动手学数据分析-Task05:数据建模及模型评估
本学习笔记为Datewhale-7月组队学习-动手学数据分析的学习内容,学习链接为:https://github.com/datawhalechina/hands-on-data-analysis
数据建模及模型评估
- 前言
- 一、学习知识点概要
- 二、学习内容
-
- (一)数据建模
-
- 1. 使用Sklearn完成模型的搭建
-
- (1)Sklearn简介
- (2)Sklearn的算法选择路径
- 2. 数据集划分
- 3. 模型创建
- 4. 输出模型预测结果
- (二)模型评估
-
- 1. 交叉验证
- 2. 混淆矩阵
- 3. ROC曲线
- 三、学习问题与解答
- 四、学习思考与总结
- 五、参考文章
前言
在前一篇博文【动手学数据分析-Task04:数据可视化】里,我们一起学习了数据可视化,数据可视化可以让我们更加直观得观察数据的构成,方便我们从数据中获取更多的信息,为选取优化方向提供思路。做数据分析的目的,是结合业务运用数据来得到需求结果。那么分析的第一步就是建模,搭建一个预测模型或者其他模型;从这个模型得到结果后,要分析模型是不是足够的可靠,就需要评估模型。那么,在这篇博文中我们将会一起学习数据建模和模型评估,这也是本期《动手学数据分析》系列学习的最后一篇博文。
一、学习知识点概要
Task05:数据建模及模型评估
知识点: Sklearn简介、数据集划分、模型创建、交叉验证、混淆矩阵和ROC曲线等
二、学习内容
导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
使图床能显示
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小
载入我们提供清洗之后的数据(clear_data.csv),大家也将原始数据载入(train.csv),说说他们有什么不同
读取原数据数集
train = pd.read_csv('train.csv')
train.shape
![]()
train.head()

读取清洗过的数据集
data = pd.read_csv('clear_data.csv')
data.shape
![]()
data.head()

