Traditional Multiple Objects Tracking (updating)
目录
1. 卡尔曼滤波的详细推导(KF、EKF、UKF)
1. 1 概率论基础
1. 2 状态、观测、控制 、马尔卡夫链
1.3 贝叶斯滤波:
1.4 线性高斯系统的贝叶斯滤波
2. 常用数据关联方法(二分图(或者叫二部图)最大匹配算法之匈牙利算法、概率密度PDA)
2.1 匈牙利算法
2.2 概率数据关联算法
3. 交互多模型(IMM)
4. 多目标跟踪(MOT)
1. 卡尔曼滤波的详细推导(KF、EKF、UKF)
1. 1 概率论基础
随机变量:随机变量是指变量的值无法预先确定仅以一定的可能性(概率)取值的量;
概率表示 :
![]()
随机变量所有取值的概率之和为1:
![]() ,
, ![]()
一维高斯分布:
![]()
多维高斯分布:
![]()
联合分布:
![]() , 如果X,Y 相互独立,则有
, 如果X,Y 相互独立,则有![]()
条件概率:
![]()
![]()
全概率公式:
![]()
![]()
贝叶斯公式:
举个栗子: 我的朋友小鹿说,他的女神每次看到他的时候都冲他笑,他现在想知道女神是不是喜欢他呢?首先,我分析了给定的已知信息和未知信息:
1)要求解的问题:女神喜欢你,记为A事件
2)已知条件:女神经常冲你笑,记为B事件
所以,P(A|B)表示女神经常冲你笑这个事件(B)发生后,女神喜欢你(A)的概率。

先验概率: 也就是在不知道B事件的前提下,我们对A事件概率的一个主观判断;
可能性函数: ![]() 这是一个调整因子,也就是新信息B带来的调整,作用是将先验概率(之前的主观判断)调整到更接近真实概率(这部分暂不解释,下文解释)
这是一个调整因子,也就是新信息B带来的调整,作用是将先验概率(之前的主观判断)调整到更接近真实概率(这部分暂不解释,下文解释)
后验概率:![]() , 即在B事件发生之后,我们对A事件概率的重新评估.
, 即在B事件发生之后,我们对A事件概率的重新评估.
通过上面的实例,在这引出经典的贝叶斯公式:
![]() 公式 1
公式 1
![]() 公式2
公式2
"Sensor Generative Model or Emit Probability" : 
由于  不依赖于
不依赖于 ,通常其倒数用归一化参数
,通常其倒数用归一化参数 表示;
表示;
![]()
继续上面那个例子: 先给定一些参数,假女神喜欢小鹿初始先验概率![]() , 并且女神喜欢在喜欢一个人的情况下对那人笑的概率为
, 并且女神喜欢在喜欢一个人的情况下对那人笑的概率为 ![]() ,不喜欢一个人对那个人笑的概率为
,不喜欢一个人对那个人笑的概率为![]()
第一周: 小鹿和女神刚认识,且在这周内女神对小鹿笑了,求女神喜欢小鹿的概率, p(A|B)
![]() ,
,
这一步中:
![]()
第二周: 小鹿和女神已经认识一周了,且确定女神对小鹿有些好感,此时的先验概率为 ![]() ,在第二周里,女神又对小鹿笑了 ,求第二周结束后,求女神喜欢小鹿的概率, p(A|B)
,在第二周里,女神又对小鹿笑了 ,求第二周结束后,求女神喜欢小鹿的概率, p(A|B)
![]()
这一步中: ![]()
第三周: 小鹿和女神已经认识两周了,且确定女神对小鹿好感有明显提升,此时的先验概率为 ![]() ,在第三周里,女神又对小鹿笑了 ,求第三周结束后,求女神喜欢小鹿的概率, p(A|B)
,在第三周里,女神又对小鹿笑了 ,求第三周结束后,求女神喜欢小鹿的概率, p(A|B)
![]()
这一步中: ![]()
第四周:都94%的概率可以判定女神喜欢小鹿了,男生应该主动点,赶紧表白吧:
贝叶斯公式进阶 (留给你们自己推导吧):
![]() 公式3
公式3
期望:
![]() ,
, ![]()
![]()
方差:
![]()
1. 2 状态、观测、控制 、马尔卡夫链
状态: 表征智能体与环境相对关系或者本身一些属性的量,机器人和自动驾驶车辆中常见的状态
有以下几种: pose 、 velocity 等;
传感器观测: 智能体通过传感器直接获取的和环境交互的状态;
瞬时观测数据通常用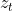 表示,一系列的观测用
表示,一系列的观测用 ![]()
控制: 智能体作出的某种动作或者给予智能体的某种激励;
瞬时控制量通常用 表示,控制序列用
表示,控制序列用![]()
状态估计的基本问题:

马尔科夫链
马尔科夫假设:
1. 当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态, ![]()
2. 当前时刻观测值只和当前时刻状态有关,![]()
