推荐系统入门(一):概述
推荐系统入门(一):概述
目录
- 推荐系统入门(一):概述
-
- 引言
- 1. 推荐系统简介
- 2. 常用评测指标
-
- 2.1 用户满意度
- 2.2 预测准确度
- 2.3 覆盖率
- 2.4 多样性
- 2.5 新颖性
- 2.6 惊喜度
- 2.7 信任度
- 2.8 实时性
- 2.9 健壮性
- 2.10 AUC曲线
- 3. 召回
-
- 3.1 召回层在推荐系统架构中的位置及作用
- 3.2 多路召回策略
- 3.3 Embedding召回
- 扩展
- 结语
- 参考资料
引言
相关系列笔记:
推荐系统入门(一):概述
推荐系统入门(二):协同过滤(附代码)
推荐系统入门(三):矩阵分解MF&因子分解机FM(附代码)
推荐系统入门(四):Wide&Deep(附代码)
推荐系统入门(五):GBDT+LR(附代码)
推荐系统入门(六):新闻推荐实践1(附代码)
推荐系统入门(七):新闻推荐实践2(附代码)
推荐系统入门(八):新闻推荐实践3(附代码)
推荐系统入门(九):新闻推荐实践4(附代码)
推荐系统入门(十):新闻推荐实践5(附代码)
移动联通互联网、人工智能等技术的迅速发展为人们的工作生活带来了很多便利,但是同时也带来了信息过载问题。搜索引擎和推荐系统是解决信息过载的代表技术。传统的搜索引擎在本质上来讲是帮助用户过滤和筛选信息,这种方式满足了大多数人的需求,但没有提供个性化的服务。相对于传统搜索引擎来说,推荐系统可以兼顾个性化需求和解决信息过载问题。推荐系统是信息过滤系统的一个子集,目的在于根据用户的喜好、习惯、个性化需求以及商品的特性来预测用户对商品的喜好,为用户推荐最合适的商品,帮助用户快速地做出决策,提高用户满意度。推荐系统的价值在于能够提供尽量合适的选择或者是推荐而不需要用户明确提供他们所想要的内容。随着大数据时代的到来,传统推荐系统在挖掘数据价值上存在的问题正在限制其性能发挥。知识图谱的出现为大数据环境下的推荐系统设计提供了一种有效途径。
目前,推荐系统已经成为产业界和学术界关注、研究的热点问题,应用领域十分广泛,在电子商务、社交网络、视频音乐推荐等领域都有所应用。例如亚马逊网站、京东、淘宝网站为用户推荐商品,MovieLens推荐电影的功能等。
传统推荐系统与深度学习推荐系统的演化关系图(图来自《深度学习推荐系统》)如下:
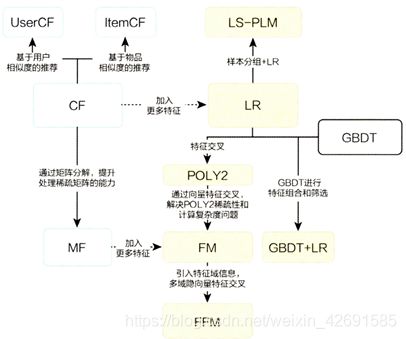
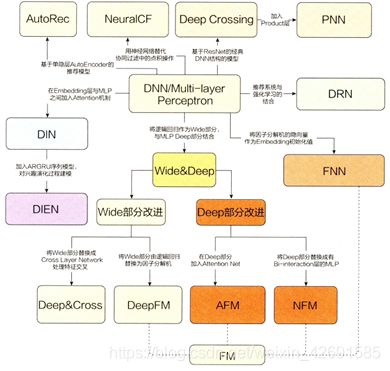
1. 推荐系统简介
- What
- 用户:推荐系统是一种帮助用户快速发现有用信息的工具。
- 公司:推荐系统是一种增加公司产品与用户接触,购买等行为概率的工具。
- Why
- 用户:在用户需求并不十分明确的情况下进行信息的过滤,与搜索系统相比,推荐系统更多的利用用户的各类历史信息猜测其可能喜欢的内容。
- 公司:解决产品能够最大限度地吸引用户,留存用户,增长用户黏性,提高用户转化率,从而达到公司商目标连续增长的目的。
本质上是一种实现将用户-商品-公司之间利益最大化的手段.