(一)数据建模
- 处理完前面的数据我们就得到建模数据,下一步是选择合适模型
- 在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习
- 模型的选择一方面是通过我们的任务来决定的。
- 除了根据我们任务来选择模型外,还可以根据数据样本量以及特征的稀疏性来决定
- 刚开始我们总是先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型
1. 使用Sklearn完成模型的搭建
(1)Sklearn简介
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。Sklearn具有以下特点:
-
简单高效的数据挖掘和数据分析工具
-
让每个人能够在复杂环境中重复使用
-
建立NumPy、Scipy、MatPlotLib之上
(2)Sklearn的算法选择路径
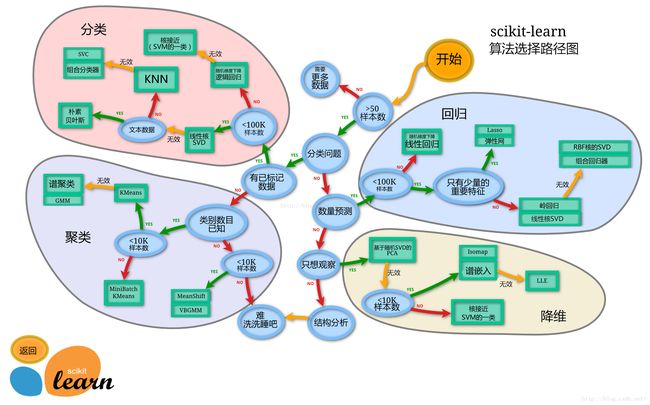
- 结构:
由图中,可以看到库的算法主要有四类:分类,回归,聚类,降维。其中:
常用的回归: 线性、决策树、SVM、KNN ;
集成回归: 随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类: 线性、决策树、SVM、KNN,朴素贝叶斯;
集成分类: 随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类: k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维: LinearDiscriminantAnalysis、PCA
- 图片中隐含的操作流程:
这个流程图代表:蓝色圆圈内是判断条件,绿色方框内是可以选择的算法。你可以根据自己的数据特征和任务目标去找到一条自己的操作路线,一步步做就好了。
2. 数据集划分
这里使用留出法划分数据集
- 将数据集分为自变量和因变量
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
提示
- 切割数据集是为了后续能评估模型泛化能力
- sklearn中切割数据集的方法为
train_test_split - 查看函数文档可以在jupyter noteboo里面使用
train_test_split?后回车即可看到 - 分层和随机种子在参数里寻找
from sklearn.model_selection import train_test_split
一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据’Survived’
X = data
y = train['Survived']
对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
查看数据形状
X_train.shape, X_test.shape
思考: 划分数据集的方法有哪些?
回答: 常用划分数据集方法:
| 方法 | 介绍 | 缺点 |
|---|---|---|
| 留出法 | 直接将数据集划分为两个互斥的集合, 分别作为训练集和测试集, 其中训练集一般是2/3 ~ 4/5 | 样本的不同划分方式会导致模型评估的相应结果也会有差别 |
| 交叉验证法 | 将数据集划D分为k个大小相似的互斥子集, 每个子集尽量保证数据分布的一致性(用分层采样);每次用k-1个子集的并集作为训练集, 余下的那一个作为测试集,从而进行k次训练和测试,最终返回的是k个测试结果的均值。 | 训练成本较大 |
| 留一法(交叉验证法特例) | 假设数据集D包含m个样本,令k=m,显然留一法不再受随机样本划分方式的影响,因为留一法的训练数据集只比D少一个样本,训练出的模型与用D训练出的模型很相似,且评估结果也是测试了数据集D中所有的样本取得平均值,因此留一法的评估结果往往比较准确。 | 计算量太大 |
| 自助法 | 我们每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为 m 次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。 | 自助法改变了初始数据的分布,会引入估计偏差 |
思考: 为什么使用分层抽样,这样的好处有什么?
解答: 因为划分的时候要尽可能保证数据分布的一致性,即避免因数据划分过程引入额外的偏差而对最终结果产生影响,所以通常我们采用 分层采样 的方式来对数据进行采样。
思考: 什么情况下切割数据集的时候不用进行随机选取
回答: 可以不用随机选取的情况是数据集本身就足够随机,这种情况一般是随机处理后的。或者使用交叉验证法中的留一法处理数据。
3. 模型创建
- 创建基于线性模型的分类模型(逻辑回归)
- 创建基于树的分类模型(决策树、随机森林)
- 分别使用这些模型进行训练,分别的到训练集和测试集的得分
- 查看模型的参数,并更改参数值,观察模型变化
提示
- 逻辑回归不是回归模型而是分类模型,不要与
LinearRegression混淆 - 随机森林其实是决策树集成为了降低决策树过拟合的情况
- 线性模型所在的模块为
sklearn.linear_model - 树模型所在的模块为
sklearn.ensemble
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
默认参数逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)

查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))

调整参数后的逻辑回归模型
lr2 = LogisticRegression(C=100)
lr2.fit(X_train, y_train)

查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))

默认参数的随机森林分类模型
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)

查看训练集和测试集score值
print("Training set score: {:.2f}".format(rfc.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc.score(X_test, y_test)))
![]()
调整参数后的随机森林分类模型
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)

查看训练集和测试集score值
print("Training set score: {:.2f}".format(rfc2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc2.score(X_test, y_test)))