基本问题1 : 根据之前的观测、控制序列预测当前时刻的状态:
![]()
基本问题2: 获得当前时刻的传感器观测量后,重新评定当前状态,估计得到最优状态;
![]()
1.3 贝叶斯滤波:
贝叶斯滤波的核心问题: 确定上一时刻最优状态估计、当前时刻观测值和当前时刻所需要估计的最优状态的联系,即确定 ![]() 、
、 ![]() 、观测三者的联系。
、观测三者的联系。
![]() 根据公式3 可以转换成:
根据公式3 可以转换成:
![]()
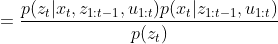
![]()
根据马尔科夫第二个假设:
![]()
![]()
因此有了: ![]() ,到这里就有些疑问了,
,到这里就有些疑问了,![]() 和
和![]() 有什么关
有什么关
系呢?根据全概率公式和公式3 ,可以得到如下形式:
![]()
![]()
![]()
![]()
贝叶斯滤波核心理念如下:
loop :
![]() 公式4 (预测)
公式4 (预测)
![]() 公式5 (测量更新)
公式5 (测量更新)
到这里是不是得再举个栗子?
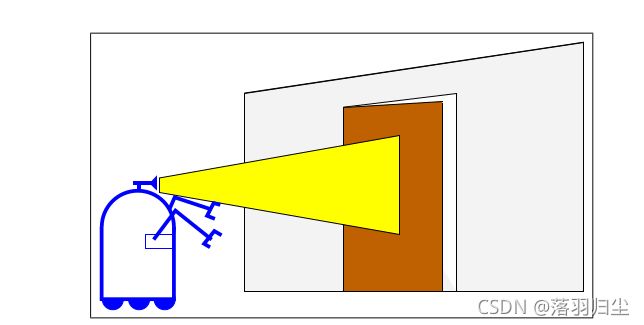
example : 让一个小机器人通过摄像头来判断一扇门是不是开着的
初始状态:![]() ,
, 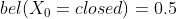
观测模型假设是带噪声的:
![]()
![]()
![]()
![]()
控制量的取值空间为 {![]() }
}
带控制量的状态转移方式如下:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
loop index1: 假设在 时刻, 机器人对门没有做任何动作,即
时刻, 机器人对门没有做任何动作,即![]()
预测:
![]()
![]()
![]()
![]()
![]()
更新: 观测结果为门是开着的
![]()
![]()
![]()
![]()
根据概率总和为1,得出![]() ,
,![]()
loop index2: 假设下一时刻, 机器人对门做push动作,即![]() ,
,![]() ,
,
![]()
预测 :
![]()
![]()
更新: 观测结果为门是开着的
![]()
![]()
1.4 线性高斯系统的贝叶斯滤波
复盘一下,多维高斯分布的表示形式为:
![]() ,
,
简易表示为:![]()
线性高斯系统: 需满足如下两个条件
条件1: 状态转移矩阵可表示成如下形式的系统,即当前时刻的状态量和上一时刻的状态量满足如下关系:
![]() 公式6 (状态转移方程)
公式6 (状态转移方程)
![]() 为系统矩阵,
为系统矩阵,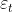 为均值为0,方差为
为均值为0,方差为 的高斯随机变量,通常情况下,
的高斯随机变量,通常情况下,![]() 的维度大于1,将公式6写成概率的形式为
的维度大于1,将公式6写成概率的形式为![]() :
:
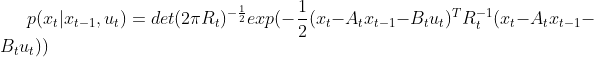
条件2:当前时刻观测值和状态量需满足如下形式
![]() 公式7 (观测方程)
公式7 (观测方程)
 为观测矩阵,
为观测矩阵,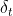 为均值为0,方差为
为均值为0,方差为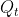 的高斯随机变量,将公式7写成概率的形式为
的高斯随机变量,将公式7写成概率的形式为![]() :
:
![]()
线性高斯系统的贝叶斯滤波:卡尔曼滤波
结合贝叶斯滤波的核心部分:预测(公式4)、更新(公式5),
线性高斯系统的预测为:
![]()

........ (推导步骤太长,偷个懒,此处省略800字)
最后求得的结果为:
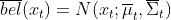
![]()
![]()
线性高斯系统的测量更新为:
![]()
![]()
最后求得的结果为:
![]()
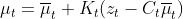
![]()
![]() (卡尔曼增益)
(卡尔曼增益)
综上卡尔曼滤波流程为:
step1: ![]()
step2: ![]()
step3: ![]()
step4:
step5: ![]()
代码示例:
* @class KalmanFilter
*
* @brief Implements a discrete-time Kalman filter.