- Who
从上面的1和2可以看出用户与公司是需要推荐系统的主要对象,那么可以在1和2的基础上展开想想什么样的人需要推荐系统,以及什么样的公司需要推荐系统。
2. 常用评测指标
评测指标(Evaluation Indicator) 是用于衡量一个推荐系统各方面的性能好坏。 针对不同的应用场景有不同的评测其中用户满意度和准确度是最常用的评价指标。
2.1 用户满意度
用户是推荐系统中非常重要的参与者,他们的满意度也直接决定了推荐系统的好坏。但是用户满意度这个指标无法离线计算,只能通过用户调查或者在线实验获得。这里在线实验一般是通过用户的线上行为统计得到的,比如电商场景中,用户如果购买了推荐的商品说明一定程度上他们是满意的,因此可以通过购买率度量用户的满意度,与购买率类似的点击率、用户停留时间和转化率等指标都可以用来度量用户的满意度。
点击率是指用户对推荐内容的点击访问频率,购买率是指用户通过点击推荐内容最终购买了商品的频率,直接点击率和直接购买率和点击率、购买率相似只是排除了那些通过访问了其他推荐链接再回退到原链接的情况。
2.2 预测准确度
预测准确度是一种离线的评测方式,能够度量一个推荐系统预测用户行为的能力。准确度预测主要包括评分预测和Top-N预测。这两种指标的侧重点不同,评分预测关注用户是否会对推荐的内容给出较高的评分,而 Top-N 预测关注于用户是否会查看所推荐内容的信息。
- 评分预测
2006 年,在线 DVD 租赁公司 Netflix 举办了一个推荐系统大赛提供了大约 500,000 个匿名用户对超过17,000 部电影的评分数据,测试数据集规模也到三百万。此次比赛便是一个典型的评分预测,评测指标均方根误差(RMSE)。
对物品的评分行为称为评分预测,评分预测模型通过对用户的历史物品评分记录进行建模,进而得到用户的兴趣模型,然后使用该模型预测用户未未见过商品的评分。评分预测的预测准确度一般通过均方根误差(RMSE)和平均绝对误差(MAE) 计算。对于测试集中的rui 是用户 u 对物品 i 的实际评分,Rui 是推荐算法计算得到的评分,RMSE可以定义为:
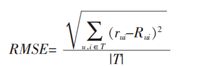
MAE定义为:
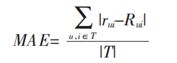
RMSE由于存在平方项,使得使得用户真实评分与推荐系统预测评分相差较大的用户加大了惩罚,即该评测指标对系统要求更加的苛刻。
- TopN推荐
在给用户推荐物品的时候,往往会给用户一个列表的推荐物品,这种场景下的推荐成为是TopN推荐,该推荐方式最常用的预测准确率指标一般是精确率(precision)和召回率(recall),令R(u)为通过推荐模型得到的推荐列表,T(u)为用户在实际场景中(测试集)的行为列表。
- 精确率(precision): 分类正确的正样本个数占分类器判定为正样本的样本个数比例(这里R(u)相当于是模型判定的正样本)
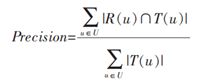
- 召回率(recall): 分类正确的正样本个数占真正的正样本个数的比例(这里的T(u)相当于真正的正样本集合)
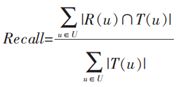
有时候为了更加全面的评估TopN推荐,通常会选取不同的推荐列表长度计算多组精确率与召回率,然后分别绘制出精确率曲线和召回率曲线,需要注意的是这里并不是PR曲线,感兴趣的可以了解一下PR曲线相关的知识。
2.3 覆盖率
覆盖率(Coverage) 是用来描述一个推荐系统对物品长尾的发掘能力,一个简单的定义可以是:推荐系统所有推荐出来的商品集合数占总物品集合数的比例。令网站的用户集合为 U,网站的商品集合为 I, 推荐系统会给用户推荐一个长度为 N 的商品列表 R(u),那么覆盖率定义如式下:
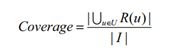