思考: 为什么线性模型可以进行分类任务,背后是怎么的数学关系
回答: f(x)=wTx+b;如果函数值小于0,我们就预测类别-1,如果函数值大于0,我们就预测类别+1。对于所有用于分类的线性模型,这个预测规则都是通用的。对于用于分类的线性模型,决策边界是输入的线性函数。换句话说,(二元)线性分类器是利用直线、平面或超平面来分开两个类别的分类器。
思考: 对于多分类问题,线性模型是怎么进行分类的
回答: 多分类的问题常常是使用差分策略,通过二分类学习来解决多分类问题,即将多分类问题拆解为多个二分类训练二分类学习器最后通过继承得到结果,最经典拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM)。
4. 输出模型预测结果
- 输出模型预测分类标签
- 输出不同分类标签的预测概率
提示
- 一般监督模型在sklearn里面有个
predict能输出预测标签,predict_proba则可以输出标签概率
预测标签
pred = lr.predict(X_train)
此时我们可以看到0和1的数组
pred[:10]
![]()
预测标签概率
pred_proba = lr.predict_proba(X_train)
pred_proba[:10]

思考: 预测标签的概率对我们有什么帮助
回答: 告诉我们可以多大程度上信任预测结果,来决定如何采取下一步行动。
(二)模型评估
- 模型评估是为了知道模型的泛化能力。
- 交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
- 在交叉验证中,数据被多次划分,并且需要训练多个模型。
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量的是正类样本中有多少被预测为正类
- f-分数是准确率与召回率的调和平均
1. 交叉验证

- 用10折交叉验证来评估逻辑回归模型
- 计算交叉验证精度的平均值
- 交叉验证在sklearn中的模块为
sklearn.model_selection
from sklearn.model_selection import cross_val_score
lr = LogisticRegression(C=100)
scores = cross_val_score(lr, X_train, y_train, cv=10)
k折交叉验证分数
scores
![]() 平均交叉验证分数
平均交叉验证分数
print("Average cross-validation score: {:.2f}".format(scores.mean()))
![]()
思考: k折越多的情况下会带来什么样的影响?
回答: 一般而言,k折越多,评估结果的稳定性和保真性越高,不过整个计算复杂度越高。一种特殊的情况是k=m,m为数据集样本个数,这种特例称为留一法,结果往往比较准确。
2. 混淆矩阵
- 计算二分类问题的混淆矩阵

- 计算精确率、召回率以及f-分数

提示 - 混淆矩阵的方法在sklearn中的
sklearn.metrics模块 - 混淆矩阵需要输入真实标签和预测标签
from sklearn.metrics import confusion_matrix
训练模型
lr = LogisticRegression(C=100)
lr.fit(X_train, y_train)

模型预测结果
pred = lr.predict(X_train)
混淆矩阵
confusion_matrix(y_train, pred)

from sklearn.metrics import classification_report
精确率、召回率以及f1-score
print(classification_report(y_train, pred))

思考: 如果自己实现混淆矩阵的时候该注意什么问题
回答: 一定要弄清楚定义,具体定义参考下面链接。https://blog.csdn.net/u011587322/article/details/80660978
3. ROC曲线
- 绘制ROC曲线
提示
- ROC曲线在sklearn中的模块为
sklearn.metrics - ROC曲线下面所包围的面积越大越好
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)