*
* @param XN dimension of state
* @param ZN dimension of observations
* @param UN dimension of controls
*/
template
class KalmanFilter {
public:
/**
* @brief Constructor which defers initialization until the initial state
* distribution parameters are set (with SetStateEstimate),
* typically on the first observation
*/
KalmanFilter() {
F_.setIdentity();
Q_.setZero();
H_.setIdentity();
R_.setZero();
B_.setZero();
x_.setZero();
P_.setZero();
y_.setZero();
S_.setZero();
K_.setZero();
}
/**
* @brief Sets the initial state belief distribution.
*
* @param x Mean of the state belief distribution
* @param P Covariance of the state belief distribution
*/
void SetStateEstimate(const Eigen::Matrix &x,
const Eigen::Matrix &P) {
x_ = x;
P_ = P;
is_initialized_ = true;
}
/**
* @brief Constructor which fully initializes the Kalman filter
* @param x Mean of the state belief distribution
* @param P Covariance of the state belief distribution
*/
KalmanFilter(const Eigen::Matrix &x,
const Eigen::Matrix &P)
: KalmanFilter() {
SetStateEstimate(x, P);
}
/**
* @brief Destructor
*/
virtual ~KalmanFilter() {}
/**
* @brief Changes the system transition function under zero control.
*
* @param F New transition matrix
*/
void SetTransitionMatrix(const Eigen::Matrix &F) { F_ = F; }
/**
* @brief Changes the covariance matrix of the transition noise.
*
* @param Q New covariance matrix
*/
void SetTransitionNoise(const Eigen::Matrix &Q) { Q_ = Q; }
/**
* @brief Changes the observation matrix, which maps states to observations.
*
* @param H New observation matrix
*/
void SetObservationMatrix(const Eigen::Matrix &H) { H_ = H; }
/**
* @brief Changes the covariance matrix of the observation noise.
*
* @param R New covariance matrix
*/
void SetObservationNoise(const Eigen::Matrix &R) { R_ = R; }
/**
* @brief Changes the covariance matrix of current state belief distribution.
*
* @param P New state covariance matrix
*/
void SetStateCovariance(const Eigen::Matrix &P) { P_ = P; }
/**
* @brief Changes the control matrix in the state transition rule.
*
* @param B New control matrix
*/
void SetControlMatrix(const Eigen::Matrix &B) { B_ = B; }
/**
* @brief Get the system transition function under zero control.
*
* @return Transition matrix.
*/
const Eigen::Matrix &GetTransitionMatrix() const { return F_; }
/**
* @brief Get the covariance matrix of the transition noise.
*
* @return Covariance matrix
*/
const Eigen::Matrix &GetTransitionNoise() const { return Q_; }
/**
* @brief Get the observation matrix, which maps states to observations.
*
* @return Observation matrix
*/
const Eigen::Matrix &GetObservationMatrix() const { return H_; }
/**
* @brief Get the covariance matrix of the observation noise.
*
* @return Covariance matrix
*/
const Eigen::Matrix &GetObservationNoise() const { return R_; }
/**
* @brief Get the control matrix in the state transition rule.