但是对于相同的覆盖率,不同物品的数量分布,或者说是物品的流行度分布是可以不一样的。为了更好的描述推荐系统挖掘长尾的能力,需要统计不同物品出现次数的分布。如果所有的物品都出现在推荐列表中,并且出现的次数都差不多,那么推荐系统发掘长尾的能力就很好。所以可以通过研究物品在推荐列表中出现的次数分布来描述推荐系统挖掘长尾的能力,如果这个分布比较平缓说明推荐系统的覆盖率比较高,而如果分布比较陡说明推荐系统的覆盖率比较低。下面分别使用信息熵和基尼系数来定义覆盖率。
信息熵定义覆盖率: 其中p(i)是物品i的流行度除以所有物品流行度之和。
![]()
基尼系数定义覆盖率: 其中ij是按照物品流行度p从小到大排序的物品列表中第j个物品。
![]()
2.4 多样性
人的兴趣爱好通常是比较广泛的,所以一个好的推荐系统得到的推荐列表中应该尽可能多的包含用户的兴趣,只有这样才能增加用户找到感兴趣物品的概率。度量推荐列表中物品的多样性换句话说就是度量推荐列表中所有物品之间的不相似性,可以通过不同的相似性函数来度量推荐列表中商品的相似性,比如商品基于内容的相似,基于协同过滤的相似,这样就可以得到不同角度的多样性。令函数s(i,j)为物品i和物品j的相似性,那么用户推荐列表的多样性可以定义为:
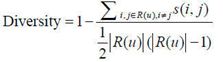
推荐系统整体的多样性可以定义为所有用户推荐列表多样性的平均值:
![]()
2.5 新颖性
新颖性,就是为用户推荐那些他们之前从未听说过的商品。通过在推荐列表中过滤掉之前用户浏览过或购买过的商品,即可以最简单的方式实现推荐的新颖性。或将推荐列表中热门度较高的商品进行过滤,因为越不热门的商品,往往对于用户来说是越新颖的。但是这种方法依然不够严谨,若想要获得更准确的信息,还需要进行用户调查。
2.6 惊喜度
惊喜度是近年来推荐系统领域中非常热门的研究话题。但需要注意的是,惊喜度与新颖性是截然不同的。惊喜度是指为用户进行的推荐与用户的历史兴趣不一致,但用户却对推荐结果感到满意。因此,为完成惊喜度较高的推荐,需要将推荐结果与用户历史兴趣加以区别,并提高用户的满意度。但目前关于惊喜度没有定量的定义方式,只能通过定性的方式来度量。
2.7 信任度
一个信任度较高的推荐系统会让用户愿意使用并由此会在网站产生更多的用户行为数据,增加网站与厂商的收益。获得关于推荐系统信任度的信息只能通过用户调查的方式,询问用户是否信任推荐系统的推荐结果。而提高推荐系统的信任度有两种主要的方法:一是提升网站推荐系统的透明度,提供合理的推荐解释。二是利用社交网络信息,将好友的相关信息用于推荐解释中。因为用户通常比较信任其好友,所以如果他们的好友购买过某商品,那么他们对含有其好友信息的推荐解释就会比较信任。
2.8 实时性
对于有很强时效性的商品,推荐系统需要在其还有时效性时将他们推荐给用户,比如用户购买了某一商品时,推荐系统应能够尽快将与该商品相关的商品推荐给用户。如果当用户对商品有过行为 ( 浏览或购买等 ) 后,展示给用户的推荐列表内容却变化不大或没有变化,这说明推荐系统的实时性不好。另外,推荐系统还应将新近加入系统的商品推荐给相关用户,而这需要提高推荐系统的物品冷启动能力。
2.9 健壮性
任何系统都有被攻击的可能,而对于可以带来商业利益的推荐系统来说,其健壮性尤为重要。在实际中,除了要选择健壮性高的算法之外,还可以通过以下两种方法提升系统的健壮性:第一,在推荐系统进行用户行为分析时,应主要选择分析行为代价高的用户行为。例如,将浏览与购买进行比较,购买行为的代价就远高于浏览行为,因为购买需要付费,以此进行攻击代价更高。第二,在系统上线前,还需要进行攻击测试,对异常数据进行识别并将其清理,进一步确保系统的健壮性。
2.10 AUC曲线
AUC(Area Under Curve),ROC曲线下与坐标轴围成的面积。
在讲AUC前需要理解混淆矩阵,召回率,精确率,ROC曲线等概念。
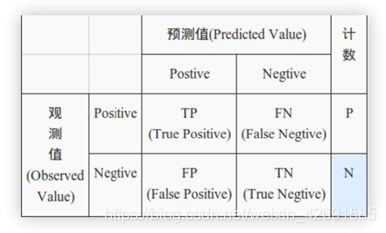
TP:真的真了(真实值是真的,预测也是真)