三、学习问题与解答
问题一: 划分数据集的方法有哪些?
解答:
常用划分数据集方法:
| 方法 | 介绍 | 缺点 |
|---|---|---|
| 留出法 | 直接将数据集划分为两个互斥的集合, 分别作为训练集和测试集, 其中训练集一般是2/3 ~ 4/5 | 样本的不同划分方式会导致模型评估的相应结果也会有差别 |
| 交叉验证法 | 将数据集划D分为k个大小相似的互斥子集, 每个子集尽量保证数据分布的一致性(用分层采样);每次用k-1个子集的并集作为训练集, 余下的那一个作为测试集,从而进行k次训练和测试,最终返回的是k个测试结果的均值。 | 训练成本较大 |
| 留一法(交叉验证法特例) | 假设数据集D包含m个样本,令k=m,显然留一法不再受随机样本划分方式的影响,因为留一法的训练数据集只比D少一个样本,训练出的模型与用D训练出的模型很相似,且评估结果也是测试了数据集D中所有的样本取得平均值,因此留一法的评估结果往往比较准确。 | 计算量太大 |
| 自助法 | 我们每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为 m 次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。 | 自助法改变了初始数据的分布,会引入估计偏差 |
问题二: 为什么使用分层抽样,这样的好处有什么?
解答: 因为划分的时候要尽可能保证数据分布的一致性,即避免因数据划分过程引入额外的偏差而对最终结果产生影响,所以通常我们采用 分层采样 的方式来对数据进行采样。
问题三: 什么情况下切割数据集的时候不用进行随机选取
解答: 可以不用随机选取的情况是数据集本身就足够随机,这种情况一般是随机处理后的。或者使用交叉验证法中的留一法处理数据。
问题四: 为什么线性模型可以进行分类任务,背后是怎么的数学关系
解答: f(x)=wTx+b;如果函数值小于0,我们就预测类别-1,如果函数值大于0,我们就预测类别+1。对于所有用于分类的线性模型,这个预测规则都是通用的。对于用于分类的线性模型,决策边界是输入的线性函数。换句话说,(二元)线性分类器是利用直线、平面或超平面来分开两个类别的分类器。
问题五: 对于多分类问题,线性模型是怎么进行分类的
解答: 多分类的问题常常是使用差分策略,通过二分类学习来解决多分类问题,即将多分类问题拆解为多个二分类训练二分类学习器最后通过继承得到结果,最经典拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM)。
问题六: 预测标签的概率对我们有什么帮助
解答: 告诉我们可以多大程度上信任预测结果,来决定如何采取下一步行动。
问题七: k折越多的情况下会带来什么样的影响?
解答: 一般而言,k折越多,评估结果的稳定性和保真性越高,不过整个计算复杂度越高。一种特殊的情况是k=m,m为数据集样本个数,这种特例称为留一法,结果往往比较准确。
问题八: 如果自己实现混淆矩阵的时候该注意什么问题
解答: 一定要弄清楚定义,具体定义参考下面链接。https://blog.csdn.net/u011587322/article/details/80660978
问题九: 对于多分类问题如何绘制ROC曲线
解答: 经典的ROC曲线适用于对二分类问题进行模型评估,通常将它推广到多分类问题的方式有两种:
-
对于每种类别,分别计算其将所有样本点的预测概率作为阈值所得到的T P R 和F P R值(是这种类别为正,其他类别为负),最后将每个取定的阈值下,对应所有类别的T P R 值和F P R值分别求平均,得到最终对应这个阈值的T P R 和F P R 值
-
首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为’macro’和’micro’的情况。
详细参考链接:https://blog.csdn.net/qq_30992103/article/details/99730059
四、学习思考与总结
本次学习,学会了如何进行数据建模及模型评估,包括Sklearn简介、数据集划分、模型创建、交叉验证、混淆矩阵和ROC曲线等内容。
做数据分析的目的,是结合业务运用数据来得到需求结果。那么分析的第一步就是建模,搭建一个预测模型或者其他模型;从这个模型得到结果后,要分析模型是不是足够的可靠,就需要评估模型。
在学习过程中遇到了许多参考答案上没有给出的疑惑,通过自己的查找和理解在上面第三部分学习问题与解答给出了参考。
经过本期《动手学数据分析》系列教程的学习,初步了解并实践了基本的数据分析过程,对以后的学习奠定了良好的基础。
希望大家可以互相交流、共同学习,如果发现博文中有错的或不解的,欢迎留言或私聊交流~
————————————————
五、参考文章
[1]https://github.com/datawhalechina/hands-on-data-analysis
[2]https://blog.csdn.net/XiaoYi_Eric/article/details/79952325
[3]https://blog.csdn.net/weixin_57878519/article/details/118158381
[4]https://blog.csdn.net/u014248127/article/details/78885180
[5]https://blog.csdn.net/qq_30992103/article/details/99730059