*
* @return Control matrix
*/
const Eigen::Matrix &GetControlMatrix() const { return B_; }
/**
* @brief Updates the state belief distribution given the control input u.
*
* @param u Control input (by default, zero)
*/
void Predict(
const Eigen::Matrix &u = Eigen::Matrix::Zero());
/**
* @brief Updates the state belief distribution given an observation z.
*
* @param z Observation
*/
void Correct(const Eigen::Matrix &z);
/**
* @brief Gets mean of our current state belief distribution
*
* @return State vector
*/
Eigen::Matrix GetStateEstimate() const { return x_; }
/**
* @brief Gets covariance of our current state belief distribution
*
* @return Covariance matrix
*/
Eigen::Matrix GetStateCovariance() const { return P_; }
/**
* @brief Gets debug string containing detailed information about the filter.
*
* @return Debug string
*/
std::string DebugString() const;
/**
* @brief Get initialization state of the filter
* @return True if the filter is initialized
*/
bool IsInitialized() const { return is_initialized_; }
private:
// Mean of current state belief distribution
Eigen::Matrix x_;
// Covariance of current state belief dist
Eigen::Matrix P_;
// State transition matrix under zero control
Eigen::Matrix F_;
// Covariance of the state transition noise
Eigen::Matrix Q_;
// Observation matrix
Eigen::Matrix H_;
// Covariance of observation noise
Eigen::Matrix R_;
// Control matrix in state transition rule
Eigen::Matrix B_;
// Innovation; marked as member to prevent memory re-allocation.
Eigen::Matrix y_;
// Innovation covariance; marked as member to prevent memory re-allocation.
Eigen::Matrix S_;
// Kalman gain; marked as member to prevent memory re-allocation.
Eigen::Matrix K_;
// true iff SetStateEstimate has been called.
bool is_initialized_ = false;
};
template
inline void KalmanFilter::Predict(
const Eigen::Matrix &u) {
CHECK(is_initialized_);
x_ = F_ * x_ + B_ * u;
P_ = F_ * P_ * F_.transpose() + Q_;
}
template
inline void KalmanFilter::Correct(
const Eigen::Matrix &z) {
CHECK(is_initialized_);
y_ = z - H_ * x_;
S_ = static_cast>(H_ * P_ * H_.transpose() + R_);
K_ = static_cast>(P_ * H_.transpose() *
PseudoInverse(S_));
x_ = x_ + K_ * y_;
P_ = static_cast>(
(Eigen::Matrix::Identity() - K_ * H_) * P_);
}
}
2. 常用数据关联方法(匈牙利算法、概率数据关联算法PDA)
数据关联,在自动驾驶感知中可以理解为,确定你所获取的每个数据的来源,即判断检测的当
前帧每个结果分别来源于(跟踪上障碍物的序列tracked list)哪个物体。下面介绍两种典型的方
法:
2.1 匈牙利算法(概念有点多,但都非常简单)
2.1.1 图论基本概念
图(graph): 由顶点集合和顶点间的二元关系集合(即边的集合或弧的集合)组成的数据结构,通常可以用 G(V, E)来表示。
顶点集合(vertext set)和边的集合(edge set)分别用 V(G)和 E(G)表示。
V(G)中的元素称为顶点(vertex),用 u、 v 等符号表示;顶点个数称为图的阶(order),通常用 n 表示。
E(G)中的元素称为边(edge),用 e 等符号表示;边的个数称为图的边数(size),通常用 m 表示。

图2.1
图2.1 (a)所示的图:
顶点集合 V(G) = {1, 2, 3, 4, 5, 6}
边的集合为 E(G) = {(1, 2), (1, 3), (2, 3), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (4, 5)}
每个元素(u, v)为一对顶点构成的无序对,表示与顶点u 和 v 相关联的一条无向边(undirected
edge),这条边没有特定的方向,因此(u, v)与(v, u)是同一条的边。如果图中所有的边都没有方向性,
这种图称为无向图(undirected graph)
图2.1(b) 所示的图:
顶点集合: V(G) = {1, 2, 3, 4, 5, 6, 7}
边的集合为: E(G) = {<1, 2>, <2, 3>, <2, 5>, <2, 6>, <3, 5>, <4, 3>, <5, 2>, <5, 4>, <6, 7>},
每个元素
(directed Edge),其中 u 是这条有向边的起始顶点(start vertex,简称起点),v 是这条有向边的终止
顶点(end vertex,简称终点),如果图中所有的边都是有方向性的,这种图称为有向图(directed
graph).
