10折交叉验证来评估逻辑回归模型
lr = LogisticRegression(C=100)
scores = cross_val_score(lr, X_train, y_train, cv=10)
# k折交叉验证分数
scores
# 平均交叉验证分数
print("Average cross-validation score: {:.2f}".format(scores.mean()))
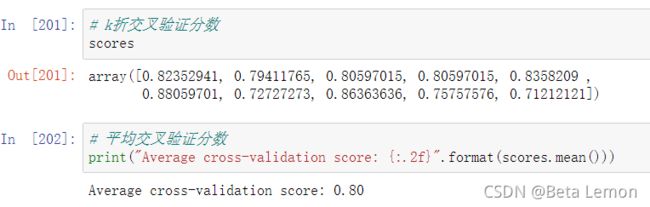
K折越多,消耗时间增加,但是平均误差被视为泛化误差,结果更可靠。
2.2 混淆矩阵
对于二分类问题常用的评价指标是精确率(precision)和召回率(recall),评价分类器的指标一般是分类准确率(accuracy)

分类器在测试数据集上的预测或正确或不正确,其有四种情况:

- sklearn中的模块:
sklearn.metrics - 混淆矩阵需要输入真实标签和预测标签
from sklearn.metrics import confusion_matrix
# 训练模型
lr = LogisticRegression(C=100)
lr.fit(X_train, y_train)

# 模型预测结果
pred = lr.predict(X_train)
# 混淆矩阵
confusion_matrix(y_train, pred)
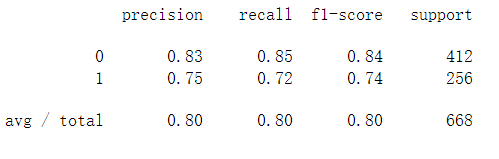
from sklearn.metrics import classification_report
# 精确率、召回率以及f1-score
print(classification_report(y_train, pred))
2.3 ROC曲线
- ROC曲线在sklearn中的模块为
sklearn.metrics - ROC曲线下面所包围的面积越大越好
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