FN:真的假了(真实值是真的,预测为假了)
FP:假的真了(真实值是假的,预测为真了)
TN:假的假了(真实值是假的,预测也是假)
召回率与准确率(上述已经进行了说明),下面是另一种形势的定义,本质上都是一样的:
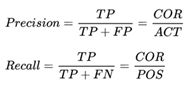
ROC(Receiver Operating Characteristic Curve)曲线:
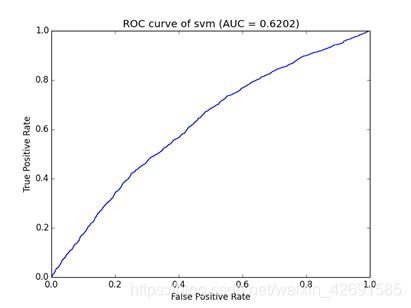
ROC曲线的横坐标为假阳性率(False Positive Rate, FPR),N是真实负样本的个数, FP是N个负样本中被分类器预测为正样本的个数。
纵坐标为真阳性率(True Positive Rate, TPR),P是真实正样本的个数,TP是P个正样本中被分类器预测为正样本的个数。
注:还有其他的评价指标具体可以参考项亮的《推荐系统实践》
3. 召回
3.1 召回层在推荐系统架构中的位置及作用
在推荐系统架构中召回层与排序层是推荐系统的核心算法层,而将推荐过程分成召回层与排序层主要是基于工程上的考虑,其中召回阶段负责将海量的候选集快速缩小为几万到几千的规模;而排序层则负责对缩小后的候选集进行精准排序。所以在召回阶段往往会利用少量的特征和简单的模型对大规模的数据集进行快速的筛选,而在排序层一般会使用更多的特征和更加复杂的模型进行精准的排序。
下面是召回层与排序层的特点:
- 召回层:待计算的候选集合大、计算速度快、模型简单、特征较少,尽量让用户感兴趣的物品在这个阶段能够被快速召回,即保证相关物品的召回率
- 排序层:首要目标是得到精准的排序结果。需要处理的物品数量少,可以利用较多的特征,使用比较复杂的模型。
在设计召回层时,**“计算速度”和“召回率”**其实是矛盾的两个指标,为提高“计算速度”,需要使召回策略尽量简单一些;而为了提高“召回率”,要求召回策略尽量选出排序模型所需要的候选集,这也就要求召回策略不能过于简单。在权衡计算速度和召回率后,目前工业界主流的召回方法是采用多个简单策略叠加的“多路召回策略”.
3.2 多路召回策略
所谓的==“多路召回”策略==,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用,可以明显的看出,“多路召回策略”是在“计算速度”和“召回率”之间进行权衡的结果。其中,各种简单策略保证候选集的快速召回,从不同角度设计的策略保证召回率接近理想的状态,不至于损伤排序效果。
如下图是多路召回的一个示意图,在多路召回中,每个策略之间毫不相关,所以一般可以写并发多线程同时进行,这样可以更加高效。

上图只是一个多路召回的例子,也就是说可以使用多种不同的策略来获取用户排序的候选商品集合,而具体使用哪些召回策略其实是与业务强相关的,针对不同的任务就会有对于该业务真实场景下需要考虑的召回规则。例如视频推荐,召回规则可以是“热门视频”、“导演召回”、“演员召回”、“最近上映”、“流行趋势”、“类型召回” 等等。
多路召回存在的问题
虽然多路召回权衡了计算速度和召回率的问题,可以使得用于排序的候选商品更加的丰富,但是实际的多路召回仍然存在一些问题。如上图所示,对于每一路召回都会从商品集合中拉回K个商品,这里的K是一个超参数,对于K的选择一般需要通过离线评估加线上的A/B测试来确定合理的K值。除此之外,对于不同的任务具体策略的选择也是人工基于经验的选择,选择的策略之间的信息是割裂的,无法总和考虑不同策略对一个物品的影响。
基于上述问题,Embedding召回是一个综合性强且计算速度也能满足需求的召回方法。
3.3 Embedding召回
在当前的主流推荐系统中,Embedding的身影已经无处不在,从一定意义上可以说,把Embedding做好了,整个推荐系统的一个难题就攻克了,下面会从什么是Embedding,常见的Embedding技术有哪些,以及如何用Embedding做召回进行一个简单的总结。
1.Embedding是什么?
