动手学数据分析 | Datawhale-8月 | Task05:数据建模及模型评估
文章目录
- Task05:数据建模及模型评估
- 一、数据预处理
-
- 1.导包
- 2.缺失值填充和one-hot编码
- 二、模型搭建
-
- 1.选择模型
- 2.切割训练集和测试集
- 3.模型创建
- 4.优化
- 总结
Task05:数据建模及模型评估
我们根据任务需求不同,要考虑建立什么模型,我们使用流行的sklearn库,建立模型。对于一个模型的好坏,我们是需要评估的,之后我们会评估我们的模型,对模型做优化。
一、数据预处理
我们拥有的泰坦尼克号的数据集,那么我们这次的目的就是,完成泰坦尼克号存活预测这个任务。1.导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
# 设置行不限制数量
pd.set_option('display.max_rows',None)
# 设置列不限制数量
pd.set_option('display.max_columns',None)
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小
2.缺失值填充和one-hot编码
- 对分类变量缺失值(Embarked,Cabin):填充某个缺失值字符(NA)、用最多类别的进行填充
- 对连续变量缺失值(Age):填充均值、中位数、众数
- 编码分类变量
train['Embarked'].groupby(train['Embarked']).count()

# 对分类变量缺失值:Cabin最多的类别是NA,Embarked最多的类别是S
train.Cabin = train['Cabin'].fillna('NA')
train.Embarked = train['Embarked'].fillna('S')
#连续变量缺失值:Age(使用均值填充)
train.Age = train['Age'].fillna(train['Age'].mean())
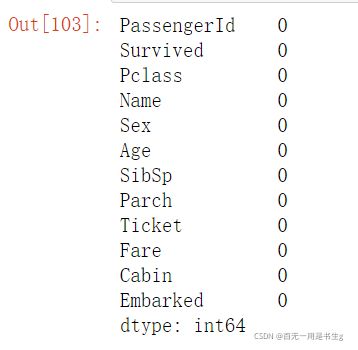
# 检查缺失值比例
train.isnull().sum()
#对分类型变量:Sex,Fare
# 取出所有的输入特征
data = train[['Pclass','Sex','Age','SibSp','Parch','Fare', 'Embarked']]
data.head()

data = pd.get_dummies(data)
data.head()

#保存文件
data.to_csv('clear_data_alone.csv')
二、模型搭建
1.选择模型
- 处理完前面的数据我们就得到建模数据,下一步是选择合适模型
- 在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习
- 模型的选择一方面是通过我们的任务来决定的。
- 除了根据我们任务来选择模型外,还可以根据数据样本量以及特征的稀疏性来决定

2.切割训练集和测试集
- 将数据集分为自变量和因变量
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
from sklearn import tree
from sklearn.model_selection import train_test_split
import pandas as pd
train = pd.read_csv('train.csv')
data = pd.read_csv('clear_data_alone.csv')
target = train['Survived']
target

#切割数据集(分层抽样)
# 数据分布不均衡的时候不使用随机抽取
# stratify = none时为随机抽取
Xtrain,Xtest,Ytrain,Ytest = train_test_split(data,target,stratify = target,random_state=1)
3.模型创建
这里选择决策树分类树模型进行举例
#建模三部曲
#实例化
clf = tree.DecisionTreeClassifier(criterion='entropy',
random_state=2,
max_depth=4,
splitter='random'
)
#训练模型
clf = clf.fit(Xtrain,Ytrain)
#导入测试集
score = clf.score(Xtest,Ytest) #预测准确率accuracy
score
![]()
#预测分类结果/标签
pred = clf.predict(Xtest)
pred

#预测标签概率
proba = clf.predict_proba(Xtest)
proba[:10]

4.优化
#画学习曲线
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1,
random_state=2,
criterion='entropy',
splitter='random'
)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
test.append(score)
print(max(test))
plt.plot(range(1,11),test,color = 'red',label = 'max_depth')
plt.xticks(range(1,11))
plt.legend()
plt.show()

#网格搜索
import numpy as np
from sklearn.model_selection import GridSearchCV
gini_thresholds = np.linspace(0,0.5,10)
#一串参数和这些参数对应的我们希望网格搜索的取值范围
parameters = {'criterion':('gini','entropy'),
'splitter':('random','best'),
'max_depth':[*range(1,10)],
'min_samples_leaf':[*range(1,50,5)],
'min_impurity_decrease':[*np.linspace(0,0.5,10)]
}
clf = tree.DecisionTreeClassifier(random_state=2)
GS = GridSearchCV(clf,parameters,cv = 10)
GS = GS.fit(Xtrain,Ytrain)
#返回最佳组合
In []:GS.best_params_
Out[]:
{'criterion': 'gini',
'max_depth': 9,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 6,
'splitter': 'best'}
#返回网格搜索后的模型评判标准
In []:GS.best_score_
Out[]:
0.8159430122116689
总结
此处只举例了决策树的简单建模,更多模型效果还待实验。
动手学数据分析 | Datawhale-8月。
结束。
感谢。