Spanner 浅析
1. 介绍
spanner是一个可以在全球的数据中心之间同步复制的多版本分布式数据库,第一个可以在全球范围内提供外部一致性(对于应用程序来说是一致的)的数据库。意味着它有一个全局的时间,这个全局的时钟是通过GPS和原子钟来实现的。系统提供了一个TrueTime API,这个API的实现对实现整个系统至关重要,可以说,这个API是系统最重要的部分。提供和megastore一样的类SQL查询语言和半关系模型,和megastore类似,支持三种事务:读写事务,只读事务,snapshot read事务。Bigtable不支持跨行事务,megastore提供数据中心之间的同步复制,不能扩展到全球,并且延时高,spanner支持跨行跨表事务,并且能扩展到全球的数据中心。
2. 部署和实现
2.1 部署和架构
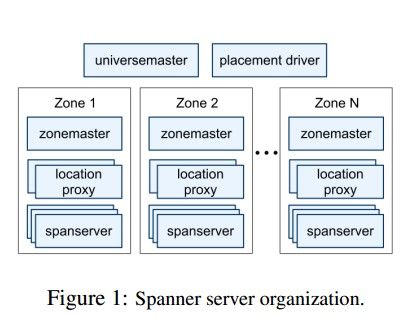
一个spanner部署实例叫做一个universe,google部署3个部署实例,一个用于生产环境,一个用于开发环境,一个用于测试环境。universe内划分为多个zones,当加入或者关闭一个数据中心的时候,相当于加入多个zones或者删除这个数据中心所对应的zones。zone也是物理隔离的级别单位,如果两个应用的数据需要分开,就分别存储在不同的zones上。每个zone由一个zonemaster,成百上前个spanserver和一个location proxy组成。zonemaster用于路由数据给spanserver,location proxy被客户端用来定位数据所在的spanserver。spanserver用来管理数据,可以管理成百个tablet,底层的实际的存储是GFS的改进版Colossus。另外,每个universe里面还有universemaster和placement driver两个单例组件,前者是用来显示整个universe的信息的,后者负责对directory在zones之间的数据迁移。它会周期性的和spanservers进行通讯以发现需要移动的directory,然后进行迁移。
2.2 数据模型
层次关系:database-table-row-column。数据模型和megastore一样是半关系模型,其本质上还是一个KV,因为数据库中的每行需要有一个rowkey,rowkey由多列组成,每行其实是一个KV,key是rowkey,value是非rowkey列。另外,和megastore的query语言类似,有主从表的概念,用户可以通过一些ad-hoc语法定义相关的一组数据,以支持locality。
2.3 TrueTime API
这个API是spanner最核心的东西,没有它,就没有这篇文章,后续的并发控制,事务的支持都是围绕它来展开。API提供三个函数,其中最重要的是TT.now(),这个函数会返回一个时间区间[earliest,latest],API保证调用TT.now()的这个时刻一定在返回的区间之间。区间的长度目前是ms级别,以后希望做到2ms以内。TrueTime API的实现是通过在服务器上部署GPS和原子钟来实现的,用到一些算法。
2.4 如何保证强一致性,并发控制,事务实现
强一致性通过paxos一致性协议实现,为了降低在广域网上的延迟,将paxos改进为pipeline的写的方式,类似于GFS对多个Chunk的写。对每个tablet的写的同步都是通过paxos一致性协议。一个tablet的所有的replicas的集合叫做一个paxos group。每个paxos group中会选举出一个replica作为leader,提供写服务,或者有必要的时候参与实现分布式事务的2PC。每个paxos group leader上有lock table模块和transaction manager模块,前者用于提供对本tablet访问的并发控制,后者参与两阶段提交(2PC)。
spanner提供三种事务:
1. 读写事务
如果一个读写事务中的写跨越多个tablet,即跨越多个paxos group,那么利用paxos group中的leader上的transaction manager来进行2PC。当客户端完成了所有的读操作并且buffer好了所有的写操作后,就开始2PC:
1.1 客户端从所有的这些paxos group的leader中去选择其中一个leader作为coordinator leader,然后将所有的写操作,coordinator leader的id,commit message发给所有的这些leader(包括coordinator leader,将其他的leader记为participant leader以示区分)。
1.2 每个participant leader首先通过lock table 加写锁,然后选择一个prepare timestamp,通过paxos log一条prepare 记录,然后告诉coordinator leader它的prepare timestamp。
1.3 coordinator leader收到participant leader的时间戳后,然后为整个读写事务选择一个commit 时间戳,这个时间戳要比它收到的所有的prepare timestamp都要大或者等于,并且要大于TT.now().latest(TT.now()是coordinator leader从client那里接收到commit message的时刻调用),coordinator leader然后会通过paxos协议写一条commit record,然后它会强同步到这个coordinator leader所在的paxos group下的其它的replica。接着coordinator leader再等一段时间,等TT.now().latest 这个时间点过去,最多等待interval(TT.now()返回的interval)的时间,然后coordinator leader将这个commit时间戳发给客户端和所有的participant leader,然后每个participant leader 应用同一个时间戳在数据上,最后释放lock table中的锁。可以看到,整个加锁过程是通过两阶段锁(2PL)的方式
2. 只读事务
spanner负责给事务提供一个时间戳,然后根据这个时间戳进行读操作。这个时间戳如何选择?
2.1 当读事务只涉及到一个paxos group的时候,由这个paxos group的leader给这个只读事务分配时间戳,当这个paxos group上目前没有 prepared transaction的时候,只需将这个paxos group上最后一次commit timestamp赋值给这个只读事务即可。
2.2 当读事务涉及到多个paxos group的时候,可以每个paxos group都问一遍,选一个最小的commit time作为其读时间戳。spanner采取一种更为简单的方式,将TT.now().latest赋值给只读事务。然后读取足够新的replica。replica是否足够新是相对于读事务的读时间戳而言的,每个replica维护一个时间戳safetime,它是一下两个时间戳的最小值:本replica所在的paxos group的leader的 transaction manager的safetime和本replica最后一次apply的时间戳。前者比所有的prepared timestamp都要小(prepared transaction就是已经写过prepared record的transaction,在写这个prepared record(通过paxos协议)之前,通过lock table加了写锁)。所以,如果给一个只读事务赋予的时间戳大于这些prepared 时间戳的任何一个的时候,就会block 住,所以为了实现lock-free 事务,系统给读事务的时间戳必须要比所有的这些prepared timestamp小。由于同步复制需要时间,有些replica还较老,所以replica的safetime也需要小于后者。
3. snapshot-read with timestamp 事务
用户提供时间戳。
3. 感想
spanner的核心就是TrueTime API,所有的东西都是围绕它来的,关于对事务的时间戳的选择上相当的精细,工程难度很高,另外,google自己也对paxos做了一系列的改进以减少在广域网上的延迟,从megastore论文上也可以看到。另外,就是分布式事务使用2PC来实现,由应用来解决性能问题。总体来说,上层的多数据中心同步对我们来说没有什么意思,下面的单个spanserver的设计还是有些借鉴作用。