Embedding其实是一种思想,主要目的是将稀疏的向量(如one-hot编码)表示转换成稠密的向量,下图直观的显示了one-hot编码和Embedding表示的区别于联系,即Embedding相当于是对one-hot做了平滑,而onehot相当于是对Embedding做了max pooling。

2.常见的Embedding技术有哪些?
目前主流的Embedding技术主要可以分为三大类:
• text embedding
• image embedding
• graph embedding
在推荐系统领域,text embedding技术是目前使用最多的embedding技术,对于文本特征可以直接使用该技术,对于非文本的id类特征,可以先将其转化成id序列再使用text embedding的技术获取id的embedding再做召回。
常见的text Embedding的技术有:
- 静态向量:word2vec, fasttext, glove
- 动态向量:ELMO, GPT, BERT
对于image embedding其实主要是对于有图或者视频的特征,目前计算机视觉模型已经发展的比较成熟了,对于图像与视频的识别都有效果比较好的模型,大部分都是卷积模块通过各种连接技巧搭建的高效模型,可以使用现有的预训练模型提取图像或者视频的向量特征,然后用于召回。
对于社交网络相关的推荐,进行推荐的用户与用于之间或者商品之间天然的存在某种复杂的图结构的关系,如何利用图中节点与节点之间的关系对其进行向量化是非常关键的,在这种场景下基于序列的text embedding和基于卷积模型的image embedding都显得力不从心,在这样的背景下Graph Embedding逐渐在推荐系统中流行起来。经典的Graph Embedding模型有, Deep Walk, Node2Vec,LINE以及比较新的阿里巴巴2018年公布的EGES graph Embedding模型。
扩展
- 为什么使用AUC?
例如0.7的AUC,其含义可以大概理解为:给定一个正样本和一个负样本,在70%的情况下,模型对正样本的打分高于对负样本的打分。可以看出这个解释下,我们关心的只有正负样本之间的分数高低,而具体的分支则无关紧要
【多高的AUC才算高】:参考文章 https://zhuanlan.zhihu.com/p/24217322
- 如何使用Embedding做召回?
参考腾讯的推荐系统 embedding 技术实践总结
结语
无论是提高推荐算法效率、鲁棒性或可解释性,加强用户界面的友好程度,还是加强用户与系统的互动,其最终目的都是为了提高用户体验感和满意度。为什么有时候人们更愿意去一些环境优雅的小书屋阅读或购买书籍,而不是选择品种更加齐全的大书城,原因就在于特色的书吧相比千篇一律的书城无论在购物环境还是服务上都能够使顾客更满意。真正的利润不是来自于商品本身,而是来自于用户的购买或点击行为。用户良好的体验感正是促成这种行为的原动力。如何设计以用户体验为中心的推荐系统将成为下一代信息过滤技术的一个核心问题,而相应的系统评价指标的设计也是任重而道远。
参考资料
- Datawhale组队学习:推荐系统基础
- 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(02):163-175.
- 李斌.推荐系统研究综述[J].现代计算机(专业版),2014(03):7-10.
- 常亮,张伟涛,古天龙,孙文平,宾辰忠.知识图谱的推荐系统综述[J].智能系统学报,2019,14(02):207-216.
- 周万珍,曹迪,许云峰,刘滨.推荐系统研究综述[J].河北科技大学学报,2020,41(01):76-87.
- 王春才,邢晖,李英韬.推荐系统评测方法和指标分析[J].信息技术与标准化,2015(07):27-29+44.