图2.1(c) 有向图的基图:
忽略有向图所有边的方向,得到的无向图称为该有向图的基图。
2.1.2 二分图
二部图(bipartite graph) :
设无向图为 G(V, E) , 它的顶点集合 V 包含两个没有公共元素的子集:
![]() ,
, ![]() , 元素个数分别为 s 和 t; 并且
, 元素个数分别为 s 和 t; 并且  与
与 之间
之间
![]() ,
, 与
与![]() 之间
之间![]() 没有边连接,则称G为二部图,有的文献也称为二分图。
没有边连接,则称G为二部图,有的文献也称为二分图。
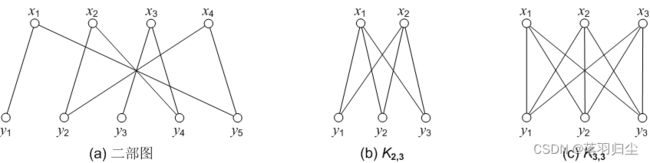
图2.2
完全二部图(complete bipartite graph):
在二部图 G 中,如果顶点集合 中每个顶点与顶点集合
中每个顶点与顶点集合 中每个顶点都有边相连,则称G
中每个顶点都有边相连,则称G
为完 全二部图,记为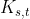 ,
,  和
和 分别为集合和集合中的顶点个数。在完全二部图中一共有
分别为集合和集合中的顶点个数。在完全二部图中一共有
![]() 条边. 图2.2中(b)、(c)均为完全二部图.
条边. 图2.2中(b)、(c)均为完全二部图.
2.1.3 匹佩问题
边覆盖点、边覆盖集、边覆盖数:
覆盖与边覆盖集: 设无向图为 G(V, E),边的集合 E*⊆E,若对于∀v∈V , ∃e∈E*,使得v与 e 相关联,
则称 e 覆盖 v,并称 E*为边覆盖集(edge covering set),或简称边覆盖。

图2.3
在图2.3(a)中,取 E* = ![]() ,则 E*就是图 G 的一个边覆盖集,因为图 G 中每个顶点都被 E*中某
,则 E*就是图 G 的一个边覆盖集,因为图 G 中每个顶点都被 E*中某
条边“覆盖”住了。
通俗地讲,所谓边覆盖集 E*,就是 G 中所有的顶点都是 E*中某条边的邻接顶点(边覆盖顶点)。
极小边覆盖:若边覆盖 E*的任何真子集都不是边覆盖, 则称 E*是极小边覆盖。
最小边覆盖: 边数最少的边覆盖集称为最小边覆盖。
边覆盖数(edge covering number): 最小的边覆盖所含的边数称为边覆盖数, 记作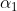
在图2.3(a)中,![]() 和
和![]() 都是极小边覆盖,
都是极小边覆盖,![]() 是最小边覆盖,= 3,
是最小边覆盖,= 3,
在图2.3(b)中,![]() 和
和![]() 都是极小边覆盖,也都是最小边覆盖,因此= 3。
都是极小边覆盖,也都是最小边覆盖,因此= 3。
边独立集、边独立数:
边独立集(匹配):设无向图为 G(V, E),边的集合 E*⊆E,若 E*中任何两条边均不相邻,则称 E*为 G 的边
独立集(edge independent set),也称 E*为 G 的匹配(matching)。所谓任何两条边均不相邻,通俗
地讲,就是任何两条边都没有公共顶点.

