《机器学习》 小白Python学习笔记(十三) ———— 集成学习 课后题8.3&8.5 Python实现
《机器学习》 小白Python学习笔记(十三) ———— 集成学习 课后题8.3&8.5 Python实现
8.3从网上下载或自己编程实现AdaBoost,以不剪枝决策树为基学习器,在西瓜数据集3.0a上训练一个AdaBoost集成,并与图8.4进行比较。
8.5试编程实现Bagging,以决策树桩为基学习器,在西瓜数据集3.0a上训练一个Bagging集成,并与图8.6进行比较。
自己手动编写的代码还没有写好(后补),先利用scikit-learn库对西瓜数据集3.0a进行bagging和boosting集成学习,并对结果进行可视化与课本上的结果进行对比。
代码:
# 西瓜数据集a
xigua = np.array([
[0.697, 0.460, 1],
[0.774, 0.376, 1],
[0.634, 0.264, 1],
[0.608, 0.318, 1],
[0.556, 0.215, 1],
[0.403, 0.237, 1],
[0.481, 0.149, 1],
[0.437, 0.211, 1],
[0.666, 0.091, 0],
[0.243, 0.267, 0],
[0.245, 0.057, 0],
[0.343, 0.099, 0],
[0.639, 0.161, 0],
[0.657, 0.198, 0],
[0.360, 0.370, 0],
[0.593, 0.042, 0],
[0.719, 0.103, 0]])
# 将属性与标签分离
x, y = xigua[:,[0,1]], xigua[:,-1]
bagging学习器:
# Bagging集成,分别设置使用3,5,11个基学习器
bagging_clf1 = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=3)
bagging_clf2 = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=5)
bagging_clf3 = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=11)
clfs = [bagging_clf1, bagging_clf2,bagging_clf3]
Adaboost:
# 使用Adaboost算法,分别设置使用3,5,11个基学习器
boosting_clf1 = BaggingClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=3)
boosting_clf2 = BaggingClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=5)
boosting_clf3 = BaggingClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=11)
clfs = [boosting_clf1, boosting_clf2, boosting_clf3]
进行学习:
for clf in clfs:
clf.fit(x ,y)
结果可视化:
# 结果可视化
# 设置x、y轴最大最小值
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xset, yset = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
label_set = []
for clf in clfs:
out_label = clf.predict(np.c_[xset.ravel(), yset.ravel()])
out_label = out_label.reshape(xset.shape)
label_set.append(out_label)
fig,axes = plt.subplots(nrows=1,ncols=3,figsize=(12, 4))
(ax0,ax1,ax2) = axes.flatten()
for k,ax in enumerate((ax0,ax1,ax2)):
ax.contourf(xset,yset,label_set[k],cmap=plt.cm.Set1)
for i, n, c in zip([0,1], ['bad','good'], ['green','white']):
idx = np.where(y == i)
ax.scatter(x[idx, 0], x[idx, 1], c=c, label=n)
ax.set_xlim(0, 1)
ax.set_ylim(0, 0.6)
ax.legend(loc='upper left')
ax.set_ylabel('sugar')
ax.set_xlabel('densty')
ax.set_title('decision boundary for %s' % (k+1))
plt.show()
我们可以得到结果:
Adaboost结果图:
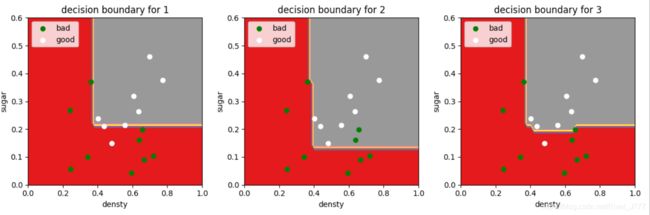
bagging结果图:

以及课本图8.4&8.6:

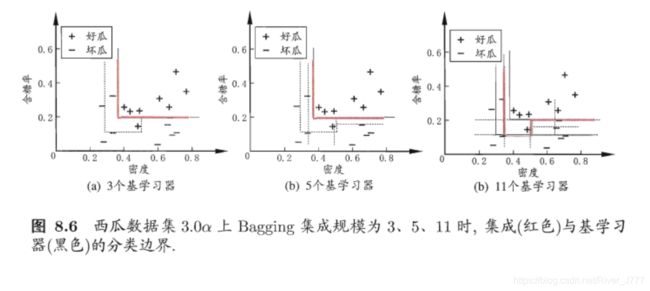
经过比较,与课本得出的结果基本相同。