图2.4
在2.4(a)图中,取 E* = ![]() ,则 E*就是图 G 的一个边独立集,因为 E*中每两条边都没有公共顶点。
,则 E*就是图 G 的一个边独立集,因为 E*中每两条边都没有公共顶点。
极大匹配: 若在 E*中加入任意一条边所得到的集合都不是匹配,则称 E*为极大匹配。
最大匹配: 边数最多的匹配称为最大匹配。
边独立数(edge independent number,也称匹配数):最大匹配的边数称为边独立数或匹配数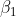 。
。
在2.4(a)图中, ![]() 、
、![]() 和
和![]() 都是极大匹配,
都是极大匹配,![]() 是最大匹配,因此
是最大匹配,因此![]()
在2.4(b)图中,![]() 、
、![]() 和
和![]() 都是极大匹配,也都是最大匹配,因此
都是极大匹配,也都是最大匹配,因此![]() 。
。
盖点与未盖点:设 v 是图 G 的一个顶点,如果 v 与 M 中的某条边关联,则称 v 为 M 的盖点(有的文献上
也称为 M 饱和点)。如果 v 不与任意一条属于匹配 M 的边相关联,则称 v 是匹配 M的未盖点(相应地,
有的文献上也称为非 M 饱和点)。所谓盖点,就是被匹配中的边盖住了,而未盖点就是没有被匹配M
中的边“盖住”的顶点。
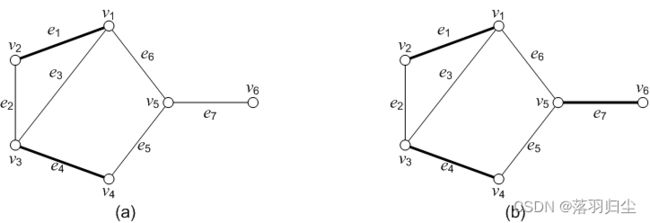 图2.4
图2.4
在2.4图 (a)所示的无向图中,取定 M = ![]() ,M 中的边用粗线标明,则顶点
,M 中的边用粗线标明,则顶点 与
与 被 M 所匹
被 M 所匹
配;、 、![]() 和
和 ![]() 是 M 的盖点,
是 M 的盖点, 和
和 ![]() 是 M 的未盖点。而在图(b)中,取定 M =
是 M 的未盖点。而在图(b)中,取定 M =![]()
则M中不存在未盖点。
完美匹配: 对于一个图 G 与给定的一个匹配 M,如果图 G 中不存在 M 的未盖点,则称匹配M为图 G 的
完美匹配。
二部图的完备匹配与完美匹配:
二部图的完备匹配:设无向图 G(V, E)为二部图,它的两个顶点集合为 X 和 Y,且|X|≤|Y|,M为 G 中的一
个最大匹配,且|M| = |X|,则称 M 为 X 到 Y 的二部图 G 的完备匹配。若|X| = |Y|,则该完备匹配覆盖住
G 的所有顶点,所以该完备匹配也是完美匹配。
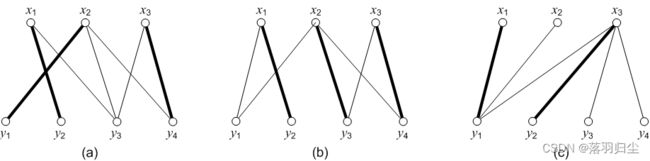
图2.5
图2.5所示的3个二部图,其中图(a)和图(b)中取定的匹配 M 都是完备匹配,而图(c)中不存在完备匹
配。
example:某公司有工作人员![]() ,他们去做工作
,他们去做工作![]() ,问能否恰当地安排
,问能否恰当地安排
使得每个人都分配到一项合适的工作。
二部图的最佳匹配:(在此引出概念,用于多目标跟踪)
设 G(V, E)为加权二部图,它的两个顶点集合分别为![]() 。
。
![]() 表示工作人员做工作
表示工作人员做工作 时的效益,权值总和最大的完备匹配称为二部图的最佳
时的效益,权值总和最大的完备匹配称为二部图的最佳
匹配。
2.1.4 二分图的最大匹配之匈牙利算法
2.1.5 匈牙利算法在多目标跟踪数据关联中的应用
2.2 概率数据关联算法
2.2.1 关联门
2.2.2 最小均方差估计
2.2.3 完备事件组
2.2.4 概率数据关联算法pda
2.2.5 pda在多目标跟踪数据关联中的应用
3. 交互多模型(Interacting Multiple Model ,IMM)
考虑每个物体可能存在不同的运动状态(匀速、匀速圆周、匀加速等),采用单一的模型估计可能会存在较大的偏差,遂引入交互多模型来解决改问题。
交互多模型介绍: